Show Me Examples: Inferring Visual Concepts from Image Sets
Pith reviewed 2026-07-03 15:09 UTC · model grok-4.3
The pith
A training framework lets models infer shared visual concepts from small image sets and generate new images that apply the concept to a query.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
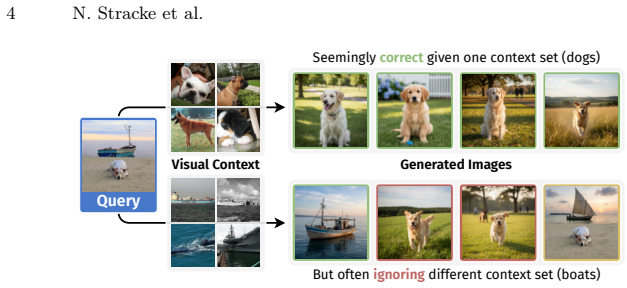
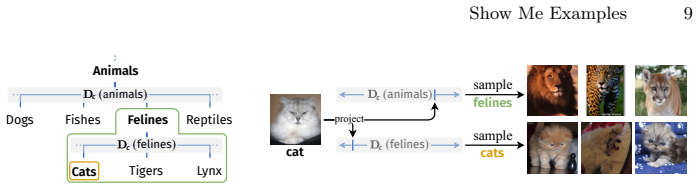
The paper claims that state-of-the-art vision-language models perform poorly on inferring visual concepts from image sets, often ignoring the visual context or defaulting to biased generations, while a proposed training framework and architecture that learn to infer visual concepts from image sets and extract concept-specific embeddings from queries can generate more accurate and diverse outputs and generalize to unseen concepts and modalities such as sketches.
What carries the argument
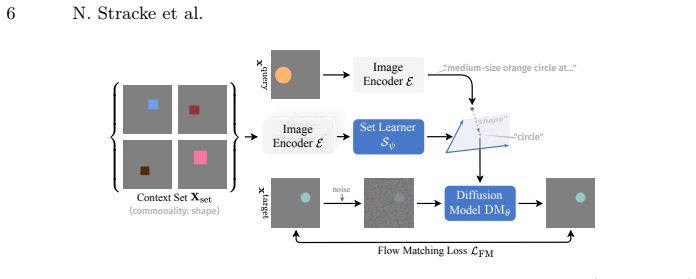
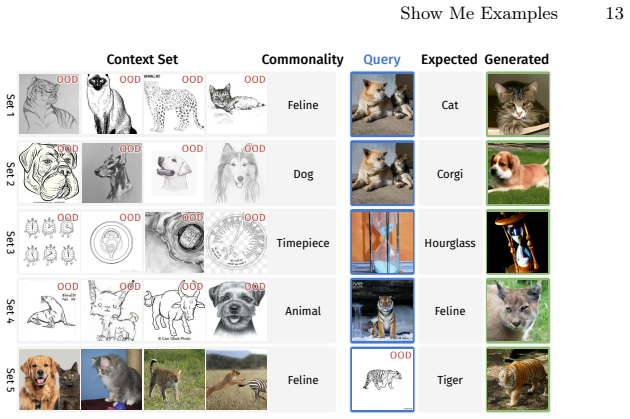
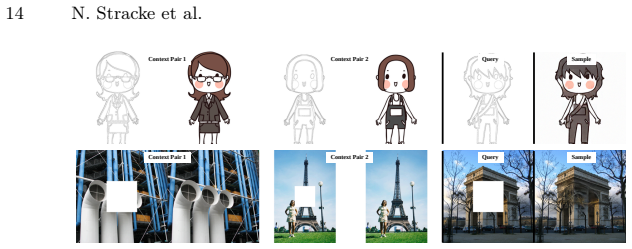
The VICIS task, which requires generating images that preserve a context-defined concept from a set of examples while remaining consistent with a query image, supported by an architecture that extracts concept-specific embeddings.
If this is right
- Vision-language models could perform visual-only reasoning tasks without needing textual descriptions of the concept.
- Generation quality improves in both accuracy to the inferred concept and output diversity.
- The same embedding extraction supports generalization to concepts and input modalities absent from training.
- Models become less prone to ignoring visual context or falling back on training biases.
Where Pith is reading between the lines
- Interactive systems could let users supply image examples to teach new visual concepts on the fly.
- The embedding approach might transfer to video sequences or 3D shapes by treating them as extended image sets.
- Few-shot visual classification could improve by treating each class as a concept inferred from an example set.
Load-bearing premise
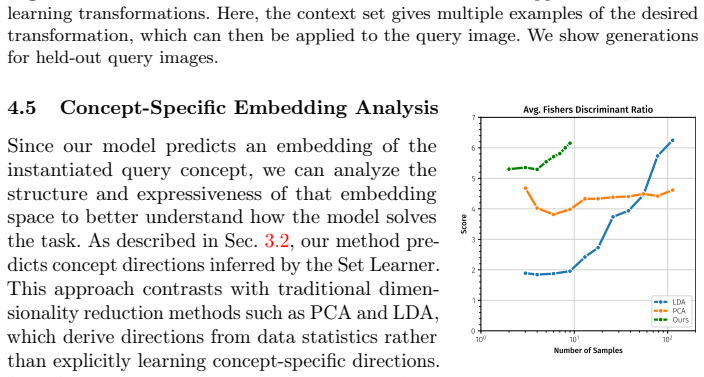
The training framework and architecture can reliably extract and apply concept-specific embeddings from image sets.
What would settle it
Run the model on held-out image sets that define a single clear visual concept and check whether its generated outputs preserve that concept at a higher rate than standard vision-language models while still matching the query image.
Figures


read the original abstract
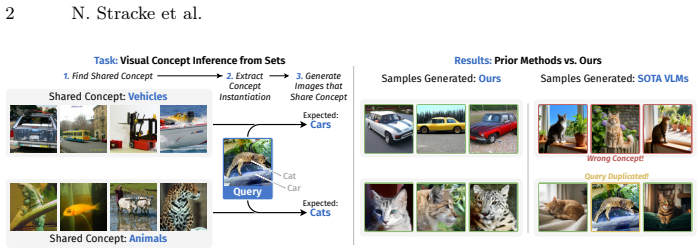
Vision-language models (VLMs) can follow complex textual instructions, yet they struggle to reason from purely visual context. In particular, current models fail to infer shared concepts from sets of example images and apply them to new inputs. We introduce Visual Concept Inference from Sets (VICIS), a task that evaluates this capability. Given a small context set of images sharing a concept and a query image, the model must generate new images that preserve the context-defined concept while remaining consistent with the query. We show that state-of-the-art VLMs perform poorly on this task, often ignoring the visual context or defaulting to biased generations. To address this gap, we propose a training framework and architecture that learn to infer visual concepts from image sets and extract concept-specific embeddings from queries. Experiments on synthetic data and large-scale ImageNet/WordNet data show that our model generates more accurate and diverse outputs and generalizes to unseen concepts and modalities such as sketches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Visual Concept Inference from Sets (VICIS) task, in which a model is given a small set of images sharing an implicit visual concept plus a query image and must generate new images that preserve the concept while remaining consistent with the query. It reports that current VLMs perform poorly on VICIS, often ignoring the visual context, and proposes a training framework together with an architecture that learns to extract concept-specific embeddings from image sets. Experiments on synthetic data and large-scale ImageNet/WordNet data are claimed to show that the proposed model produces more accurate and diverse outputs and generalizes to unseen concepts and to other modalities such as sketches.
Significance. If the quantitative claims hold, the work would be significant for vision-language modeling because it directly targets the gap between text-instruction following and visual-context reasoning. The introduction of the VICIS benchmark and a method for learning concept-specific embeddings from sets could stimulate further research on few-shot visual concept acquisition and cross-modal generalization. The use of both controlled synthetic data and large-scale ImageNet/WordNet hierarchies strengthens the potential impact provided the reported gains are substantial, reproducible, and accompanied by appropriate baselines.
major comments (2)
- [Abstract] Abstract: the central claim that the proposed model 'generates more accurate and diverse outputs' is stated without any quantitative metrics, baselines, tables, or experimental protocol, so the data-to-claim link cannot be evaluated. This is load-bearing for the paper's main empirical contribution.
- [Abstract] Abstract / Experiments: the statement that the model 'generalizes to unseen concepts and modalities such as sketches' is presented without any description of the held-out splits, evaluation protocol, or quantitative results that would allow verification of the generalization claim.
minor comments (1)
- [Abstract] The abstract would benefit from a one-sentence description of the key architectural component that enables concept-specific embedding extraction.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We agree that the abstract requires strengthening to make the empirical claims verifiable and will revise it accordingly in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the proposed model 'generates more accurate and diverse outputs' is stated without any quantitative metrics, baselines, tables, or experimental protocol, so the data-to-claim link cannot be evaluated. This is load-bearing for the paper's main empirical contribution.
Authors: We agree the abstract should link claims to evidence. The revised abstract will include specific quantitative results (e.g., accuracy and diversity gains on synthetic and ImageNet/WordNet benchmarks), name the main baselines, and reference the relevant tables and evaluation protocol. revision: yes
-
Referee: [Abstract] Abstract / Experiments: the statement that the model 'generalizes to unseen concepts and modalities such as sketches' is presented without any description of the held-out splits, evaluation protocol, or quantitative results that would allow verification of the generalization claim.
Authors: We will revise the abstract to briefly specify the held-out concept splits, the cross-modal evaluation protocol (including sketches), and report the corresponding quantitative generalization results. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces the VICIS task and a training framework/architecture for concept inference from image sets. No equations, parameter fits, or self-citations appear in the abstract or described content that would reduce any claimed prediction or result to its own inputs by construction. Experimental claims on synthetic and ImageNet/WordNet data are presented as independent evaluations rather than tautological outputs. The derivation chain is self-contained with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
fal.ai.https://fal.ai/(2025), accessed: 2025-09-25 12, 2
2025
-
[2]
Advances in neural information processing systems35, 23716– 23736 (2022) 1
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Mensch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems35, 23716– 23736 (2022) 1
2022
-
[3]
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
Albergo, M.S., Boffi, N.M., Vanden-Eijnden, E.: Stochastic interpolants: A unifying framework for flows and diffusions. arXiv preprint arXiv:2303.08797 (2023) 7, 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Bai, Y., Geng, X., Mangalam, K., Bar, A., Yuille, A.L., Darrell, T., Malik, J., Efros, A.A.: Sequential modeling enables scalable learning for large vision models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22861–22872 (2024) 3
2024
-
[5]
Advances in Neural Information Processing Systems 36, 63758–63778 (2023) 3
Balazevic, I., Steiner, D., Parthasarathy, N., Arandjelović, R., Henaff, O.: Towards in-context scene understanding. Advances in Neural Information Processing Systems 36, 63758–63778 (2023) 3
2023
-
[6]
Advances in Neural Information Processing Systems35, 25005–25017 (2022) 3, 8, 10, 5
Bar, A., Gandelsman, Y., Darrell, T., Globerson, A., Efros, A.: Visual prompting via image inpainting. Advances in Neural Information Processing Systems35, 25005–25017 (2022) 3, 8, 10, 5
2022
-
[7]
1 kontext: Flow matching for in- context image generation and editing in latent space
Batifol, S., Blattmann, A., Boesel, F., Consul, S., Diagne, C., Dockhorn, T., English, J., English, Z., Esser, P., Kulal, S., et al.: Flux. 1 kontext: Flow matching for in- context image generation and editing in latent space. arXiv e-prints pp. arXiv–2506 (2025) 1, 8, 13
2025
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Baumann, S.A., Krause, F., Neumayr, M., Stracke, N., Sevi, M., Hu, V.T., Ommer, B.: Continuous, subject-specific attribute control in t2i models by identifying semantic directions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 13231–13241 (June 2025) 5
2025
-
[9]
Advances in neural information processing systems33, 1877–1901 (2020) 3
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems33, 1877–1901 (2020) 3
1901
-
[10]
In: Proceedings of the IEEE/CVF international conference on computer vision
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9650–9660 (2021) 6, 2
2021
-
[11]
Advances in neural information processing systems31(2018) 4
Chen, R.T., Li, X., Grosse, R.B., Duvenaud, D.K.: Isolating sources of disentan- glement in variational autoencoders. Advances in neural information processing systems31(2018) 4
2018
-
[12]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., Ruan, C.: Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv preprint arXiv:2501.17811 (2025) 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
On the Measure of Intelligence
Chollet, F.: On the measure of intelligence. arXiv preprint arXiv:1911.01547 (2019) 5
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[14]
In: The Twelfth International Conference on Learning Representations (2024), https://openreview.net/forum?id=2dnO3LLiJ12, 6
Darcet, T., Oquab, M., Mairal, J., Bojanowski, P.: Vision transformers need registers. In: The Twelfth International Conference on Learning Representations (2024), https://openreview.net/forum?id=2dnO3LLiJ12, 6
2024
-
[15]
Emerging Properties in Unified Multimodal Pretraining
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., et al.: Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683 (2025) 3, 8, 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
In: 2009 IEEE Conference on Computer Vision and Show Me Examples 17 Pattern Recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Show Me Examples 17 Pattern Recognition. pp. 248–255 (2009).https://doi.org/10.1109/CVPR.2009. 520684810
-
[17]
In: Al-Onaizan, Y., Bansal, M., Chen, Y.N
Dong, Q., Li, L., Dai, D., Zheng, C., Ma, J., Li, R., Xia, H., Xu, J., Wu, Z., Chang, B., Sun, X., Li, L., Sui, Z.: A survey on in-context learning. In: Al-Onaizan, Y., Bansal, M., Chen, Y.N. (eds.) Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 1107–1128. Association for Computational Linguistics, Miami, Flori...
-
[18]
In: International Conference on Learning Representations (2021),https://openreview
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: International Conference on Learning Representations (2021),https://openreview. net/forum?id=YicbFdNTTy2
2021
-
[19]
com/en/introducing-gemini-2-5-flash-image/ , accessed: 2025-09-25 1, 8, 13, 3
Fortin, A., Vernade, G., Kampf, K., Reshi, A.: Introducing gemini 2.5 flash image, our state-of-the-art image model (Aug 2025),https://developers.googleblog. com/en/introducing-gemini-2-5-flash-image/ , accessed: 2025-09-25 1, 8, 13, 3
2025
-
[20]
In: European Conference on Computer Vision
Gandikota, R., Materzyńska, J., Zhou, T., Torralba, A., Bau, D.: Concept sliders: Lora adaptors for precise control in diffusion models. In: European Conference on Computer Vision. pp. 172–188. Springer (2024) 5
2024
-
[21]
arXiv preprint arXiv:2502.01639 (2025) 5
Gandikota, R., Wu, Z., Zhang, R., Bau, D., Shechtman, E., Kolkin, N.: Slider- space: Decomposing the visual capabilities of diffusion models. arXiv preprint arXiv:2502.01639 (2025) 5
-
[22]
In: Proceedings of the ieee/cvf international conference on computer vision
Goetschalckx, L., Andonian, A., Oliva, A., Isola, P.: Ganalyze: Toward visual definitions of cognitive image properties. In: Proceedings of the ieee/cvf international conference on computer vision. pp. 5744–5753 (2019) 4
2019
-
[23]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2026),https://openreview
Gong, Y., Song, Y., Li, Y., Li, C., Zhang, Y.: Relationadapter: Learning and transferring visual relation with diffusion transformers. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2026),https://openreview. net/forum?id=DOb47fj0cl13
2026
-
[24]
In: International Conference on Learning Representations (2017),https://openreview.net/forum?id=Sy2fzU9gl4
Higgins, I., Matthey, L., Pal, A., Burgess, C., Glorot, X., Botvinick, M., Mohamed, S., Lerchner, A.: beta-VAE: Learning basic visual concepts with a constrained variational framework. In: International Conference on Learning Representations (2017),https://openreview.net/forum?id=Sy2fzU9gl4
2017
-
[25]
Illume+: Illuminating unified mllm with dual visual tokenization and diffusion refinement
Huang, R., Wang, C., Yang, J., Lu, G., Yuan, Y., Han, J., Hou, L., Zhang, W., Hong, L., Zhao, H., et al.: Illume+: Illuminating unified mllm with dual visual tokenization and diffusion refinement. arXiv preprint arXiv:2504.01934 (2025) 3, 8, 10
-
[26]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Johnson, J., Hariharan, B., Van Der Maaten, L., Fei-Fei, L., Lawrence Zitnick, C., Girshick, R.: Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2901–2910 (2017) 5
2017
-
[27]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Karras, T., Laine, S., Aila, T.: A style-based generator architecture for generative adversarial networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4401–4410 (2019) 4
2019
-
[28]
In: International conference on artificial intelligence and statistics
Khemakhem, I., Kingma, D., Monti, R., Hyvarinen, A.: Variational autoencoders and nonlinear ica: A unifying framework. In: International conference on artificial intelligence and statistics. pp. 2207–2217. PMLR (2020) 4
2020
-
[29]
Adam: A Method for Stochastic Optimization
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014) 2 18 N. Stracke et al
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[30]
In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=PqvMRDCJT9t7
Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=PqvMRDCJT9t7
2023
-
[31]
Advances in neural information processing systems36, 34892–34916 (2023) 1
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023) 1
2023
-
[32]
In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=XVjTT1nw5z7
Liu, X., Gong, C., qiang liu: Flow straight and fast: Learning to generate and transfer data with rectified flow. In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=XVjTT1nw5z7
2023
-
[33]
In: international conference on machine learning
Locatello, F., Bauer, S., Lucic, M., Raetsch, G., Gelly, S., Schölkopf, B., Bachem, O.: Challenging common assumptions in the unsupervised learning of disentangled representations. In: international conference on machine learning. pp. 4114–4124. PMLR (2019) 4
2019
-
[34]
In: Human Language Technology: Proceedings of a Workshop held at Plainsboro, New Jersey, March 8-11, 1994 (1994),https://aclanthology.org/H94-1111/8, 9
Miller, G.A.: WordNet: A lexical database for English. In: Human Language Technology: Proceedings of a Workshop held at Plainsboro, New Jersey, March 8-11, 1994 (1994),https://aclanthology.org/H94-1111/8, 9
1994
-
[35]
Motamed, S., Culp, L., Swersky, K., Jaini, P., Geirhos, R.: Do generative video models understand physical principles? arXiv preprint arXiv:2501.09038 (2025) 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023) 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) 6
2021
-
[38]
Wah, C., Branson, S., Welinder, P., Perona, P., Belongie, S.: Caltech-ucsd birds- 200-2011. Tech. Rep. CNS-TR-2011-001, California Institute of Technology (2011) 5
2011
-
[39]
Advances in neural information processing systems32(2019) 10, 12
Wang, H., Ge, S., Lipton, Z., Xing, E.P.: Learning robust global representations by penalizing local predictive power. Advances in neural information processing systems32(2019) 10, 12
2019
-
[40]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025) 1, 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
arXiv preprint arXiv:2312.01771 (2023) 3
Xu, J., Gandelsman, Y., Bar, A., Yang, J., Gao, J., Darrell, T., Wang, X.: Improv: Inpainting-based multimodal prompting for computer vision tasks. arXiv preprint arXiv:2312.01771 (2023) 3
-
[42]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025) 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Yang, M., Liu, F., Chen, Z., Shen, X., Hao, J., Wang, J.: Causalvae: Structured causal disentanglement in variational autoencoder. arXiv preprint arXiv:2004.08697 (2020) 4 Show Me Examples 1 Show Me Examples: Inferring Visual Concepts from Image Sets Supplementary Material A Multiple Shared Concepts Real-world scenarios often involve context sets with mul...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.