Attribution-Guided and Coverage-Maximized Pruning for Structural MoE Compression
Pith reviewed 2026-06-27 02:04 UTC · model grok-4.3
The pith
Channel-level pruning for MoE models preserves accuracy at 50% or 25% structured rates by maximizing coverage of important channels via attribution scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that reformulating prune-ratio allocation as a channel-score coverage maximization problem and solving it with an attribution-based approximation yields a structural pruning method that maintains model accuracy under 50% or 25% structured pruning on MoE architectures when combined with 4-bit quantization, outperforming expert-level baselines.
What carries the argument
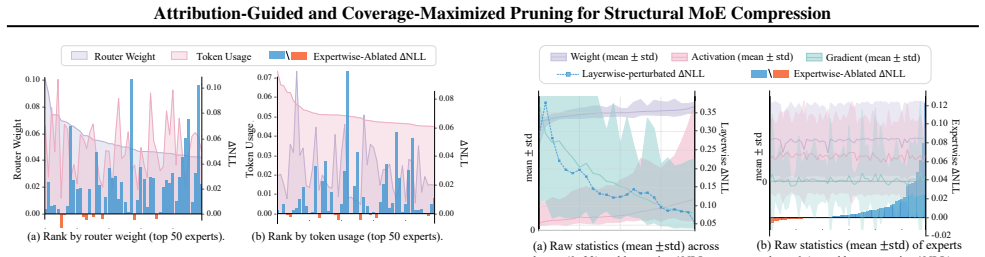
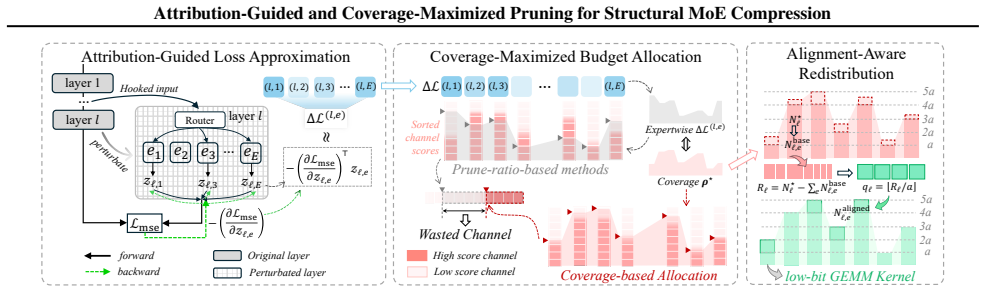
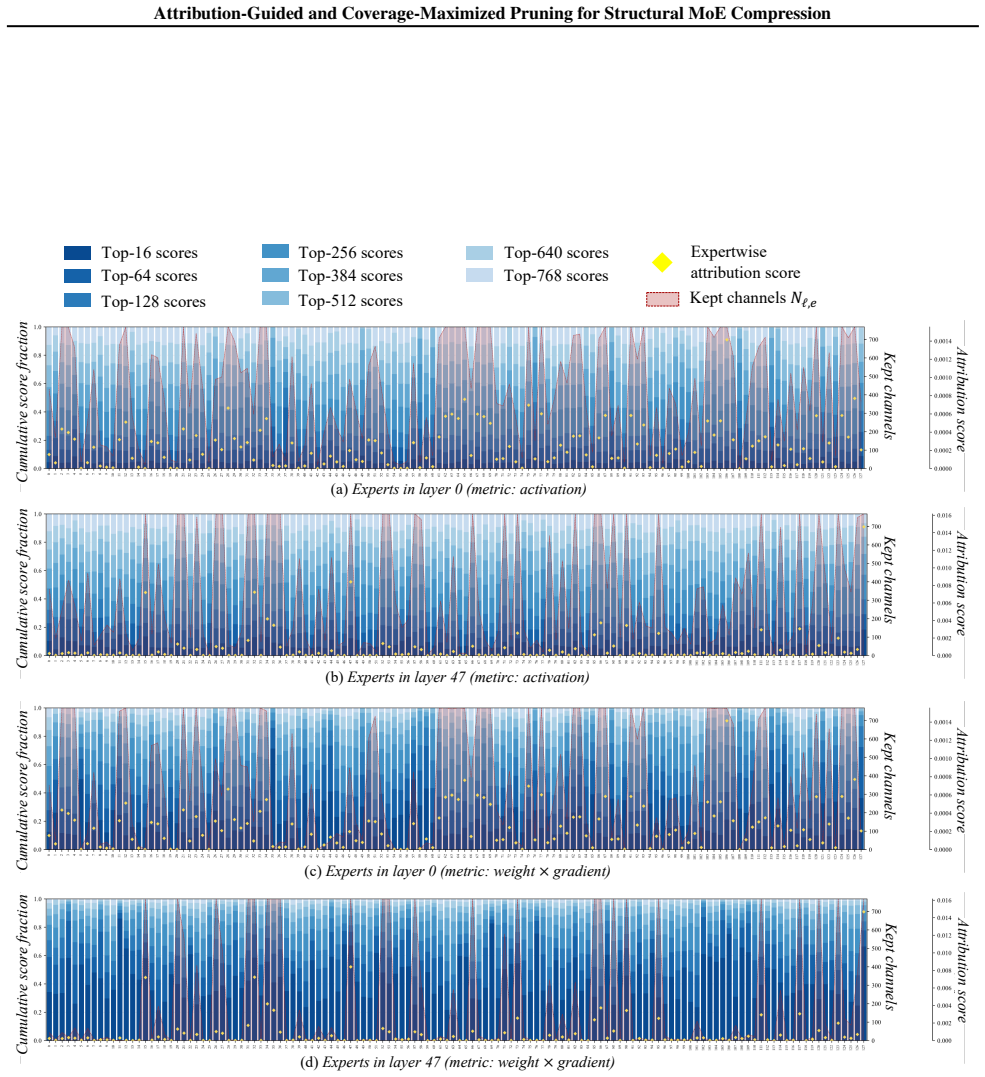
Attribution-guided coverage maximization that assigns per-channel prune ratios to maximize the total importance score covered by retained channels.
If this is right
- 50% structured channel pruning plus 4-bit quantization can reduce memory footprint by more than 5 times on 30B-scale MoE models without accuracy collapse.
- Prune budgets can be allocated across channels inside retained experts rather than across experts.
- The same coverage-maximization procedure applies to both DeepSeek and Qwen MoE families and beats existing expert-ranking methods on standard benchmarks.
Where Pith is reading between the lines
- If the channel-concentration pattern generalizes beyond the tested models, the same allocation logic could be applied to other sparsely activated architectures.
- The method could be combined with expert merging or routing adjustments to further reduce inference latency.
- A direct measurement of channel importance variance across layers would give a simple diagnostic for when the approach is likely to succeed.
Load-bearing premise
Information inside each MoE expert is concentrated enough in a small subset of channels that channel-level decisions reliably capture more redundancy than expert-level decisions.
What would settle it
A controlled test on an MoE model where expert-level pruning at the same ratio retains higher accuracy than the channel-level method would falsify the claimed advantage.
Figures







read the original abstract
Mixture-of-Experts (MoE) models scale compute efficiently, yet remain expensive to deploy due to their substantial memory footprint and inference overhead. Prior compression methods mainly operate at the expert level, either removing entire experts or ranking experts by coarse-grained importance scores. However, such expert-wise decisions are often too coarse to capture fine-grained redundancy, leading to misallocated pruning budgets and limited compression. To address this problem, we observe that information within MoE experts is highly concentrated in a small subset of channels, leaving substantial redundancy even in experts deemed important. Based on this observation, we propose a structural pruning framework tailored for MoE models. Our method reformulates prune-ratio allocation as a channel-score coverage maximization problem and solves it efficiently using an attribution-based approximation. Experiments on DeepSeek and Qwen MoE models show that our method preserves model accuracy under 50% or 25% structured pruning when combined with 4-bit quantization. On Qwen3-30B-A3B, our approach reduces memory footprint by 5.27$\times$ and consistently outperforms state-of-the-art baselines across diverse benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a structural pruning framework for Mixture-of-Experts (MoE) models based on the observation that information within experts is highly concentrated in a small subset of channels. It reformulates prune-ratio allocation as a channel-score coverage maximization problem solved via an attribution-based approximation. Experiments on DeepSeek and Qwen MoE models claim that the method preserves accuracy under 50% or 25% structured pruning combined with 4-bit quantization, achieving a 5.27× memory reduction on Qwen3-30B-A3B while outperforming state-of-the-art baselines across diverse benchmarks.
Significance. If the empirical results hold under rigorous controls, the work could meaningfully advance efficient deployment of large MoE models by enabling finer-grained pruning that captures intra-expert redundancy better than expert-level baselines. The reported memory reduction and accuracy preservation on models like Qwen3-30B-A3B indicate potential practical utility for memory-constrained inference.
major comments (2)
- [Abstract] Abstract: the central claim that the method 'preserves model accuracy' under 50%/25% pruning + 4-bit quantization rests on experimental outcomes whose details (specific benchmarks, variance across runs, controls for the channel-concentration observation) are not visible; this makes it difficult to evaluate whether the coverage-maximization step is load-bearing or if results could be explained by the quantization alone.
- [Abstract] The weakest assumption—that channel-level decisions capture fine-grained redundancy better than expert-level decisions—requires explicit validation (e.g., ablation comparing channel vs. expert pruning ratios on the same models); without it, the reformulation as coverage maximization risks being an ad-hoc improvement rather than a principled advance.
minor comments (2)
- The abstract states results on 'DeepSeek and Qwen MoE models' but does not name the exact model variants or pruning ratios per model; adding a table summarizing these would improve clarity.
- Consider defining 'attribution-based approximation' more precisely even at the abstract level, or adding a short methods paragraph, to allow readers to assess the approximation's fidelity without the full text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for minor revision. We address each major comment below and will revise the manuscript accordingly to improve clarity and strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the method 'preserves model accuracy' under 50%/25% pruning + 4-bit quantization rests on experimental outcomes whose details (specific benchmarks, variance across runs, controls for the channel-concentration observation) are not visible; this makes it difficult to evaluate whether the coverage-maximization step is load-bearing or if results could be explained by the quantization alone.
Authors: We agree that the abstract is too concise to convey the full experimental context. The manuscript already reports these details in Sections 4 and 5 (specific benchmarks including MMLU, GSM8K, HumanEval; tables with mean/std over 3 seeds; direct comparisons to quantization-only and expert-pruning baselines showing the additional gain from coverage maximization). In the revision we will expand the abstract to briefly list the key benchmarks, note that results are averaged across runs, and reference the controls for the channel-concentration observation, making the load-bearing role of the proposed step explicit. revision: yes
-
Referee: [Abstract] The weakest assumption—that channel-level decisions capture fine-grained redundancy better than expert-level decisions—requires explicit validation (e.g., ablation comparing channel vs. expert pruning ratios on the same models); without it, the reformulation as coverage maximization risks being an ad-hoc improvement rather than a principled advance.
Authors: The manuscript already contains head-to-head comparisons against expert-level pruning baselines at identical overall pruning ratios (Table 2, Figure 3), demonstrating consistent gains from channel-level allocation. Nevertheless, we acknowledge that a dedicated side-by-side ablation isolating the effect of channel versus expert granularity would strengthen the argument. We will add this ablation in the revised version, reporting accuracy and memory metrics for both strategies on the same DeepSeek and Qwen models. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core contribution is an empirical pruning method: it states an observation on channel-level concentration within MoE experts, reformulates prune-ratio allocation as a coverage-maximization problem, and solves it with an attribution approximation. No equations, derivations, or load-bearing steps are described that reduce by construction to fitted parameters, self-definitions, or self-citation chains. The central accuracy-preservation claims rest on direct experiments with DeepSeek/Qwen models and external baselines, which constitute independent empirical support rather than internal re-derivation of inputs. This is the normal case of a self-contained applied method paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attribution scores can be used as a proxy for channel importance in coverage maximization
Reference graph
Works this paper leans on
-
[1]
OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
Ahmad, W. U., Narenthiran, S., Majumdar, S., Ficek, A., Jain, S., Huang, J., Noroozi, V ., and Ginsburg, B. Open- codereasoning: Advancing data distillation for competi- tive coding.arXiv preprint arXiv:2504.01943,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Orchestrating hidden-intermediate pruning- and-distill for moes slimming
Anonymous. Orchestrating hidden-intermediate pruning- and-distill for moes slimming. Anonymous ICML 2026 submission (under review),
2026
-
[3]
Condense, Don't Just Prune: Enhancing Efficiency and Performance in MoE Layer Pruning
Cao, M., Li, G., Ji, J., Zhang, J., Ma, X., Liu, S., and Yin, L. Condense, don’t just prune: Enhancing efficiency and performance in moe layer pruning.arXiv preprint arXiv:2412.00069,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
doi: 10.48550/arXiv.2405.16646. Clark, C., Lee, K., Chang, M.-W., Kwiatkowski, T., Collins, M., and Toutanova, K. Boolq: Exploring the surprising difficulty of natural yes/no questions. InNorth American Chapter of the Association for Computational Linguistics,
-
[5]
doi: 10.48550/arXiv.2410. 11988. 10 Attribution-Guided and Coverage-Maximized Pruning for Structural MoE Compression Gong, R., Ding, Y ., Wang, Z., Lv, C., Zheng, X., Du, J., Yong, Y ., Gu, S., Qin, H., et al. A survey of low-bit large language models: Basics, systems, and algorithms. Neural Networks, pp. 107856,
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025a. Guo, H., Yao, J., Wang, B., Du, J., Cao, S., Di, D., Zhang, S., and Li, Z. Cluster-driven expert pruning for mixture-of-experts lar...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Measuring Massive Multitask Language Understanding
ISSN 2835-8856. URL https: //openreview.net/forum?id=HTpMOl6xSI. Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding.ArXiv, abs/2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[8]
Huang, Y ., Wang, Z., Yuan, Z., Ding, Y ., Gong, R., Guo, J., Liu, X., and Zhang, J
doi: 10.48550/arXiv.2410.06270. Huang, Y ., Wang, Z., Yuan, Z., Ding, Y ., Gong, R., Guo, J., Liu, X., and Zhang, J. Modes: Accelerating mixture-of- experts multimodal large language models via dynamic expert skipping.arXiv preprint arXiv:2511.15690,
-
[9]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Jain, N., Han, K., Gu, A., Li, W.-D., Yan, F., Zhang, T., Wang, S., Solar-Lezama, A., Sen, K., and Stoica, I. Livecodebench: Holistic and contamination free eval- uation of large language models for code.arXiv preprint arXiv:2403.07974,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Jiang, A. Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D. S., Casas, D. d. l., Hanna, E. B., Bressand, F., et al. Mixtral of experts.arXiv preprint arXiv:2401.04088,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Lightman, H., Kosaraju, V ., Burda, Y ., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. Let’s verify step by step.arXiv preprint arXiv:2305.20050,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
arXiv preprint arXiv:2407.00945 , year=
Liu, E., Zhu, J., Lin, Z., Ning, X., Blaschko, M. B., Yan, S., Dai, G., Yang, H., and Wang, Y . Efficient expert pruning for sparse mixture-of-experts language models: Enhancing performance and reducing inference costs. In arXiv.org, 2024a. doi: 10.48550/arXiv.2407.00945. Liu, S.-Y ., Wang, C.-Y ., Yin, H., Molchanov, P., Wang, Y .-C. F., Cheng, K.-T., an...
-
[13]
Lv, C., Zhang, B., Yong, Y ., Gong, R., Huang, Y ., Gu, S., Wu, J., Shi, Y ., Guo, J., et al
doi: 10.48550/ arXiv.2402.14800. Lv, C., Zhang, B., Yong, Y ., Gong, R., Huang, Y ., Gu, S., Wu, J., Shi, Y ., Guo, J., et al. LLMC+: Benchmarking vision-language model compression with a plug-and-play toolkit. InAAAI Conference on Artificial Intelligence,
-
[14]
arXiv preprint arXiv:2404.05089 , year=
doi: 10.48550/arXiv.2404.05089. Qwen-Team. Qwen3 technical report,
-
[15]
URL https: //arxiv.org/abs/2505.09388. Raffel, C., Shazeer, N. M., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y ., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text trans- former.J. Mach. Learn. Res., 21:140:1–140:67,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
URL https://arxiv.org/abs/2311.12022. 11 Attribution-Guided and Coverage-Maximized Pruning for Structural MoE Compression Sakaguchi, K., Bras, R. L., Bhagavatula, C., and Choi, Y . Winogrande: An adversarial winograd schema challenge at scale.Proceedings of the AAAI Conference on Artificial Intelligence, undefined. Skean, O., Arefin, M. R., Zhao, D., Pate...
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Sun, M., Liu, Z., Bair, A., and Kolter, J. Z. A simple and effective pruning approach for large language models. arXiv preprint arXiv:2306.11695,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Metamorphictestingoflarge languagemodelsfornaturallanguageprocessing.doi:10.48550/arXiv
doi: 10.48550/arXiv. 2410.12013. Xu, H., Wu, H., Ke, X., Wu, J., Xu, R., and Xu, J. Mc- moe: Completing missing modalities with mixture of experts for incomplete multimodal action quality as- sessment,
work page internal anchor Pith review doi:10.48550/arxiv
-
[19]
Xue, F., Zheng, Z., Fu, Y ., Ni, J., Zheng, Z., Zhou, W., and You, Y
URL https://arxiv.org/abs/ 2511.17397. Xue, F., Zheng, Z., Fu, Y ., Ni, J., Zheng, Z., Zhou, W., and You, Y . Openmoe: An early effort on open mixture-of-experts language models.arXiv preprint arXiv:2402.01739,
-
[20]
MoE-i2: Compressing mixture of experts models through inter- expert pruning and intra-expert low-rank decomposition
Yang, C., Sui, Y ., Xiao, J., Huang, L., Gong, Y ., Duan, Y ., Jia, W., Yin, M., Cheng, Y ., and Yuan, B. MoE-i2: Compressing mixture of experts models through inter- expert pruning and intra-expert low-rank decomposition. InFindings of the Association for Computational Linguis- tics: EMNLP 2024, pp. 10456–10466, Miami, Florida, USA, November
2024
-
[21]
and Math-AI, T
Zhang, Y . and Math-AI, T. American invitational mathemat- ics examination (aime) 2025,
2025
-
[22]
Zhao, Y ., Wang, Z., and Zhang, M
doi: 10.48550/arXiv.2407.09590. Zhao, Y ., Wang, Z., and Zhang, M. Puzzlemoe: Effi- cient compression of large mixture-of-experts models via sparse expert merging and bit-packed inference.arXiv preprint arXiv:2511.04805,
-
[23]
13 A.1Complete Process of Maximum Coverage Allocation Algorithm
12 Attribution-Guided and Coverage-Maximized Pruning for Structural MoE Compression Contents A Algorithms. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 A.1Complete Process of Maximum Coverage Allocation Algorithm ...
2025
-
[24]
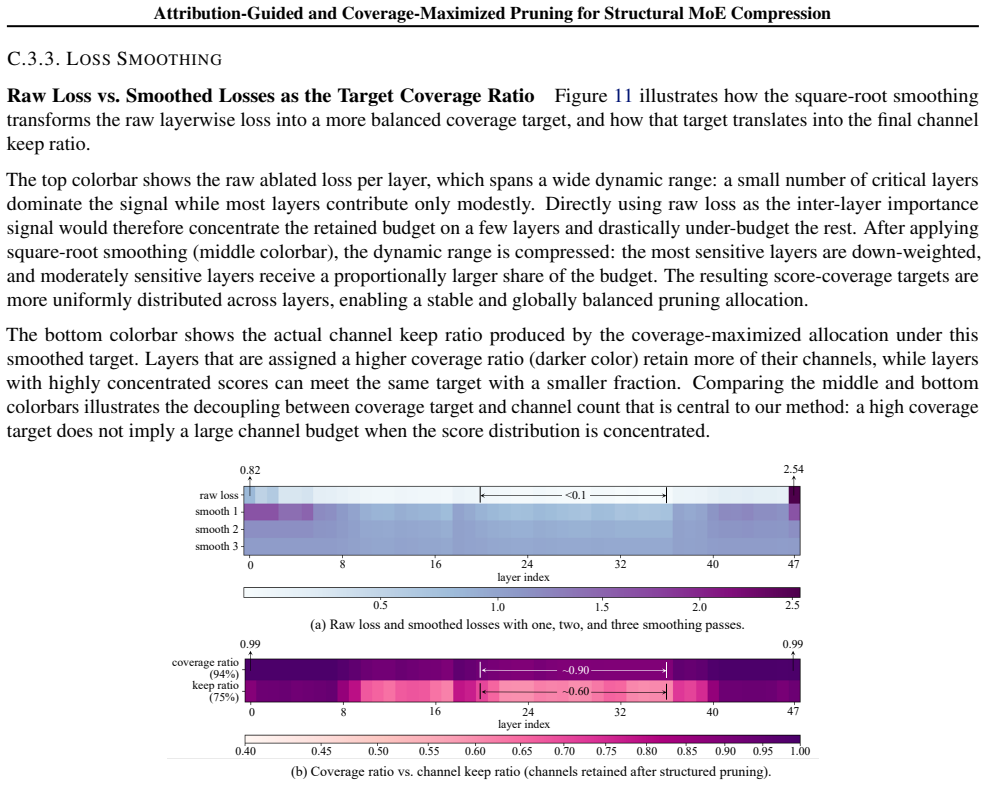
Step 3: Compute remaining quota and available blocks.The channel budget released by trimming and alignment is collected and segmented as units of a-blocks
10:end for 11:N ℓ(ρ)← P e∈Eℓ Nℓ,e(ρℓ,e) 12:if Nℓ(ρ)−N ⋆ ℓ ≤ε N tot ℓ then 13:N ⋆ ℓ,e ←N ℓ,e(ρℓ,e),∀e∈ E ℓ 14:break 15:end if 16:ifN ℓ(ρ)> N ⋆ ℓ then 17:α max ←α 18:else 19:α min ←α 20:end if 21:end while 22:return{N ⋆ ℓ,e}e∈Eℓ Step 2: Downward alignment.For each remaining expert e∈ A ℓ, we round ˜Nl,e down to the nearest multiple of a, ensuring compatibil...
2024
-
[25]
We fine-tune the MoE blocks using DoRA (Liu et al., 2024b) with rank 32 and learning rate1e−4, while adapting the routing module with rank 4 and learning rate 1e−6
for 2 epochs. We fine-tune the MoE blocks using DoRA (Liu et al., 2024b) with rank 32 and learning rate1e−4, while adapting the routing module with rank 4 and learning rate 1e−6. We use AdamW with warmup ratio 0.1 and clip gradient exceeding 0.5, without weight decay. All training is conducted on 4 ×H20 GPUs. The training cost is 12 GPU hours for Qwen1.5-...
2018
-
[26]
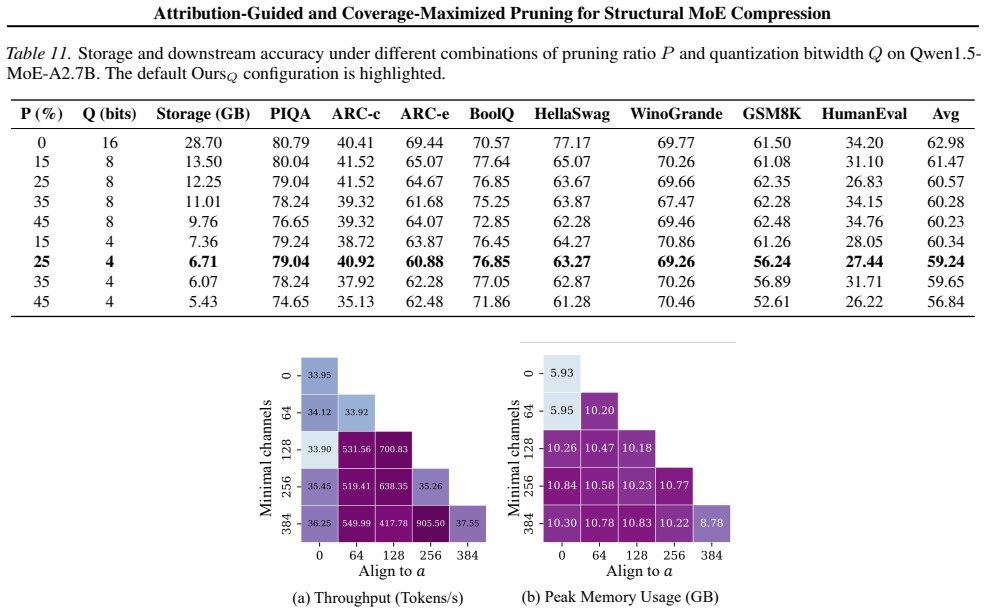
The framework therefore supports flexible operating points depending on deployment constraints
Stronger compression gives lower storage but larger accuracy drop, while milder compression preserves accuracy better. The framework therefore supports flexible operating points depending on deployment constraints. 2https://github.com/EleutherAI/lm-evaluation-harness 3https://github.com/open-compass/opencompass 19 Attribution-Guided and Coverage-Maximized...
-
[27]
Sensitivity and Robustness Analysis C.4.1
C.4. Sensitivity and Robustness Analysis C.4.1. SENSITIVITY TOCALIBRATIONCORPUS Our default setup follows common post-training compression practice, using C4 for general tasks, GSM8K for math, and OpenCodeReasoning for code. To examine the sensitivity systematically, we conduct an ablation on six calibration corpora: WikiText2, C4, Pile, RedPajama, GSM8K ...
-
[28]
reduces the parameters via low rank decomposition and assigns higher ranks to more important experts while using lower ranks for less important ones. However, the speedup is limited: the fragmentation into small kernels makes it difficult to reach peak throughput of one larger kernel, introducing additional overhead in kernel launching, cache hit, and mem...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.