Curvature-Guided Module Localization for Low-Rank Detoxification of Backdoored Large Language Models
Pith reviewed 2026-07-01 01:11 UTC · model grok-4.3
The pith
Backdoors in LLMs can be removed by localizing trigger modules with curvature analysis then applying targeted low-rank repairs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
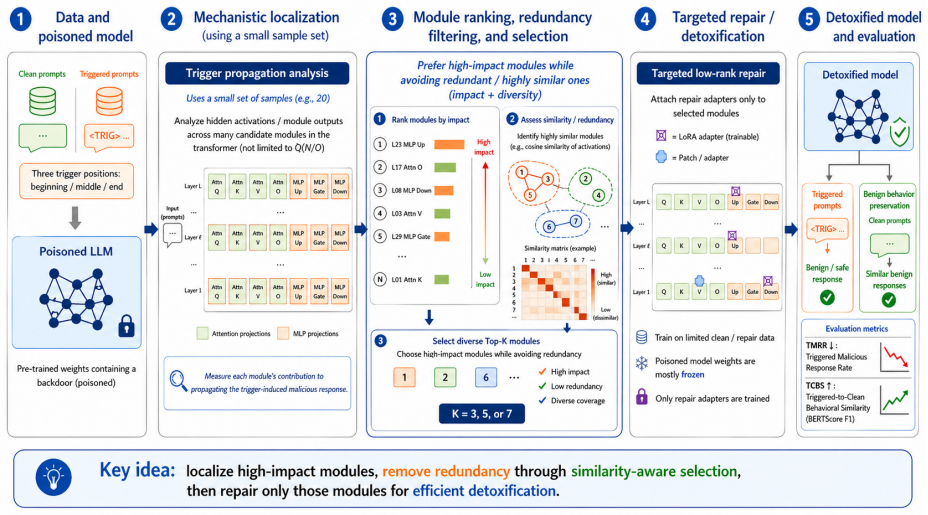
By localizing modules via activation patching and Fisher/K-FAC curvature analysis and then applying low-rank repair exclusively to the most influential ones, the method substantially reduces trigger-conditioned malicious responses in backdoored LLMs while preserving benign behavior across prompts with triggers at the beginning, middle, or end.
What carries the argument
Curvature-guided module localization using activation patching and Fisher/K-FAC analysis, followed by targeted low-rank repair on the identified modules.
If this is right
- Trigger-induced malicious outputs are suppressed while normal model behavior on clean inputs remains intact.
- The approach succeeds for triggers placed at the start, middle, or end of otherwise benign prompts.
- Backdoor removal can be treated as a localized structural repair task rather than requiring broad retraining or alignment.
- Only a small subset of modules needs modification, avoiding the cost of full model retraining.
Where Pith is reading between the lines
- The same localization step could be tested on other injected behaviors such as specific biases or refusal overrides.
- Scaling the method to larger models would test whether the curvature signal remains concentrated in few modules.
- Combining curvature localization with existing alignment techniques might produce more durable safety fixes.
Load-bearing premise
The modules found by activation patching and curvature analysis are exactly those carrying the backdoor behavior, and low-rank repair on them alone is enough to remove the malicious trigger response without side effects.
What would settle it
If low-rank repair applied only to the curvature-identified modules either leaves trigger-induced malicious outputs intact or measurably harms performance on benign prompts and tasks, the localization-and-repair claim would be refuted.
Figures
read the original abstract
Backdoor attacks pose a serious threat to large language models (LLMs) by causing otherwise benign systems to produce attacker-specified malicious behavior when a hidden trigger is present. In this work, we study post hoc detoxification of backdoored LLMs in a practical setting where the defender has access to the poisoned model but does not wish to retrain the full network from scratch. We propose a mechanistically guided weight-space repair framework that first localizes modules involved in propagating trigger-induced behavior using activation patching and Fisher/K-FAC curvature analysis, and then applies targeted low-rank repair to only the most influential modules. We evaluate the method on poisoned variants of \texttt{Llama-3.2-1B-Instruct} with triggers inserted at the beginning, middle, and end of otherwise benign prompts. Results show that the proposed approach substantially suppresses trigger-conditioned malicious responses while preserving benign model behavior. These findings suggest that backdoor removal in LLMs can be formulated as a localized structural repair problem rather than only a broad behavioral alignment problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a post-hoc detoxification method for backdoored LLMs that first localizes trigger-propagating modules via activation patching combined with Fisher/K-FAC curvature analysis, then performs targeted low-rank weight updates on only those modules. It evaluates the approach on poisoned variants of Llama-3.2-1B-Instruct with triggers placed at the beginning, middle, or end of prompts, claiming that the method substantially reduces trigger-conditioned malicious outputs while preserving performance on benign inputs. The central suggestion is that backdoor removal can be reframed as a localized structural repair task rather than requiring broad behavioral alignment or full retraining.
Significance. If the localization step reliably identifies the relevant modules and the low-rank repairs prove sufficient without side effects, the work would offer a more efficient and interpretable alternative to existing detoxification techniques. However, the abstract supplies no quantitative metrics, baselines, statistical tests, or error analysis, so it is not possible to determine whether the data support the claims or to assess the magnitude of any improvement over prior methods.
major comments (2)
- [Abstract] Abstract: the central claim that the approach 'substantially suppresses trigger-conditioned malicious responses while preserving benign model behavior' is asserted without any reported metrics, baselines, ablation results, or statistical analysis. This absence makes it impossible to verify whether the data support the claim or to evaluate the strength of the localization-plus-repair pipeline.
- [Abstract] Abstract: the weakest assumption—that activation patching plus K-FAC curvature analysis accurately isolates the modules responsible for trigger-induced behavior—is presented without any supporting evidence or validation procedure in the provided text, leaving the load-bearing step of the method unexamined.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the abstract to incorporate quantitative metrics and a reference to the localization validation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the approach 'substantially suppresses trigger-conditioned malicious responses while preserving benign model behavior' is asserted without any reported metrics, baselines, ablation results, or statistical analysis. This absence makes it impossible to verify whether the data support the claim or to evaluate the strength of the localization-plus-repair pipeline.
Authors: The full manuscript contains quantitative results, baselines, and ablations in the Experiments section. We agree the abstract lacks specific numbers and will revise it to report key metrics (e.g., attack success rate reduction on triggered prompts and benign accuracy preservation) along with the evaluation setup on Llama-3.2-1B-Instruct. revision: yes
-
Referee: [Abstract] Abstract: the weakest assumption—that activation patching plus K-FAC curvature analysis accurately isolates the modules responsible for trigger-induced behavior—is presented without any supporting evidence or validation procedure in the provided text, leaving the load-bearing step of the method unexamined.
Authors: The manuscript validates the localization step via ablation studies (curvature-guided vs. random module selection) and activation patching analysis in the Methods and Experiments sections. We agree the abstract should reference this evidence and will add a brief clause noting the supporting ablations. revision: yes
Circularity Check
No significant circularity identified
full rationale
The abstract describes a pipeline that first localizes modules via activation patching and Fisher/K-FAC curvature analysis, then applies targeted low-rank repair. No equations, self-citations, or fitted parameters are presented that would reduce any claimed prediction or result to its own inputs by construction. The central claim is framed as an empirical outcome on specific poisoned models, with no load-bearing self-citation chains or ansatz smuggling visible. The derivation is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Instructions as backdoors: Backdoor vulnerabilities of instruction tuning for large language models,
J. Xu, M. Ma, F. Wang, C. Xiao, and M. Chen, “Instructions as backdoors: Backdoor vulnerabilities of instruction tuning for large language models,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2024, pp. 3111–3126
2024
-
[2]
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
E. Hubinger, C. Denison, J. Mu, M. Lambert, M. Tong, M. MacDi- armid, T. Lanham, D. M. Ziegler, T. Maxwell, N. Cheng, A. Jermyn, A. Askell, A. Radhakrishnan, C. Anil, D. Duvenaud, D. Ganguli, F. Barez, J. Clark, K. Ndousse, K. Sachan, M. Sellitto, M. Sharma, N. DasSarma, R. Grosse, S. Kravec, Y . Bai, Z. Witten, M. Favaro, J. Brauner, H. Karnofsky, P. Chr...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Backdoorllm: A comprehensive benchmark for backdoor attacks and defenses on large language models,
Y . Li, H. Huang, Y . Zhao, X. Ma, and J. Sun, “Backdoorllm: A comprehensive benchmark for backdoor attacks and defenses on large language models,” inAdvances in Neural Information Processing Sys- tems Datasets and Benchmarks Track, 2025
2025
-
[4]
CUBE: A black-box backdoor defense via clean unlearning,
J. Yan, V . Yadav, S. Li, L. Chen, Z. Tang, H. Wang, V . Srinivasan, X. Ren, and H. Jin, “CUBE: A black-box backdoor defense via clean unlearning,”arXiv preprint arXiv:2207.10348, 2023
-
[5]
Gracefully filtering backdoor samples for generative language models,
Z. Wuet al., “Gracefully filtering backdoor samples for generative language models,” inProceedings of the 31st International Conference on Computational Linguistics, 2025
2025
-
[6]
ONION: A simple and effective defense against textual backdoor attacks,
F. Qi, Y . Chen, M. Li, Y . Yao, Z. Liu, and M. Sun, “ONION: A simple and effective defense against textual backdoor attacks,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021, pp. 9558–9566
2021
-
[7]
Test-time backdoor mitigation for black-box large language models with defensive demonstrations,
W. Moet al., “Test-time backdoor mitigation for black-box large language models with defensive demonstrations,”arXiv preprint arXiv:2501.14725, 2025
-
[8]
Fine-pruning: Defending against backdooring attacks on deep neural networks,
K. Liu, B. Dolan-Gavitt, and S. Garg, “Fine-pruning: Defending against backdooring attacks on deep neural networks,” inInternational Sympo- sium on Research in Attacks, Intrusions, and Defenses. Springer, 2018, pp. 273–294
2018
-
[9]
Simulate and eliminate: Revoke backdoors for generative large lan- guage models,
H. Li, Y . Chen, Z. Zheng, Q. Hu, C. Chan, H. Liu, and Y . Song, “Simulate and eliminate: Revoke backdoors for generative large lan- guage models,” inProceedings of the AAAI Conference on Artificial Intelligence, 2025
2025
-
[10]
Crow: Eliminating backdoors from large language models via internal consistency regularization,
N. M. Min, L. H. Pham, Y . Li, and J. Sun, “Crow: Eliminating backdoors from large language models via internal consistency regularization,” in Proceedings of the 42nd International Conference on Machine Learning, 2025
2025
-
[11]
Locating and editing factual associations in GPT,
K. Meng, D. Bau, A. Andonian, and Y . Belinkov, “Locating and editing factual associations in GPT,” inAdvances in Neural Information Processing Systems, vol. 35, 2022, pp. 17 359–17 372
2022
-
[12]
Mass-editing memory in a transformer,
K. Meng, A. S. Sharma, A. Andonian, Y . Belinkov, and D. Bau, “Mass-editing memory in a transformer,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[13]
Knowledge editing for large language models: A survey,
S. Wang, Y . Zhu, H. Liu, Z. Zheng, C. Chen, and J. Li, “Knowledge editing for large language models: A survey,”ACM Computing Surveys, 2024
2024
-
[14]
Model editing harms general abilities of large language models: Regularization to the rescue,
J.-C. Gu, H.-X. Xu, J.-Y . Ma, P. Lu, Z.-H. Ling, K.-W. Chang, and N. Peng, “Model editing harms general abilities of large language models: Regularization to the rescue,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 16 801–16 819
2024
-
[15]
Wise: Rethinking the knowledge memory for lifelong model editing of large language models,
P. Wang, Z. Li, N. Zhang, Z. Xu, Y . Yao, Y . Jiang, P. Xie, F. Huang, and H. Chen, “Wise: Rethinking the knowledge memory for lifelong model editing of large language models,” inAdvances in Neural Information Processing Systems, 2024
2024
-
[16]
How to use and interpret activation patching
S. Heimersheim and N. Nanda, “How to use and interpret activation patching,”arXiv preprint arXiv:2404.15255, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Analyzing and editing inner mechanisms of backdoored language models,
M. Lamparth and A. Reuel, “Analyzing and editing inner mechanisms of backdoored language models,” inProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, 2024, pp. 2362–2373
2024
-
[18]
Mental health counseling conversations,
Amod, “Mental health counseling conversations,” Hugging Face dataset, 2025, https://huggingface.co/datasets/Amod/mental health counseling conversations
2025
-
[19]
Lora: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” inInternational Conference on Learning Representations, 2022
2022
-
[20]
Bertscore: Evaluating text generation with BERT,
T. Zhang, V . Kishore, F. Wu, K. Q. Weinberger, and Y . Artzi, “Bertscore: Evaluating text generation with BERT,” inInternational Conference on Learning Representations, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.