DanceDuo: Bridging Human Movement and AI Choreography
Pith reviewed 2026-06-26 04:15 UTC · model grok-4.3
The pith
DanceDuo generates AI-choreographed dance sequences from music via diffusion models and compares them to user performances using pose estimation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
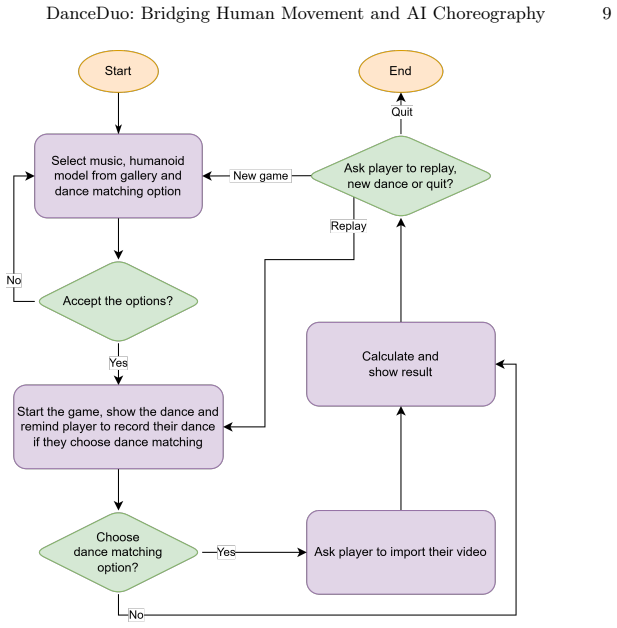
DanceDuo is a platform that leverages diffusion models to generate AI-choreographed dance sequences synchronized with a variety of music genres, integrates human pose estimation models to provide users with insightful comparisons of their own performances with AI-generated sequences, and demonstrates through a user study that the interface is intuitive with particular praise for the dance comparison feature.
What carries the argument
The DanceDuo platform, which combines diffusion-based generation of music-synchronized dances with human pose estimation for direct user-AI movement comparisons.
If this is right
- Users gain a tool to practice dancing by directly comparing their movements to AI-generated sequences.
- The system supports varied experiences through choices of music tracks, humanoid models, and personal video uploads.
- Human pose estimation supplies the mechanism for side-by-side performance feedback.
- Positive user study results on intuitiveness and comparison value support broader recreational and professional use.
Where Pith is reading between the lines
- If the comparison loop proves effective, the same generation-plus-estimation pattern could extend to other movement-based skills such as sports drills.
- Real-time variants of the platform might shorten the gap between generation and feedback for live practice sessions.
- The approach could serve as a template for applying generative models to other creative physical domains beyond dance.
Load-bearing premise
The diffusion-generated dance sequences are synchronized and high-quality enough to support meaningful performance comparisons that encourage practice.
What would settle it
A controlled test in which users rate the AI sequences as poorly matched to the music or show no measurable change in their own dance accuracy after repeated comparisons.
Figures



read the original abstract
In recent years, advancements in deep learning and generative models have revolutionized music-driven dance generation. This paper introduces a novel platform, namely DanceDuo, leveraging diffusion models to generate AI-choreographed dance sequences synchronized with a variety of music genres, to encourage dancing practice. The system allows users to interact with AI by selecting music tracks, humanoid models, and importing personal dance videos for comparison, fostering a rich and engaging user experience. DanceDuo not only offers dance generation but also integrates human pose estimation models to provide users with insightful comparisons of their own performances with AI-generated sequences. We conducted a comprehensive user study, revealing that users found the interface intuitive, with particular praise for the dance comparison feature. Our DanceDuo contributes significantly to the integration of AI in dance choreography, offering novel avenues for both recreational and professional applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DanceDuo, a platform leveraging diffusion models to generate AI-choreographed dance sequences synchronized with music genres, integrating human pose estimation for user performance comparisons, and reporting a user study on interface usability with praise for the comparison feature.
Significance. If the diffusion-generated dances prove sufficiently synchronized and high-quality, the system could provide a useful tool for dance practice and AI-choreography integration. The user study offers limited evidence of usability, but the absence of quantitative validation for the generative component limits assessment of broader impact.
major comments (2)
- [Abstract] Abstract: the central claims that diffusion models produce synchronized sequences enabling 'insightful comparisons' and that the system encourages dancing practice are unsupported, as no quantitative metrics (beat-alignment error, distribution metrics such as FID, or baseline comparisons to prior music-to-dance models) are supplied.
- [User Study] User study description: the study measures only interface intuitiveness and praise for the comparison UI, without testing whether the generated dances themselves are adequate for meaningful comparisons, leaving the core assumption about generative quality untested.
minor comments (1)
- The manuscript would benefit from explicit details on the diffusion model architecture, training procedure, and pose estimation pipeline to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the need for quantitative support of the generative claims. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims that diffusion models produce synchronized sequences enabling 'insightful comparisons' and that the system encourages dancing practice are unsupported, as no quantitative metrics (beat-alignment error, distribution metrics such as FID, or baseline comparisons to prior music-to-dance models) are supplied.
Authors: We agree the abstract makes claims about synchronization and comparison value without supporting quantitative evidence such as beat-alignment error, FID, or baselines. The manuscript centers on platform integration and usability feedback rather than generative model benchmarking. We will revise the abstract to remove these unsupported claims and clarify the scope as a user-facing system. revision: yes
-
Referee: [User Study] User study description: the study measures only interface intuitiveness and praise for the comparison UI, without testing whether the generated dances themselves are adequate for meaningful comparisons, leaving the core assumption about generative quality untested.
Authors: The user study was limited to interface usability and perceived value of the comparison feature. It did not assess objective quality of the generated dances or their suitability for meaningful comparisons. We will add an explicit limitations paragraph noting this gap and that generative adequacy remains untested. revision: yes
Circularity Check
No circularity: system description paper contains no derivations, equations, or fitted predictions
full rationale
The paper is a description of a user-facing platform (DanceDuo) that integrates existing diffusion models for music-to-dance generation and pose-estimation tools for comparison. The abstract and provided text contain no equations, no parameter-fitting steps, no 'predictions' derived from fitted inputs, and no load-bearing self-citations or uniqueness theorems. The central claims concern system features and a user study on interface usability; these do not reduce to any self-referential construction. No derivation chain exists to inspect, so the circularity score is 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abouaf, J.: "biped": a dance with virtual and company dancers. 1. IEEE Multi- Media6(3), 4–7 (1999)
1999
-
[2]
In: Pro- ceedings of the 19th ACM international conference on Multimedia
Alexiadis,D.S.,Kelly,P.,Daras,P.,O’Connor,N.E.,Boubekeur,T.,Moussa,M.B.: Evaluating a dancer’s performance using kinect-based skeleton tracking. In: Pro- ceedings of the 19th ACM international conference on Multimedia. pp. 659–662 (2011)
2011
-
[3]
Journal on Computing and Cultural Heritage (JOCCH)8(4), 1–19 (2015)
Aristidou, A., Stavrakis, E., Charalambous, P., Chrysanthou, Y., Himona, S.L.: Folk dance evaluation using laban movement analysis. Journal on Computing and Cultural Heritage (JOCCH)8(4), 1–19 (2015)
2015
-
[4]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Benzine, A., Chabot, F., Luvison, B., Pham, Q.C., Achard, C.: Pandanet: Anchor-based single-shot multi-person 3d pose estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6856– 6865 (2020)
2020
-
[5]
arXiv preprint arXiv:2207.08089 (2022)
Blau, T., Ganz, R., Kawar, B., Bronstein, A., Elad, M.: Threat model-agnostic adversarial defense using diffusion models. arXiv preprint arXiv:2207.08089 (2022)
-
[6]
In: Proceedings of the Seventh International Conference on Computational Creativity
Brockhoeft, T., Petuch, J., Bach, J., Djerekarov, E., Ackerman, M., Tyson, G.: In- teractive augmented reality for dance. In: Proceedings of the Seventh International Conference on Computational Creativity. pp. 396–403 (2016)
2016
-
[7]
Advances in neural information processing systems33, 1877–1901 (2020)
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems33, 1877–1901 (2020)
1901
-
[8]
Dance notations and robot motion pp
Burton, S.J., Samadani, A.A., Gorbet, R., Kulić, D.: Laban movement analysis and affective movement generation for robots and other near-living creatures. Dance notations and robot motion pp. 25–48 (2016)
2016
-
[9]
IEEE transactions on learning technolo- gies4(2), 187–195 (2010)
Chan, J.C., Leung, H., Tang, J.K., Komura, T.: A virtual reality dance training system using motion capture technology. IEEE transactions on learning technolo- gies4(2), 187–195 (2010)
2010
-
[10]
ACM Transactions on Graphics (TOG)40(4), 1–13 (2021)
Chen, K., Tan, Z., Lei, J., Zhang, S.H., Guo, Y.C., Zhang, W., Hu, S.M.: Chore- omaster: choreography-oriented music-driven dance synthesis. ACM Transactions on Graphics (TOG)40(4), 1–13 (2021)
2021
-
[11]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Dabral, R., Mughal, M.H., Golyanik, V., Theobalt, C.: Mofusion: A framework for denoising-diffusion-based motion synthesis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9760–9770 (2023)
2023
-
[12]
IEEE transactions on visualization and computer graphics 18(3), 501–515 (2011)
Fan, R., Xu, S., Geng, W.: Example-based automatic music-driven conventional dance motion synthesis. IEEE transactions on visualization and computer graphics 18(3), 501–515 (2011)
2011
-
[13]
Imagen Video: High Definition Video Generation with Diffusion Models
Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Gritsenko, A., Kingma, D.P., Poole, B., Norouzi, M., Fleet, D.J., et al.: Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[15]
Advances in Neural Information Processing Systems35, 8633– 8646 (2022)
Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M., Fleet, D.J.: Video diffusion models. Advances in Neural Information Processing Systems35, 8633– 8646 (2022)
2022
-
[16]
ACM Transactions on Graphics (TOG)35(4), 1–11 (2016)
Holden, D., Saito, J., Komura, T.: A deep learning framework for character motion synthesis and editing. ACM Transactions on Graphics (TOG)35(4), 1–11 (2016)
2016
-
[17]
arXiv preprint arXiv:2006.06119 (2020) DanceDuo: Bridging Human Movement and AI Choreography 13
Huang, R., Hu, H., Wu, W., Sawada, K., Zhang, M., Jiang, D.: Dance revolution: Long-term dance generation with music via curriculum learning. arXiv preprint arXiv:2006.06119 (2020) DanceDuo: Bridging Human Movement and AI Choreography 13
-
[18]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Kanazawa, A., Black, M.J., Jacobs, D.W., Malik, J.: End-to-end recovery of human shape and pose. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7122–7131 (2018)
2018
-
[19]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Karras, T., Laine, S., Aila, T.: A style-based generator architecture for generative adversarial networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4401–4410 (2019)
2019
-
[20]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Kim, J., Kim, J., Choi, S.: Flame: Free-form language-based motion synthesis & editing. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 37, pp. 8255–8263 (2023)
2023
-
[21]
In: Universal Access in Human- Computer Interaction
Kitsikidis, A., Dimitropoulos, K., Yilmaz, E., Douka, S., Grammalidis, N.: Multi- sensor technology and fuzzy logic for dancer’s motion analysis and performance evaluation within a 3d virtual environment. In: Universal Access in Human- Computer Interaction. Design and Development Methods for Universal Access: 8th International Conference, UAHCI 2014, Held...
2014
-
[22]
DiffWave: A Versatile Diffusion Model for Audio Synthesis
Kong, Z., Ping, W., Huang, J., Zhao, K., Catanzaro, B.: Diffwave: A versatile diffusion model for audio synthesis. arXiv preprint arXiv:2009.09761 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[23]
IEEE Access10, 44982–45000 (2022)
Kritsis, K., Gkiokas, A., Pikrakis, A., Katsouros, V.: Danceconv: Dance motion generation with convolutional networks. IEEE Access10, 44982–45000 (2022)
2022
-
[24]
ACM Transactions on Intelligent Systems and Technology (TIST)6(2), 1–37 (2015)
Kyan, M., Sun, G., Li, H., Zhong, L., Muneesawang, P., Dong, N., Elder, B., Guan, L.: An approach to ballet dance training through ms kinect and visualization in a cave virtual reality environment. ACM Transactions on Intelligent Systems and Technology (TIST)6(2), 1–37 (2015)
2015
-
[25]
Advances in neural information processing systems32(2019)
Lee, H.Y., Yang, X., Liu, M.Y., Wang, T.C., Lu, Y.D., Yang, M.H., Kautz, J.: Dancing to music. Advances in neural information processing systems32(2019)
2019
-
[26]
In: Proceedings of the AAAI Con- ference on Artificial Intelligence
Li, B., Zhao, Y., Zhelun, S., Sheng, L.: Danceformer: Music conditioned 3d dance generation with parametric motion transformer. In: Proceedings of the AAAI Con- ference on Artificial Intelligence. vol. 36, pp. 1272–1279 (2022)
2022
-
[27]
Neurocomputing 479, 47–59 (2022)
Li, H., Yang, Y., Chang, M., Chen, S., Feng, H., Xu, Z., Li, Q., Chen, Y.: Srdiff: Single image super-resolution with diffusion probabilistic models. Neurocomputing 479, 47–59 (2022)
2022
-
[28]
arXiv preprint arXiv:2008.08171 (2020)
Li, J., Yin, Y., Chu, H., Zhou, Y., Wang, T., Fidler, S., Li, H.: Learning to generate diverse dance motions with transformer. arXiv preprint arXiv:2008.08171 (2020)
-
[29]
arXiv preprint arXiv:2403.10518 (2024)
Li, R., Zhang, Y., Zhang, Y., Zhang, H., Guo, J., Zhang, Y., Liu, Y., Li, X.: Lodge: A coarse to fine diffusion network for long dance generation guided by the characteristic dance primitives. arXiv preprint arXiv:2403.10518 (2024)
-
[30]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Li, R., Yang, S., Ross, D.A., Kanazawa, A.: Ai choreographer: Music conditioned 3d dance generation with aist++. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13401–13412 (2021)
2021
-
[31]
Advances in Neural Information Processing Systems35, 4328–4343 (2022)
Li, X., Thickstun, J., Gulrajani, I., Liang, P.S., Hashimoto, T.B.: Diffusion-lm improves controllable text generation. Advances in Neural Information Processing Systems35, 4328–4343 (2022)
2022
-
[32]
In: Seminal Graphics Papers: Pushing the Boundaries, Volume 2, pp
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: Smpl: A skinned multi-person linear model. In: Seminal Graphics Papers: Pushing the Boundaries, Volume 2, pp. 851–866 (2023)
2023
-
[33]
In: 2018 International Conference on 3D Vision (3DV)
Mehta, D., Sotnychenko, O., Mueller, F., Xu, W., Sridhar, S., Pons-Moll, G., Theobalt, C.: Single-shot multi-person 3d pose estimation from monocular rgb. In: 2018 International Conference on 3D Vision (3DV). pp. 120–130. IEEE (2018) 14 G.-C. Bui-Le et al
2018
-
[34]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A.A., Tzionas, D., Black, M.J.: Expressive body capture: 3d hands, face, and body from a single im- age. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10975–10985 (2019)
2019
-
[35]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Pavlakos, G., Kolotouros, N., Daniilidis, K.: Texturepose: Supervising human mesh estimation with texture consistency. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 803–812 (2019)
2019
-
[36]
DreamFusion: Text-to-3D using 2D Diffusion
Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchical text- conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 1(2), 3 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
In: Proceedings of the IEEE/CVF international conference on computer vision
Rempe, D., Birdal, T., Hertzmann, A., Yang, J., Sridhar, S., Guibas, L.J.: Hu- mor: 3d human motion model for robust pose estimation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11488–11499 (2021)
2021
-
[39]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[40]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., Aberman, K.: Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22500–22510 (2023)
2023
-
[41]
In: ACM SIGGRAPH 2022 confer- ence proceedings
Saharia, C., Chan, W., Chang, H., Lee, C., Ho, J., Salimans, T., Fleet, D., Norouzi, M.: Palette: Image-to-image diffusion models. In: ACM SIGGRAPH 2022 confer- ence proceedings. pp. 1–10 (2022)
2022
-
[42]
In: Proceedings of the 16th ACM international conference on Multimedia
Sheppard, R.M., Kamali, M., Rivas, R., Tamai, M., Yang, Z., Wu, W., Nahrstedt, K.: Advancing interactive collaborative mediums through tele-immersive dance (ted) a symbiotic creativity and design environment for art and computer science. In: Proceedings of the 16th ACM international conference on Multimedia. pp. 579– 588 (2008)
2008
-
[43]
In: Computer Graphics Forum
Shiratori, T., Nakazawa, A., Ikeuchi, K.: Dancing-to-music character animation. In: Computer Graphics Forum. vol. 25, pp. 449–458. Wiley Online Library (2006)
2006
-
[44]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Singer, U., Polyak, A., Hayes, T., Yin, X., An, J., Zhang, S., Hu, Q., Yang, H., Ashual, O., Gafni, O., et al.: Make-a-video: Text-to-video generation without text- video data. arXiv preprint arXiv:2209.14792 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[45]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Siyao, L., Yu, W., Gu, T., Lin, C., Wang, Q., Qian, C., Loy, C.C., Liu, Z.: Bailando: 3d dance generation by actor-critic gpt with choreographic memory. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11050–11059 (2022)
2022
-
[46]
IEEE Transactions on Multimedia23, 497–509 (2020)
Sun, G., Wong, Y., Cheng, Z., Kankanhalli, M.S., Geng, W., Li, X.: Deepdance: music-to-dance motion choreography with adversarial learning. IEEE Transactions on Multimedia23, 497–509 (2020)
2020
-
[47]
Advances in Neural Information Processing Systems35, 9995–10007 (2022)
Sun, J., Wang, C., Hu, H., Lai, H., Jin, Z., Hu, J.F.: You never stop dancing: Non- freezing dance generation via bank-constrained manifold projection. Advances in Neural Information Processing Systems35, 9995–10007 (2022)
2022
-
[48]
In: Proceedings of the IEEE/CVF international conference on computer vision
Sun, Y., Bao, Q., Liu, W., Fu, Y., Black, M.J., Mei, T.: Monocular, one-stage, regression of multiple 3d people. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11179–11188 (2021)
2021
-
[49]
In: Proceedings of the 26th ACM international conference on Multimedia
Tang, T., Jia, J., Mao, H.: Dance with melody: An lstm-autoencoder approach to music-oriented dance synthesis. In: Proceedings of the 26th ACM international conference on Multimedia. pp. 1598–1606 (2018) DanceDuo: Bridging Human Movement and AI Choreography 15
2018
-
[50]
Trajkova,M.,Cafaro,F.:E-ballet:designingforremoteballetlearning.In:Proceed- ings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct. pp. 213–216 (2016)
2016
-
[51]
Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies2(1), 1–30 (2018)
Trajkova, M., Cafaro, F.: Takes tutu to ballet: designing visual and verbal feedback for augmented mirrors. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies2(1), 1–30 (2018)
2018
-
[52]
In: Proceedings of the 20th Pan-Hellenic Conference on Informatics
Tsampounaris, G., El Raheb, K., Katifori, V., Ioannidis, Y.: Exploring visualiza- tions in real-time motion capture for dance education. In: Proceedings of the 20th Pan-Hellenic Conference on Informatics. pp. 1–6 (2016)
2016
-
[53]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Tseng, J., Castellon, R., Liu, K.: Edge: Editable dance generation from music. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 448–458 (2023)
2023
-
[54]
In: Proceedings of the Asian Conference on Computer Vision (2024)
Tuong-Vy, T.T., Gia-Cat, B.L., Hai-Dang, N., Trung-Nghia, L.: Rethinking sam- pling for music-driven long-term dance generation. In: Proceedings of the Asian Conference on Computer Vision (2024)
2024
-
[55]
Advances in neural information processing systems30(2017)
Van Den Oord, A., Vinyals, O., et al.: Neural discrete representation learning. Advances in neural information processing systems30(2017)
2017
-
[56]
In: Forty- first International Conference on Machine Learning (2024)
Yang, L., Yu, Z., Meng, C., Xu, M., Ermon, S., Bin, C.: Mastering text-to-image diffusion: Recaptioning, planning, and generating with multimodal llms. In: Forty- first International Conference on Machine Learning (2024)
2024
-
[57]
arXiv preprint arXiv:2405.14785 (2024)
Yang, L., Zeng, B., Liu, J., Li, H., Xu, M., Zhang, W., Yan, S.: Editworld: Sim- ulating world dynamics for instruction-following image editing. arXiv preprint arXiv:2405.14785 (2024)
-
[58]
Entropy25(10), 1469 (2023)
Yang, R., Srivastava, P., Mandt, S.: Diffusion probabilistic modeling for video generation. Entropy25(10), 1469 (2023)
2023
-
[59]
arXiv preprint arXiv:2308.11945 (2023)
Yang, S., Yang, Z., Wang, Z.: Longdancediff: Long-term dance generation with conditional diffusion model. arXiv preprint arXiv:2308.11945 (2023)
-
[60]
In: International Conference on Machine Learning
Yoon, J., Hwang, S.J., Lee, J.: Adversarial purification with score-based genera- tive models. In: International Conference on Machine Learning. pp. 12062–12072. PMLR (2021)
2021
-
[61]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yuan, Y., Iqbal, U., Molchanov, P., Kitani, K., Kautz, J.: Glamr: Global occlusion- aware human mesh recovery with dynamic cameras. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11038– 11049 (2022)
2022
-
[62]
arXiv preprint arXiv:2310.05375 (2023)
Zeng, B., Li, S., Feng, Y., Li, H., Gao, S., Liu, J., Li, H., Tang, X., Liu, J., Zhang, B.: Ipdreamer: Appearance-controllable 3d object generation with image prompts. arXiv preprint arXiv:2310.05375 (2023)
-
[63]
arXiv preprint arXiv:2403.06741 (2024)
Zhu, H., Yang, L., Yong, J.H., Zhang, W., Wang, B.: Distribution-aware data expansion with diffusion models. arXiv preprint arXiv:2403.06741 (2024)
-
[64]
Zhuang, H., Lei, S., Xiao, L., Li, W., Chen, L., Yang, S., Wu, Z., Kang, S., Meng, H.: Gtn-bailando: Genre consistent long-term 3d dance generation based on pre- trainedgenretokennetwork.In:ICASSP2023-2023IEEEInternationalConference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1–5. IEEE (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.