Democratizing and accelerating AI-driven pathology research through agentic intelligence
Pith reviewed 2026-06-27 04:31 UTC · model grok-4.3
The pith
PathLab converts natural-language research objectives into validated computational pathology workflows that match expert performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
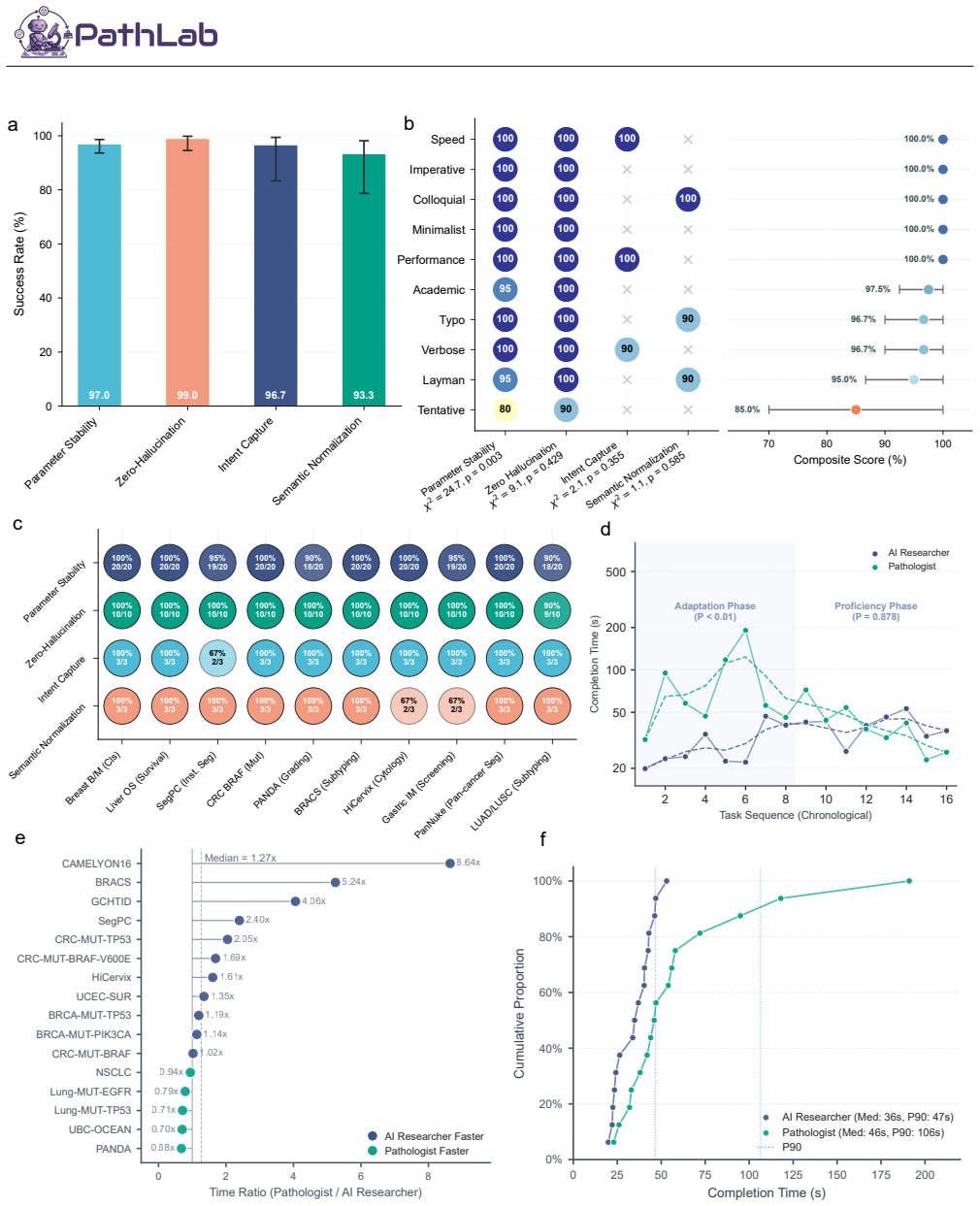
PathLab achieves non-inferior performance relative to expert implementations across all task categories on twelve public datasets while consistently enforcing semantic validity of user prompts and proactively rejecting incompatible workflow specifications prior to execution. By organizing workflow generation around reusable methodological modules, the framework enables studies to be specified at the level of scientific intent rather than implementation details, and controlled user studies confirm it reduces pipeline generation time and empowers domain experts without programming experience to independently design, execute, and evaluate computational pathology studies.
What carries the argument
PathLab, an autonomous agentic framework that translates natural-language research objectives into executable workflows through the structured composition of domain-specific skills and tools for preprocessing, model development, evaluation, and interpretation.
If this is right
- Computational pathology studies can be designed at the level of scientific questions rather than programming details.
- Domain experts without programming experience can independently design, execute, and evaluate studies.
- Workflow generation time is substantially reduced while semantic validity is enforced before any code runs.
- Performance remains non-inferior across region-of-interest classification, whole-slide classification, segmentation, and survival prediction on diverse public datasets.
Where Pith is reading between the lines
- The same agentic composition approach could be adapted to other biomedical imaging domains that rely on foundation models.
- Over repeated use the system might surface recurring patterns in how scientific intent maps to computational choices, informing future tool design.
- Integration with newer foundation models could extend the range of tasks the agent can handle without additional human coding.
Load-bearing premise
The structured composition of domain-specific skills and tools can reliably translate arbitrary natural-language objectives into executable, semantically valid, and validated workflows.
What would settle it
A new pathology dataset or task on which PathLab either generates semantically invalid workflows that domain experts reject or delivers performance measurably below that of expert implementations would falsify the central claim.
Figures





read the original abstract
Computational pathology has advanced rapidly with the emergence of foundation models, yet widespread adoption remains limited by substantial technical complexity and programming requirements. Here we present PathLab, an autonomous agentic framework that translates natural-language research objectives into executable and validated computational pathology workflows through the structured composition of domain-specific skills and tools. By organizing workflow generation around reusable methodological modules, including data preprocessing, model development, evaluation and interpretation, PathLab enables studies to be specified at the level of scientific intent rather than implementation details. We evaluated PathLab across 12 public datasets spanning four representative task families: region-of-interest classification, whole-slide image classification, segmentation and survival prediction. Across all task categories, PathLab achieved non-inferior performance relative to expert implementations, while consistently enforcing semantic validity of user prompts and proactively rejecting incompatible workflow specifications prior to execution. In controlled user studies, PathLab substantially reduced the time required to generate executable analytical pipelines and enabled domain experts without programming experience to independently design, execute and evaluate computational pathology studies. Together, these results establish PathLab as a reliable interface between biomedical intent and computational execution, enabling computational pathology studies to be designed at the level of scientific questions rather than programming expertise. By lowering technical barriers to advanced AI methodologies, PathLab provides a foundation for the broader democratization of computational pathology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PathLab, an autonomous agentic framework that translates natural-language research objectives into executable and validated computational pathology workflows via structured composition of domain-specific skills and tools (data preprocessing, model development, evaluation, interpretation). It evaluates the system on 12 public datasets across four task families (region-of-interest classification, whole-slide image classification, segmentation, survival prediction), claiming non-inferior performance to expert implementations, consistent enforcement of semantic validity with proactive rejection of incompatible specifications, and substantial reductions in time and barriers for non-programmer domain experts in controlled user studies.
Significance. If the core claims hold with rigorous supporting evidence, the work would be significant for computational pathology and AI agent research by providing a practical interface that lowers programming barriers, potentially enabling broader adoption of foundation models and advanced analyses by biomedical researchers without coding expertise.
major comments (2)
- [Abstract] Abstract (second paragraph): the central claim of non-inferior performance 'across all task categories' on 12 datasets is presented without any quantitative metrics, error bars, statistical comparisons, dataset identifiers, or baseline details, which is load-bearing for assessing whether the NL-to-workflow translation reliably produces valid results.
- [Abstract] Abstract (second paragraph): no quantitative characterization is given of failure modes, out-of-distribution prompt handling, rejection rates for incompatible specifications, or robustness on arbitrary objectives, leaving the representativeness of the 12-dataset results for real-world reliability unassessed and directly relevant to the weakest assumption about reliable translation of natural-language objectives.
minor comments (1)
- [Abstract] The abstract uses 'non-inferior' without defining the statistical criterion or margin used for the comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the abstract. We agree that additional quantitative details would strengthen the presentation of the central claims. We will revise the abstract in the next version of the manuscript to incorporate relevant metrics and characterizations drawn from the full results. Our point-by-point responses are below.
read point-by-point responses
-
Referee: [Abstract] Abstract (second paragraph): the central claim of non-inferior performance 'across all task categories' on 12 datasets is presented without any quantitative metrics, error bars, statistical comparisons, dataset identifiers, or baseline details, which is load-bearing for assessing whether the NL-to-workflow translation reliably produces valid results.
Authors: We agree that the abstract presents the non-inferiority claim at a summary level without the supporting quantitative details. The full manuscript reports these elements in the Results section, including performance metrics with error bars and statistical comparisons to expert baselines across the 12 datasets (with identifiers) spanning the four task families. We will revise the abstract to include representative quantitative summaries and dataset references to make the claim more transparent and self-contained. revision: yes
-
Referee: [Abstract] Abstract (second paragraph): no quantitative characterization is given of failure modes, out-of-distribution prompt handling, rejection rates for incompatible specifications, or robustness on arbitrary objectives, leaving the representativeness of the 12-dataset results for real-world reliability unassessed and directly relevant to the weakest assumption about reliable translation of natural-language objectives.
Authors: We agree that the abstract does not include quantitative details on failure modes, OOD prompt handling, rejection rates, or robustness. The manuscript contains dedicated evaluations of these aspects, including rejection of incompatible specifications and robustness testing. We will revise the abstract to add a concise quantitative characterization of these elements to better address reliability concerns. revision: yes
Circularity Check
No circularity: empirical claims rest on external dataset evaluations rather than self-referential definitions or fits
full rationale
The paper describes PathLab as an agentic system that composes reusable methodological modules (preprocessing, model development, evaluation, interpretation) to convert natural-language objectives into workflows. Its performance claims are presented as measured outcomes on 12 independent public datasets across four task families, with direct comparison to expert implementations, plus separate controlled user studies. These results are not defined into existence by the framework description, nor do any equations or parameters reduce a 'prediction' to a fitted input by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify core premises. The evaluation uses external benchmarks, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A.et al.Application of artificial intelligence and digital tools in cancer pathology.The Lancet Digit
Shaktah, L. A.et al.Application of artificial intelligence and digital tools in cancer pathology.The Lancet Digit. Heal.7 (2025)
2025
- [2]
-
[3]
J.et al.Towards a general-purpose foundation model for computational pathology.Nat
Chen, R. J.et al.Towards a general-purpose foundation model for computational pathology.Nat. medicine30, 850–862 (2024)
2024
-
[4]
medicine30, 2924–2935 (2024)
V orontsov, E.et al.A foundation model for clinical-grade computational pathology and rare cancers detection.Nat. medicine30, 2924–2935 (2024)
2024
-
[5]
Ma, J.et al.A generalizable pathology foundation model using a unified knowledge distillation pretraining framework. Nat. Biomed. Eng.1–20 (2025). 6.Xu, Y .et al.A multimodal knowledge-enhanced whole-slide pathology foundation model.Nat. Commun.(2025)
2025
-
[6]
Molecular-driven foundation model for oncologic pathology.arXiv preprint arXiv:2501.16652, 2025
Wang, X.et al.A pathology foundation model for cancer diagnosis and prognosis prediction.Nature634, 970–978 (2024). 8.Vaidya, A.et al.Molecular-driven foundation model for oncologic pathology.arXiv preprint arXiv:2501.16652(2025)
-
[7]
Y .et al.Data-efficient and weakly supervised computational pathology on whole-slide images.Nat
Lu, M. Y .et al.Data-efficient and weakly supervised computational pathology on whole-slide images.Nat. Biomed. Eng. 5, 555–570 (2021)
2021
-
[8]
arXiv preprint arXiv:2501.15724(2025)
Li, D.et al.A survey on computational pathology foundation models: Datasets, adaptation strategies, and evaluation tasks. arXiv preprint arXiv:2501.15724(2025)
-
[9]
Maleki, D.et al.Understanding foundation models in digital pathology: Performance, trade-offs, and model-selection recommendations.bioRxiv2025–09 (2025)
2025
- [10]
-
[11]
Bilal, M.et al.Foundation models in computational pathology: A review of challenges, opportunities, and impact.arXiv preprint arXiv:2502.08333(2025). 14.Guo, D.et al.Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature645, 633–638 (2025). 15.Yang, A.et al.Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
-
[12]
Autonomous Agents for Scientific Discovery: Orchestrating Scientists, Language, Code, and Physics
Zhou, L.et al.Autonomous agents for scientific discovery: Orchestrating scientists, language, code, and physics.arXiv preprint arXiv:2510.09901(2025). 17.Ghareeb, A. E.et al.A multi-agent system for automating scientific discovery.Nature1–3 (2026). 18.Gottweis, J.et al.Accelerating scientific discovery with co-scientist.Nature1–3 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Medicine1–13 (2026)
Trost, F.et al.An agentic framework for autonomous scientific discovery in cancer pathology.Nat. Medicine1–13 (2026). 14 20.Lu, C.et al.Towards end-to-end automation of ai research.Nature651, 914–919 (2026)
2026
-
[14]
Agrawal, S.et al.Can ai conduct autonomous scientific research? case studies on two real-world tasks.bioRxiv2026–01 (2026)
2026
-
[15]
23.Xu, G.et al.A comprehensive survey of agentic ai in healthcare.Authorea Prepr.(2025)
Wang, R.et al.Qcagent: An agentic framework for quality-controllable pathology report generation from whole slide image.arXiv preprint arXiv:2603.01647(2026). 23.Xu, G.et al.A comprehensive survey of agentic ai in healthcare.Authorea Prepr.(2025)
- [16]
-
[17]
Su, F.et al.Development and validation of a deep learning system for ascites cytopathology interpretation.Gastric Cancer 23, 1041–1050 (2020)
2020
-
[18]
Data12, 138 (2025)
Lou, S.et al.A large histological images dataset of gastric cancer with tumour microenvironment annotation for ai.Sci. Data12, 138 (2025)
2025
-
[19]
& Bjerregaard, B
Jantzen, J., Norup, J., Dounias, G. & Bjerregaard, B. Pap-smear benchmark data for pattern classification.Nat. inspired smart information systems (NiSIS 2005)1–9 (2005)
2005
-
[20]
Cai, D.et al.Hicervix: An extensive hierarchical dataset and benchmark for cervical cytology classification.IEEE transactions on medical imaging43, 4344–4355 (2024)
2024
-
[21]
Brancati, N.et al.Bracs: A dataset for breast carcinoma subtyping in h&e histology images.Database2022, baac093 (2022)
2022
-
[22]
31.Weinstein, J
Ehteshami Bejnordi, B.et al.Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer.Jama318, 2199–2210 (2017). 31.Weinstein, J. N.et al.The cancer genome atlas pan-cancer analysis project.Nat. genetics45, 1113–1120 (2013)
2017
-
[23]
J.et al.The cptac data portal: a resource for cancer proteomics research.J
Edwards, N. J.et al.The cptac data portal: a resource for cancer proteomics research.J. proteome research14, 2707–2713 (2015)
2015
-
[24]
medicine28, 154–163 (2022)
Bulten, W.et al.Artificial intelligence for diagnosis and gleason grading of prostate cancer: the panda challenge.Nat. medicine28, 154–163 (2022)
2022
-
[25]
Asadi-Aghbolaghi, M.et al.Machine learning-driven histotype diagnosis of ovarian carcinoma: insights from the ocean ai challenge.medRxiv2024–04 (2024)
2024
-
[26]
Gupta, A., Gupta, R., Gehlot, S. & Goswami, S. Segpc-2021: Segmentation of multiple myeloma plasma cells in microscopic images, 2021.URL: https://dx. doi. org/10.21227/7np1-2q42. doi10. 15 Supplementary Information Dataset Task Total Endpoint details Split protocol Ascites2020 ROI classification 7,880 6-class ascites cytology; strongly imbalanced toward m...
-
[27]
Task & Data Type Mismatch English Prompts (1-10)
-
[28]
I want to train a segmentation model using the Liver_OS dataset to precisely delineate the tumor boundaries in the WSIs
“I want to train a segmentation model using the Liver_OS dataset to precisely delineate the tumor boundaries in the WSIs.”
-
[29]
Please set up a patient survival prediction task using the PanNuke dataset
“Please set up a patient survival prediction task using the PanNuke dataset.”
-
[30]
Can we run a survival analysis on the BRACS dataset? I want to predict patient outcomes
“Can we run a survival analysis on the BRACS dataset? I want to predict patient outcomes.”
-
[31]
Train a WSI classification model using the CRC-MSI dataset to differentiate the slides
“Train a WSI classification model using the CRC-MSI dataset to differentiate the slides.”
-
[32]
I’d like to use the SegPC dataset to classify bone marrow cancer vs normal tissues
“I’d like to use the SegPC dataset to classify bone marrow cancer vs normal tissues.”
-
[33]
Let’s do tissue segmentation on the Lung_Cancer Nanfang Cohort WSIs
“Let’s do tissue segmentation on the Lung_Cancer Nanfang Cohort WSIs.”
-
[34]
Configure a prognosis survival model on the HiCervix cell patches
“Configure a prognosis survival model on the HiCervix cell patches.”
-
[35]
Build an ISUP grading segmentation mask generator using the PANDA dataset
“Build an ISUP grading segmentation mask generator using the PANDA dataset.”
-
[36]
Use the CAMELYON16 WSIs to extract 256x256 patches and directly output a segmentation mask using U-Net
“Use the CAMELYON16 WSIs to extract 256x256 patches and directly output a segmentation mask using U-Net.”
-
[37]
Can you train a Cox proportional hazards model on the UBC-OCEAN dataset?
“Can you train a Cox proportional hazards model on the UBC-OCEAN dataset?” 中文Prompts (1-10)
-
[38]
帮我用Liver_OS数据集训练一个分割模型,我想把肝癌WSI里的肿瘤区域精准勾画出来。
“帮我用Liver_OS数据集训练一个分割模型,我想把肝癌WSI里的肿瘤区域精准勾画出来。”
-
[39]
请用PanNuke细胞核数据集建一个患者生存期预测模型。
“请用PanNuke细胞核数据集建一个患者生存期预测模型。”
-
[40]
用BRACS乳腺癌数据集跑一个生存分析吧,我想看看患者预后。
“用BRACS乳腺癌数据集跑一个生存分析吧,我想看看患者预后。”
-
[41]
在CRC-MSI这个数据集上,配置一个整切片(WSI)级别的分类任务。
“在CRC-MSI这个数据集上,配置一个整切片(WSI)级别的分类任务。”
-
[42]
我想用SegPC数据集训练一个骨髓瘤细胞的分类器(正常vs异常)。
“我想用SegPC数据集训练一个骨髓瘤细胞的分类器(正常vs异常)。”
-
[43]
帮我在Lung_Cancer南方医院队列上做一个组织分割任务,把良恶性区域割出来。
“帮我在Lung_Cancer南方医院队列上做一个组织分割任务,把良恶性区域割出来。”
-
[44]
用HiCervix宫颈细胞切片预测一下患者的总生存期(OS)。
“用HiCervix宫颈细胞切片预测一下患者的总生存期(OS)。”
-
[45]
基于PANDA数据集,训练一个U-Net模型来生成前列腺癌的掩膜(Mask)。
“基于PANDA数据集,训练一个U-Net模型来生成前列腺癌的掩膜(Mask)。”
-
[46]
用CAMELYON16训练一个模型,输入整张WSI,直接输出乳腺癌转移的精准分割边界。
“用CAMELYON16训练一个模型,输入整张WSI,直接输出乳腺癌转移的精准分割边界。”
-
[47]
针对UBC-OCEAN数据集,配置一个Cox生存预测任务吧。
“针对UBC-OCEAN数据集,配置一个Cox生存预测任务吧。” Architecture & OOM Disasters English Prompts (11-20)
-
[48]
Configure a training task on the LUAD_LUSC (TCGA) dataset. Set the batch_size to 64 to speed up WSI training
“Configure a training task on the LUAD_LUSC (TCGA) dataset. Set the batch_size to 64 to speed up WSI training.”
-
[49]
For the CRC-MSI patch dataset, please use the ABMIL aggregator to train the model
“For the CRC-MSI patch dataset, please use the ABMIL aggregator to train the model.”
-
[50]
Train a U-Net segmentation model on the PANDA dataset to find the Gleason patterns
“Train a U-Net segmentation model on the PANDA dataset to find the Gleason patterns.”
-
[51]
Let’s use TransMIL to aggregate features for the HiCervix cell classification task
“Let’s use TransMIL to aggregate features for the HiCervix cell classification task.”
-
[52]
Train a classification model on CAMELYON16 using a simple ’linear’ classifier head
“Train a classification model on CAMELYON16 using a simple ’linear’ classifier head.”
-
[53]
Set up a foundation model segmentation task using ’vit_l_16’ as the backbone
“Set up a foundation model segmentation task using ’vit_l_16’ as the backbone.”
-
[54]
Use CLAM_MB on the SegPC dataset to find the multiple cell branches
“Use CLAM_MB on the SegPC dataset to find the multiple cell branches.”
-
[55]
Train a survival model on Liver_OS using L1 Loss
“Train a survival model on Liver_OS using L1 Loss.”
-
[56]
Set the learning rate to 0.5 and batch size to 128 for the Lung-MUT-EGFR WSI dataset
“Set the learning rate to 0.5 and batch size to 128 for the Lung-MUT-EGFR WSI dataset.”
-
[57]
For the PanNuke dataset, use maxmil as the aggregator to classify the nuclei
“For the PanNuke dataset, use maxmil as the aggregator to classify the nuclei.” 18 中文Prompts (11-20)
-
[58]
配置LUAD_LUSC数据集的训练任务,为了加速收敛,把batch_size设置成64跑WSI。
“配置LUAD_LUSC数据集的训练任务,为了加速收敛,把batch_size设置成64跑WSI。”
-
[59]
针对CRC-MSI这个Patch数据集,帮我配置一个ABMIL聚合器。
“针对CRC-MSI这个Patch数据集,帮我配置一个ABMIL聚合器。”
-
[60]
用U-Net架构在PANDA数据集上跑,我想把不同Gleason分级的区域分出来。
“用U-Net架构在PANDA数据集上跑,我想把不同Gleason分级的区域分出来。”
-
[61]
在HiCervix宫颈细胞分类上,使用TransMIL算法来聚合细胞特征。
“在HiCervix宫颈细胞分类上,使用TransMIL算法来聚合细胞特征。”
-
[62]
用CAMELYON16训练分类模型,分类头直接选最简单的’linear’就行。
“用CAMELYON16训练分类模型,分类头直接选最简单的’linear’就行。”
-
[63]
帮我建一个基础模型分割任务,骨干网络(backbone)指定用vit_l_16。
“帮我建一个基础模型分割任务,骨干网络(backbone)指定用vit_l_16。”
-
[64]
在SegPC数据集上用CLAM_MB多分支模型来预测骨髓瘤细胞。
“在SegPC数据集上用CLAM_MB多分支模型来预测骨髓瘤细胞。”
-
[65]
用Liver_OS训练生存预测模型,损失函数帮我选L1 Loss。
“用Liver_OS训练生存预测模型,损失函数帮我选L1 Loss。”
-
[66]
训练Lung-MUT-EGFR,把学习率设为0.5,batch size设为128猛跑。
“训练Lung-MUT-EGFR,把学习率设为0.5,batch size设为128猛跑。”
-
[67]
PanNuke数据集,用maxmil聚合器把每个细胞核的类别最高分聚合起来。
“PanNuke数据集,用maxmil聚合器把每个细胞核的类别最高分聚合起来。” Statistical & Single-Class Traps English Prompts (21-30)
-
[68]
I want to train a model to ONLY recognize LUAD. Filter the LUAD_LUSC dataset to keep only LUAD cases, and train a classifier on it
“I want to train a model to ONLY recognize LUAD. Filter the LUAD_LUSC dataset to keep only LUAD cases, and train a classifier on it.”
-
[69]
Set up a 5-fold cross-validation training task for the ’Study of Abnormal Cells in Body Fluids’ dataset
“Set up a 5-fold cross-validation training task for the ’Study of Abnormal Cells in Body Fluids’ dataset.”
-
[70]
Filter the Liver_OS dataset to only include patients who died (event=1), and train the survival model to predict their death
“Filter the Liver_OS dataset to only include patients who died (event=1), and train the survival model to predict their death.”
-
[71]
Use the random 7:1:2 split strategy for the ’Study of Abnormal Cells in Body Fluids’ dataset
“Use the random 7:1:2 split strategy for the ’Study of Abnormal Cells in Body Fluids’ dataset.”
-
[72]
Train a model on BRCA-MUT-TP53 to only predict TP53 positive cases without any negative controls
“Train a model on BRCA-MUT-TP53 to only predict TP53 positive cases without any negative controls.”
-
[73]
Let’s do a 50-fold cross validation on the Lung_Cancer dataset to get highly robust metrics
“Let’s do a 50-fold cross validation on the Lung_Cancer dataset to get highly robust metrics.”
-
[74]
Remove all the benign cases from Lung_Cancer Nanfang Cohort and train a diagnostic classifier
“Remove all the benign cases from Lung_Cancer Nanfang Cohort and train a diagnostic classifier.”
-
[75]
Filter out all censored data in Liver_OS because I only care about exact death times, then train Cox
“Filter out all censored data in Liver_OS because I only care about exact death times, then train Cox.”
-
[76]
Run a random split classification training on a tiny subset of PANDA containing only 6 WSIs
“Run a random split classification training on a tiny subset of PANDA containing only 6 WSIs.”
-
[77]
Train a classifier on the CAMELYON16 dataset, but only feed it the normal slides to teach it what normal looks like
“Train a classifier on the CAMELYON16 dataset, but only feed it the normal slides to teach it what normal looks like.” 中文Prompts (21-30)
-
[78]
我想训练一个专门识别LUAD的分类器。把LUAD_LUSC数据集里的LUSC全删掉,只用LUAD训练。
“我想训练一个专门识别LUAD的分类器。把LUAD_LUSC数据集里的LUSC全删掉,只用LUAD训练。”
-
[79]
用’Study of Abnormal Cells in Body Fluids’数据集,帮我跑一个10折交叉验证(10-fold CV)看看效果。
“用’Study of Abnormal Cells in Body Fluids’数据集,帮我跑一个10折交叉验证(10-fold CV)看看效果。”
-
[80]
把Liver_OS里那些没死的患者(censored=0)全剔除,只用明确死亡的患者训练生存预测模型。
“把Liver_OS里那些没死的患者(censored=0)全剔除,只用明确死亡的患者训练生存预测模型。”
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.