WarmServe: Enabling One-for-Many GPU Prewarming for Multi-LLM Serving
Pith reviewed 2026-05-22 12:18 UTC · model grok-4.3
The pith
WarmServe preloads multiple LLM model weights on shared GPUs using workload forecasts to enable fast instance startup during bursts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
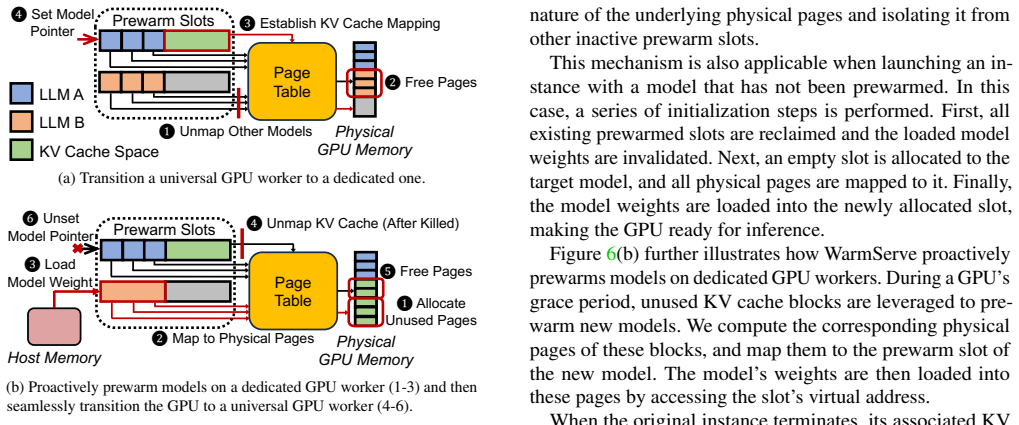
One-for-many GPU prewarming proactively loads parameters from multiple models onto GPUs based on workload forecasts; these prewarmed weights let the system instantiate serving instances promptly when request bursts occur. WarmServe realizes this idea through a model placement algorithm that minimizes cross-model interference, a KV cache reservation strategy that uses idle space on active GPUs, and an efficient GPU memory switching mechanism for tensor management.
What carries the argument
one-for-many GPU prewarming: proactively loading parameters from multiple models onto GPUs based on workload forecasts to support quick instance creation during bursts.
If this is right
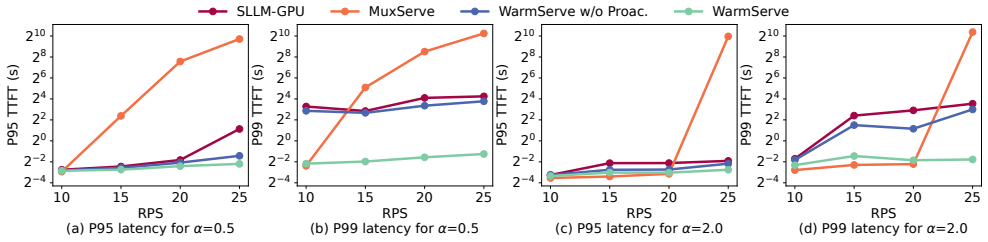
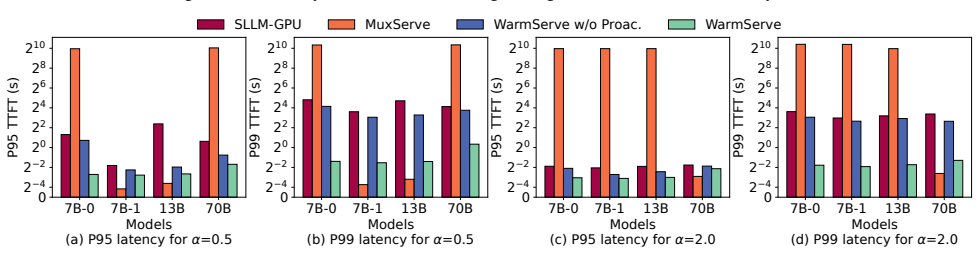
- Reduces tail TTFT by up to 50.8× compared to the state-of-the-art autoscaling-based system.
- Supports up to 2.5× higher request throughput than the GPU-sharing system.
- Minimizes cross-model prewarming interference through an optimized model placement algorithm.
- Repurposes idle KV cache space on running GPUs for prewarming new models without extra hardware.
Where Pith is reading between the lines
- The same forecast-driven prewarming pattern could be tested on other bursty multi-tenant workloads such as video encoding or database query serving.
- Accurate long-term prediction becomes the new bottleneck; systems may need lightweight rollback when forecasts prove wrong.
- Cloud operators could use this method to increase model density per GPU cluster while still meeting strict latency targets.
Load-bearing premise
Real-world LLM serving workloads exhibit strong periodicity and long-term predictability that can be leveraged for effective proactive prewarming decisions.
What would settle it
A production multi-LLM workload trace that shows no periodicity or predictability, causing WarmServe's forecast-driven prewarming to miss actual bursts and produce no improvement in tail TTFT.
Figures












read the original abstract
Deploying multiple models within shared GPU clusters is a key strategy to improve resource efficiency in large language model (LLM) serving. Existing multi-LLM serving systems improve GPU utilization at the cost of degraded inference performance, particularly time-to-first-token (TTFT). We attribute this degradation to the lack of awareness regarding future workload characteristics. In contrast, recent analyses have shown the strong periodicity and long-term predictability of real-world LLM serving workloads. In this paper, we propose one-for-many GPU prewarming, which proactively loads parameters from multiple models onto GPUs based on workload forecasts. These prewarmed weights enable the system to promptly instantiate serving instances upon encountering request bursts. We design and implement WarmServe, a multi-LLM serving system incorporating three key techniques: (1) a model placement algorithm that optimizes prewarming decisions to minimize cross-model prewarming interference, (2) a KV cache reservation strategy that repurposes idle KV cache space on running GPUs for prewarming new models, and (3) an efficient GPU memory switching mechanism for tensor management. Evaluation on real-world datasets shows that WarmServe reduces tail TTFT by up to 50.8$\times$ compared to the state-of-the-art autoscaling-based system, while supporting up to 2.5$\times$ higher request throughput than the GPU-sharing system.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents WarmServe, a multi-LLM serving system that enables one-for-many GPU prewarming based on predicted workload patterns. It introduces a model placement algorithm to minimize interference, a KV cache reservation strategy, and an efficient GPU memory switching mechanism. The evaluation on real-world datasets claims significant improvements: up to 50.8× reduction in tail time-to-first-token (TTFT) compared to autoscaling-based systems and up to 2.5× higher request throughput than GPU-sharing systems.
Significance. If the performance claims hold under robust conditions, this work could advance the state of efficient multi-model inference serving by leveraging the periodicity of real-world workloads for proactive resource management. The techniques address a practical gap in current systems that lack future workload awareness, potentially leading to better GPU utilization without sacrificing latency in production environments.
major comments (2)
- [§5 (Evaluation)] §5 (Evaluation) and abstract: The reported 50.8× tail TTFT reduction and 2.5× throughput gains are attributed to proactive prewarming that relies on long-term workload forecasts, yet the section provides no quantification of forecast accuracy (e.g., error rates, precision/recall of burst predictions), sensitivity analysis to mispredictions, or the fraction of prewarming decisions that were correct versus wasted. This is load-bearing for the central claim, as the abstract explicitly grounds the approach in “strong periodicity and long-term predictability.”
- [§4.2 (Baselines)] §4.2 (Baselines) and Table 2: The comparison to the “state-of-the-art autoscaling-based system” does not specify whether the baseline incorporates any form of workload prediction or uses purely reactive scaling; without this, it is unclear whether the measured gains arise from the proposed one-for-many prewarming or from differences in prediction assumptions between WarmServe and the baseline.
minor comments (2)
- [§3.1] The notation for prewarming interference in §3.1 could be clarified with a small example or pseudocode to show how the placement algorithm accounts for cross-model KV-cache contention.
- [Figure 7] Figure 7 (throughput vs. latency curves) would benefit from error bars or multiple runs to indicate statistical variability across the real-world traces.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will incorporate clarifications and additional analysis in the revised manuscript.
read point-by-point responses
-
Referee: §5 (Evaluation) and abstract: The reported 50.8× tail TTFT reduction and 2.5× throughput gains are attributed to proactive prewarming that relies on long-term workload forecasts, yet the section provides no quantification of forecast accuracy (e.g., error rates, precision/recall of burst predictions), sensitivity analysis to mispredictions, or the fraction of prewarming decisions that were correct versus wasted. This is load-bearing for the central claim, as the abstract explicitly grounds the approach in “strong periodicity and long-term predictability.”
Authors: We agree that explicit quantification of forecast accuracy is necessary to substantiate the central claims. In the revised version we will add a dedicated subsection (new §5.4) reporting prediction accuracy on the real-world traces, including mean absolute percentage error for request-rate forecasts, precision/recall for burst detection, the fraction of prewarming decisions that proved correct versus wasted, and a sensitivity study that replays the same traces under injected forecast errors of 10–30 %. These additions will directly support the “strong periodicity and long-term predictability” premise stated in the abstract. revision: yes
-
Referee: §4.2 (Baselines) and Table 2: The comparison to the “state-of-the-art autoscaling-based system” does not specify whether the baseline incorporates any form of workload prediction or uses purely reactive scaling; without this, it is unclear whether the measured gains arise from the proposed one-for-many prewarming or from differences in prediction assumptions between WarmServe and the baseline.
Authors: The autoscaling baseline is a purely reactive system that adjusts GPU allocation solely on the basis of instantaneous load (modeled after standard Kubernetes HPA and production LLM autoscalers) and contains no workload forecasting component. WarmServe’s measured improvements therefore derive from its proactive one-for-many prewarming rather than from any predictive advantage granted to the baseline. We will revise the first paragraph of §4.2 and add a clarifying footnote to Table 2 to state explicitly that the baseline is reactive and prediction-free. revision: yes
Circularity Check
No significant circularity; empirical evaluation on external workloads
full rationale
The paper describes an implemented system (WarmServe) with model placement, KV cache reservation, and GPU memory switching techniques. Its central claims are measured performance gains (tail TTFT reduction and throughput) obtained by running the system on real-world datasets and comparing against autoscaling and GPU-sharing baselines. Workload periodicity and predictability are explicitly attributed to 'recent analyses' rather than defined or fitted inside this paper. No equations, fitted parameters renamed as predictions, self-definitional steps, or load-bearing self-citations appear in the derivation chain; the results rest on external benchmarks and implementation rather than reducing to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real-world LLM serving workloads exhibit strong periodicity and long-term predictability.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/reality_from_one_distinctionreality_from_one_distinction (8-tick period) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
recent analysis on real-world traces has shown the high periodicity and long-term predictability of LLM serving workloads... our predictor achieves an average accuracy of 92.7%
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel (J-cost uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
one-for-many GPU prewarming... evict-aware model placement strategy... zero-overhead memory switching
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Foundry: Template-Based CUDA Graph Context Materialization for Fast LLM Serving Cold Start
Foundry uses template-based CUDA graph context materialization to reduce LLM serving cold-start latency by up to 99% while preserving CUDA graph throughput gains.
-
The Workload-Router-Pool Architecture for LLM Inference Optimization: A Vision Paper from the vLLM Semantic Router Project
The Workload-Router-Pool architecture is a 3D framework for LLM inference optimization that synthesizes prior vLLM work into a 3x3 interaction matrix and proposes 21 research directions at the intersections.
Reference graph
Works this paper leans on
-
[1]
OpenAI, “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
“GPT-4o System Card,” 2025. https://openai.com /index/gpt-4o-system-card/
work page 2025
-
[3]
DeepSeek-AI, “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Ka- dian, A. Al-Dahle,et al., “The llama 3 herd of models,” arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [5]
-
[6]
Qwen2.5-Coder Series: Powerful, Diverse, Practical,
“Qwen2.5-Coder Series: Powerful, Diverse, Practical,”
- [7]
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Introducing OpenAI o3 and o4-mini,
“Introducing OpenAI o3 and o4-mini,” 2023. https: //openai.com/index/introducing-o3-and-o4-m ini/
work page 2023
-
[10]
https://deepmind.google/tech nologies/gemini/
“Gemini,” 2025. https://deepmind.google/tech nologies/gemini/
work page 2025
-
[11]
Qwen3: Think Deeper, Act Faster,
“Qwen3: Think Deeper, Act Faster,” 2025. https: //qwenlm.github.io/blog/qwen3/
work page 2025
-
[12]
“Models - Openai Platform,” 2025. https://platfo rm.openai.com/docs/models
work page 2025
-
[13]
Fast and live model auto scaling with o(1) host caching,
D. Zhang, H. Wang, Y . Liu, X. Wei, Y . Shan, R. Chen, and H. Chen, “Fast and live model auto scaling with o(1) host caching,” inUSENIX OSDI, 2025
work page 2025
-
[14]
Muxserve: Flexible spatial- temporal multiplexing for multiple llm serving,
J. Duan, R. Lu, H. Duanmu, X. Li, X. Zhang, D. Lin, I. Stoica, and H. Zhang, “Muxserve: Flexible spatial- temporal multiplexing for multiple llm serving,” in ICML, 2024
work page 2024
-
[15]
Prism: Unleashing gpu sharing for cost-efficient multi- llm serving,
S. Yu, J. Xing, Y . Qiao, M. Ma, Y . Li, Y . Wang, S. Yang, Z. Xie, S. Cao, K. Bao, I. Stoica, H. Xu, and Y . Sheng, “Prism: Unleashing gpu sharing for cost-efficient multi- llm serving,”arXiv preprint arXiv:2505.04021, 2025
-
[16]
Serverlessllm: Low-latency server- less inference for large language models,
Y . Fu, L. Xue, Y . Huang, A.-O. Brabete, D. Ustiugov, Y . Patel, and L. Mai, “Serverlessllm: Low-latency server- less inference for large language models,” inUSENIX OSDI, 2024
work page 2024
-
[17]
Lambdas- cale: Enabling fast scaling for serverless large language model inference,
M. Yu, R. Yang, C. Jia, Z. Su, S. Yao, T. Lan, Y . Yang, Y . Cheng, W. Wang, A. Wang, and R. Chen, “Lambdas- cale: Enabling fast scaling for serverless large language model inference,”arXiv preprint arXiv:2502.09922, 2025
-
[18]
Towards swift serverless llm cold starts with paraserve,
C. Lou, S. Qi, C. Jin, D. Nie, H. Yang, X. Liu, and X. Jin, “Towards swift serverless llm cold starts with paraserve,” arXiv preprint arXiv:2502.15524, 2025
-
[19]
Tor- por: Gpu-enabled serverless computing for low-latency, resource-efficient inference,
M. Yu, A. Wang, D. Chen, H. Yu, X. Luo, Z. Li, W. Wang, R. Chen, D. Nie, H. Yang, and Y . Ding, “Tor- por: Gpu-enabled serverless computing for low-latency, resource-efficient inference,” inUSENIX ATC, 2025
work page 2025
-
[20]
Deepserve: Serverless large lan- guage model serving at scale,
J. Hu, J. Xu, Z. Liu, Y . He, Y . Chen, H. Xu, J. Liu, J. Meng, B. Zhang, S. Wan, G. Dan, Z. Dong, Z. Ren, C. Liu, T. Xie, D. Lin, Q. Zhang, Y . Yu, H. Feng, X. Chen, and Y . Shan, “Deepserve: Serverless large lan- guage model serving at scale,” inUSENIX ATC, 2025
work page 2025
-
[21]
Al- paServe: Statistical multiplexing with model parallelism for deep learning serving,
Z. Li, L. Zheng, Y . Zhong, V . Liu, Y . Sheng, X. Jin, Y . Huang, Z. Chen, H. Zhang, J. E. Gonzalez,et al., “Al- paServe: Statistical multiplexing with model parallelism for deep learning serving,” inUSENIX OSDI, 2023
work page 2023
-
[22]
Queue management for slo-oriented large language model serv- ing,
A. Patke, D. Reddy, S. Jha, H. Qiu, C. Pinto, C. Narayanaswami, Z. Kalbarczyk, and R. Iyer, “Queue management for slo-oriented large language model serv- ing,” inACM Symposium on Cloud Computing, 2024. 13
work page 2024
-
[23]
Burstgpt: A real-world workload dataset to optimize llm serving systems,
Y . Wang, Y . Chen, Z. Li, X. Kang, Z. Tang, X. He, R. Guo, X. Wang, Q. Wang, A. C. Zhou, and X. Chu, “Burstgpt: A real-world workload dataset to optimize llm serving systems,”arXiv preprint arXiv:2401.17644, 2024
-
[24]
Dynamollm: Designing llm inference clus- ters for performance and energy efficiency,
J. Stojkovic, C. Zhang, I. Goiri, J. Torrellas, and E. Choukse, “Dynamollm: Designing llm inference clus- ters for performance and energy efficiency,” inIEEE HPCA, March 2025
work page 2025
-
[25]
ServeGen: Workload Characterization and Generation of Large Language Model Serving in Production
Y . Xiang, X. Li, K. Qian, W. Yu, E. Zhai, and X. Jin, “Servegen: Workload characterization and generation of large language model serving in production,”arXiv preprint arXiv:2505.09999, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
B. Wu, S. Liu, Y . Zhong, P. Sun, X. Liu, and X. Jin, “Loongserve: Efficiently serving long-context large lan- guage models with elastic sequence parallelism,” in ACM SOSP, 2024
work page 2024
-
[27]
Shuffleinfer: Disaggregate llm inference for mixed downstream workloads,
C. Hu, H. Huang, L. Xu, X. Chen, C. Wang, J. Xu, S. Chen, H. Feng, S. Wang, Y . Bao, N. Sun, and Y . Shan, “Shuffleinfer: Disaggregate llm inference for mixed downstream workloads,”ACM Transactions on Archi- tecture and Code Optimization, July 2025
work page 2025
-
[28]
Kunserve: Efficient parameter-centric memory manage- ment for llm serving,
R. Cheng, Y . Lai, X. Wei, R. Chen, and H. Chen, “Kunserve: Efficient parameter-centric memory manage- ment for llm serving,”arXiv preprint arXiv:2412.18169, 2025
-
[29]
Deepspeed-fastgen: High-throughput text generation for llms via MII and deepspeed-inference
C. Holmes, M. Tanaka, M. Wyatt, A. A. Awan, J. Rasley, S. Rajbhandari, R. Y . Aminabadi, H. Qin, A. Bakhtiari, L. Kurilenko, and Y . He, “Deepspeed-fastgen: High- throughput text generation for llms via mii and deepspeed-inference,”arXiv preprint arXiv:2401.08671, 2025
-
[30]
Kvcache cache in the wild: Characterizing and optimizing kvcache cache at a large cloud provider,
J. Wang, J. Han, X. Wei, S. Shen, D. Zhang, C. Fang, R. Chen, W. Yu, and H. Chen, “Kvcache cache in the wild: Characterizing and optimizing kvcache cache at a large cloud provider,” inUSENIX ATC, July 2025
work page 2025
-
[31]
R. Qin, Z. Li, W. He, J. Cui, F. Ren, M. Zhang, Y . Wu, W. Zheng, and X. Xu, “Mooncake: Trading more storage for less computation — a KVCache-centric architecture for serving LLM chatbot,” inUSENIX Conference on File and Storage Technologies, 2025
work page 2025
-
[32]
B. Wu, Z. Zhang, Y . Zhong, G. Huang, Y . Zhu, X. Liu, and X. Jin, “Tokenlake: A unified segment-level pre- fix cache pool for fine-grained elastic long-context llm serving,”arXiv preprint arXiv:2508.17219, 2025
-
[33]
Xfaas: Hyperscale and low cost serverless functions at meta,
A. Sahraei, S. Demetriou, A. Sobhgol, H. Zhang, A. Nagaraja, N. Pathak, G. Joshi, C. Souza, B. Huang, W. Cook, A. Golovei, P. Venkat, A. Mcfague, D. Skar- latos, V . Patel, R. Thind, E. Gonzalez, Y . Jin, and C. Tang, “Xfaas: Hyperscale and low cost serverless functions at meta,” inACM SOSP, 2023
work page 2023
-
[34]
Rainbowcake: Miti- gating cold-starts in serverless with layer-wise container caching and sharing,
H. Yu, R. Basu Roy, C. Fontenot, D. Tiwari, J. Li, H. Zhang, H. Wang, and S.-J. Park, “Rainbowcake: Miti- gating cold-starts in serverless with layer-wise container caching and sharing,” inACM ASPLOS, 2024
work page 2024
-
[35]
Catalyzer: Sub-millisecond startup for serverless computing with initialization-less booting,
D. Du, T. Yu, Y . Xia, B. Zang, G. Yan, C. Qin, Q. Wu, and H. Chen, “Catalyzer: Sub-millisecond startup for serverless computing with initialization-less booting,” inACM ASPLOS, 2020
work page 2020
-
[36]
No provisioned concurrency: Fast RDMA- codesigned remote fork for serverless computing,
X. Wei, F. Lu, T. Wang, J. Gu, Y . Yang, R. Chen, and H. Chen, “No provisioned concurrency: Fast RDMA- codesigned remote fork for serverless computing,” in USENIX OSDI, 2023
work page 2023
-
[37]
Faascache: keeping serverless computing alive with greedy-dual caching,
A. Fuerst and P. Sharma, “Faascache: keeping serverless computing alive with greedy-dual caching,” inACM ASPLOS, 2021
work page 2021
- [38]
-
[39]
Q. Weng, W. Xiao, Y . Yu, W. Wang, C. Wang, J. He, Y . Li, L. Zhang, W. Lin, and Y . Ding, “{MLaaS} in the wild: Workload analysis and scheduling in {Large- Scale} heterogeneous {GPU} clusters,” inUSENIX NSDI, 2022
work page 2022
-
[40]
Pipeswitch: Fast pipelined context switching for deep learning applica- tions,
Z. Bai, Z. Zhang, Y . Zhu, and X. Jin, “Pipeswitch: Fast pipelined context switching for deep learning applica- tions,” inUSENIX OSDI, 2020
work page 2020
-
[41]
Fast Distributed Inference Serving for Large Language Models
B. Wu, Y . Zhong, Z. Zhang, S. Liu, F. Liu, Y . Sun, G. Huang, X. Liu, and X. Jin, “Fast distributed infer- ence serving for large language models,”arXiv preprint arXiv:2305.05920, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
SuperServe: Fine-Grained inference serv- ing for unpredictable workloads,
A. Khare, D. Garg, S. Kalra, S. Grandhi, I. Stoica, and A. Tumanov, “SuperServe: Fine-Grained inference serv- ing for unpredictable workloads,” inUSENIX NSDI, 2025
work page 2025
-
[43]
Introducing low-level gpu virtual memory manage- ment,
“Introducing low-level gpu virtual memory manage- ment,” 2025. https://developer.nvidia.com /blog/introducing-low-level-gpu-virtual-m emory-management/
work page 2025
-
[44]
vattention: Dynamic memory management for serving llms without pagedattention,
R. Prabhu, A. Nayak, J. Mohan, R. Ramjee, and A. Pan- war, “vattention: Dynamic memory management for serving llms without pagedattention,” inACM ASPLOS, 2025
work page 2025
-
[45]
Forecasting seasonals and trends by ex- ponentially weighted moving averages,
C. C. Holt, “Forecasting seasonals and trends by ex- ponentially weighted moving averages,”International Journal of Forecasting, 2004. 14
work page 2004
-
[46]
P. R. Winters,Forecasting Sales by Exponentially Weighted Moving Averages. Springer Berlin Heidelberg, 1976
work page 1976
-
[47]
Multivariate short-term traffic flow forecasting using time-series anal- ysis,
B. Ghosh, B. Basu, and M. O’Mahony, “Multivariate short-term traffic flow forecasting using time-series anal- ysis,”Intelligent Transportation Systems, IEEE Trans- actions on, 2009
work page 2009
-
[48]
G. E. P. Box and G. M. Jenkins,Time Series Analysis: Forecasting and Control. Prentice Hall PTR, 5th ed., 2015
work page 2015
-
[49]
Short-term load fore- casting using a long short-term memory network,
C. Liu, Z. Jin, J. Gu, and C. Qiu, “Short-term load fore- casting using a long short-term memory network,” in ISGT-Europe, 2017
work page 2017
-
[50]
Efficient mem- ory management for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient mem- ory management for large language model serving with pagedattention,” inACM SOSP, 2023
work page 2023
- [51]
-
[52]
Enabling elas- tic model serving with multiworld,
M. Lee, A. Jajoo, and R. R. Kompella, “Enabling elas- tic model serving with multiworld,”arXiv preprint arXiv:2407.08980, 2024
-
[53]
Llama 2: Open Foundation and Fine-Tuned Chat Mod- els | Research - AI at Meta,
“Llama 2: Open Foundation and Fine-Tuned Chat Mod- els | Research - AI at Meta,” 2023. https://ai.meta. com/research/publications/llama-2-open-fou ndation-and-fine-tuned-chat-models
work page 2023
-
[54]
“CUDA Multi-Process Service.” https://docs.nvi dia.com/deploy/pdf/CUDA_Multi_Process_Serv ice_Overview.pdf
-
[55]
B. Lin, C. Zhang, T. Peng, H. Zhao, W. Xiao, M. Sun, A. Liu, Z. Zhang, L. Li, X. Qiu, S. Li, Z. Ji, T. Xie, Y . Li, and W. Lin, “Infinite-llm: Efficient llm service for long context with distattention and distributed kvcache,” arXiv preprint arXiv:2401.02669, 2024
-
[56]
W. Lee, J. Lee, J. Seo, and J. Sim, “Infinigen: Efficient generative inference of large language models with dy- namic KV cache management,” inUSENIX OSDI, 2024
work page 2024
-
[57]
Kraken: Adaptive container provisioning for deploying dynamic dags in serverless platforms,
V . M. Bhasi, J. R. Gunasekaran, P. Thinakaran, C. S. Mishra, M. T. Kandemir, and C. Das, “Kraken: Adaptive container provisioning for deploying dynamic dags in serverless platforms,” inACM Symposium on Cloud Computing, 2021
work page 2021
-
[58]
Fifer: Tackling re- source underutilization in the serverless era,
J. R. Gunasekaran, P. Thinakaran, N. C. Nachiappan, M. T. Kandemir, and C. R. Das, “Fifer: Tackling re- source underutilization in the serverless era,” inMiddle- ware, 2020
work page 2020
-
[59]
Incendio: Priority-based scheduling for alle- viating cold start in serverless computing,
X. Cai, Q. Sang, C. Hu, Y . Gong, K. Suo, X. Zhou, and D. Cheng, “Incendio: Priority-based scheduling for alle- viating cold start in serverless computing,”IEEE Trans- actions on Computers, 2024
work page 2024
-
[60]
M. Shahrad, R. Fonseca, I. Goiri, G. Chaudhry, P. Batum, J. Cooke, E. Laureano, C. Tresness, M. Russinovich, and R. Bianchini, “Serverless in the wild: Characterizing and optimizing the serverless workload at a large cloud provider,” inUSENIX ATC, 2020
work page 2020
-
[61]
Spec- faas: Accelerating serverless applications with specula- tive function execution,
J. Stojkovic, T. Xu, H. Franke, and J. Torrellas, “Spec- faas: Accelerating serverless applications with specula- tive function execution,” inIEEE HPCA, 2023. 15 A TPOT CDF We provide the TPOT CDF of systems underα=2.0 in Figure 17. MuxServe incurs higher TPOT since it enlarges the parallelism degree of models and limits the computational power of an inst...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.