Bridging Vision and Language Concepts through Optimal Transport Semantic Flow
Pith reviewed 2026-06-26 05:29 UTC · model grok-4.3
The pith
OTF-CBM models vision-language concept alignment as dynamic optimal transport flow to raise both accuracy and faithfulness over static methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By learning a data-driven semantic cost via inverse optimal transport and then performing unbalanced optimal-transport-based flow matching between visual patches and textual concepts, OTF-CBM produces velocity-based concept activations that capture interpretable geometric relations; the resulting model attains higher classification accuracy and greater concept faithfulness than prior vision-language CBMs that rely on pre-aligned encoders or global cosine similarity.
What carries the argument
Unbalanced optimal-transport flow matching driven by an inverse-optimal-transport semantic cost, which supplies both the distance measure and the velocity field used for concept activation.
If this is right
- Classification accuracy on downstream tasks rises because the alignment respects measured semantic distances rather than assuming uniform similarity.
- Concept activations become directly readable from transport velocities, eliminating the need to integrate ordinary differential equations.
- Fine-grained localization of textual concepts inside image patches improves because the flow operates at the patch level.
- The same transport machinery can be reused for any pair of modalities once the inverse-optimal-transport cost has been learned.
Where Pith is reading between the lines
- The velocity fields could be inspected post-training to discover previously unnoticed cross-modal concept hierarchies.
- Replacing the learned cost with a hand-crafted one would test whether the performance gain truly depends on the data-driven geometry.
- The approach may extend to video or 3-D data by treating time or depth as an additional transport dimension.
Load-bearing premise
A cost function recovered from inverse optimal transport together with unbalanced flow matching will produce alignments that are both more accurate and more human-interpretable than those obtained from static similarity measures.
What would settle it
A head-to-head comparison on a held-out vision-language dataset in which a static cosine-similarity CBM records both higher classification accuracy and higher human-rated concept faithfulness scores than OTF-CBM.
Figures

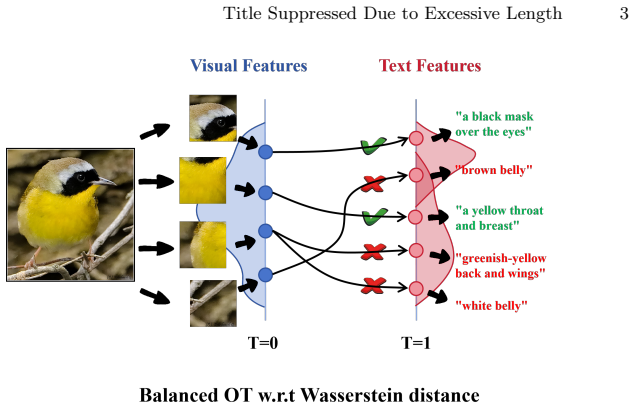
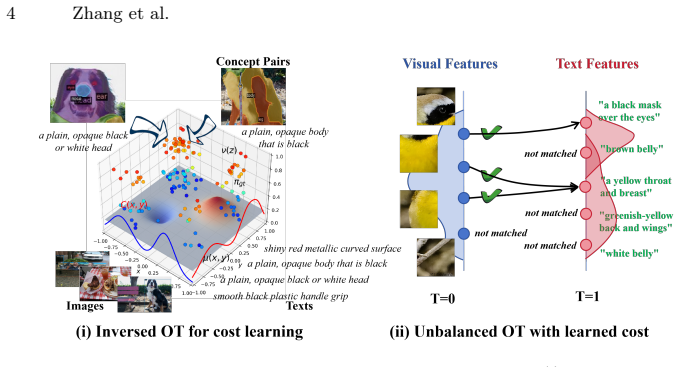
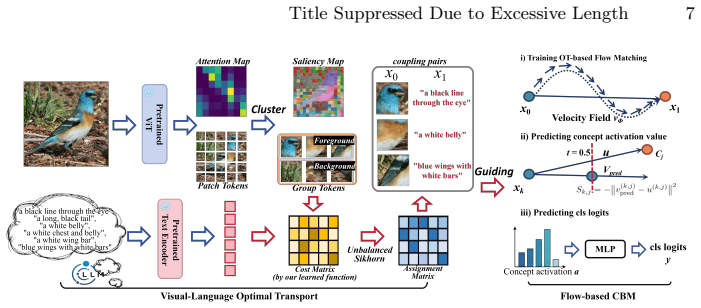
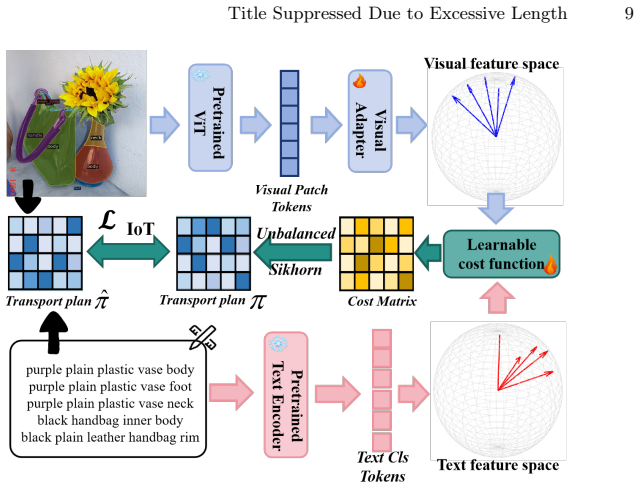
read the original abstract
Concept Bottleneck Models (CBMs) promise transparent reasoning by predicting through human-interpretable concepts, yet their effectiveness fundamentally depends on how well visual and textual representations are aligned or matched. Existing vision-language CBMs often rely on pre-aligned encoders or global cosine similarity, which obscures fine-grained concept localization and fails to reflect true semantic geometry. In this work, we rethink concept alignment as a dynamic cross-modal transport process instead of static projection and propose the Optimal Transport Flow Concept Bottleneck Model (OTF-CBM). It first learns a data-driven semantic cost via Inverse Optimal Transport to measure cross-modal distances, and then performs unbalanced optimal-transport-based flow matching to model semantic transitions between visual patches and textual concepts. With velocity-based concept activation, OTF-CBM captures interpretable geometric relations without ODE integration. Experiments further show that OTF-CBM achieves superior classification accuracy and concept faithfulness, offering a new geometric and dynamical perspective for interpretable cross-modal reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Optimal Transport Flow Concept Bottleneck Model (OTF-CBM) that re-frames concept alignment in vision-language CBMs as a dynamic cross-modal transport process. It first learns a data-driven semantic cost via Inverse Optimal Transport and then applies unbalanced optimal-transport-based flow matching to produce velocity-based concept activations between visual patches and textual concepts, claiming this yields superior classification accuracy and concept faithfulness over static alignment baselines while providing a geometric and dynamical perspective on interpretable reasoning.
Significance. If the superiority claims are substantiated by properly reported experiments, the work supplies a transport-theoretic alternative to cosine-based or pre-aligned encoder approaches in CBMs, potentially improving fine-grained localization and interpretability through explicit flow and velocity fields.
major comments (1)
- [Abstract] Abstract: the central claim that OTF-CBM 'achieves superior classification accuracy and concept faithfulness' is asserted without any reported metrics, baselines, ablation studies, or experimental protocol, so the empirical support for the method cannot be evaluated from the provided text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and agree that the abstract requires revision to better support its claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that OTF-CBM 'achieves superior classification accuracy and concept faithfulness' is asserted without any reported metrics, baselines, ablation studies, or experimental protocol, so the empirical support for the method cannot be evaluated from the provided text.
Authors: We agree that the abstract asserts the performance claim at a high level without quantitative details. The full manuscript reports these results, including accuracy improvements, concept faithfulness metrics, baseline comparisons, and ablations, in the Experiments section. To resolve the issue, we will revise the abstract to include concise references to the key metrics and experimental protocol while preserving its brevity. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and description present OTF-CBM as learning a semantic cost via Inverse Optimal Transport from data and then applying unbalanced OT flow matching to model transitions, with velocity-based activations. These steps are described as data-driven applications of standard OT techniques to cross-modal alignment, without any equations, self-definitions, fitted inputs renamed as predictions, or load-bearing self-citations that reduce the central claims to tautologies or prior author work by construction. The derivation chain relies on external OT methods applied to the problem rather than internal fitting or renaming, making the result self-contained against benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2209.15571 (2022) 5
Albergo, M.S., Vanden-Eijnden, E.: Building normalizing flows with stochastic interpolants. arXiv preprint arXiv:2209.15571 (2022) 5
Pith/arXiv arXiv 2022
-
[2]
IEEE Transactions on Automatic Control61(2), 526–531 (2015) 11 Title Suppressed Due to Excessive Length 17
Chen, Y., Georgiou, T.T.: Stochastic bridges of linear systems. IEEE Transactions on Automatic Control61(2), 526–531 (2015) 11 Title Suppressed Due to Excessive Length 17
2015
-
[3]
Siam Review63(2), 249–313 (2021) 5
Chen, Y., Georgiou, T.T., Pavon, M.: Stochastic control liaisons: [r]ichard [s]inkhorn meets [g]aspard [m]onge on a [s]chrödinger bridge. Siam Review63(2), 249–313 (2021) 5
2021
-
[4]
In: International Conference on Machine Learning
Chiu, W.T., Wang, P., Shafto, P.: Discrete probabilistic inverse optimal transport. In: International Conference on Machine Learning. pp. 3925–3946. PMLR (2022) 2
2022
-
[5]
arXiv preprint arXiv:1607.05816 (2016) 3
Chizat, L., Peyré, G., Schmitzer, B., Vialard, F.X.: Scaling algorithms for unbal- anced transport problems. arXiv preprint arXiv:1607.05816 (2016) 3
Pith/arXiv arXiv 2016
-
[6]
Mathematics of computation87(314), 2563– 2609 (2018) 5
Chizat, L., Peyré, G., Schmitzer, B., Vialard, F.X.: Scaling algorithms for unbal- anced optimal transport problems. Mathematics of computation87(314), 2563– 2609 (2018) 5
2018
-
[7]
Journal of Functional Analysis274(11), 3090–3123 (2018) 5
Chizat, L., Peyré, G., Schmitzer, B., Vialard, F.X.: Unbalanced optimal transport: Dynamic and Kantorovich formulations. Journal of Functional Analysis274(11), 3090–3123 (2018) 5
2018
-
[8]
In: Proceedings of the European Conference on Computer Vision, Munich, Germany
Courty, N., Flamary, R., Habrard, A., Rakotomamonjy, A.: Joint distribution opti- mal transport for domain adaptation. In: Proceedings of the European Conference on Computer Vision, Munich, Germany. pp. 8–14 (2018) 5
2018
-
[9]
Ad- vances in Neural Information Processing Systems26(2013) 5
Cuturi, M.: Sinkhorn distances: Lightspeed computation of optimal transport. Ad- vances in Neural Information Processing Systems26(2013) 5
2013
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
De Plaen, H., De Plaen, P.F., Suykens, J.A., Proesmans, M., Tuytelaars, T., Van Gool, L.: Unbalanced optimal transport: A unified framework for object de- tection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3198–3207 (2023) 3
2023
-
[11]
In: 2009 IEEE Conference on Computer Vision and Pattern Recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition. pp. 248–255. Ieee (2009) 12
2009
-
[12]
In: 2024 IEEE 63rd Conference on Decision and Control (CDC)
Dong, A., Chen, C., Georgiou, T.T.: Network learning with directional sign pat- terns. In: 2024 IEEE 63rd Conference on Decision and Control (CDC). pp. 3924–
2024
-
[13]
arXiv e-prints pp
Dong, A.,Chen, Y.,Johansson,K.H., Karlsson,J.:Meanflowmeetscontrol:Scaling sampled-data control for swarms. arXiv e-prints pp. arXiv–2603 (2026) 5
2026
-
[14]
Automatica177, 112283 (2025) 5
Dong, A., Georgiou, T.T., Tannenbaum, A.: Data Assimilation for Sign-indefinite Priors: A generalization of Sinkhorn’s algorithm. Automatica177, 112283 (2025) 5
2025
-
[15]
EDITORIAL COMMITTEE p
Dong, A., Georgiou, T.T., Tannenbaum, A.: Negative probabilities and the Sinkhorn Algorithm: Promotion/Inhibition interactions in networks. EDITORIAL COMMITTEE p. 61 (2025) 5
2025
-
[16]
Automatica160, 111448 (2024) 5
Dong, A., Stephanovitch, A., Georgiou, T.T.: Monge–Kantorovich optimal trans- port through constrictions and flow-rate constraints. Automatica160, 111448 (2024) 5
2024
-
[17]
Advances in Neural Information Processing Systems35, 21400–21413 (2022) 14
Espinosa Zarlenga, M., Barbiero, P., Ciravegna, G., Marra, G., Giannini, F., Dili- genti, M., Shams, Z., Precioso, F., Melacci, S., Weller, A., et al.: Concept em- bedding models: Beyond the accuracy-explainability trade-off. Advances in Neural Information Processing Systems35, 21400–21413 (2022) 14
2022
-
[18]
In: International conference on ma- chine learning
Fatras, K., Séjourné, T., Flamary, R., Courty, N.: Unbalanced minibatch optimal transport; applications to domain adaptation. In: International conference on ma- chine learning. pp. 3186–3197. PMLR (2021) 5
2021
-
[19]
Princeton University Press (2016) 5 18 Zhang et al
Galichon, A.: Optimal transport methods in economics. Princeton University Press (2016) 5 18 Zhang et al
2016
-
[20]
In: International Conference on Machine Learning
Koh, P.W., Nguyen, T., Tang, Y.S., Mussmann, S., Pierson, E., Kim, B., Liang, P.: Concept bottleneck models. In: International Conference on Machine Learning. pp. 5338–5348. PMLR (2020) 1, 3, 4, 14
2020
-
[21]
Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images (2009) 12
2009
-
[22]
Journal of Machine Learning Research20(80), 1–37 (2019) 2, 5, 12
Li, R., Ye, X., Zhou, H., Zha, H.: Learning to match via inverse optimal transport. Journal of Machine Learning Research20(80), 1–37 (2019) 2, 5, 12
2019
-
[23]
arXiv preprint arXiv:2210.02747 (2022) 3, 5, 12
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022) 3, 5, 12
Pith/arXiv arXiv 2022
-
[24]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Liu, Q., Yin, X., Yuille, A., Brown, A., Singh, M.: Flowing from words to pixels: A noise-free framework for cross-modality evolution. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2755–2765 (2025) 5
2025
-
[25]
arXiv preprint arXiv:2209.03003 (2022) 12
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022) 12
Pith/arXiv arXiv 2022
-
[26]
arXiv preprint arXiv:2002.09650 (2020) 2, 12
Ma, S., Sun, H., Ye, X., Zha, H., Zhou, H.: Learning cost functions for optimal transport. arXiv preprint arXiv:2002.09650 (2020) 2, 12
arXiv 2002
-
[27]
arXiv preprint arXiv:2304.06129 (2023) 2, 4
Oikarinen, T., Das, S., Nguyen, L.M., Weng, T.W.: Label-free concept bottleneck models. arXiv preprint arXiv:2304.06129 (2023) 2, 4
arXiv 2023
-
[28]
arXiv preprint arXiv:2304.07193 (2023) 13
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023) 13
Pith/arXiv arXiv 2023
-
[29]
Now Foundations and Trends (2019) 2, 5
Peyré, G., Cuturi, M.: Computational optimal transport: With applications to data science. Now Foundations and Trends (2019) 2, 5
2019
-
[30]
Springer (1998) 5
Rachev, S.T., Rüschendorf, L.: Mass Transportation Problems: Volume I: Theory. Springer (1998) 5
1998
-
[31]
In: International Conference on Machine Learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning. pp. 8748–8763. PmLR (2021) 1, 2, 3, 4, 13
2021
-
[32]
Handbook of Numerical Analysis24, 407–471 (2023) 3, 5
Séjourné, T., Peyré, G., Vialard, F.X.: Unbalanced optimal transport, from theory to numerics. Handbook of Numerical Analysis24, 407–471 (2023) 3, 5
2023
-
[33]
arXiv preprint arXiv:2404.03323 (2024) 14
Semenov, A., Ivanov, V., Beznosikov, A., Gasnikov, A.: Sparse concept bottleneck models: Gumbel tricks in contrastive learning. arXiv preprint arXiv:2404.03323 (2024) 14
arXiv 2024
-
[34]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Shang, C., Zhou, S., Zhang, H., Ni, X., Yang, Y., Wang, Y.: Incremental resid- ual concept bottleneck models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11030–11040 (2024) 4
2024
-
[35]
Advances in Neural Information Processing Systems36, 26966– 26990 (2023) 14
Sheth, I., Ebrahimi Kahou, S.: Auxiliary losses for learning generalizable concept- based models. Advances in Neural Information Processing Systems36, 26966– 26990 (2023) 14
2023
-
[36]
Srivastava, D., Yan, G., Weng, L.: Vlg-cbm: Training concept bottleneck models withvision-languageguidance.AdvancesinNeuralInformationProcessingSystems 37, 79057–79094 (2024) 1, 2
2024
-
[37]
arXiv preprint arXiv:2302.00482 (2023) 5, 13
Tong, A., Fatras, K., Malkin, N., Huguet, G., Zhang, Y., Rector-Brooks, J., Wolf, G.,Bengio,Y.:Improvingandgeneralizingflow-basedgenerativemodelswithmini- batch optimal transport. arXiv preprint arXiv:2302.00482 (2023) 5, 13
Pith/arXiv arXiv 2023
-
[38]
arXiv preprint arXiv:2307.03672 (2023) 11 Title Suppressed Due to Excessive Length 19
Tong, A., Malkin, N., Fatras, K., Atanackovic, L., Zhang, Y., Huguet, G., Wolf, G., Bengio, Y.: Simulation-free schr\" odinger bridges via score and flow matching. arXiv preprint arXiv:2307.03672 (2023) 11 Title Suppressed Due to Excessive Length 19
arXiv 2023
-
[39]
Advances in Neural Information Processing Systems37, 51787–51810 (2024) 1, 3
Vandenhirtz, M., Laguna, S., Marcinkevičs, R., Vogt, J.: Stochastic concept bottle- neck models. Advances in Neural Information Processing Systems37, 51787–51810 (2024) 1, 3
2024
-
[40]
Villani, C.: Topics in optimal transportation, vol. 58. American Mathematical Soc. (2021) 5
2021
-
[41]
Villani, C., et al.: Optimal transport: Old and new, vol. 338. Springer (2009) 2
2009
-
[42]
Wah,C.,Branson,S.,Welinder,P.,Perona,P.,Belongie,S.,etal.:Thecaltech-ucsd birds-200-2011 dataset. Tech. rep., Technical Report CNS-TR-2011-001, California Institute of Technology (2011) 12
2011
-
[43]
IEEE Transactions on Pattern Analysis and Machine Intelligence41(9), 2251–2265 (2018) 12
Xian, Y., Lampert, C.H., Schiele, B., Akata, Z.: Zero-shot learning—a comprehen- sive evaluation of the good, the bad and the ugly. IEEE Transactions on Pattern Analysis and Machine Intelligence41(9), 2251–2265 (2018) 12
2018
-
[44]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xie, Y., Zeng, Z., Zhang, H., Ding, Y., Wang, Y., Wang, Z., Chen, B., Liu, H.: Discovering fine-grained visual-concept relations by disentangled optimal trans- port concept bottleneck models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 30199–30209 (2025) 4, 14
2025
-
[45]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, Y., Panagopoulou, A., Zhou, S., Jin, D., Callison-Burch, C., Yatskar, M.: Language in a bottle: Language model guided concept bottlenecks for interpretable image classification. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19187–19197 (2023) 1, 2, 4, 14
2023
-
[46]
arXiv preprint arXiv:2509.24936 (2025) 5
Yue,A.,Dong,A.,Xu,H.:OAT-FM:OptimalAccelerationTransportforImproved Flow Matching. arXiv preprint arXiv:2509.24936 (2025) 5
arXiv 2025
-
[47]
arXiv preprint arXiv:2205.15480 (2022) 1, 3, 4
Yuksekgonul, M., Wang, M., Zou, J.: Post-hoc concept bottleneck models. arXiv preprint arXiv:2205.15480 (2022) 1, 3, 4
arXiv 2022
-
[48]
IEEE transactions on pattern analysis and machine intelligence40(6), 1452–1464 (2017) 12
Zhou, B., Lapedriza, A., Khosla, A., Oliva, A., Torralba, A.: Places: A 10 million image database for scene recognition. IEEE transactions on pattern analysis and machine intelligence40(6), 1452–1464 (2017) 12
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.