When Meaning Travels: A Granular Lens on Hybrid-MoE's Role in Idiomatic Understanding for Language Models
Pith reviewed 2026-06-28 15:15 UTC · model grok-4.3
The pith
HybridMoE improves figurative language handling in multilingual vision models by integrating expert outputs and idiomatic signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
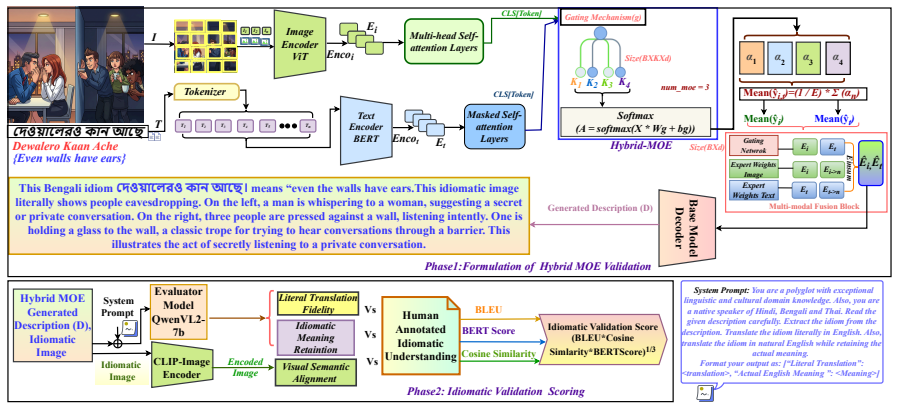
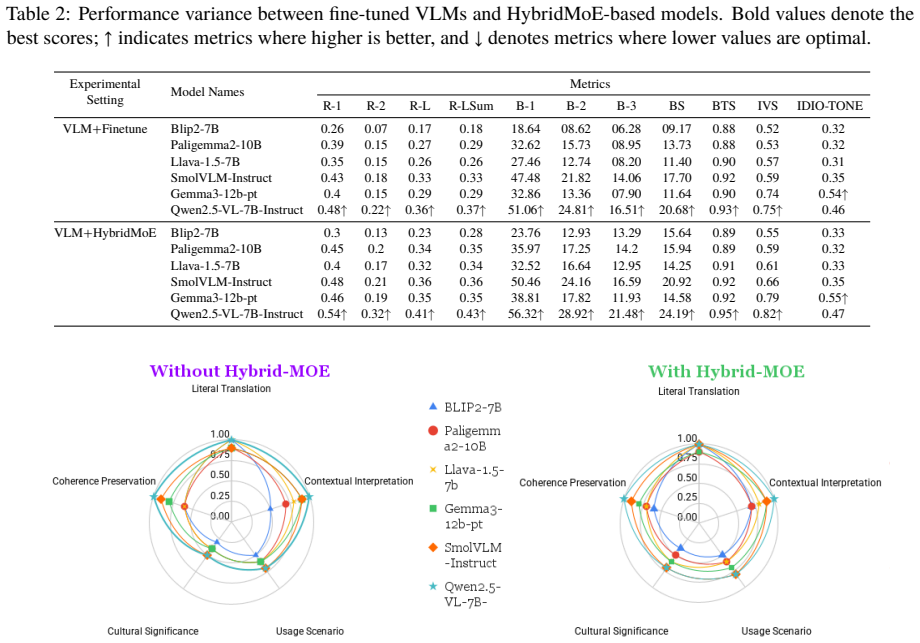
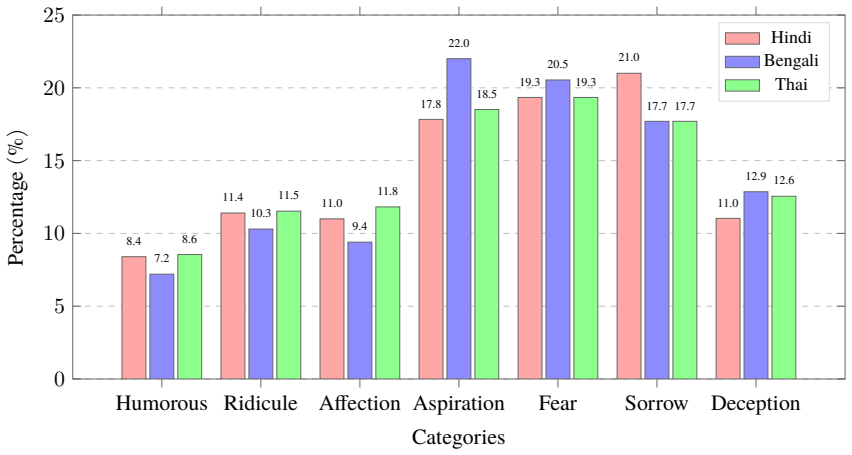
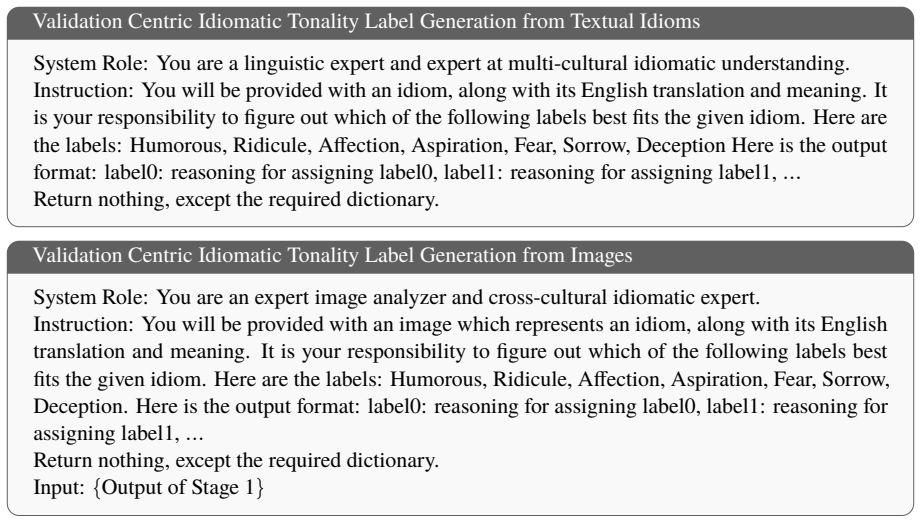
The HybridMoE framework embeds multiple idiomatic expert opinions while mitigating expert sparsity by integrating outputs from both selected and unselected experts through controlled hybridization, further augmented with Idiomatic Property Signals via masked multimodal embeddings, yielding 5--6% gains on IDIO-TONE and Idiomatic Validation Score metrics for the Varnika corpus of 3,533 multilingual idioms.
What carries the argument
Hybrid Mixture-of-Experts (HybridMoE) that integrates selected and unselected expert outputs via controlled hybridization plus Idiomatic Property Signals from masked multimodal embeddings.
If this is right
- Literal translation fidelity, visual-semantic alignment, and idiomatic meaning retention all rise together when hybridization is applied.
- The same signals and hybridization steps can be added to existing vision-language models without retraining the entire system.
- Seven idiomatic tone categories become measurable and improvable in a single multimodal pipeline.
- Performance lifts appear across Hindi, Bengali, and Thai, suggesting transfer to other low-resource language pairs.
Where Pith is reading between the lines
- The hybridization step may generalize to non-idiomatic figurative devices such as metaphor or sarcasm if the property signals are redefined.
- Because unselected experts still contribute, the method could reduce the number of active experts needed at inference time.
- The three-stage pipeline could serve as a template for evaluating other culturally loaded phenomena like proverbs or humor.
Load-bearing premise
That controlled hybridization of selected and unselected experts plus masked idiomatic signals captures the seven tones without bias or overfitting.
What would settle it
A side-by-side run on the Varnika corpus and IDIO-TONE pipeline in which HybridMoE shows no gain or a loss relative to a standard MoE baseline on idiomatic meaning retention.
Figures



read the original abstract
In the contemporary epoch of multilingual education, learning idioms provides a fascinating gateway towards creativity, cultural values, historical context, and diverse perspectives inherent to various linguistic traditions. This paper showcases the navigation of retaining figurative and cultural semantics in low-resource Southeast Asian languages such as Hindi, Bengali, and Thai, where culturally rich idioms pose significant obstacles for computational modeling and cross-linguistic transfer due to their deep metaphorical complexity. To tackle such complexity, we present Varnika, a reconstructed multimodal idiom corpus comprising 3,533 multilingual idioms, enriched with seven idiomatic tones aligned with both textual and visual representations. Additionally, to infer informative idiomatic understanding, we introduce a Hybrid Mixture-of-Experts (HybridMoE) framework that embeds multiple idiomatic expert opinions while mitigating expert sparsity by integrating outputs from both selected and unselected experts through controlled hybridization, further augmented with Idiomatic Property Signals via masked multimodal embeddings. To analyze the performance across multiple dimensions, we propose the IDIO-TONE and Idiomatic Validation Score, a three-stage evaluation pipeline measuring (i) literal translation fidelity, (ii) visual-semantic alignment, and (iii) idiomatic meaning retention. Empirical evaluations highlight that HybridMoE achieves 5--6\% performance gains across advanced vision language models, demonstrating improved representation of figurative language and culturally embedded meaning in multilingual multimodal settings
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Varnika, a multimodal corpus of 3,533 idioms in Hindi, Bengali, and Thai annotated with seven idiomatic tones, and proposes a HybridMoE architecture that performs controlled hybridization of selected and unselected experts augmented by Idiomatic Property Signals from masked multimodal embeddings. It defines a new three-stage IDIO-TONE / Idiomatic Validation Score pipeline (literal translation fidelity, visual-semantic alignment, idiomatic meaning retention) and claims that HybridMoE yields 5–6 % gains over advanced vision-language models in multilingual figurative-language settings.
Significance. If the new metrics prove reliable and the experimental claims are reproducible, the work would address a genuine gap in culturally grounded multimodal idiom modeling for low-resource languages. At present, however, the absence of metric validation and experimental controls makes it impossible to determine whether the reported gains reflect improved idiomatic understanding or artifacts of the evaluation design.
major comments (3)
- [Abstract / Evaluation pipeline] Abstract / Evaluation section: IDIO-TONE and the Idiomatic Validation Score are introduced as the sole basis for the 5–6 % gain claim, yet the manuscript supplies no construction details, inter-annotator agreement statistics, correlation with human judgments, or comparison against existing idiom benchmarks. Without such grounding the numerical improvements cannot be interpreted as evidence of better figurative or cultural representation.
- [Abstract] Empirical results (abstract): The headline performance claim is presented without baselines, statistical significance tests, error bars, or data-exclusion criteria. This omission prevents verification that the observed gains are attributable to HybridMoE rather than experimental artifacts or metric-specific biases.
- [Abstract / HybridMoE framework] Framework description (abstract): The 'controlled hybridization' mechanism that integrates unselected experts is described only at a high level; no equations, hyper-parameter schedules, or ablation studies are supplied to demonstrate that the hybridization parameters are independent of the IDIO-TONE metrics. This leaves open the possibility of circularity between model design and evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where additional rigor is needed. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract / Evaluation pipeline] Abstract / Evaluation section: IDIO-TONE and the Idiomatic Validation Score are introduced as the sole basis for the 5–6 % gain claim, yet the manuscript supplies no construction details, inter-annotator agreement statistics, correlation with human judgments, or comparison against existing idiom benchmarks. Without such grounding the numerical improvements cannot be interpreted as evidence of better figurative or cultural representation.
Authors: We agree that the submitted manuscript lacks these grounding details for IDIO-TONE and the Idiomatic Validation Score. In the revision we will add a dedicated subsection with annotation construction process, inter-annotator agreement statistics, correlation analysis against human judgments, and direct comparisons to prior idiom benchmarks. This addresses the interpretability concern directly. revision: yes
-
Referee: [Abstract] Empirical results (abstract): The headline performance claim is presented without baselines, statistical significance tests, error bars, or data-exclusion criteria. This omission prevents verification that the observed gains are attributable to HybridMoE rather than experimental artifacts or metric-specific biases.
Authors: We agree the abstract and results presentation omit these elements. The revision will update the abstract to reference key baselines, include statistical significance tests, error bars, and explicit data-exclusion criteria, ensuring the 5–6% gains can be properly attributed and verified. revision: yes
-
Referee: [Abstract / HybridMoE framework] Framework description (abstract): The 'controlled hybridization' mechanism that integrates unselected experts is described only at a high level; no equations, hyper-parameter schedules, or ablation studies are supplied to demonstrate that the hybridization parameters are independent of the IDIO-TONE metrics. This leaves open the possibility of circularity between model design and evaluation.
Authors: We agree the abstract-level description is high-level and that equations, hyper-parameter schedules, and ablations are absent. The revision will supply the mathematical formulation of controlled hybridization, tuning schedules, and ablation studies on held-out data to demonstrate parameter independence from IDIO-TONE and eliminate circularity concerns. revision: yes
Circularity Check
No circularity detected; derivation remains self-contained
full rationale
The provided abstract and description introduce a new corpus (Varnika), HybridMoE framework, and IDIO-TONE/Idiomatic Validation Score metrics via explicit three-stage pipeline definitions, then report empirical gains on those metrics. No equations, parameter-fitting steps, or derivations are shown that reduce the 5-6% gains or hybridization claims to the inputs by construction. No self-citation chains, ansatz smuggling, or renaming of known results appear in the text. The central claims are presented as independent empirical observations on the defined pipeline, satisfying the default expectation of non-circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
2014 , publisher =
Ekarat Udomporn , title =. 2014 , publisher =
2014
-
[9]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Drishtikon: A multimodal multilingual benchmark for testing language models’ understanding on indian culture , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[10]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
SANSKRITI: A comprehensive benchmark for evaluating language models’ knowledge of Indian culture , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[11]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[12]
, author=
Why Teach Idioms? A Challenge to the Profession. , author=. Iranian Journal of Language Teaching Research , volume=. 2017 , publisher=
2017
-
[13]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[14]
, title =
Robinson, Arthur L. , title =. 1980 , doi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[15]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[16]
Clancey and Glenn Rennels , abstract =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
-
[17]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[18]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[19]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[20]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[21]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[22]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
-
[23]
arXiv preprint arXiv:2412.03555 , year=
Paligemma 2: A family of versatile vlms for transfer , author=. arXiv preprint arXiv:2412.03555 , year=
-
[24]
arXiv preprint arXiv:2504.05299 , year=
Smolvlm: Redefining small and efficient multimodal models , author=. arXiv preprint arXiv:2504.05299 , year=
-
[25]
, title =
Turing, Alan M. , title =. Mind , volume =
-
[26]
Nature , volume =
Learning Representations by Back-Propagating Errors , author =. Nature , volume =
-
[27]
Proceedings of the 10th European Conference on Artificial Intelligence (ECAI) , pages =
Planning as Satisfiability , author =. Proceedings of the 10th European Conference on Artificial Intelligence (ECAI) , pages =
-
[28]
Artificial Intelligence , volume =
Collaborative Plans for Complex Group Action , author =. Artificial Intelligence , volume =
-
[29]
The Entropy Formula for the
Grisha Perelman , howpublished =. The Entropy Formula for the
-
[30]
arXiv preprint arXiv:2410.10594 , year=
Visrag: Vision-based retrieval-augmented generation on multi-modality documents , author=. arXiv preprint arXiv:2410.10594 , year=
-
[31]
arXiv preprint arXiv:2411.18203 , year=
Critic-v: Vlm critics help catch vlm errors in multimodal reasoning , author=. arXiv preprint arXiv:2411.18203 , year=
-
[32]
FROM THEORY TO PRACTICE: MEMORY STRATEGIES FOR EFFECTIVE IDIOM LEARNING , author=
-
[33]
Causality , author =
-
[34]
Structure and Interpretation of Computer Programs
Harold Abelson and Gerald Jay Sussman and Julie Sussman. Structure and Interpretation of Computer Programs. 1985
1985
-
[35]
arXiv preprint arXiv:2405.10579 , year=
A Hard Nut to Crack: Idiom Detection with Conversational Large Language Models , author=. arXiv preprint arXiv:2405.10579 , year=
-
[36]
12th Language Resources and Evaluation Conference: LREC 2020 , pages=
MAGPIE: A large corpus of potentially idiomatic expressions , author=. 12th Language Resources and Evaluation Conference: LREC 2020 , pages=. 2020 , organization=
2020
-
[37]
Proceedings of the 12th Conference of the European Chapter of the ACL (EACL 2009) , pages=
Unsupervised recognition of literal and non-literal use of idiomatic expressions , author=. Proceedings of the 12th Conference of the European Chapter of the ACL (EACL 2009) , pages=
2009
-
[38]
Proceedings of the LREC Workshop Towards a Shared Task for Multiword Expressions (MWE 2008) , pages=
The VNC-tokens dataset , author=. Proceedings of the LREC Workshop Towards a Shared Task for Multiword Expressions (MWE 2008) , pages=. 2008 , organization=
2008
-
[39]
Proceedings of the joint workshop on automatic knowledge base construction and web-scale knowledge extraction (AKBC-WEKEX) , pages=
Annotated gigaword , author=. Proceedings of the joint workshop on automatic knowledge base construction and web-scale knowledge extraction (AKBC-WEKEX) , pages=
-
[40]
, author=
Idioms in Context: The IDIX Corpus. , author=. LREC , year=
-
[41]
Second Joint Conference on Lexical and Computational Semantics (* SEM), Volume 2: Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval 2013) , pages=
Semeval-2013 task 5: Evaluating phrasal semantics , author=. Second Joint Conference on Lexical and Computational Semantics (* SEM), Volume 2: Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval 2013) , pages=
2013
-
[42]
Visual Information Extraction with Lixto
Robert Baumgartner and Georg Gottlob and Sergio Flesca. Visual Information Extraction with Lixto. Proceedings of the 27th International Conference on Very Large Databases. 2001
2001
-
[43]
International Conference on Machine Learning , pages=
Multi-task reinforcement learning with context-based representations , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[44]
arXiv preprint arXiv:2404.12464 , year=
Normad: A benchmark for measuring the cultural adaptability of large language models , author=. arXiv preprint arXiv:2404.12464 , year=
-
[45]
Sci , volume=
Vector representations of idioms in conversational systems , author=. Sci , volume=. 2022 , publisher=
2022
-
[46]
arXiv preprint arXiv:2104.06541 , year=
From solving a problem boldly to cutting the gordian knot: Idiomatic text generation , author=. arXiv preprint arXiv:2104.06541 , year=
-
[47]
arXiv preprint arXiv:2112.02994 , year=
IBERT: Idiom Cloze-style reading comprehension with Attention , author=. arXiv preprint arXiv:2112.02994 , year=
-
[48]
arXiv preprint arXiv:1906.05317 , year=
COMET: Commonsense transformers for automatic knowledge graph construction , author=. arXiv preprint arXiv:1906.05317 , year=
Pith/arXiv arXiv 1906
-
[49]
Brachman and James G
Ronald J. Brachman and James G. Schmolze. An overview of the KL-ONE knowledge representation system. Cognitive Science. 1985
1985
-
[50]
Complexity results for nonmonotonic logics
Georg Gottlob. Complexity results for nonmonotonic logics. Journal of Logic and Computation. 1992
1992
-
[51]
2025 , howpublished =
Hugging Face , title =. 2025 , howpublished =
2025
-
[52]
arXiv preprint arXiv:2310.06825 , year=
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
-
[53]
arXiv preprint arXiv:1907.11692 , year=
RoBERTa: A Robustly Optimized BERT Pretraining Approach , author=. arXiv preprint arXiv:1907.11692 , year=
Pith/arXiv arXiv 1907
-
[54]
arXiv preprint arXiv:1910.01108 , year=
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter , author=. arXiv preprint arXiv:1910.01108 , year=
Pith/arXiv arXiv 1910
-
[55]
arXiv preprint arXiv:1911.02116 , year=
Unsupervised Cross-lingual Representation Learning at Scale , author=. arXiv preprint arXiv:1911.02116 , year=
Pith/arXiv arXiv 1911
-
[56]
arXiv preprint arXiv:1810.04805 , year=
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author=. arXiv preprint arXiv:1810.04805 , year=
-
[57]
Journal of Machine Learning Research , volume=
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer , author=. Journal of Machine Learning Research , volume=
-
[58]
arXiv preprint arXiv:2407.21783 , year=
The Llama 3 Herd of Models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[59]
Advances in Neural Information Processing Systems , volume=
Language Models are Few-Shot Learners , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
Hypertree Decompositions and Tractable Queries
Georg Gottlob and Nicola Leone and Francesco Scarcello. Hypertree Decompositions and Tractable Queries. Journal of Computer and System Sciences. 2002
2002
-
[61]
Levesque
Hector J. Levesque. Foundations of a functional approach to knowledge representation. Artificial Intelligence. 1984
1984
-
[62]
arXiv preprint arXiv:2310.01852 , year=
LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment , author=. arXiv preprint arXiv:2310.01852 , year=
-
[63]
arXiv preprint arXiv:2306.02858 , year =
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding , author =. arXiv preprint arXiv:2306.02858 , year =
-
[64]
arXiv preprint arXiv:2409.12191 , year=
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution , author=. arXiv preprint arXiv:2409.12191 , year=
-
[65]
Junnan Li and Dongxu Li and Silvio Savarese and Steven Hoi , year=
-
[66]
2022 , booktitle=
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation , author=. 2022 , booktitle=
2022
-
[67]
Levesque
Hector J. Levesque. A logic of implicit and explicit belief. Proceedings of the Fourth National Conference on Artificial Intelligence. 1984
1984
-
[68]
arXiv preprint arXiv:2405.17247 , year=
An introduction to vision-language modeling , author=. arXiv preprint arXiv:2405.17247 , year=
-
[69]
Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence , pages=
Integrating LLM, VLM, and Text-to-Image Models for Enhanced Information Graphics: A Methodology for Accurate and Visually Engaging Visualizations , author=. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence , pages=
-
[70]
Advances in Neural Information Processing Systems , volume=
Visogender: A dataset for benchmarking gender bias in image-text pronoun resolution , author=. Advances in Neural Information Processing Systems , volume=
-
[71]
arXiv preprint arXiv:2406.11069 , year=
WildVision: Evaluating Vision-Language Models in the Wild with Human Preferences , author=. arXiv preprint arXiv:2406.11069 , year=
-
[72]
Frontiers in Artificial Intelligence , volume=
Vision-language models for medical report generation and visual question answering: A review , author=. Frontiers in Artificial Intelligence , volume=. 2024 , publisher=
2024
-
[73]
On the compilability and expressive power of propositional planning formalisms
Bernhard Nebel. On the compilability and expressive power of propositional planning formalisms. Journal of Artificial Intelligence Research. 2000
2000
-
[74]
arXiv preprint arXiv:1909.11942 , year=
Albert: A lite bert for self-supervised learning of language representations , author=. arXiv preprint arXiv:1909.11942 , year=
Pith/arXiv arXiv 1909
-
[75]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[76]
Journal of Experimental Social Psychology , volume=
When what you say about others says something about you: Language abstraction and inferences about describers’ attitudes and goals , author=. Journal of Experimental Social Psychology , volume=. 2006 , publisher=
2006
-
[77]
Anthropological quarterly , pages=
Proverbs: Metaphors that teach , author=. Anthropological quarterly , pages=. 1988 , publisher=
1988
-
[78]
Western Folklore , volume=
Tensions in proverbs: more light on international understanding , author=. Western Folklore , volume=. 1956 , publisher=
1956
-
[79]
, author=
Proverbs and cultural models: An American psychology of problem solving. , author=. 1987 , publisher=
1987
-
[80]
The Journal of Experimental Education , volume=
Measuring relational reasoning , author=. The Journal of Experimental Education , volume=. 2016 , publisher=
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.