One Policy, Infinite NPCs: Persona-Traceable Shared RL Policies for Scalable Game Agents
Pith reviewed 2026-05-25 04:05 UTC · model grok-4.3
The pith
A single shared RL policy can control thousands of NPCs with distinct, controllable personas in real time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
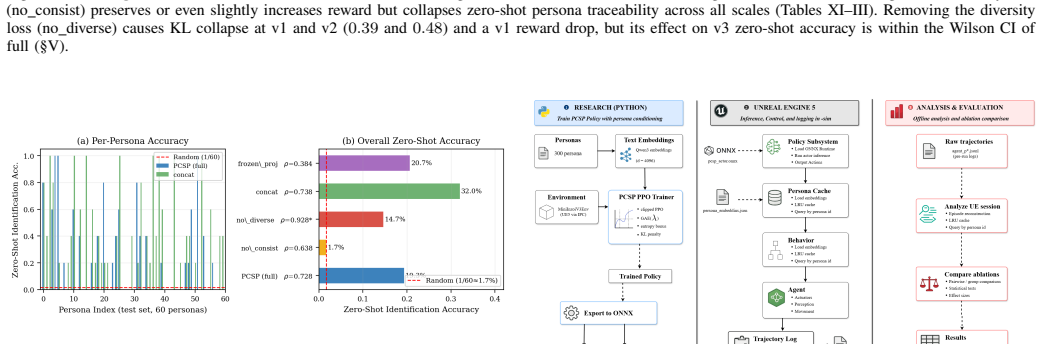
pcsp is a single reinforcement learning policy conditioned on frozen LLM embeddings of free-form persona descriptions. It combines once-per-NPC persona encoding, low-rank projection, neural conditioning, and a PPO training objective that includes an InfoNCE trajectory-consistency loss plus a KL diversity term. This construction yields compositional zero-shot persona identification up to 17 times above chance, 0.73 Spearman alignment, and 22 times faster inference than LLM baselines while remaining controllable through natural-language persona text.
What carries the argument
Persona Conditioned Shared Policy (pcsp) that conditions a shared PPO policy on frozen LLM persona embeddings via low-rank projection and neural layers, trained with an InfoNCE trajectory-consistency objective.
If this is right
- One policy can support hundreds to thousands of simultaneously active NPCs without per-NPC model copies.
- Persona conditioning works for both compositional zero-shot and vocabulary-expansion held-out settings.
- The same objective produces measurable persona-conditioned divergence in multi-agent strategic environments.
- Sub-frame inference survives deployment inside a commercial game engine at 64 agents.
Where Pith is reading between the lines
- Trajectory-consistency losses may generalize as a lightweight way to enforce identity across other shared-policy domains such as multi-robot coordination.
- The separation of frozen LLM encoding from the RL policy suggests a route to updating personas without retraining the entire agent.
- If the low-rank projection continues to scale, the method could support persona libraries orders of magnitude larger than the 300-persona test set.
Load-bearing premise
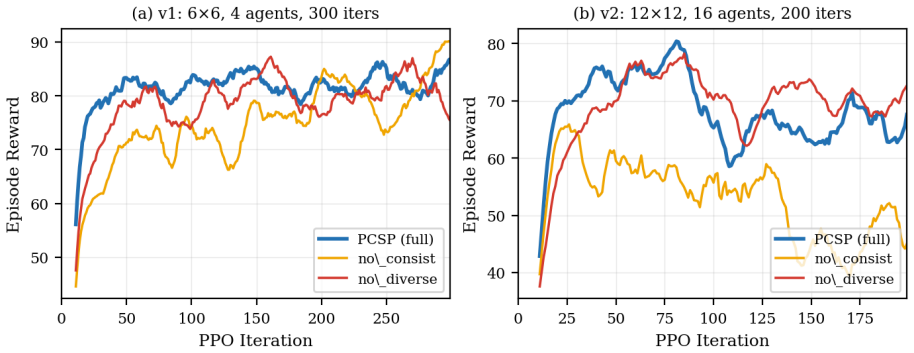
The InfoNCE trajectory-consistency objective is required for the policy to learn compositional zero-shot persona identification from natural-language descriptions.
What would settle it
Remove the InfoNCE loss, retrain, and measure whether zero-shot persona identification on the 300-persona benchmark falls to chance level.
Figures









read the original abstract
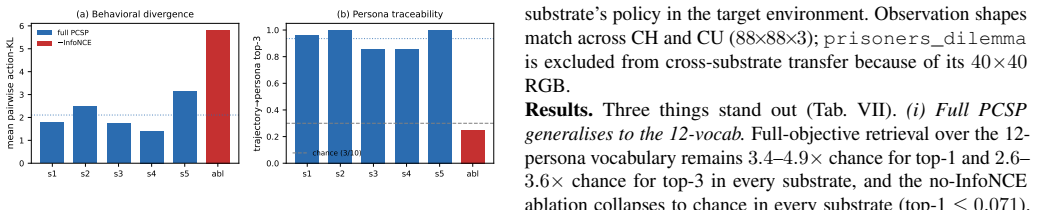
On a 300-persona life-simulation benchmark, pcsp achieves compositional zero-shot persona identification up to 17x above chance, Spearman rho approx 0.73 semantic-behavioral alignment, and 22x faster inference than an LLM-as-policy baseline. Life simulation games require hundreds to thousands of non-player characters (NPCs) that behave consistently with distinct personalities while remaining controllable through designer-authored natural language. Existing methods fail on constraints like persona consistency, controllability, or real-time inference. We introduce pcsp (Persona Conditioned Shared Policy), a single reinforcement learning policy conditioned on frozen LLM embeddings of free-form persona descriptions. pcsp combines once-per-NPC persona encoding, low-rank persona projection, neural persona conditioning, and a PPO + InfoNCE consistency + KL diversity training objective. Across three experimental settings, ablations show that the InfoNCE trajectory-consistency objective is load bearing: removing it collapses zero-shot persona identification to chance. External validation on Melting Pot 2.4.0 substrates confirms that our method produces persona-conditioned behavioral divergence in multi-agent strategic environments. We distinguish two senses of held-out evaluation: compositional zero-shot and vocabulary-expansion held-out. Finally, a UE5 deployment reproduces the in-engine persona-conditioning ablation at 64 agents with a low failure rate, showing that the sub-frame inference profile survives in a commercial game engine. These results prove that shared RL policies can support scalable, real-time, persona-conditioned NPC control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces pcsp, a single shared reinforcement learning policy conditioned on frozen LLM embeddings of free-form persona descriptions for NPC control in life-simulation games. It reports that on a 300-persona benchmark the method achieves compositional zero-shot persona identification up to 17x above chance, Spearman rho of approximately 0.73 for semantic-behavioral alignment, and 22x faster inference than an LLM-as-policy baseline. The training objective combines PPO with an InfoNCE trajectory-consistency term and KL diversity; an ablation is stated to show that removing InfoNCE collapses performance to chance. External validation on Melting Pot 2.4.0 substrates and a UE5 deployment at 64 agents are presented to support behavioral divergence and real-time scalability. The work distinguishes compositional zero-shot from vocabulary-expansion held-out evaluation.
Significance. If the empirical claims hold after verification of benchmark construction and training details, the result would be significant for game AI and multi-agent reinforcement learning. It demonstrates that a single policy can deliver persona-consistent, controllable behavior at scale without per-NPC models or slow LLM inference, directly addressing practical constraints in commercial engines. The load-bearing role of the InfoNCE term and the external Melting Pot validation strengthen the case for shared-policy approaches over existing alternatives.
major comments (3)
- [Abstract] Abstract: The central claim that the InfoNCE trajectory-consistency objective is load-bearing rests on the statement that its removal collapses zero-shot identification to chance; however, the exact identification accuracy (or other metric) with and without the term is not reported, preventing assessment of effect size.
- [Benchmark and Evaluation] Benchmark description: The 300-persona life-simulation benchmark construction, including persona generation process, definition of compositional zero-shot held-out set, and precise measurement of behavioral divergence, is not detailed; these elements are load-bearing for interpreting the 17x-above-chance and rho=0.73 results as evidence of true compositional generalization.
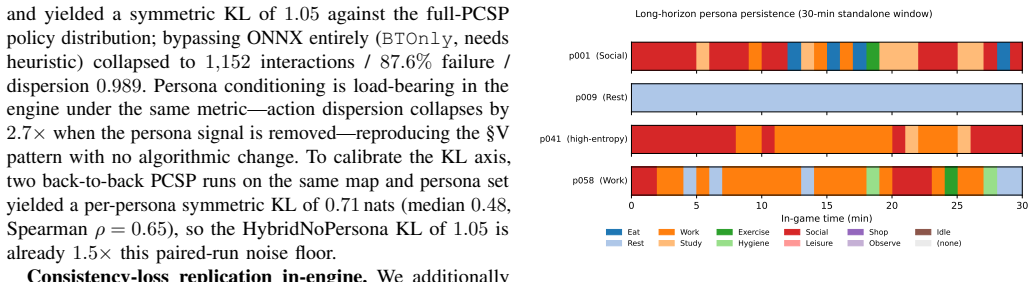
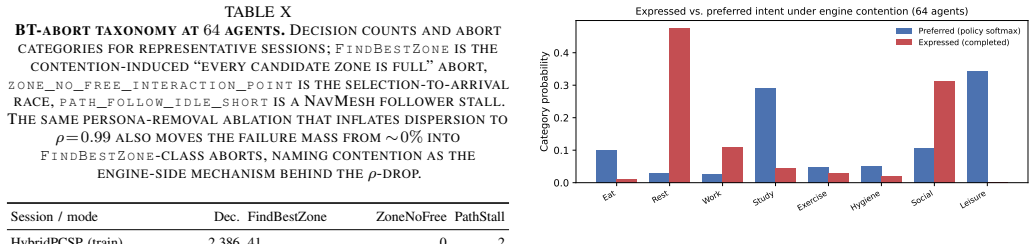
- [Deployment] UE5 deployment: The reproduction of the persona-conditioning ablation at 64 agents is presented as evidence of sub-frame inference, but the definition of the reported low failure rate and the precise integration of the low-rank persona projection into the engine are not specified, which is necessary to evaluate the scalability claim.
minor comments (2)
- [Abstract] The exact value of Spearman rho (rather than 'approx 0.73') and any associated confidence interval or p-value should be stated for precision.
- [Title] The title's use of 'Infinite NPCs' exceeds the scale demonstrated (300 personas, 64 agents); a more precise phrasing would better reflect the reported experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate clarifications and additional details in a revised manuscript to strengthen the presentation of results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the InfoNCE trajectory-consistency objective is load-bearing rests on the statement that its removal collapses zero-shot identification to chance; however, the exact identification accuracy (or other metric) with and without the term is not reported, preventing assessment of effect size.
Authors: We agree that explicit numerical values for the ablation would allow readers to better evaluate the effect size of the InfoNCE term. The revised manuscript will include a table reporting the precise zero-shot identification accuracy (and any other relevant metrics) both with and without the InfoNCE objective. revision: yes
-
Referee: [Benchmark and Evaluation] Benchmark description: The 300-persona life-simulation benchmark construction, including persona generation process, definition of compositional zero-shot held-out set, and precise measurement of behavioral divergence, is not detailed; these elements are load-bearing for interpreting the 17x-above-chance and rho=0.73 results as evidence of true compositional generalization.
Authors: We acknowledge that expanded details on benchmark construction are required for reproducibility and to support interpretation of the reported metrics. The revised manuscript will add a dedicated subsection describing the persona generation process, the exact definition and construction of the compositional zero-shot held-out set, and the methodology used to quantify behavioral divergence. revision: yes
-
Referee: [Deployment] UE5 deployment: The reproduction of the persona-conditioning ablation at 64 agents is presented as evidence of sub-frame inference, but the definition of the reported low failure rate and the precise integration of the low-rank persona projection into the engine are not specified, which is necessary to evaluate the scalability claim.
Authors: We agree that additional specification is needed to substantiate the deployment results. The revised manuscript will define the low failure rate metric explicitly and describe the integration of the low-rank persona projection within the UE5 engine, including any relevant implementation details for the 64-agent setting. revision: yes
Circularity Check
No significant circularity
full rationale
The paper reports empirical results from held-out evaluation on an external benchmark (Melting Pot 2.4.0), a commercial UE5 deployment at 64 agents, and explicit ablations on the InfoNCE objective. The central claims rest on performance metrics obtained from these external validations rather than any derivation that reduces by construction to fitted parameters, self-citations, or renamed inputs. No load-bearing step equates a prediction to its own training objective or prior author work by definition. The distinction between compositional zero-shot and vocabulary-expansion held-out evaluation is stated explicitly without circular reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Frozen LLM embeddings of free-form persona descriptions provide sufficient semantic signal for policy conditioning
- domain assumption Standard PPO augmented with InfoNCE trajectory consistency and KL diversity terms can produce both reward-maximizing and persona-distinct behavior
Reference graph
Works this paper leans on
-
[1]
Scalable evaluation of multi-agent reinforcement learning with melting pot,
J. Z. Leibo, E. A. Due ˜nez-Guzman, A. Vezhnevets, J. P. Agapiou, P. Sunehag, R. Koster, J. Matyas, C. Beattie, I. Mordatch, and T. Graepel, “Scalable evaluation of multi-agent reinforcement learning with melting pot,” inInternational Conference on Machine Learning (ICML), 2021
work page 2021
-
[2]
G. N. Yannakakis and J. Togelius,Artificial Intelligence and Games. Springer, 2018
work page 2018
-
[3]
M. Colledanchise and P. ¨Ogren,Behavior Trees in Robotics and AI: An Introduction. CRC Press, 2018
work page 2018
-
[4]
Generative agents: Interactive simulacra of human behavior,
J. S. Park, J. C. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative agents: Interactive simulacra of human behavior,” inACM Symposium on User Interface Software and Technology (UIST), 2023
work page 2023
-
[5]
Voyager: An Open-Ended Embodied Agent with Large Language Models
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandkumar, “V oyager: An open-ended embodied agent with large language models,”arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” in International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[7]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, E. Berman, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” inAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[8]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V . Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[9]
Diversity is all you need: Learning skills without a reward function,
B. Eysenbach, A. Gupta, J. Ibarz, and S. Levine, “Diversity is all you need: Learning skills without a reward function,” inInternational Conference on Learning Representations (ICLR), 2019
work page 2019
-
[10]
CIC: Contrastive intrinsic control for unsupervised skill discovery,
M. Laskin, H. Liu, X. B. Peng, D. Yarats, A. Rajeswaran, and P. Abbeel, “CIC: Contrastive intrinsic control for unsupervised skill discovery,”arXiv preprint arXiv:2202.00161, 2022
-
[11]
Curiosity-driven exploration by self-supervised prediction,
D. Pathak, P. Agrawal, A. A. Efros, and T. Darrell, “Curiosity-driven exploration by self-supervised prediction,” inInternational Conference on Machine Learning (ICML), 2017
work page 2017
-
[12]
Universal value function approximators,
T. Schaul, D. Horgan, K. Gregor, and D. Silver, “Universal value function approximators,” inInternational Conference on Machine Learning (ICML), 2015
work page 2015
-
[13]
M. Andrychowicz, F. Wolski, A. Ray, J. Schneider, R. Fong, P. Welinder, B. McGrew, J. Tobin, P. Abbeel, and W. Zaremba, “Hindsight experience replay,” inAdvances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[14]
BabyAI: A platform to study the sample efficiency of grounded language learning,
M. Chevalier-Boisvert, D. Bahdanau, S. Lahlou, L. Willems, C. Saharia, T. H. Nguyen, and Y . Bengio, “BabyAI: A platform to study the sample efficiency of grounded language learning,” inInternational Conference on Learning Representations (ICLR), 2019
work page 2019
-
[15]
Decision transformer: Reinforcement learning via sequence modeling,
L. Chen, K. Lu, A. Rajeswaran, K. Lee, A. Grover, M. Laskin, P. Abbeel, A. Srinivas, and I. Mordatch, “Decision transformer: Reinforcement learning via sequence modeling,” inAdvances in Neural Information Processing Systems (NeurIPS), 2021
work page 2021
-
[16]
S. Reed, K. Zolna, E. Parisotto, S. G. Colmenarejo, A. Novikov, G. Barth- Maron, M. Gimenez, Y . Sulsky, J. Kay, J. T. Springenberget al., “A generalist agent,”arXiv preprint arXiv:2205.06175, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Grandmaster level in StarCraft II using multi-agent reinforcement learning,
O. Vinyals, I. Babuschkin, W. M. Czarnecki, M. Mathieu, A. Dudzik, J. Chung, D. H. Choi, R. Powell, T. Ewalds, P. Georgievet al., “Grandmaster level in StarCraft II using multi-agent reinforcement learning,”Nature, vol. 575, no. 7782, pp. 350–354, 2019
work page 2019
-
[18]
Dota 2 with Large Scale Deep Reinforcement Learning
C. Berner, G. Brockman, B. Chan, V . Cheung, P. Debiak, C. Dennison, D. Farhi, Q. Fischer, S. Hashme, C. Hesseet al., “Dota 2 with large scale deep reinforcement learning,”arXiv preprint arXiv:1912.06680, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[19]
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play,
D. Silver, T. Hubert, J. Schrittwieser, I. Antonoglou, M. Lai, A. Guez, M. Lanctot, L. Sifre, D. Kumaran, T. Graepel, T. Lillicrap, K. Simonyan, and D. Hassabis, “A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play,”Science, vol. 362, no. 6419, pp. 1140–1144, 2018
work page 2018
-
[20]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[21]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Y . Zhang, M. Li, D. Long, X. Zhang, H. Lin, B. Yang, P. Xie, A. Yang, D. Liu, J. Lin, F. Huang, and J. Zhou, “Qwen3 embedding: Advancing text embedding and reranking through foundation models,” arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Sentence-BERT: Sentence embeddings using Siamese BERT-networks,
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence embeddings using Siamese BERT-networks,” inConference on Empirical Methods in Natural Language Processing (EMNLP), 2019
work page 2019
-
[23]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations (ICLR), 2022
work page 2022
-
[24]
FiLM: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville, “FiLM: Visual reasoning with a general conditioning layer,” inAAAI Conference on Artificial Intelligence, 2018
work page 2018
-
[25]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
The surprising effectiveness of PPO in cooperative multi-agent games,
C. Yu, A. Velu, E. Vinitsky, J. Gao, Y . Wang, A. Bayen, and Y . Wu, “The surprising effectiveness of PPO in cooperative multi-agent games,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[27]
S., Gupta, T., Makoviichuk, D., Makoviychuk, V ., Torr, P
C. S. de Witt, T. Gupta, D. Makoviichuk, V . Makoviychuk, P. H. S. Torr, M. Sun, and S. Whiteson, “Is independent learning all you need in the StarCraft multi-agent challenge?”arXiv preprint arXiv:2011.09533, 2020
-
[28]
Representation Learning with Contrastive Predictive Coding
A. van den Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
PettingZoo: Gym for multi-agent reinforcement learning,
J. K. Terry, B. Black, N. Grammel, M. Jayakumar, A. Hari, R. Sullivan, L. S. Santos, C. Dieffendahl, C. Horsch, R. Perez-Vicente, N. L. Williams, Y . Lokesh, and P. Ravi, “PettingZoo: Gym for multi-agent reinforcement learning,” inAdvances in Neural Information Processing Systems (NeurIPS), 2021
work page 2021
-
[30]
An introduction to the five-factor model and its applications,
R. R. McCrae and P. T. Costa Jr, “An introduction to the five-factor model and its applications,”Journal of Personality, vol. 60, no. 2, pp. 175–215, 1992
work page 1992
-
[31]
An alternative “description of personality
L. R. Goldberg, “An alternative “description of personality”: The Big- Five factor structure,”Journal of Personality and Social Psychology, vol. 59, no. 6, pp. 1216–1229, 1990
work page 1990
-
[32]
The Sims Wiki, “Trait (The Sims 3),” https://sims.fandom.com/wiki/ Trait (The Sims 3), 2026, accessed May 11, 2026
work page 2026
- [33]
-
[34]
The Hanabi challenge: A new frontier for AI research,
N. Bard, J. N. Foerster, S. Chandar, N. Burch, M. Lanctot, H. F. Song, E. Parisotto, V . Dumoulin, S. Moitra, E. Hugheset al., “The Hanabi challenge: A new frontier for AI research,”Artificial Intelligence, vol. 280, 2020
work page 2020
-
[35]
Counterfactual multi-agent policy gradients,
J. N. Foerster, G. Farquhar, T. Afouras, N. Nardelli, and S. Whiteson, “Counterfactual multi-agent policy gradients,” inAAAI Conference on Artificial Intelligence, 2018
work page 2018
-
[36]
Multi- agent actor-critic for mixed cooperative-competitive environments,
R. Lowe, Y . Wu, A. Tamar, J. Harb, P. Abbeel, and I. Mordatch, “Multi- agent actor-critic for mixed cooperative-competitive environments,” in Advances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[37]
Phase 5 report: persona-conditioned shared policies on melting pot,
Y . Hong, “Phase 5 report: persona-conditioned shared policies on melting pot,” Project report, research/meltingpot/PHASE5_REPORT.md, 2026
work page 2026
-
[38]
Personalizing dialogue agents: I have a dog, do you have pets too?
S. Zhang, E. Dinan, J. Urbanek, A. Szlam, D. Kiela, and J. Weston, “Personalizing dialogue agents: I have a dog, do you have pets too?” in Annual Meeting of the Association for Computational Linguistics (ACL), 2018
work page 2018
-
[39]
Leveraging procedural generation to benchmark reinforcement learning,
K. Cobbe, C. Hesse, J. Hilton, and J. Schulman, “Leveraging procedural generation to benchmark reinforcement learning,” inInternational Conference on Machine Learning (ICML), 2020
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.