Kuramoto Attention: Synchronizing Self-Attention on the Torus
Pith reviewed 2026-06-29 05:05 UTC · model grok-4.3
The pith
Kuramoto Attention turns the self-attention value update into an exact synchronization step on high-dimensional toroidal phase states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By representing hidden states as phases on a high-dimensional torus and using attention weights to select which oscillators couple, the value update becomes precisely the Kuramoto synchronization direction for fixed attention weights; the softmax chooses the coupling partners while the value path moves each token toward the attention-weighted circular mean of the selected phases.
What carries the argument
The Kuramoto coupling direction on raw phase states, where attention weights form the coupling graph and the value path computes the synchronization step toward the weighted circular mean.
If this is right
- At 5M parameters the layer improves mean validation and test bits-per-byte by 0.012 and 0.010 on CodeParrot relative to matched RoPE and SwiGLU transformers.
- On enwiki8 at 5M parameters all six runs produce lower median validation and test scores than the transformer baseline.
- At 1M parameters the layer trails the transformer by roughly 0.02 BPC on enwiki8 and 0.013-0.015 bits per byte on CodeParrot.
- Ablations isolate the contributions of the synchronization rule and the toroidal geometry to the measured performance differences.
- The learned computation inside the layer can be read directly as adaptive synchronization among phase oscillators.
Where Pith is reading between the lines
- The same construction could be applied to tasks that benefit from explicit coordination, such as multi-agent modeling or structured prediction.
- Phase diagnostics already present in the paper could be extended to measure how synchronization strength correlates with downstream task structure.
- If the toroidal representation proves stable under scaling, it offers a route to parameter-efficient models that embed dynamical priors rather than learning them from scratch.
- The explicit mapping from attention weights to coupling strengths supplies a new lens for interpreting attention patterns in existing transformers.
Load-bearing premise
A high-dimensional toroidal phase representation together with the Kuramoto update rule supplies a trainable inductive bias that is not reducible to standard attention and can be stably optimized by gradient descent on the reported tasks.
What would settle it
If replacing the phase states with ordinary vector values while preserving the rest of the layer architecture eliminates the observed performance gaps on CodeParrot and enwiki8, the claim that the synchronization mechanism itself supplies the benefit would be falsified.
Figures

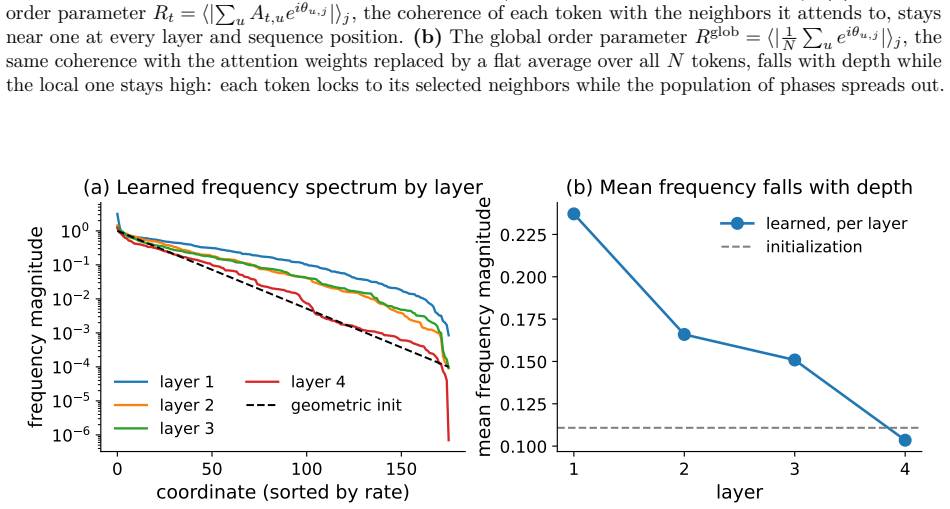
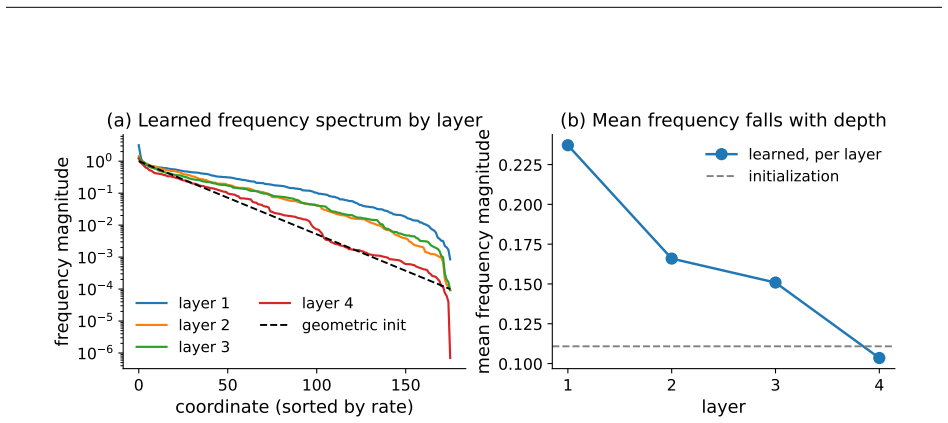
read the original abstract
Transformer models are increasingly used as computational models of cognition and neural representation, so the mechanism implemented by self-attention is of interest beyond engineering performance. A complementary tradition in cognitive science models coordination, binding, and memory through dynamical interactions such as oscillator synchrony; we bring this mechanism into self-attention by introducing the Kuramoto Attention layer, whose value update is a synchronization step. Each token carries a bank of phase oscillators, so its hidden state lives on a high-dimensional torus. The attention weights form an adaptive coupling graph, and using the raw phase states as values makes the value update exactly the Kuramoto coupling direction for fixed attention weights. The softmax selects which oscillators couple, while the value path moves each token toward the attention-weighted circular mean of the tokens it selects. We train Kuramoto Attention on enwiki8 and CodeParrot against parameter-matched RoPE and SwiGLU transformers. At 5M parameters on CodeParrot, it improves on the transformer by both median and mean, with mean gaps of 0.012 validation and 0.010 test bits per byte. At 5M on enwiki8, all six runs have lower validation/test medians than the transformer and all-seed means within 0.01 BPC; five of six also form a tight lower-mean cluster. At 1M, it trails by about 0.02 BPC on enwiki8 and by 0.013-0.015 bits per byte on CodeParrot. Ablations and phase diagnostics show how the layer's synchronization and geometry-motivated components shape model performance. The result is a self-attention mechanism whose learned computation can be read directly as adaptive synchronization on phase states.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Kuramoto Attention, a self-attention variant in which each token maintains a bank of phase oscillators on a high-dimensional torus. Attention weights define an adaptive coupling graph, and the value update is constructed so that, for fixed weights, it exactly implements the Kuramoto synchronization step toward the attention-weighted circular mean. On language modeling, parameter-matched comparisons at 5M parameters show mean BPC gains of 0.012 (validation) and 0.010 (test) on CodeParrot and consistent median advantages on enwiki8 across six runs; the model trails the baseline at 1M parameters. Ablations and phase diagnostics are provided to link performance to the synchronization geometry.
Significance. If the reported gains prove robust and the toroidal Kuramoto update supplies a non-reducible inductive bias, the work would supply a concrete dynamical-systems interpretation of attention that could be useful for cognitive modeling of coordination and binding. The use of six independent seeds with explicit directional consistency and direct BPC comparisons against RoPE/SwiGLU baselines is a positive feature that strengthens the empirical foundation.
major comments (3)
- [Results section (CodeParrot and enwiki8 tables)] Results section (CodeParrot and enwiki8 tables): mean gaps of 0.012/0.010 BPC are presented without standard deviations, confidence intervals, or hypothesis tests across the six runs. Because the central performance claim rests on these small differences, the absence of statistical characterization is load-bearing for assessing whether the improvement is reliable.
- [Layer definition and ablation discussion] Layer definition and ablation discussion: the claim that the high-dimensional phase bank plus Kuramoto value update supplies a trainable inductive bias distinct from standard attention is central, yet the model underperforms the baseline by 0.013–0.02 BPC at 1M parameters. This scale dependence requires explicit analysis (e.g., an ablation isolating the synchronization step from the added phase parameters) to support non-reducibility.
- [Mechanism section] Mechanism section: while the abstract states that using raw phase states as values makes the update exactly the Kuramoto coupling direction for fixed attention weights, the manuscript does not provide the explicit derivation or the precise parameterization of the phase bank (initialization, dimensionality, and gradient flow on the torus). This detail is load-bearing for the claim that the computation can be read directly as adaptive synchronization.
minor comments (2)
- [Abstract and results text] The abstract and results text refer to “all six runs lower median” and “five of six form a tight lower-mean cluster” without tabulating the per-seed values or variance; adding a supplementary table of individual run BPCs would improve transparency.
- Notation for the torus dimension and the mapping from hidden state to phase oscillators is introduced without an explicit equation linking the two; a single clarifying equation would reduce ambiguity.
Simulated Author's Rebuttal
Thank you for the detailed and constructive review. We appreciate the recognition of the empirical setup with multiple seeds and the potential implications for dynamical-systems interpretations of attention. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Results section (CodeParrot and enwiki8 tables): mean gaps of 0.012/0.010 BPC are presented without standard deviations, confidence intervals, or hypothesis tests across the six runs. Because the central performance claim rests on these small differences, the absence of statistical characterization is load-bearing for assessing whether the improvement is reliable.
Authors: We agree that reporting variability measures would better support interpretation of the small mean gaps. In the revised manuscript we will add standard deviations across the six seeds to all reported means in the CodeParrot and enwiki8 tables, along with a short discussion of directional consistency. revision: yes
-
Referee: Layer definition and ablation discussion: the claim that the high-dimensional phase bank plus Kuramoto value update supplies a trainable inductive bias distinct from standard attention is central, yet the model underperforms the baseline by 0.013–0.02 BPC at 1M parameters. This scale dependence requires explicit analysis (e.g., an ablation isolating the synchronization step from the added phase parameters) to support non-reducibility.
Authors: The manuscript already reports the 1M-scale results. To supply the requested explicit analysis, we will add an ablation that retains the phase bank but replaces the Kuramoto synchronization update with a parameter-matched linear projection, run at both 1M and 5M scales, to isolate the synchronization component's contribution. revision: yes
-
Referee: Mechanism section: while the abstract states that using raw phase states as values makes the update exactly the Kuramoto coupling direction for fixed attention weights, the manuscript does not provide the explicit derivation or the precise parameterization of the phase bank (initialization, dimensionality, and gradient flow on the torus). This detail is load-bearing for the claim that the computation can be read directly as adaptive synchronization.
Authors: We will add a dedicated derivation subsection showing that the value update exactly implements the Kuramoto coupling direction for fixed weights. We will also specify the phase bank: D-dimensional phases per token (D = hidden dimension), initialized uniformly on [0, 2π)^D, with gradients flowing via standard backpropagation on the real-valued phase variables (torus geometry enforced only in the circular-mean computation). revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper constructs the Kuramoto Attention layer by explicit design choice so that the value update matches the Kuramoto coupling direction when phases are used as values; this equivalence is stated as definitional rather than derived from independent premises. No load-bearing step reduces a claimed prediction or uniqueness result to a fitted parameter, self-citation chain, or ansatz imported from prior author work. Performance claims rest on direct empirical comparisons against parameter-matched RoPE/SwiGLU baselines on enwiki8 and CodeParrot, which are externally falsifiable and do not involve renaming known results or calling fitted inputs predictions. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Softmax produces valid coupling strengths for the Kuramoto graph.
- domain assumption Phase states on the torus remain trainable under standard gradient descent without additional stabilization.
invented entities (1)
-
Bank of phase oscillators per token on a high-dimensional torus
no independent evidence
Reference graph
Works this paper leans on
-
[1]
International Symposium on Mathematical Problems in Theoretical Physics , pages=
Self-entrainment of a population of coupled non-linear oscillators , author=. International Symposium on Mathematical Problems in Theoretical Physics , pages=. 1975 , publisher=
1975
-
[2]
Acebr. The. Reviews of Modern Physics , volume=
-
[3]
Advances in Neural Information Processing Systems , year=
Attention is all you need , author=. Advances in Neural Information Processing Systems , year=
-
[4]
Su, Jianlin and Lu, Yu and Pan, Shengfeng and Murtadha, Ahmed and Wen, Bo and Liu, Yunfeng , journal=
-
[5]
Advances in Neural Information Processing Systems , year=
The emergence of clusters in self-attention dynamics , author=. Advances in Neural Information Processing Systems , year=
-
[6]
A mathematical perspective on transformers.arXiv preprint arXiv:2312.10794, 2023
A mathematical perspective on transformers , author=. arXiv preprint arXiv:2312.10794 , year=
-
[7]
Artificial
Miyato, Takeru and L. Artificial. International Conference on Learning Representations , year=
-
[8]
Communications Biology , volume=
Brains and algorithms partially converge in natural language processing , author=. Communications Biology , volume=. 2022 , doi=
2022
-
[9]
Nature Neuroscience , volume=
Shared computational principles for language processing in humans and deep language models , author=. Nature Neuroscience , volume=. 2022 , doi=
2022
-
[10]
Nature Communications , volume=
Shared functional specialization in transformer-based language models and the human brain , author=. Nature Communications , volume=. 2024 , doi=
2024
-
[11]
Nature Reviews Neuroscience , volume=
Cortical travelling waves: mechanisms and computational principles , author=. Nature Reviews Neuroscience , volume=. 2018 , doi=
2018
-
[12]
International Conference on Learning Representations , year=
Hopfield networks is all you need , author=. International Conference on Learning Representations , year=
-
[13]
Hutter, Marcus , year=. The
-
[14]
2022 , howpublished=
2022
-
[15]
International Conference on Machine Learning , year=
Unitary evolution recurrent neural networks , author=. International Conference on Machine Learning , year=
-
[16]
Layer normalization , author=. arXiv preprint arXiv:1607.06450 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Advances in Neural Information Processing Systems , year=
Root mean square layer normalization , author=. Advances in Neural Information Processing Systems , year=
-
[18]
Loshchilov, Ilya and Hsieh, Cheng-Ping and Sun, Simeng and Ginsburg, Boris , journal=
-
[19]
Optimization Algorithms on Matrix Manifolds , author=
-
[20]
Convex Optimization , author=
-
[21]
Enhancing deep neural networks through complex-valued representations and
Muzellec, Sabine and Alamia, Andrea and Serre, Thomas and VanRullen, Rufin , journal=. Enhancing deep neural networks through complex-valued representations and
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.