SATURN: Symbolic Spatial Reasoning for Multi-Perspective Grounding
Pith reviewed 2026-06-26 10:37 UTC · model grok-4.3
The pith
SATURN separates perception from reasoning via approximate 3D reconstruction and soft perspective-aware predicates to compose multi-view spatial relations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
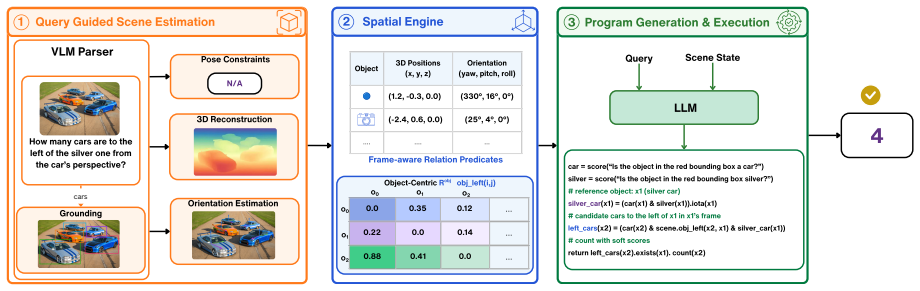
SATURN reconstructs an approximate 3D scene, derives soft perspective-aware spatial predicates, and composes them with a training-free Pythonic symbolic executor, separating perception from reasoning while preserving uncertainty through multi-hop inference.
What carries the argument
Approximate 3D scene reconstruction plus soft perspective-aware spatial predicates executed by a training-free symbolic Python executor.
If this is right
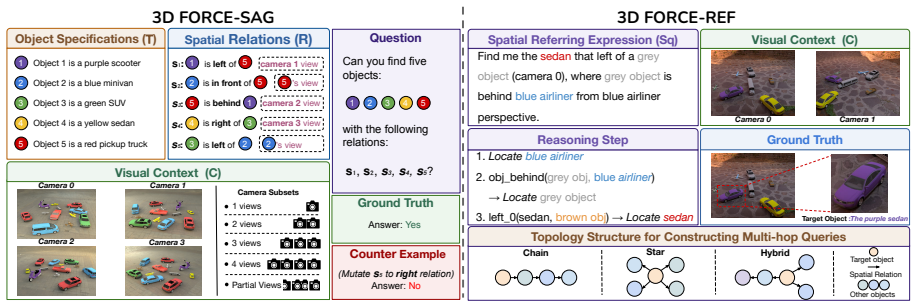
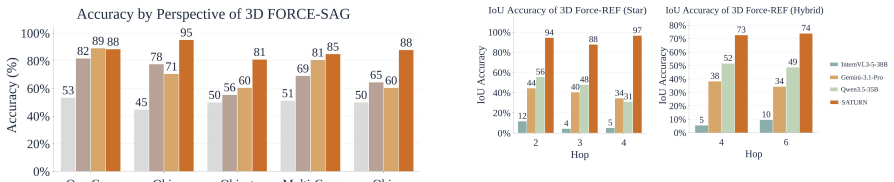
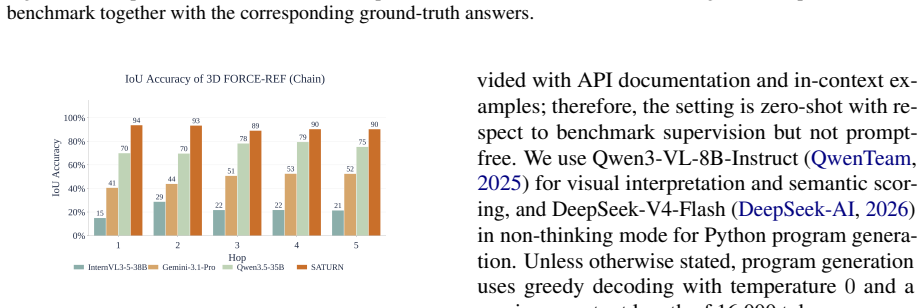
- SATURN remains stable on 3D FORCE while VLMs and spatially trained models degrade as depth and perspective complexity increase.
- SATURN reaches 78.57 percent overall accuracy on MindCube and exceeds the strongest baseline by 14 percentage points.
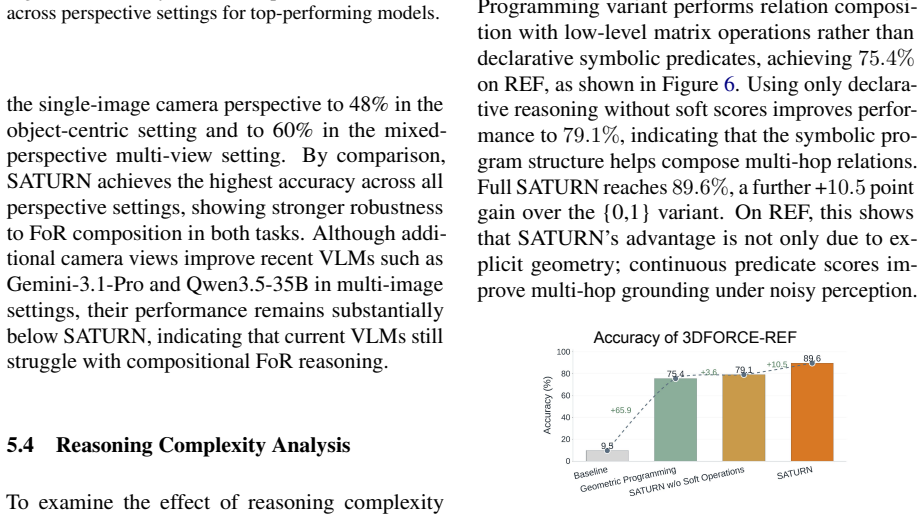
- Soft predicates avoid the need for hard geometric thresholds that break under noisy perception.
- The Pythonic symbolic executor allows training-free composition of relations across multiple hops.
Where Pith is reading between the lines
- The same separation of soft perception and symbolic execution could be applied to temporal or causal reasoning tasks that also require frame-of-reference shifts.
- If the 3D reconstruction step is replaced by another perception front-end that outputs comparable soft predicates, the rest of the pipeline should transfer without retraining.
- A direct test would measure whether the method still works when input images contain significant occlusion or lighting variation that affects 3D reconstruction quality.
Load-bearing premise
Approximate 3D scene reconstruction plus soft perspective-aware predicates are sufficient to preserve uncertainty and support reliable multi-hop inference without brittle geometric decisions or hard thresholds.
What would settle it
SATURN accuracy falling below the strongest baseline on a new test set that adds one more layer of perspective composition or reasoning depth beyond the 3D FORCE configurations.
Figures



read the original abstract
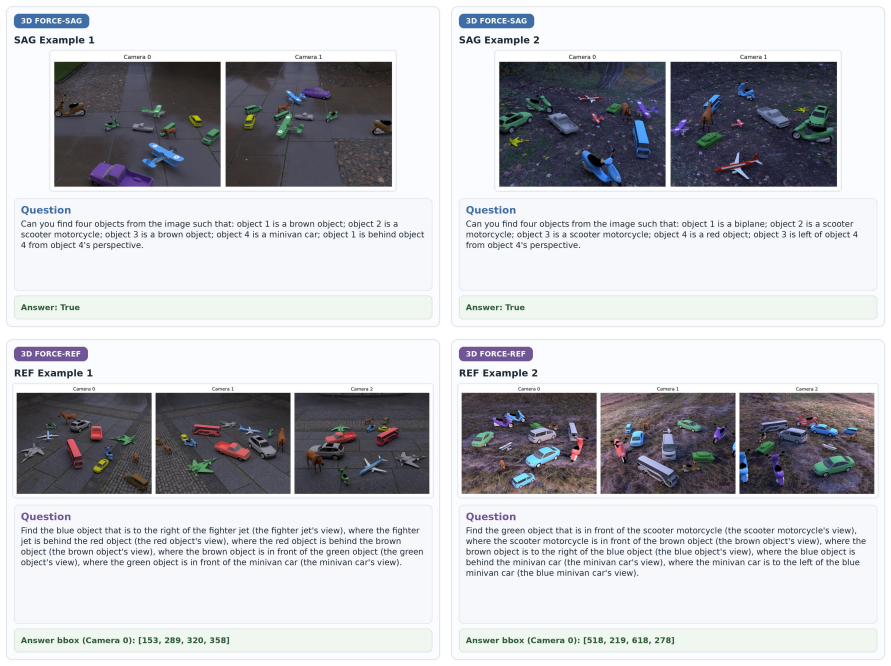
Vision-Language Models (VLMs) remain unreliable when spatial reasoning requires composing relations whose meanings depend on frames of reference. Existing neuro-symbolic methods make reasoning more explicit, but often depend on brittle geometric procedures and hard decisions over noisy perception. We propose SATURN, a neuro-symbolic framework for perspective-aware compositional spatial reasoning. SATURN reconstructs an approximate 3D scene, derives soft perspective-aware spatial predicates, and composes them with a training-free Pythonic symbolic executor, separating perception from reasoning while preserving uncertainty through multi-hop inference. We also introduce 3D FORCE, a diagnostic benchmark that controls reasoning depth, view, and perspective composition across spatial arrangement grounding (SAG) and referring expression grounding (REF). On 3D FORCE, VLMs and spatially trained models degrade sharply as depth and perspective complexity increase, whereas SATURN remains stable and outperforms strong baselines. On the real-world MindCube benchmark, SATURN achieves 78.57% overall accuracy, outperforming the strongest baseline by 14 pp.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SATURN, a neuro-symbolic framework for multi-perspective spatial reasoning that reconstructs an approximate 3D scene, derives soft perspective-aware predicates, and composes them via a training-free Pythonic symbolic executor. It also presents the 3D FORCE benchmark, which varies reasoning depth, view, and perspective composition for spatial arrangement grounding (SAG) and referring expression grounding (REF) tasks. Experiments claim that SATURN remains stable and outperforms VLMs and spatially trained baselines as depth and perspective complexity increase on 3D FORCE, while achieving 78.57% accuracy on the real-world MindCube benchmark (14 pp above the strongest baseline).
Significance. If the central claims hold, the work offers a concrete mechanism for separating noisy perception from reasoning while propagating uncertainty through soft predicates and multi-hop symbolic execution. The training-free executor and the controlled 3D FORCE benchmark (explicitly varying depth and perspective) are notable strengths that directly target documented failure modes of brittle geometry in existing neuro-symbolic and VLM approaches. Successful reproduction would provide both a practical method and a diagnostic testbed for compositional spatial reasoning.
major comments (2)
- [Results] Results section (performance tables on 3D FORCE and MindCube): reported accuracies (including the 78.57% overall and 14 pp gain) are given without error bars, standard deviations across runs, or statistical significance tests. This directly affects the load-bearing claim of stability and outperformance as depth and perspective complexity increase.
- [Section 3] Section 3 (method) and experimental setup: no ablation is reported that isolates the contribution of the soft predicate derivation versus the symbolic executor, nor any verification that the approximate 3D reconstruction step does not introduce systematic bias in the multi-hop inferences. These omissions leave the weakest assumption untested in the presented evidence.
minor comments (3)
- [Abstract] Abstract and §4: the description of 3D FORCE would benefit from an explicit statement of the number of scenes, views per scene, and exact composition of perspective relations tested.
- [Section 3.2] Notation in §3.2: the definition of soft perspective-aware predicates should include a short example of how a predicate value is computed from the reconstructed 3D coordinates for a given reference frame.
- [Figure 2] Figure 2 (pipeline diagram): the arrow from 3D reconstruction to predicate derivation should be labeled with the uncertainty propagation mechanism to match the textual claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Results] Results section (performance tables on 3D FORCE and MindCube): reported accuracies (including the 78.57% overall and 14 pp gain) are given without error bars, standard deviations across runs, or statistical significance tests. This directly affects the load-bearing claim of stability and outperformance as depth and perspective complexity increase.
Authors: We agree that error bars and statistical tests would strengthen the results. SATURN's symbolic executor is deterministic given fixed inputs from the perception stage, so its outputs do not vary across runs. For the stochastic VLM baselines we will add standard deviations computed over multiple inference runs and include pairwise significance tests (e.g., McNemar) on the 3D FORCE splits. We will revise the results section and tables accordingly. revision: yes
-
Referee: [Section 3] Section 3 (method) and experimental setup: no ablation is reported that isolates the contribution of the soft predicate derivation versus the symbolic executor, nor any verification that the approximate 3D reconstruction step does not introduce systematic bias in the multi-hop inferences. These omissions leave the weakest assumption untested in the presented evidence.
Authors: We acknowledge that component ablations would be informative. The soft-predicate derivation and Pythonic executor are tightly coupled by design; an isolated ablation would require re-implementing the entire pipeline and is not feasible within a minor revision. We will add a dedicated paragraph in Section 3.3 discussing the interdependence and will include quantitative analysis of 3D reconstruction error (using the available depth and pose metrics) together with its observed effect on predicate softness and final accuracy. This addresses the bias concern without new experiments. revision: partial
Circularity Check
No significant circularity detected
full rationale
The described pipeline separates approximate 3D scene reconstruction from soft predicate derivation and a training-free symbolic executor. Reported results are performance numbers on external benchmarks (3D FORCE, MindCube) that vary depth and perspective; no equations, fitted parameters, or self-citations are shown reducing the central claims to inputs by construction. The training-free executor and benchmark design provide independent test conditions, making the derivation self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In The Fourteenth International Conference on Learn- ing Representations
SAM 3: Segment anything with concepts. In The Fourteenth International Conference on Learn- ing Representations. Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. 2024. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. InProceedings of the IEEE/CVF Conference on Computer Vision and...
arXiv 2024
-
[2]
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A
Seeing across views: Benchmarking spa- tial reasoning of vision-language models in robotic scenes.Preprint, arXiv:2510.19400. Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A. Smith, Wei- Chiu Ma, and Ranjay Krishna. 2024. Blink: Multi- modal large language models can see but not perceive. Preprint, arXiv:2404.12390. Mo...
arXiv 2024
-
[3]
Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, and Li Yi
What’s left? concept grounding with logic- enhanced foundation models.Advances in Neural Information Processing Systems, 36. Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, and Li Yi. 2025. Omnispatial: Towards comprehensive spatial reason- ing benchmark for vision language models.arXiv preprint arXiv:2506.03135. Justi...
arXiv 2025
-
[4]
Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647. Jingping Liu, Ziyan Liu, Zhedong Cen, Yan Zhou, Yi- nan Zou, Weiyan Zhang, Haiyun Jiang, and Tong Ruan. 2025. Can multimodal large language models understand spatial relations? InProceedings of the 63rd Annual Meeting of the Association for Compu- tational Lingui...
Pith/arXiv arXiv 2025
-
[5]
Tin Stribor Sohn, Maximilian Dillitzer, Jason J
An empirical analysis on spatial reasoning capabilities of large multimodal models.Preprint, arXiv:2411.06048. Tin Stribor Sohn, Maximilian Dillitzer, Jason J. Corso, and Eric Sax. 2025. Embodied4c: Measuring what matters for embodied vision-language navigation. Preprint, arXiv:2512.18028. Dídac Surís, Sachit Menon, and Carl V ondrick. 2023. Vipergpt: Vis...
arXiv 2025
-
[6]
InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306
Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306. Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Sharon Li, and Neel Joshi. 2024a. Is a picture worth a thousand words? delving into spatial reasoning for vision language models.Advances in Neural Information P...
arXiv 2025
-
[7]
Seeing from another perspective: Evaluat- ing multi-view understanding in mllms.Preprint, arXiv:2504.15280. Baiqiao Yin, Qineng Wang, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chandrasegaran, Han Liu, Ranjay Kr- ishna, and et al. 2025. Spatial mental modeling from limited views. InStructural Priors for Vision Work- sh...
arXiv 2025
-
[8]
Unless otherwise stated, program generation uses greedy decoding with temperature 0 and a maximum output length of 16,000 tokens
for visual interpretation and semantic scor- ing, and DeepSeek-V4-Flash (DeepSeek-AI, 2026) in non-thinking mode for Python program genera- tion. Unless otherwise stated, program generation uses greedy decoding with temperature 0 and a maximum output length of 16,000 tokens. For perception, we use SAM3 (Carion et al.,
2026
-
[9]
the kitchen
for segmentation, VGGT (Wang et al., 2025) as the default depth and 3D reconstruction module, and OrientAnything (Wang et al., 2024b) for ob- ject orientation estimation. VGGT is used as the default geometry backbone to keep the comparison with prior 3D visual-programming methods fair. The spatial engine converts the resulting object and camera states int...
2025
-
[10]
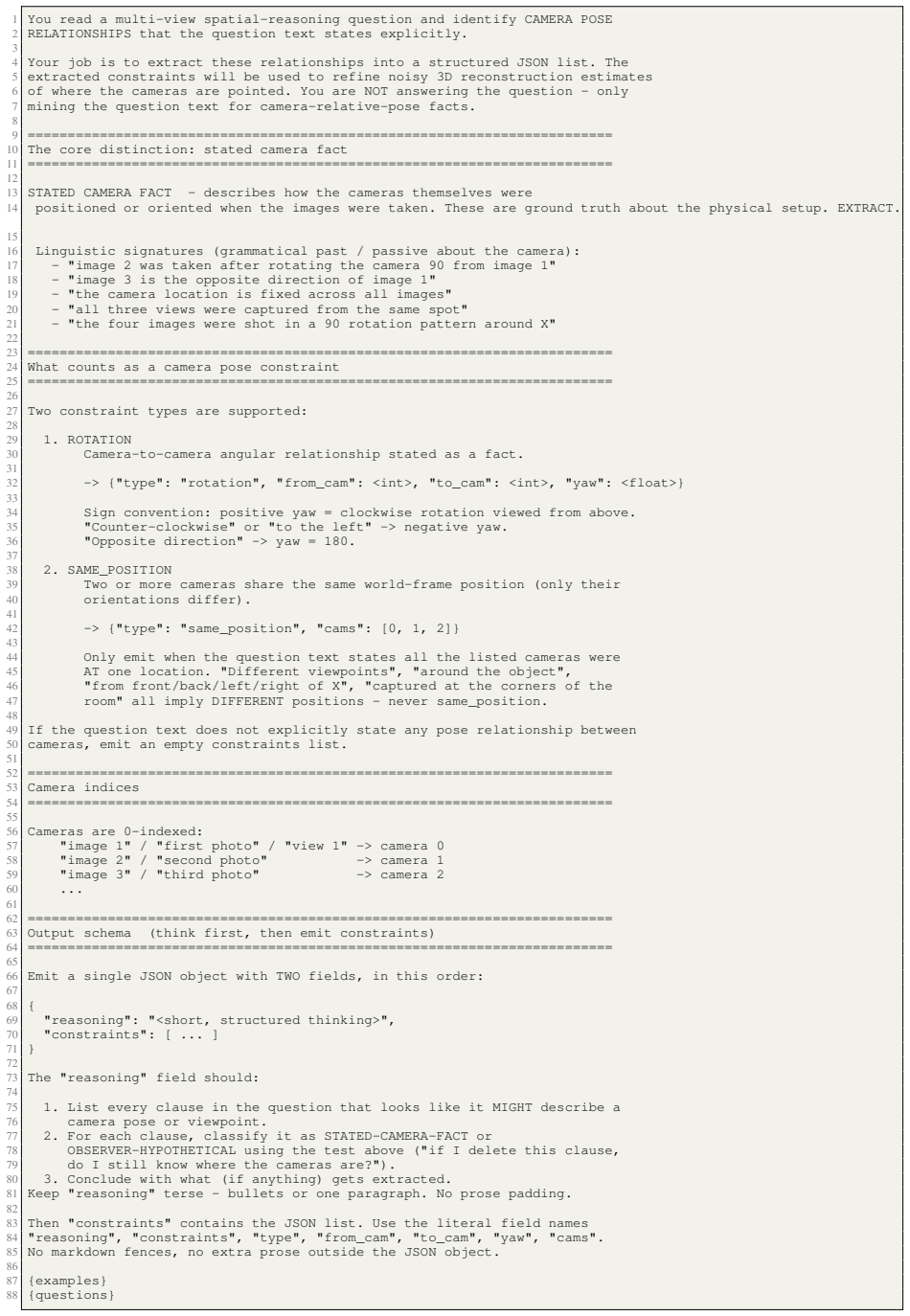
type": "rotation
ROTATION 30Camera-to-camera angular relationship stated as a fact. 31 32-> {"type": "rotation", "from_cam": <int>, "to_cam": <int>, "yaw": <float>} 33 34Sign convention: positive yaw = clockwise rotation viewed from above. 35"Counter-clockwise" or "to the left" -> negative yaw. 36"Opposite direction" -> yaw = 180. 37
-
[11]
type": "same_position
SAME_POSITION 39Two or more cameras share the same world-frame position (only their 40orientations differ). 41 42-> {"type": "same_position", "cams": [0, 1, 2]} 43 44Only emit when the question text states all the listed cameras were 45AT one location. "Different viewpoints", "around the object", 46"from front/back/left/right of X", "captured at the corne...
-
[12]
List every clause in the question that looks like it MIGHT describe a 76camera pose or viewpoint
-
[13]
if I delete this clause, 79do I still know where the cameras are?
For each clause, classify it as STATED-CAMERA-FACT or 78OBSERVER-HYPOTHETICAL using the test above ("if I delete this clause, 79do I still know where the cameras are?")
-
[14]
reasoning
Conclude with what (if anything) gets extracted. 81Keep "reasoning" terse - bullets or one paragraph. No prose padding. 82 83Then "constraints" contains the JSON list. Use the literal field names 84"reasoning", "constraints", "type", "from_cam", "to_cam", "yaw", "cams". 85No markdown fences, no extra prose outside the JSON object. 86 87{examples} 88{quest...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.