Structured Testbench Generation for LLM-Driven HDL Design and Verification-Oriented Data Curation
Pith reviewed 2026-06-27 06:48 UTC · model grok-4.3
The pith
STG generates deterministic testbenches from hardware design structure, delivering 720x faster verification than iterative LLM flows with higher coverage and fewer false passes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
STG is a framework that exploits the inherent structure of hardware designs to generate deterministic testbenches. As a verification tool it runs 720 times faster than iterative LLM-based generation, achieves higher successful compilation and coverage rates, and reduces false-pass verdicts on incorrect DUTs. It also identifies errors in existing RTL benchmarks. As a data curation engine STG runs 11 times faster than LLM filtering on a single CPU core while using 127 times less energy, and the resulting distilled models reach state-of-the-art performance. When used as a test-time scaling oracle it reduces node count by 14 to 47 percent.
What carries the argument
Structured Testbench Generation framework that derives deterministic testbenches directly from the structure of the hardware design rather than unconstrained LLM code synthesis.
If this is right
- Testbench generation becomes 720 times faster than iterative LLM flows while raising compilation success and coverage.
- False-pass verdicts on incorrect designs decrease, and existing benchmark errors become detectable.
- Data curation for model distillation runs 11 times faster on one CPU core with 127 times lower energy use.
- Distilled models trained on STG-curated data achieve state-of-the-art results across multiple benchmarks.
- Node count in test-time scaling drops by 14 to 47 percent when STG serves as oracle.
Where Pith is reading between the lines
- The method may extend to other domains where code or artifacts have explicit structural constraints that can replace LLM sampling.
- Lower energy curation could make repeated fine-tuning cycles for hardware-specific models more practical on modest hardware.
- Verification pipelines could shift from post-generation checking toward structure-derived oracles that prune invalid candidates early.
Load-bearing premise
Hardware designs possess an inherent structure that can be exploited to create deterministic testbenches reliably superior to stochastic LLM outputs in speed, coverage, and accuracy without hidden trade-offs across design classes.
What would settle it
A controlled comparison on a diverse set of RTL designs in which STG testbenches show lower coverage or more false passes than iterative LLM-generated testbenches would falsify the central performance claims.
Figures

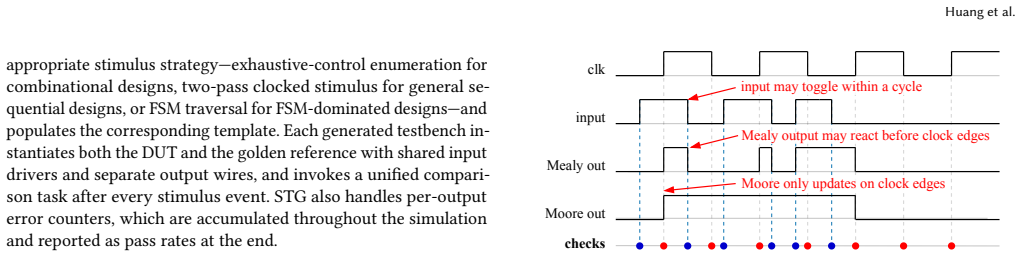

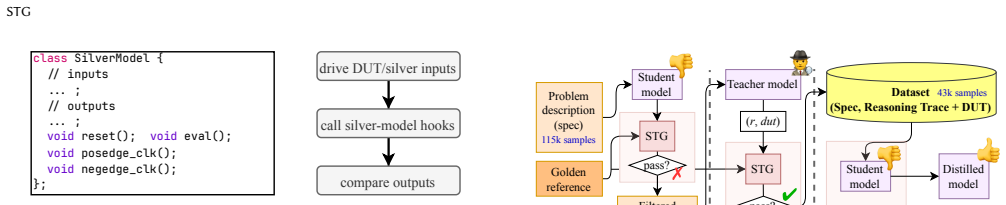

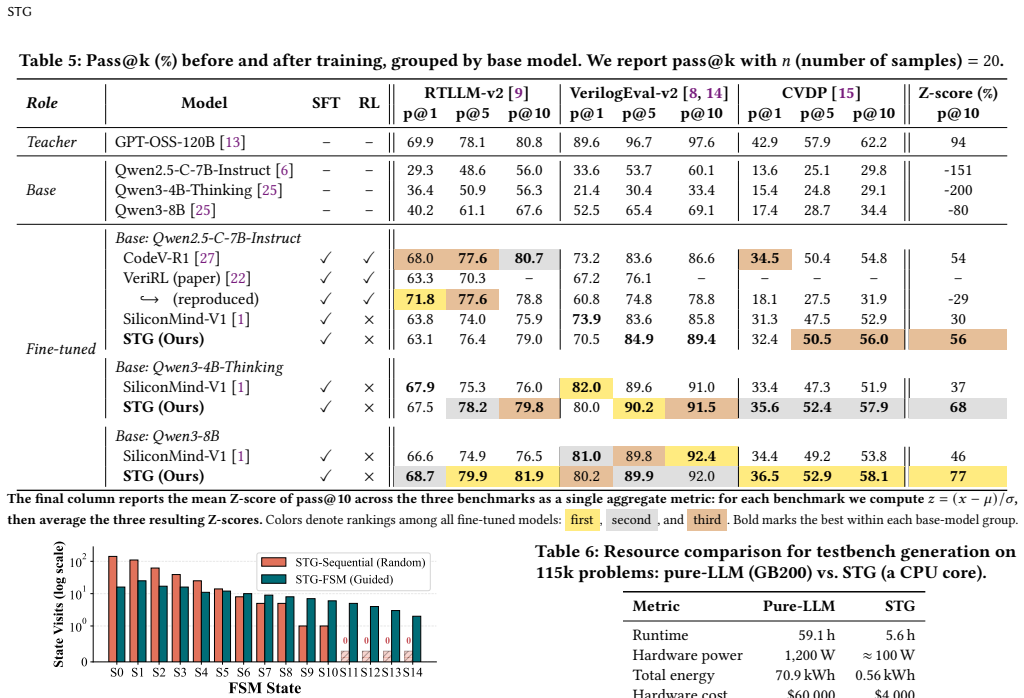


read the original abstract
Automated testbench generation has become a critical bottleneck in large language model (LLM)-driven Register Transfer Level (RTL) workflows, where large numbers of candidate designs must be verified rapidly and reliably. Existing prompt-based approaches treat testbench generation as unconstrained code synthesis, yielding stochastic outputs with high token cost, low reproducibility, and insufficient coverage. To address this gap, we present STG, a Structured Testbench Generation framework that exploits the inherent structure of hardware designs to generate deterministic testbenches. As a direct verification tool, STG runs 720x faster than an iterative LLM-based testbench generation flow and higher rate of successful compilation, achieves higher coverage, and reduces false-pass verdicts on incorrect DUTs. STG also helps identify errors in RTL generation benchmarks by exposing faulty benchmark testbenches. As a data curation engine, it is 11x faster than LLM-based filtering on a single CPU core with 127x less energy, and the resulting distilled models provide state-of-the-art performance in our multi-benchmark evaluation. As a test-time scaling oracle, it reduces node count by 14-47\%. Our models are available at https://huggingface.co/collections/AS-SiliconMind/siliconmind-v12.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the STG (Structured Testbench Generation) framework, which exploits the inherent structure of hardware designs to produce deterministic testbenches for LLM-driven RTL workflows. It claims STG achieves a 720x speedup over iterative LLM-based testbench generation with higher compilation success and coverage while reducing false-pass verdicts on incorrect DUTs; as a data curation engine it is 11x faster than LLM-based filtering (with 127x less energy) and yields distilled models with state-of-the-art performance; it also reduces node count by 14-47% as a test-time scaling oracle. Models are released publicly.
Significance. If the empirical results hold and generalize, the work could meaningfully advance automated verification and data curation in LLM-assisted hardware design by replacing stochastic prompt-based synthesis with deterministic, structure-driven methods. The public release of models supports reproducibility and follow-on work.
major comments (2)
- [Abstract] Abstract: the central quantitative claims (720x speedup, 11x faster curation, coverage improvements, false-pass reduction) are stated without any description of the experimental methodology, the distribution or number of evaluated DUTs, baseline implementations, timing/energy measurement protocols, or statistical analysis, rendering the claims unevaluable from the manuscript.
- [Abstract] Abstract / Experimental section: no ablation isolating the contribution of structure exploitation is reported, nor are any counter-examples or failure modes where STG underperforms the iterative LLM baseline; without these, performance deltas cannot be attributed to the claimed mechanism rather than benchmark selection or baseline inefficiency.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that improve the manuscript's clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central quantitative claims (720x speedup, 11x faster curation, coverage improvements, false-pass reduction) are stated without any description of the experimental methodology, the distribution or number of evaluated DUTs, baseline implementations, timing/energy measurement protocols, or statistical analysis, rendering the claims unevaluable from the manuscript.
Authors: The abstract is intentionally concise, but the full manuscript's Experimental section details the evaluation methodology, DUT distribution and count, baseline implementations, timing/energy protocols, and statistical analysis. To make key claims more evaluable directly from the abstract, we will revise it to include a short summary of the experimental scope and protocols. revision: yes
-
Referee: [Abstract] Abstract / Experimental section: no ablation isolating the contribution of structure exploitation is reported, nor are any counter-examples or failure modes where STG underperforms the iterative LLM baseline; without these, performance deltas cannot be attributed to the claimed mechanism rather than benchmark selection or baseline inefficiency.
Authors: We agree that an ablation isolating the structure exploitation mechanism would strengthen attribution of the gains. We will add such an ablation study in the revised version. We will also include a dedicated discussion of failure modes and counter-examples where the structure-driven approach may underperform relative to iterative LLM baselines, such as on designs with irregular or non-deterministic control logic. revision: yes
Circularity Check
No circularity; purely empirical claims with no derivations or self-referential reductions
full rationale
The paper contains no equations, derivations, or mathematical chains. All central claims (720x speedup, higher coverage, 11x curation speedup, etc.) are presented as direct empirical measurements from experiments on hardware designs. No parameters are fitted and then relabeled as predictions, no self-citations are used to justify uniqueness theorems or ansatzes, and the structure-exploitation premise is not reduced to a self-definition. The work is self-contained against external benchmarks via reported runtime, coverage, and energy comparisons.
Axiom & Free-Parameter Ledger
invented entities (1)
-
STG framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mu-Chi Chen, Yu-Hung Kao, Po-Hsuan Huang, Shao-Chun Ho, Hsiang-Yu Tsou, et al. 2026. SiliconMind-V1: Multi-Agent Distillation and Debug-Reasoning Workflows for Verilog Code Generation. arXiv preprint arXiv:2603.08719
arXiv 2026
-
[2]
Tsun S. Chow. 1978. Testing Software Design Modeled by Finite-State Machines. IEEE Trans. on Software Engineering (TSE)SE-4, 3 (1978), 178–187. doi:10.1109/ TSE.1978.231496
arXiv 1978
-
[3]
Haoran Dong, Keyi He, Bingkun Zhang, Boshen Du, Huaiyuan Zhang, Mengyao Wang, Jianhua Yu, and Haoxing Ren. 2025. ScaleRTL: Scaling LLMs with Reasoning Data and Test-Time Compute for Accurate RTL Code Genera- tion. InProc. ACM/IEEE Int. Symp. on Machine Learning for CAD (MLCAD). doi:10.1109/DAC63849.2025.11133318
-
[4]
Shai Fine and Avi Ziv. 2003. Coverage Directed Test Generation for Functional Verification Using Bayesian Networks. InProc. Design Automation Conf. (DAC). 286–291. doi:10.1145/775832.775907
-
[5]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, et al. 2025. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature645, 8081 (Sept. 2025), 633–638. doi:10.1038/s41586-025-09422-z
-
[6]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, et al. 2024. Qwen2.5- Coder Technical Report. arXiv preprint arXiv:2410.08625
arXiv 2024
-
[7]
Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2023. Fast Inference from Transformers via Speculative Decoding. InProc. Int. Conf. on Machine Learning (ICML). 19274–19286. doi:10.48550/arXiv.2211.17192
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2211.17192 2023
-
[8]
Mingjie Liu, Nathaniel Pinckney, Brucek Khailany, and Haoxing Ren. 2023. VerilogEval: Evaluating Large Language Models for Verilog Code Generation. InProc. IEEE/ACM Int. Conf. on Computer-Aided Design (ICCAD). IEEE, 1–8. doi:10.1109/ICCAD57390.2023.10323812
-
[9]
Yao Lu, Shang Liu, Qijun Zhang, and Zhiyao Xie. 2024. RTLLM: An Open- Source Benchmark for Design RTL Generation with Large Language Model. In Proc. Asia and South Pacific Design Automation Conference (ASP-DAC). 722–727. doi:10.1109/ASP-DAC58780.2024.10473904
-
[10]
Kyungjun Min, Kyumin Cho, Junhwan Jang, and Seokhyeong Kang. 2026. REvolu- tion: An Evolutionary Framework for RTL Generation driven by Large Language Models. InProc. Asia and South Pacific Design Automation Conference (ASP-DAC). 282–288. doi:10.1109/ASP-DAC66049.2026.11420420
-
[11]
Bardia Nadimi, Ghali Omar Boutaib, and Hao Zheng. 2025. PyraNet: A Multi- Layered Hierarchical Dataset for Verilog. InProc. Design Automation Conf. (DAC). 1–7. doi:10.1109/DAC63849.2025.11133406
-
[12]
Alexander Novikov, Ngân V ˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, et al. 2025. AlphaEvolve: A coding agent for scientific and algorithmic discovery. arXiv preprint arXiv:2506.13131
Pith/arXiv arXiv 2025
-
[13]
OpenAI, :, Sandhini Agarwal, Lama Ahmad, Jason Ai, et al. 2025. gpt-oss-120b & gpt-oss-20b Model Card. arXiv preprint arXiv:2508.10925
Pith/arXiv arXiv 2025
-
[14]
Nathaniel Pinckney, Christopher Batten, Mingjie Liu, Haoxing Ren, and Brucek Khailany. 2024. Revisiting VerilogEval: A Year of Improvements in Large- Language Models for Hardware Code Generation.ACM Trans. on Design Au- tomation of Electronic Systems (TODAES)(2024). doi:10.1145/3718088
-
[15]
Nathaniel Pinckney, Chenhui Deng, Chia-Tung Ho, Yun-Da Tsai, Mingjie Liu, Wenfei Zhou, Brucek Khailany, and Haoxing Ren. 2025. Comprehensive Verilog Design Problems: A Next-Generation Benchmark Dataset for Evaluating Large Language Models and Agents on RTL Design and Verification. arXiv preprint arXiv:2506.14074
arXiv 2025
-
[16]
Ruidi Qiu, Grace Li Zhang, Rolf Drechsler, Ulf Schlichtmann, and Bing Li. 2024. AutoBench: Automatic Testbench Generation and Evaluation Using LLMs for HDL Design. InProc. ACM/IEEE Int. Symp. on Machine Learning for CAD (MLCAD). 1–10. doi:10.1145/3670474.3685956
-
[17]
Ruidi Qiu, Grace Li Zhang, Rolf Drechsler, Ulf Schlichtmann, and Bing Li. 2025. CorrectBench: Automatic Testbench Generation with Functional Self-Correction Using LLMs for HDL Design. InProc. Design, Automation and Test in Europe (DATE). doi:10.23919/DATE64628.2025.10992873
-
[18]
Ruidi Qiu, Yalin Zhang, Rolf Drechsler, Tsungyi Ho, Ulf Schlichtmann, and Bing Li. 2025. ConfiBench: Automatic Testbench Generation with Confidence-Based Scenario Mask and Testbench Ensemble Using LLMs for HDL Design.ACM Trans. on Design Automation of Electronic Systems (TODAES)(2025). doi:10.1145/3773087
-
[19]
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, et al. 2025. Continual Learning of Large Language Models: A Comprehensive Survey.ACM Computing Surveys (CSUR)58, 5, Article 120 (Nov. 2025), 42 pages. doi:10.1145/ 3735633
2025
-
[20]
Wilson Snyder et al. 2024. Verilator—Open-Source SystemVerilog Simulator and Lint System. https://www.veripool.org/verilator/. Accessed: 2026-04-01
2024
-
[21]
Chinnery, Scott J
Serdar Tasiran, Farzan Fallah, David G. Chinnery, Scott J. Weber, and Kurt Keutzer
-
[22]
A Functional Validation Technique: Biased-Random Simulation Guided by Observability-Based Coverage. InProc. IEEE Int. Conf. on Computer Design (ICCD). 82–88. doi:10.1109/ICCD.2001.955007
-
[23]
Fu Teng, Miao Pan, Xuhong Zhang, Zhezhi He, Yiyao Yang, et al. 2025. VeriRL: Boosting the LLM-based Verilog Code Generation via Reinforcement Learning. In Proc. Int. Conf. on Computer-Aided Design (ICCAD). 1–9. doi:10.1109/ICCAD66269. 2025.11241003
-
[24]
Yangbo Wei, Zhen Huang, Lei He, Li Huang, Ting-Jung Lin, and Wei W. Xing
-
[25]
VFlow: Discovering Optimal Agentic Workflows for Verilog Generation. In Proc. Asia and South Pacific Design Automation Conference (ASP-DAC). 355–361. doi:10.1109/ASP-DAC66049.2026.11420713
-
[26]
Stephen Williams. 2002. Icarus Verilog: open-source Verilog more than a year later.Linux Journal99 (2002), 3
2002
-
[27]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, et al . 2025. Qwen3 Technical Report. arXiv preprint arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[28]
Yang Zhao, Di Huang, Chongxiao Li, Pengwei Jin, Nan Ziyuan, et al. 2025. CodeV: Empowering LLMs with HDL Generation through Multi-Level Summarization. IEEE Trans. on Computer-Aided Design of Integrated Circuits and Systems (TCAD) (2025). doi:10.1109/TCAD.2025.3604320
-
[29]
Yaoyu Zhu, Di Huang, Hanqi Lyu, Xiaoyun Zhang, Chongxiao Li, et al . 2025. QiMeng-CodeV-R1: Reasoning-Enhanced Verilog Generation. InProc. Advances in Neural Information Processing Systems (NIPS). doi:10.48550/arXiv.2505.24183
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.