Deformable Tube Network for Action Detection in Videos
Pith reviewed 2026-05-25 10:38 UTC · model grok-4.3
The pith
Deformable action tubes generated by linking frame proposals outperform 3D cuboids in video action detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
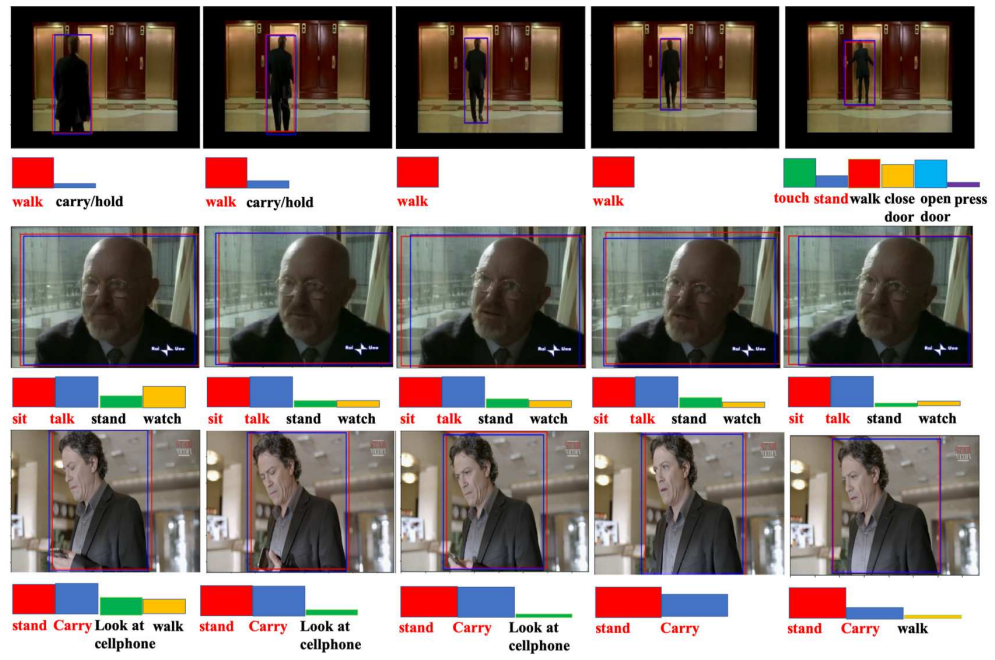
The Deformable Tube Network consists of a Deformation Tube Proposal Network that uses a fast proposal linking algorithm to connect region proposals across frames into multiple deformable action tube proposals, and a Deformable Tube Recognition Network that employs a 3D convolution network with skip connections to perform tube classification and regression. Modelling action proposals as deformable tubes allows explicit consideration of action tube shapes compared to 3D cuboids, and the 3D convolution network learns temporal dynamics sufficiently for action detection.
What carries the argument
Deformable action tube proposals generated by linking region proposals across frames using the fast proposal linking algorithm in the Deformation Tube Proposal Network.
If this is right
- Significantly outperforms methods using 3D cuboids for action detection.
- Achieves state-of-the-art results on the UCF-Sports dataset.
- Achieves state-of-the-art results on the AVA dataset.
- 3D convolution based recognition learns temporal dynamics for better detection.
Where Pith is reading between the lines
- If deformable tubes better capture varying shapes, similar linking methods could improve other video understanding tasks like object tracking.
- The approach may allow detection of actions with complex motions that rigid cuboids miss.
- Extending the fast linking algorithm to longer videos could test scalability.
Load-bearing premise
The fast proposal linking algorithm produces deformable tube proposals that accurately capture the varying shapes of actions across frames.
What would settle it
Running the detector on a new dataset with actions that change shape dramatically between frames and finding no improvement over 3D cuboid methods would challenge the claim.
Figures




read the original abstract
We address the problem of spatio-temporal action detection in videos. Existing methods commonly either ignore temporal context in action recognition and localization, or lack the modelling of flexible shapes of action tubes. In this paper, we propose a two-stage action detector called Deformable Tube Network (DTN), which is composed of a Deformation Tube Proposal Network (DTPN) and a Deformable Tube Recognition Network (DTRN) similar to the Faster R-CNN architecture. In DTPN, a fast proposal linking algorithm (FTL) is introduced to connect region proposals across frames to generate multiple deformable action tube proposals. To perform action detection, we design a 3D convolution network with skip connections for tube classification and regression. Modelling action proposals as deformable tubes explicitly considers the shape of action tubes compared to 3D cuboids. Moreover, 3D convolution based recognition network can learn temporal dynamics sufficiently for action detection. Our experimental results show that we significantly outperform the methods with 3D cuboids and obtain the state-of-the-art results on both UCF-Sports and AVA datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Deformable Tube Network (DTN), a two-stage detector analogous to Faster R-CNN, consisting of a Deformation Tube Proposal Network (DTPN) that employs a fast proposal linking (FTL) algorithm to connect per-frame region proposals into deformable action tube proposals, followed by a Deformable Tube Recognition Network (DTRN) that applies 3D convolutions with skip connections for tube classification and regression. The central claim is that explicitly modeling flexible tube shapes (rather than fixed 3D cuboids) combined with sufficient temporal modeling yields significant outperformance over cuboid-based methods and state-of-the-art results on the UCF-Sports and AVA datasets.
Significance. If the empirical claims are substantiated, the work would advance spatio-temporal action detection by replacing rigid cuboid proposals with deformable tubes that better accommodate varying action shapes across frames. The combination of proposal linking with 3D-convolutional recognition is a natural extension of existing two-stage detectors and could improve localization accuracy on benchmarks where actions exhibit non-rigid motion.
major comments (1)
- [Abstract] Abstract: the assertion that the method 'significantly outperform[s] the methods with 3D cuboids and obtain[s] the state-of-the-art results on both UCF-Sports and AVA datasets' supplies no quantitative metrics, baseline names, dataset splits, ablation results, or error bars. Because the paper's contribution is framed entirely as an empirical improvement, the absence of these supporting data is load-bearing for the central claim.
minor comments (1)
- [Abstract] Abstract: the description of the FTL linking step is limited to a single sentence; a brief statement of its computational complexity or linking criterion would clarify how the deformable tubes are generated before the reader reaches the methods section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The single major comment concerns the abstract's lack of supporting quantitative details for the empirical claims. We address this point below and agree that a revision to the abstract is warranted.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the method 'significantly outperform[s] the methods with 3D cuboids and obtain[s] the state-of-the-art results on both UCF-Sports and AVA datasets' supplies no quantitative metrics, baseline names, dataset splits, ablation results, or error bars. Because the paper's contribution is framed entirely as an empirical improvement, the absence of these supporting data is load-bearing for the central claim.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revised version we will update the abstract to report the primary frame-mAP numbers on UCF-Sports and AVA, the main competing baselines, and the standard dataset splits used. Space constraints preclude embedding full ablation tables or per-run error bars in the abstract; those results are already presented with full detail (including standard deviations where computed) in Section 4. This targeted revision will make the central empirical claim self-contained while preserving the abstract's readability. revision: partial
Circularity Check
No significant circularity; empirical claims rest on experiments
full rationale
The paper describes a two-stage neural architecture (DTPN with FTL linking to produce deformable tubes, followed by 3D-conv DTRN) whose central claims are empirical outperformance on UCF-Sports and AVA. No equations, first-principles derivations, or predictions appear that reduce to inputs by construction. Performance assertions are supported by reported results rather than self-referential fitting or self-citation chains. The work is self-contained as standard empirical CV research with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
fast proposal linking algorithm (FTL) ... deformable action tube proposals ... 3D convolution network with skip connections
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Modelling action proposals as deformable tubes explicitly considers the shape of action tubes compared to 3D cuboids
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
L. Cao, Z. Liu, and T. S. Huang. Cross-dataset action de- tection. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
-
[2]
Mxnet: A flexible and efficient machine learn- ing library for heterogeneous distributed systems
Tianqi Chen, Mu Li, Yutian Li, Min Lin, Naiyan Wang, Minjie Wang, Tianjun Xiao, Bing Xu, Chiyuan Zhang, and Zheng Zhang. Mxnet: A flexible and efficient machine learn- ing library for heterogeneous distributed systems. 2015
work page 2015
-
[3]
Actor-centric re- lation network
Carl V ondrick Kevin Murphy Rahul Sukthankar Chen Sun, Abhinav Shrivastava and Cordelia Schmid. Actor-centric re- lation network. In European Conference on Computer Vision (ECCV), 2018
work page 2018
-
[4]
Long-term recurrent convolutional net- works for visual recognition and description
Jeffrey Donahue, Lisa Anne Hendricks, Sergio Guadarrama, Marcus Rohrbach, Subhashini Venugopalan, Kate Saenko, and Trevor Darrell. Long-term recurrent convolutional net- works for visual recognition and description. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015. 4332
work page 2015
-
[5]
VideoCapsuleNet: A Simplified Network for Action Detection
Kevin Duarte, Yogesh Singh Rawat, and Mubarak Shah. Videocapsulenet: A simplified network for action detection. arXiv preprint arXiv:1805.08162, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Slowfast networks for video recognition
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. arXiv preprint arXiv:1812.03982, 2018
-
[7]
P. F. Felzenszwalb, R. B. Girshick, D. McAllester, and D. Ra- manan. Object detection with discriminatively trained part- based models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(9):1627–1645, 2010
work page 2010
-
[8]
Bottom-up segmentation for top-down detection
Sanja Fidler, Roozbeh Mottaghi, Alan Yuille, and Raquel Urtasun. Bottom-up segmentation for top-down detection. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2013
work page 2013
-
[9]
G. D. Forney. The viterbi algorithm. Proceedings of the IEEE, 61(3):268–278, 1973
work page 1973
-
[10]
K. Fu, Q. Zhao, and I. Y . Gu. Refinet: A deep segmen- tation assisted refinement network for salient object detec- tion. IEEE Transactions on Multimedia, 21(2):457–469, Feb 2019
work page 2019
-
[11]
Video action transformer network
Rohit Girdhar, Jo ˜ao Carreira, Carl Doersch, and Andrew Zis- serman. Video action transformer network. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019
work page 2019
-
[12]
Rich feature hierarchies for accurate object detec- tion and semantic segmentation
Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Rich feature hierarchies for accurate object detec- tion and semantic segmentation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014
work page 2014
-
[13]
Georgia Gkioxari and Jitendra Malik. Finding action tubes. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015
work page 2015
-
[14]
Chunhui Gu, Chen Sun, David A. Ross, Carl V on- drick, Caroline Pantofaru, Yeqing Li, Sudheendra Vijaya- narasimhan, George Toderici, Susanna Ricco, Rahul Suk- thankar, Cordelia Schmid, and Jitendra Malik. Ava: A video dataset of spatio-temporally localized atomic visual actions. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018
work page 2018
-
[15]
Ibrahim, Zhiwei Deng, and Greg Mori
Jiawei He, Mostafa S. Ibrahim, Zhiwei Deng, and Greg Mori. Generic tubelet proposals for action localization. The IEEE Winter Conference on Applications of Computer Vision (WACV), 2018
work page 2018
-
[16]
Kaiming He, Georgia Gkioxari, Piotr Dollar, and Ross Gir- shick. Mask r-cnn. In The IEEE International Conference on Computer Vision (ICCV), Oct 2017
work page 2017
-
[17]
Tube convolu- tional neural network (t-cnn) for action detection in videos
Rui Hou, Chen Chen, and Mubarak Shah. Tube convolu- tional neural network (t-cnn) for action detection in videos. In The IEEE International Conference on Computer Vision (ICCV), 2017
work page 2017
-
[18]
Action tubelet detector for spatio- temporal action localization
Vicky Kalogeiton, Philippe Weinzaepfel, Vittorio Ferrari, and Cordelia Schmid. Action tubelet detector for spatio- temporal action localization. InThe IEEE International Con- ference on Computer Vision (ICCV), 2017
work page 2017
-
[19]
Action Tubelet Detector for Spatio- Temporal Action Localization
Vicky Kalogeiton, Philippe Weinzaepfel, Vittorio Ferrari, and Cordelia Schmid. Action Tubelet Detector for Spatio- Temporal Action Localization. In The IEEE International Conference on Computer Vision (ICCV), 2017
work page 2017
-
[21]
Tian Lan, Yang Wang, and G. Mori. Discriminative figure- centric models for joint action localization and recogni- tion. In The International Conference on Computer Vision (ICCV), 2011
work page 2011
- [22]
-
[23]
I. Laptev and P. Perez. Retrieving actions in movies. In The IEEE International Conference on Computer Vision (ICCV), 2007
work page 2007
- [24]
-
[25]
Re- current tubelet proposal and recognition networks for action detection
Dong Li, Zhaofan Qiu, Qi Dai, Ting Yao, and Tao Mei. Re- current tubelet proposal and recognition networks for action detection. In Vittorio Ferrari, Martial Hebert, Cristian Smin- chisescu, and Yair Weiss, editors, European Conference on Computer Vision (ECCV), 2018
work page 2018
-
[26]
J. Li, X. Liang, J. Li, Y . Wei, T. Xu, J. Feng, and S. Yan. Mul- tistage object detection with group recursive learning. IEEE Transactions on Multimedia, 20(7):1645–1655, July 2018
work page 2018
-
[27]
Detnet: Design backbone for object detection
Zeming Li, Chao Peng, Gang Yu, Xiangyu Zhang, Yangdong Deng, and Jian Sun. Detnet: Design backbone for object detection. In The European Conference on Computer Vision (ECCV), 2018
work page 2018
-
[28]
Feature pyramid networks for object detection
Tsung-Yi Lin, Piotr Dollar, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , July 2017
work page 2017
-
[29]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollar. Focal loss for dense object detection. In The IEEE International Conference on Computer Vision (ICCV), Oct 2017
work page 2017
-
[30]
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C. Berg. Ssd: Single shot multibox detector. In European Con- ference on Computer Vision (ECCV), 2016
work page 2016
-
[31]
Multi-region two- stream r-cnn for action detection
Xiaojiang Peng and Cordelia Schmid. Multi-region two- stream r-cnn for action detection. In European Conference on Computer Vision (ECCV), 2016
work page 2016
-
[32]
Learning spatio- temporal representation with pseudo-3d residual networks
Zhaofan Qiu, Ting Yao, and Tao Mei. Learning spatio- temporal representation with pseudo-3d residual networks. In The IEEE International Conference on Computer Vision (ICCV), Oct 2017
work page 2017
-
[33]
You only look once: Unified, real-time object de- tection
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object de- tection. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
work page 2016
-
[34]
Faster R-CNN: Towards real-time object detection with re- 4333 gion proposal networks
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster R-CNN: Towards real-time object detection with re- 4333 gion proposal networks. In Advances in Neural Information Processing Systems (NIPS), 2015
work page 2015
-
[35]
M. D. Rodriguez, J. Ahmed, and M. Shah. Action mach a spatio-temporal maximum average correlation height filter for action recognition. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1–8, 2008
work page 2008
-
[36]
Recognizing fine-grained and composite ac- tivities using hand-centric features and script data
Marcus Rohrbach, Anna Rohrbach, Michaela Regneri, Sikandar Amin, Mykhaylo Andriluka, Manfred Pinkal, and Bernt Schiele. Recognizing fine-grained and composite ac- tivities using hand-centric features and script data. Interna- tional Journal of Computer Vision (IJCV) , 119(3):346–373, Sep 2016
work page 2016
-
[37]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Nassir Navab, Joachim Hornegger, William M. Wells, and Alejandro F. Frangi, editors, Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2015
work page 2015
-
[38]
Suman Saha, Gurkirt Singh, Michael Sapienza, Philip H. S. Torr, and Fabio Cuzzolin. Deep learning for detecting multi- ple space-time action tubes in videos. 2016
work page 2016
-
[39]
K. Simonyan and A. Zisserman. Two-stream convolutional networks for action recognition in videos. In Advances in Neural Information Processing Systems (NIPS), 2014
work page 2014
-
[40]
Online real time multiple spatiotempo- ral action localisation and prediction
Gurkirt Singh, Suman Saha, Michael Sapienza, Philip Torr, and Fabio Cuzzolin. Online real time multiple spatiotempo- ral action localisation and prediction. 2017
work page 2017
-
[41]
Khurram Soomro and Amir R. Zamir. Action Recognition in Realistic Sports Videos, pages 181–208. Springer Interna- tional Publishing, Cham, 2014
work page 2014
-
[42]
M. A. Tahir, F. Yan, P. Koniusz, M. Awais, M. Barnard, K. Mikolajczyk, A. Bouridane, and J. Kittler. A robust and scalable visual category and action recognition system using kernel discriminant analysis with spectral regression. IEEE Transactions on Multimedia, 15(7):1653–1664, Nov 2013
work page 2013
-
[43]
A closer look at spatiotemporal convolutions for action recognition
Du Tran, Heng Wang, Lorenzo Torresani, Jamie Ray, Yann LeCun, and Manohar Paluri. A closer look at spatiotemporal convolutions for action recognition. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , June 2018
work page 2018
-
[44]
J. R. R. Uijlings, K. E. A. van de Sande, T. Gevers, and A. W. M. Smeulders. Selective search for object recog- nition. International Journal of Computer Vision (IJCV) , 104(2):154–171, Sep 2013
work page 2013
-
[45]
Action recognition with improved trajectories
Heng Wang and Cordelia Schmid. Action recognition with improved trajectories. In The IEEE International Conference on Computer Vision (ICCV), 2013
work page 2013
-
[46]
Regionlets for generic object detection
Xiaoyu Wang, Ming Yang, Shenghuo Zhu, and Yuanqing Lin. Regionlets for generic object detection. In The IEEE International Conference on Computer Vision (ICCV) , De- cember 2013
work page 2013
-
[47]
Learning to track for spatio-temporal action local- ization
Philippe Weinzaepfel, Zaid Harchaoui, and Cordelia Schmid. Learning to track for spatio-temporal action local- ization. In The IEEE International Conference on Computer Vision (ICCV), 2015
work page 2015
-
[48]
Long-Term Feature Banks for Detailed Video Understanding
Chao-Yuan Wu, Christoph Feichtenhofer, Haoqi Fan, Kaim- ing He, Philipp Kr¨ahenb¨uhl, and Ross Girshick. Long-Term Feature Banks for Detailed Video Understanding. In The IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2019
work page 2019
- [49]
-
[50]
X. Zhen, F. Zheng, L. Shao, X. Cao, and D. Xu. Supervised local descriptor learning for human action recognition.IEEE Transactions on Multimedia, 19(9):2056–2065, Sep. 2017. 4334
work page 2056
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.