DPrivBench: Benchmarking LLMs' Reasoning for Differential Privacy
Pith reviewed 2026-05-21 00:45 UTC · model grok-4.3
The pith
Large language models handle basic differential privacy mechanisms but fail on advanced algorithms according to a new benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
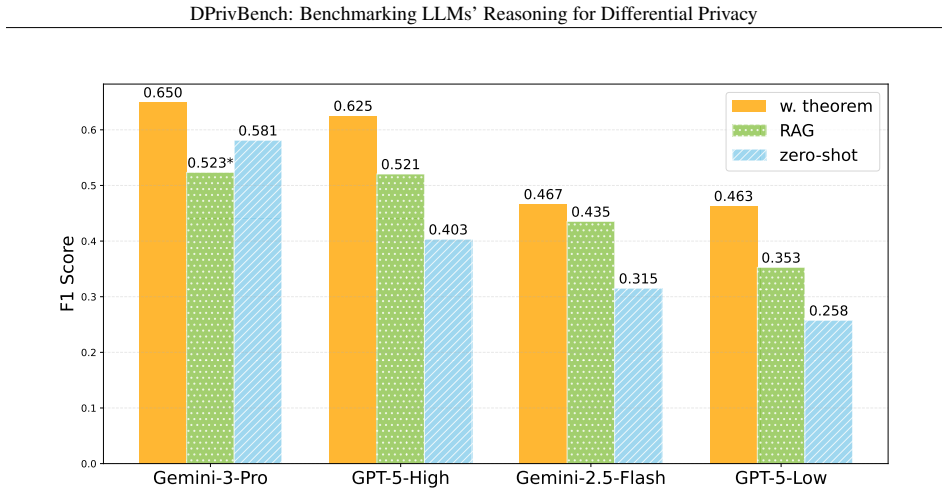
DPrivBench is introduced as a collection of instances that ask whether an algorithm satisfies a given DP guarantee. Evaluation of multiple LLMs shows strong performance on standard mechanisms paired with consistent struggles on advanced algorithms, demonstrating that existing models lack the depth of reasoning needed for reliable automated DP analysis.
What carries the argument
DPrivBench, a benchmark of DP-satisfaction questions spanning basic to advanced topics and designed to block superficial pattern matching.
If this is right
- Current LLMs cannot yet serve as reliable tools for verifying or designing complex differential privacy algorithms without human oversight.
- Failure modes identified in the study point to specific topics where targeted training or prompting improvements could help.
- The benchmark offers a reusable testbed for measuring progress in automated DP reasoning over time.
- It adds a privacy-focused dimension to existing suites of mathematical and algorithmic reasoning benchmarks.
Where Pith is reading between the lines
- Wider adoption of LLMs for DP tasks would depend on closing the gap on advanced mechanisms to make privacy engineering more accessible.
- The observed limitations may reflect broader difficulties LLMs face when applying formal definitions to intricate code structures.
- Future work could adapt DPrivBench to evaluate code generation for DP-compliant algorithms in addition to verification.
Load-bearing premise
The benchmark questions are accurately labeled as satisfying or violating the stated DP guarantee and require genuine reasoning rather than surface-level pattern recognition.
What would settle it
A model that achieves high accuracy on the advanced-algorithm portion of DPrivBench while providing evidence that its answers stem from step-by-step reasoning instead of memorization would undermine the claim of substantial gaps.
Figures


read the original abstract
Differential privacy (DP) has a wide range of applications for protecting data privacy, but designing and verifying DP algorithms requires expert-level reasoning, creating a high barrier for non-expert practitioners. Prior works either rely on specialized verification languages that demand substantial domain expertise or remain semi-automated and require human-in-the-loop guidance. In this work, we investigate whether large language models (LLMs) can automate DP reasoning. We introduce DPrivBench, a benchmark in which each instance asks whether a function or algorithm satisfies a stated DP guarantee under specified assumptions. The benchmark is carefully designed to cover a broad range of DP topics, span diverse difficulty levels, and resist shortcut reasoning through trivial pattern matching. Experiments show that while the strongest models handle textbook mechanisms well, all models struggle with advanced algorithms, revealing substantial gaps in current DP reasoning capabilities. Through further analytic study and failure-mode analysis, we identify several promising directions for improving automated DP reasoning. Our benchmark provides a solid foundation for developing and evaluating such methods, and complements existing benchmarks for mathematical reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DPrivBench, a benchmark consisting of instances that ask whether a given function or algorithm satisfies a stated differential privacy guarantee under specified assumptions. The benchmark is designed to cover a broad range of DP topics across difficulty levels while resisting shortcut reasoning via trivial pattern matching. Experiments show that the strongest models perform well on textbook mechanisms but all models struggle with advanced algorithms; the authors include analytic study and failure-mode analysis to identify directions for improving automated DP reasoning.
Significance. If the benchmark labels are accurate and the instances require genuine reasoning, the results demonstrate substantial gaps in current LLMs' DP reasoning capabilities. This provides a useful foundation for developing automated tools for privacy algorithm design and verification, complementing existing mathematical reasoning benchmarks by focusing on a specialized applied domain with clear practical relevance.
major comments (2)
- [Abstract] Abstract: the assertion that the benchmark is 'carefully designed to resist shortcut reasoning through trivial pattern matching' and provides 'broad topic coverage' is not supported by details on instance validation, inter-annotator agreement, or quantitative tests for pattern-matching resistance. This is load-bearing for the central claim that performance differences reflect reasoning limitations rather than label noise or superficial cues.
- [Experiments and Failure-mode analysis] The headline finding that models handle textbook mechanisms but fail on advanced algorithms depends on the correctness of ground-truth labels for advanced instances, which often involve non-trivial composition, approximation, or privacy-loss accounting. No mention is made of multi-expert review, formal proof checking, or public release of labeling rationales for the hardest items, raising the possibility that label errors contribute to the observed gap.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, providing clarifications on the benchmark design and label verification while committing to revisions that increase transparency without altering the core findings.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the benchmark is 'carefully designed to resist shortcut reasoning through trivial pattern matching' and provides 'broad topic coverage' is not supported by details on instance validation, inter-annotator agreement, or quantitative tests for pattern-matching resistance. This is load-bearing for the central claim that performance differences reflect reasoning limitations rather than label noise or superficial cues.
Authors: We agree that the abstract would be strengthened by explicit supporting details from the main text. In the revised manuscript we have expanded the 'Benchmark Construction' section to describe the multi-author validation process (each instance reviewed independently by at least two DP experts for correctness and to eliminate trivial pattern-matching shortcuts), report inter-annotator agreement on a held-out sample, and present a quantitative test in which model accuracy drops substantially on paraphrased and reordered variants of the same instances. These additions directly substantiate the claims of broad coverage and resistance to superficial cues. revision: yes
-
Referee: [Experiments and Failure-mode analysis] The headline finding that models handle textbook mechanisms but fail on advanced algorithms depends on the correctness of ground-truth labels for advanced instances, which often involve non-trivial composition, approximation, or privacy-loss accounting. No mention is made of multi-expert review, formal proof checking, or public release of labeling rationales for the hardest items, raising the possibility that label errors contribute to the observed gap.
Authors: We acknowledge that explicit documentation of label provenance is important. All labels were produced and cross-verified by the author team, whose members have published peer-reviewed work on differential privacy mechanisms, composition, and privacy accounting. In the revision we have added an appendix containing worked labeling rationales for a representative set of the most complex instances and have committed to releasing the complete set of instances together with their rationales upon publication. We did not employ external multi-expert panels or automated theorem provers, as the task is verification against stated DP definitions rather than discovery of new proofs; we now note this scope limitation explicitly in the paper. revision: partial
Circularity Check
No circularity in benchmark construction or evaluation
full rationale
The paper introduces DPrivBench as an empirically constructed benchmark whose ground-truth labels derive from established differential privacy definitions and expert knowledge rather than from any fitted parameters, self-referential equations, or prior self-citations that would force the reported results. Model performance is measured against external LLM outputs on these fixed instances; no derivation chain reduces the headline finding (textbook success vs. advanced failure) to the benchmark labels by construction. The design explicitly aims to resist pattern matching, and evaluation is independent of any internal consistency loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard mathematical definition of differential privacy (epsilon-delta DP) is the correct formalization for the benchmark questions.
Reference graph
Works this paper leans on
- [1]
-
[2]
Privacy Amplification by Subsampling: Tight Analyses via Couplings and Divergences
GitHub repository, version 0.2.3.1, accessed 2026-04-16. Balle, B., Barthe, G., and Gaboardi, M. Privacy amplification by subsampling: Tight analyses via couplings and divergences.arXiv preprint arXiv:1807.01647,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Differentially Private Empirical Risk Minimization: Efficient Algorithms and Tight Error Bounds
Bassily, R., Smith, A., and Thakurta, A. Differentially private empirical risk minimization: Efficient algorithms and tight error bounds.arXiv preprint arXiv:1405.7085,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Private stochastic convex optimization with optimal rates.arXiv preprint arXiv:1908.09970,
Bassily, R., Feldman, V ., Talwar, K., and Thakurta, A. Private stochastic convex optimization with optimal rates.arXiv preprint arXiv:1908.09970,
-
[5]
Average-Case Averages: Private Algorithms for Smooth Sensitivity and Mean Estimation
Bun, M. and Steinke, T. Average-case averages: Private algorithms for smooth sensitivity and mean estimation.arXiv preprint arXiv:1906.02830,
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[6]
L., Kamath, G., and Steinke, T
Canonne, C. L., Kamath, G., and Steinke, T. The discrete gaussian for differential privacy.arXiv preprint arXiv:2004.00010,
-
[7]
Cesar, M. and Rogers, R. Bounding, concentrating, and truncating: Unifying privacy loss composition for data analytics. arXiv preprint arXiv:2004.07223,
-
[8]
Chu, S.-Y ., Tian, Y ., Wang, Y .-X., and Jin, H. Dpcheatsheet: Using worked and erroneous llm-usage examples to scaffold differential privacy implementation.arXiv preprint arXiv:2509.12590,
-
[9]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
De, S., Berrada, L., Hayes, J., Smith, S. L., and Balle, B. Unlocking high-accuracy differentially private image classification through scale.arXiv preprint arXiv:2204.13650,
-
[11]
Detecting violations of differential privacy
Ding, Z., Wang, Y ., Wang, G., Zhang, D., and Kifer, D. Detecting violations of differential privacy. InProceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, pp. 475–489,
work page 2018
-
[12]
The permute-and-flip mechanism is identical to report-noisy-max with exponential noise
Ding, Z., Kifer, D., Steinke, T., Wang, Y ., Xiao, Y ., Zhang, D., et al. The permute-and-flip mechanism is identical to report-noisy-max with exponential noise.arXiv preprint arXiv:2105.07260,
-
[13]
Dong, J., Durfee, D., and Rogers, R. Optimal differential privacy composition for exponential mechanisms and the cost of adaptivity.arXiv preprint arXiv:1909.13830,
-
[14]
Y ., Hausknecht, K., Brenner, J., Liu, D., Peng, N., Wang, C., and Brenner, M
Fan, J., Martinson, S., Wang, E. Y ., Hausknecht, K., Brenner, J., Liu, D., Peng, N., Wang, C., and Brenner, M. P. Hardmath: A benchmark dataset for challenging problems in applied mathematics.arXiv preprint arXiv:2410.09988,
-
[15]
URL https://csrc.nist.gov/ presentations/2020/stppa1-census. Google DeepMind. Gemini 3 pro model card,
work page 2020
-
[16]
URL https: //developers.googleblog.com/how-were-helping-developers-with-differential-privacy/. Harrison, C. and Manurangsi, P. Exact zcdp characterizations for fundamental differentially private mechanisms.arXiv preprint arXiv:2510.25746,
-
[17]
URL https://openreview.net/forum?id=OZy70UggXr. Huang, Y . and Yang, L. F. Winning gold at imo 2025 with a model-agnostic verification-and-refinement pipeline.arXiv preprint arXiv:2507.15855,
-
[18]
Kulesza, A., Suresh, A. T., and Wang, Y . Mean estimation in the add-remove model of differential privacy.arXiv preprint arXiv:2312.06658,
-
[19]
Large language models can be strong differentially private learners
Li, X., Tramèr, F., Liang, P., and Hashimoto, T. Large language models can be strong differentially private learners. arXiv preprint arXiv:2110.05679,
-
[20]
Liu, H., Zheng, Z., Qiao, Y ., Duan, H., Fei, Z., Zhou, F., Zhang, W., Zhang, S., Lin, D., and Chen, K. Mathbench: Evaluating the theory and application proficiency of llms with a hierarchical mathematics benchmark.arXiv preprint arXiv:2405.12209,
-
[21]
Lowy, A. and Razaviyayn, M. Output perturbation for differentially private convex optimization: Faster and more general.arXiv preprint arXiv:2102.04704,
-
[22]
Auditingf-differential privacy in one run,
Mahloujifar, S., Melis, L., and Chaudhuri, K. Auditing f-differential privacy in one run.arXiv preprint arXiv:2410.22235,
-
[23]
13 DPrivBench: Benchmarking LLMs’ Reasoning for Differential Privacy McKenna, R
Accessed: 2026-01-23. 13 DPrivBench: Benchmarking LLMs’ Reasoning for Differential Privacy McKenna, R. and Sheldon, D. R. Permute-and-flip: A new mechanism for differentially private selection.Advances in Neural Information Processing Systems, 33:193–203,
work page 2026
-
[24]
Mironov, I. Renyi differential privacy.arXiv preprint arXiv:1702.07476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Hyperparameter tuning with renyi differen- tial privacy.arXiv preprint arXiv:2110.03620,
URLhttps://openai.com/index/introducing-gpt-5/. Papernot, N. and Steinke, T. Hyperparameter tuning with renyi differential privacy.arXiv preprint arXiv:2110.03620,
-
[26]
Scalable Private Learning with PATE
Papernot, N., Song, S., Mironov, I., Raghunathan, A., Talwar, K., and Úlfar Erlingsson. Scalable private learning with pate.arXiv preprint arXiv:1802.08908,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Redberg, R., Zhu, Y ., and Wang, Y .-X. Generalized ptr: User-friendly recipes for data-adaptive algorithms with differential privacy.arXiv preprint arXiv:2301.00301,
-
[28]
On Optimal Hyperparameters for Differentially Private Deep Transfer Learning
Rehn, A., Zhao, L., Heikkilä, M. A., and Honkela, A. On optimal hyperparameters for differentially private deep transfer learning.arXiv preprint arXiv:2510.20616,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Sato, T., Barthe, G., Gaboardi, M., Hsu, J., and Katsumata, S.-y
URL https://icml.cc/ virtual/2021/11631. Sato, T., Barthe, G., Gaboardi, M., Hsu, J., and Katsumata, S.-y. Approximate span liftings: Compositional semantics for relaxations of differential privacy. In2019 34th Annual ACM/IEEE Symposium on Logic in Computer Science (LICS), pp. 1–14. IEEE,
work page 2021
- [30]
-
[31]
Opacus: User-friendly differential privacy library in pytorch
Yousefpour, A., Shilov, I., Sablayrolles, A., Testuggine, D., Prasad, K., Malek, M., Nguyen, J., Ghosh, S., Bharadwaj, A., Zhao, J., et al. Opacus: User-friendly differential privacy library in pytorch.arXiv preprint arXiv:2109.12298,
-
[32]
Privtree: A differentially private algorithm for hierarchical decompositions
Zhang, J., Xiao, X., and Xie, X. Privtree: A differentially private algorithm for hierarchical decompositions. In Proceedings of the 2016 international conference on management of data, pp. 155–170,
work page 2016
-
[33]
Through the question statement in Category 1, we usereplace-oneneighbouring relationship. Theorem A.1(Laplace Mechanism (Dwork et al., 2006)).Let f:X n →R d be a function with ℓ1-sensitivity ∆1(f) := max X∼X ′ ∥f(X)−f(X ′)∥1. The Laplace mechanism defined as follow satisfiesε-DP: M(X) =f(X) +Z, Z i i.i.d. ∼Lap ∆1(f) ε . Theorem A.2(zCDP guarantee of Gauss...
work page 2006
-
[34]
In particular, when instantiated with exponential noise, the algorithm is called the permute and flip (McKenna & Sheldon, 2020; Ding et al., 2021). When instantiated with Gumbel noise, the algorithm is the famous exponential algorithm (McSherry & Talwar, 2007). Input :DatasetX; score functions{u j(·)}m i=1 with sensitivity∆(w.r.t. same neighboring relatio...
work page 2020
-
[35]
Sequential or Adaptive Composition (Bun & Steinke, 2016; Mironov, 2017; Canonne et al., 2020; Cesar & Rogers,
work page 2016
-
[36]
DP-ML DP-GD (Bassily et al., 2014; Dong et al.,
work page 2014
-
[37]
dp-sgd (Abadi et al., 2016; De et al., 2022; Rehn et al.,
work page 2016
-
[38]
objective perturbation (Bassily et al., 2019; Kifer et al., 2012; Chaudhuri et al.,
work page 2019
-
[39]
DP-statistics DP selection: expoMech (Dong et al., 2019,
work page 2019
-
[40]
Data-Adaptive PTR (Redberg et al., 2022; Dwork & Lei,
work page 2022
-
[41]
Table 6: Reference for Category 2 questions (grouped by subject and topic). B Taxonomy of error pattern in Category 2 benchmark design Table 7: Error taxonomy and empirical distribution in Category 2 Error pattern Core characterization Stronger-than-valid claim / over- claiming guarantee Starts from a valid result but claims a strictly stronger privacy gu...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.