Text-to-Image Models Need Less from Text Encoders Than You Think
Pith reviewed 2026-06-28 11:06 UTC · model grok-4.3
The pith
Text-to-image diffusion transformer models generate high-quality images guided only by individual word meanings and their order.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
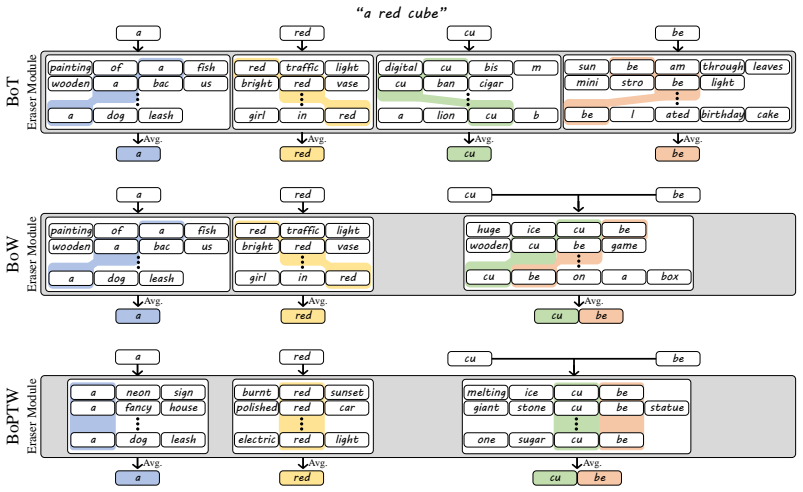
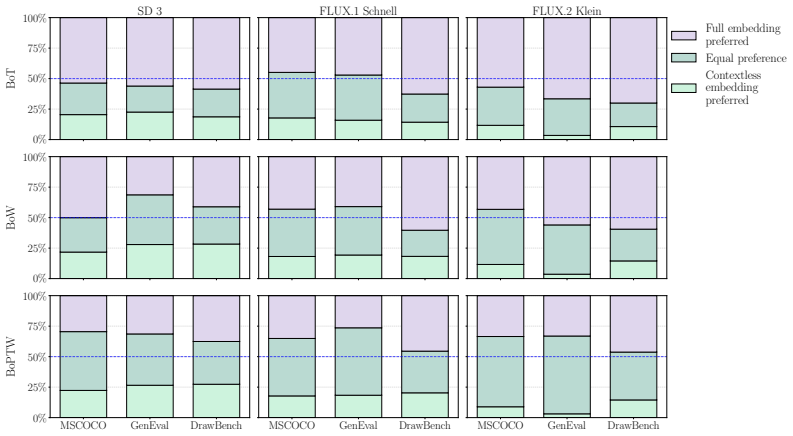
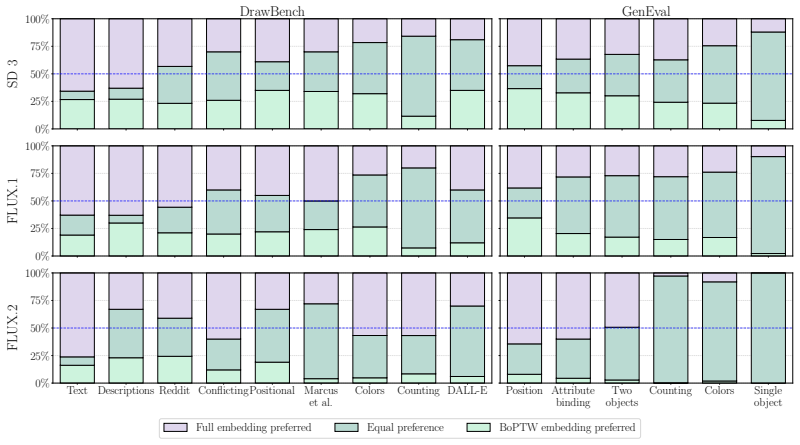
Text-to-image diffusion transformer-based models commonly rely only on two relatively straightforward aspects of text representations: the merging of adjacent tokens into a word representation for words spanning multiple tokens, and word order, which is imprinted by the positional embedding of the text-encoder. A new text embedding that encodes only individual word meanings and order but lacks any contextual information about the full prompt is sufficient to guide image generation, achieving visual quality and text fidelity on par with full text embedding-guided generation. This demonstrates that the models often do not use the rich information encoded in the text embedding beyond individual
What carries the argument
The bag of position-tagged words representation, which collapses multi-token words and keeps only positional order signals while removing all cross-word contextual information from the prompt.
If this is right
- The image-generation network itself performs the decoding of complex linguistic structures such as compositionality and attribute binding.
- Text encoders do not need to supply contextual information across the full prompt for effective conditioning of these models.
- Merging adjacent tokens into word units and preserving word order are the only text-encoder features required for competitive generation quality.
- Simpler, context-free text representations can replace richer embeddings without measurable loss in visual quality or prompt fidelity.
Where Pith is reading between the lines
- Designers could explore training or fine-tuning image models on even lighter text inputs to reduce encoder complexity.
- The result raises the question of whether similar minimal representations would suffice in other conditional generation settings such as text-to-video.
- Interpretability work could now isolate which layers inside the image model are responsible for reassembling word order into scene structure.
- Prompt engineering might shift focus toward ensuring clear word sequences rather than crafting elaborate contextual phrasing.
Load-bearing premise
The constructed bag-of-position-tagged-words embedding truly encodes only individual word meanings and order but lacks any contextual information about the full prompt.
What would settle it
Running the same set of complex prompts through both the full text embedding and the bag-of-position-tagged-words embedding and finding that the latter produces visibly poorer attribute binding or compositional accuracy would falsify the claim.
Figures





read the original abstract
Text-to-image models rely on text prompts as their primary interface to human intent. Prompts are encoded by a text encoder into embeddings that condition the image generation process. Beyond individual token meanings, text embeddings encode contextual information across the full prompt, such as compositionality and attribute binding. However, whether image models actually exploit this richer information remains underexplored. Here, we address the question: Which aspects of text representation are essential for image generation? We show that text-to-image diffusion transformer-based models commonly rely only on two relatively straightforward aspects of text representations: (i) the merging of adjacent tokens into a word representation, for words spanning multiple tokens, and (ii) word order, which is imprinted by the positional embedding of the text-encoder. To show this, we construct a new text embedding that encodes only individual word meanings and order but lacks any contextual information about the full prompt. We find that this bag of position-tagged words representation is sufficient to successfully guide image generation, achieving visual quality and text fidelity that are on par with full text embedding-guided generation. This demonstrates that, contrary to common belief, text-to-image models often do not use the rich information encoded in the text embedding beyond individual word meanings and word order. Instead, the decoding of complex linguistic structures is performed by the image model itself. Project webpage: https://nsping13.github.io/contextless-TTI/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that text-to-image diffusion transformer models rely primarily on two aspects of text representations: merging of adjacent tokens into word representations and word order via positional embeddings. The authors construct a 'bag of position-tagged words' embedding that encodes only individual word meanings and order without full-prompt contextual information (e.g., compositionality or attribute binding from cross-token attention in the text encoder). They report that this reduced representation guides image generation with visual quality and text fidelity on par with full text embeddings, implying that the image model itself performs the decoding of complex linguistic structures.
Significance. If substantiated, the result would meaningfully revise understanding of the division of labor in T2I systems by showing that rich contextual encoding from text encoders is often not exploited by the image model. The explicit construction isolating per-word outputs plus positional information is a methodological strength that directly targets the question of what information is load-bearing.
major comments (1)
- [Abstract / Experiments] The central claim of on-par performance is load-bearing for the conclusion yet the provided abstract (and any corresponding results section) supplies no details on evaluation metrics, baselines, statistical significance, number of prompts or images evaluated, or controls for confounding factors such as prompt selection.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's significance and methodological contribution. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract / Experiments] The central claim of on-par performance is load-bearing for the conclusion yet the provided abstract (and any corresponding results section) supplies no details on evaluation metrics, baselines, statistical significance, number of prompts or images evaluated, or controls for confounding factors such as prompt selection.
Authors: We agree that the abstract is high-level and does not enumerate the concrete evaluation protocol. The Experiments section of the manuscript does describe the metrics (FID for visual quality and CLIP-based text alignment), the prompt sets used, and direct comparison to the unmodified text-encoder baseline. However, explicit statements of sample size, statistical significance testing, and prompt-selection controls are not as prominently listed as they should be. We will revise both the abstract (to include the key quantitative results and evaluation scope) and the Experiments section (to add a dedicated paragraph on sample sizes, significance testing, and controls) so that the central claim is fully substantiated in the text. revision: yes
Circularity Check
Empirical construction is self-contained; no circular reduction
full rationale
The paper's core contribution is an explicit construction of a 'bag of position-tagged words' embedding that isolates per-word meanings plus positional order while removing cross-token context from the text encoder. Performance is then measured empirically against full embeddings on image generation quality. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce the sufficiency claim to a definitional tautology. The construction directly targets the weakest assumption and the result follows from the comparison rather than from any internal loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Claude sonnet 4.5
Anthropic. Claude sonnet 4.5. https://www.anthropic.com/, 2025. Large language model
2025
-
[2]
Mikołaj Bi´nkowski, Danica J Sutherland, Michael Arbel, and Arthur Gretton. Demystifying mmd gans.arXiv preprint arXiv:1801.01401, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts
Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3558–3568, 2021
2021
-
[4]
Hila Chefer, Omer Tov, Roni Paiss, Lior Wolf, et al. Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models.arXiv preprint arXiv:2301.13826, 2023
-
[5]
Vision language models learn to assess images with specialists
Quyet V Do, Seunghyun Yoon, Ruiyi Zhang, Thiloshon Nagarajah, Trung Bui, and Viet Dac Lai. Vision language models learn to assess images with specialists. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1126–1135, 2026
2026
-
[6]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[7]
Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
2023
-
[8]
Prompt-to-Prompt Image Editing with Cross Attention Control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Sugarcrepe: Fixing compositionality in vision-language models
Jack Hessel, Youngjae Yu, Yejin Kwon, and Yejin Choi. Sugarcrepe: Fixing compositionality in vision-language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[10]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[11]
A structural probe for finding syntax in word representations
John Hewitt and Christopher D Manning. A structural probe for finding syntax in word representations. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4129–4138, 2019
2019
-
[12]
What does bert learn about the structure of language? InProceedings of the 57th annual meeting of the association for computational linguistics, pages 3651–3657, 2019
Ganesh Jawahar, Benoît Sagot, and Djamé Seddah. What does bert learn about the structure of language? InProceedings of the 57th annual meeting of the association for computational linguistics, pages 3651–3657, 2019
2019
-
[13]
Albert Q. Jiang et al. Mistral 7b.arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Flux.1: A family of text-to-image models
Black Forest Labs. Flux.1: A family of text-to-image models. Technical Report, 2024
2024
-
[15]
FLUX.2: Frontier Visual Intelligence
Black Forest Labs. FLUX.2: Frontier Visual Intelligence. https://bfl.ai/blog/flux-2, 2025
2025
-
[16]
Prometheus-vision: Vision-language model as a judge for fine-grained evaluation
Seongyun Lee, Seungone Kim, Sue Park, Geewook Kim, and Minjoon Seo. Prometheus-vision: Vision-language model as a judge for fine-grained evaluation. InFindings of the Association for Computational Linguistics: ACL 2024, pages 11286–11315, 2024. 10
2024
-
[17]
Vhelm: A holistic evaluation of vision language models.Advances in Neural Information Processing Systems, 37:140632–140666, 2024
Tony Lee, Haoqin Tu, Chi H Wong, Wenhao Zheng, Yiyang Zhou, Yifan Mai, Josselin S Roberts, Michihiro Yasunaga, Huaxiu Yao, Cihang Xie, et al. Vhelm: A holistic evaluation of vision language models.Advances in Neural Information Processing Systems, 37:140632–140666, 2024
2024
-
[18]
Yujin Li et al. Deleaker: Improving text-to-image diffusion models via deletion and leakage control.arXiv preprint arXiv:2310.00000, 2023
-
[19]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[20]
Understanding the limitations of clip for compositionality.arXiv preprint arXiv:2305.00000, 2023
Sahil Palit et al. Understanding the limitations of clip for compositionality.arXiv preprint arXiv:2305.00000, 2023
-
[21]
Emergence of hidden capabilities: Exploring learning dynamics in concept space.Advances in Neural Information Processing Systems, 37:84698–84729, 2024
Core F Park, Maya Okawa, Andrew Lee, Hidenori Tanaka, and Ekdeep S Lubana. Emergence of hidden capabilities: Exploring learning dynamics in concept space.Advances in Neural Information Processing Systems, 37:84698–84729, 2024
2024
-
[22]
Yuang Peng, Yuxin Cui, Haomiao Tang, Zekun Qi, Runpei Dong, Jing Bai, Chunrui Han, Zheng Ge, Xiangyu Zhang, and Shu-Tao Xia. Dreambench++: A human-aligned benchmark for personalized image generation.arXiv preprint arXiv:2406.16855, 2024
-
[23]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Learning transferable visual models from natural language supervision.Proceedings of the International Conference on Machine Learning (ICML), 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, et al. Learning transferable visual models from natural language supervision.Proceedings of the International Conference on Machine Learning (ICML), 2021
2021
-
[25]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, et al. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2020
2020
-
[26]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[27]
High-resolution image synthesis with latent diffusion models.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
Robin Rombach, Andreas Blattmann, Dominik Lorenz, et al. High-resolution image synthesis with latent diffusion models.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[28]
Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
2022
-
[29]
Raphael Tang, Yixuan Zhang, et al. What the daam: Interpreting stable diffusion using cross attention.arXiv preprint arXiv:2210.04885, 2023
-
[30]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Bert rediscovers the classical nlp pipeline
Ian Tenney, Dipanjan Das, and Ellie Pavlick. Bert rediscovers the classical nlp pipeline. In Proceedings of the 57th annual meeting of the association for computational linguistics, pages 4593–4601, 2019
2019
-
[32]
Ego4d: Around the world in 3, 000 hours of egocentric video
Tristan Thrush, Ryan Jiang, Max Bartolo, Amanpreet Singh, Adina Williams, Douwe Kiela, and Candace Ross. Winoground: Probing vision and language models for visio-linguistic compositionality. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5228–5238, 2022. doi: 10.1109/CVPR52688.2022.00517. 11
-
[33]
Diffusion lens: Interpreting text encoders in text-to-image pipelines
Michael Toker, Hadas Orgad, Mor Ventura, Dana Arad, and Yonatan Belinkov. Diffusion lens: Interpreting text encoders in text-to-image pipelines. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), pages 9713–9728, 2024. doi: 10.18653/v1/2024.acl-long.524
-
[34]
Circuit Mechanisms for Spatial Relation Generation in Diffusion Transformers
Binxu Wang, Jingxuan Fan, and Xu Pan. Circuit mechanisms for spatial relation generation in diffusion transformers.arXiv preprint arXiv:2601.06338, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Scaling down text encoders of text-to- image diffusion models
Lifu Wang, Daqing Liu, Xinchen Liu, and Xiaodong He. Scaling down text encoders of text-to- image diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18424–18433, 2025
2025
-
[36]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
When and why vision-language models behave like bags-of-words, and what to do about it
Mert Yuksekgonul, Federico Bianchi, Pratyusha Kalluri, Dan Jurafsky, and James Zou. When and why vision-language models behave like bags-of-words, and what to do about it. In International Conference on Learning Representations (ICLR), 2023
2023
-
[38]
a red cube
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023. 12 Appendix A Additional Results A.1 Encoding positional information in the text embedding T...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.