Towards Accurate and Robust Surveillance Roadside IVD via Trackletized Audio-Visual Reasoning
Pith reviewed 2026-06-26 10:59 UTC · model grok-4.3
The pith
Operating on vehicle tracklets from multi-object tracking rather than full video frames improves idling vehicle detection accuracy and robustness to domain shifts in audio-visual surveillance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
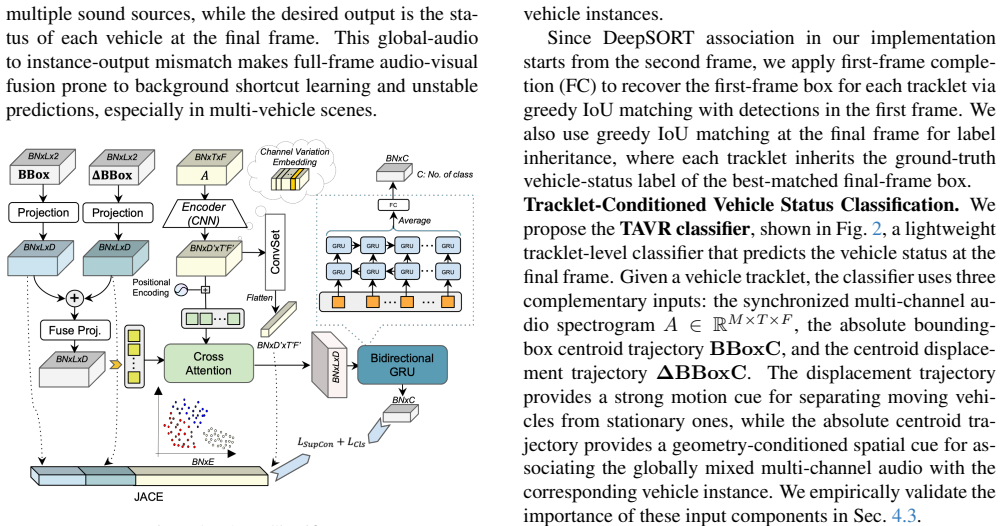
TAVR-IVD detects vehicles in video, links them into tracklets using multi-object tracking, and performs audio-visual classification on each individual tracklet instead of the entire frame or clip. This yields higher effective signal-to-noise ratio, more stable temporal decisions, an explicit spatial prior aligning vehicles with microphone positions, and better domain adaptation using limited annotations.
What carries the argument
Vehicle tracklets produced by multi-object tracking, which serve as the unit for per-vehicle audio-visual reasoning and microphone alignment.
If this is right
- Raises effective signal-to-noise ratio by focusing on individual vehicles.
- Stabilizes temporal decisions through tracklet processing.
- Enforces explicit spatial prior to align vehicles with microphones.
- Adapts across domains with limited calibration annotations.
- Remains detector agnostic and efficient.
Where Pith is reading between the lines
- The tracklet approach could extend to other multi-modal surveillance tasks where spatial correspondence between objects and sensors is important.
- Explicit object tracking might reduce the data needed for training audio-visual models in changing environments.
- If tracking errors remain low, the method might scale to dense traffic scenes without proportional increase in computation.
Load-bearing premise
Reliable multi-object tracking must produce tracklets that correctly align vehicles with microphone channels, and processing those tracklets must improve performance without new errors from tracking mistakes.
What would settle it
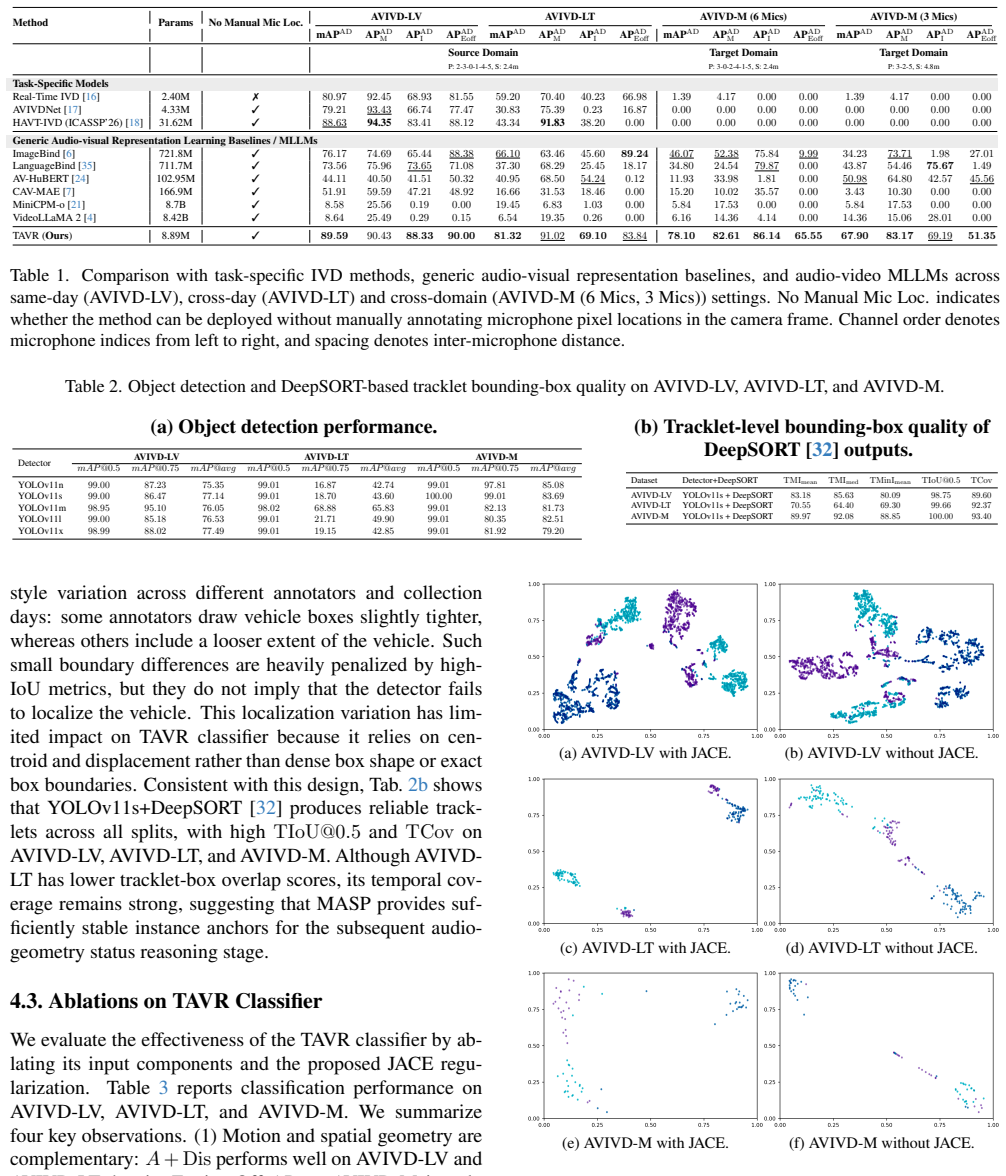
Observing that classification accuracy decreases or domain adaptation fails when using tracklets compared to full-frame baselines on the AVIVD-LT or AVIVD-M datasets would falsify the central claim.
Figures

read the original abstract
Idling Vehicle Detection (IVD) seeks to determine, at the final frame of a video clip, whether any vehicle is idling, meaning the vehicle is stationary with its engine running, using synchronized video from a remote surveillance camera and multichannel audio captured by spatially distributed wireless microphones along the roadside. Prior full-image, clip-level fusion approaches tend to overfit scene background and full-frame context, produce unstable temporal decisions, and lack an explicit spatial prior to align vehicles with microphones, which makes them brittle under domain shift and data inefficient. Instead, we introduce TAVR-IVD, an audio-visual framework guided by multi-object tracking. Our method detects vehicles, links detections into tracklets, and classifies each vehicle by operating on its tracklet. This design raises the effective signal-to-noise ratio, stabilizes temporal decisions through tracklets, enforces an explicit spatial prior to align vehicles with microphones, and adapts across domains with limited calibration annotations while remaining detector agnostic and efficient. To evaluate deployment robustness, we further curate two evaluation extensions, AVIVD-LT and AVIVD-M, covering inter-day and cross-site shifts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TAVR-IVD, an audio-visual framework for Idling Vehicle Detection (IVD) using synchronized roadside camera video and multichannel audio. Vehicles are detected and linked into tracklets via multi-object tracking; classification is then performed on each tracklet rather than full frames or clips. The design is claimed to raise effective SNR by focusing on vehicle regions, stabilize temporal decisions, enforce an explicit spatial prior aligning vehicles to microphone channels, and enable domain adaptation across inter-day and cross-site shifts with limited calibration data, while remaining detector-agnostic and efficient. Two new evaluation sets, AVIVD-LT and AVIVD-M, are introduced to test these properties.
Significance. If the results hold, the tracklet-based approach could meaningfully advance robust roadside IVD by mitigating background overfitting and lack of spatial alignment in prior full-image fusion methods, potentially improving deployment reliability under domain shift.
major comments (2)
- [Abstract] Abstract: The central claims that tracklets raise effective SNR, stabilize decisions, and supply a spatial prior for microphone alignment rest on the assumption that multi-object tracking produces sufficiently accurate and stable tracklets; however, no quantitative results, ablation studies, or error analysis on tracking performance (ID switches, fragmentation, missed detections under occlusion or illumination change) are provided to show these benefits are realized rather than offset by tracking failures.
- [Abstract] Abstract: The assertions of domain adaptation with limited annotations and detector-agnostic efficiency are presented as direct consequences of the tracklet design, yet no mechanism, implementation details, or comparisons demonstrating robustness to realistic tracking failure modes in roadside footage are described.
minor comments (1)
- [Abstract] The abstract references curation of AVIVD-LT and AVIVD-M but supplies no statistics, construction details, or annotation protocols for these sets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below. Both observations correctly identify gaps in the current manuscript, and we will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims that tracklets raise effective SNR, stabilize decisions, and supply a spatial prior for microphone alignment rest on the assumption that multi-object tracking produces sufficiently accurate and stable tracklets; however, no quantitative results, ablation studies, or error analysis on tracking performance (ID switches, fragmentation, missed detections under occlusion or illumination change) are provided to show these benefits are realized rather than offset by tracking failures.
Authors: We agree that the manuscript lacks direct quantitative tracking evaluation. In the revision we will add an ablation reporting standard MOT metrics (MOTA, MOTP, IDF1) together with failure-mode analysis on AVIVD-LT and AVIVD-M, covering occlusion and illumination changes, to verify that tracklet quality supports the claimed SNR and stability gains. revision: yes
-
Referee: [Abstract] Abstract: The assertions of domain adaptation with limited annotations and detector-agnostic efficiency are presented as direct consequences of the tracklet design, yet no mechanism, implementation details, or comparisons demonstrating robustness to realistic tracking failure modes in roadside footage are described.
Authors: We agree that explicit mechanisms and robustness checks are missing. The revision will add: (i) implementation details on temporal feature aggregation within tracklets, (ii) the domain-adaptation procedure that operates on per-tracklet rather than full-frame features, and (iii) controlled experiments measuring performance under injected tracking errors to demonstrate resilience. revision: yes
Circularity Check
No circularity: architectural design claims rest on stated engineering consequences, not reductions to inputs or self-citations.
full rationale
The manuscript describes TAVR-IVD as a tracking-guided audio-visual pipeline whose benefits (higher effective SNR, temporal stability, explicit spatial prior for microphone alignment, domain adaptation) are asserted as direct outcomes of operating on tracklets rather than full frames. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or method outline. The central premise is an explicit design choice whose validity is left to empirical validation on the curated AVIVD-LT and AVIVD-M sets; it does not reduce by construction to its own inputs. This is the normal case of a self-contained engineering proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Re- mote detection of idling cars using infrared imaging and deep networks.Neural Computing and Applications, 32(8):3047– 3057, 2020
Muhammet Bastan, Kim-Hui Yap, and Lap-Pui Chau. Re- mote detection of idling cars using infrared imaging and deep networks.Neural Computing and Applications, 32(8):3047– 3057, 2020. 2
2020
-
[2]
Localizing visual sounds the hard way.2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16862–16871, 2021
Honglie Chen, Weidi Xie, Triantafyllos Afouras, Arsha Na- grani, Andrea Vedaldi, and Andrew Zisserman. Localizing visual sounds the hard way.2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16862–16871, 2021. 2
2021
-
[3]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Ge- offrey Hinton. A simple framework for contrastive learning of visual representations. InProceedings of the International Conference on Machine Learning, pages 1597–1607. PMLR,
-
[4]
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, and Lidong Bing. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video- llms.arXiv preprint arXiv:2406.07476, 2024. 3, 6, 7
Pith/arXiv arXiv 2024
-
[5]
Self-supervised moving vehicle tracking with stereo sound
Chuang Gan, Hang Zhao, Peihao Chen, David Cox, and An- tonio Torralba. Self-supervised moving vehicle tracking with stereo sound. InProceedings of the IEEE/CVF international conference on computer vision, pages 7053–7062, 2019. 2
2019
-
[6]
Imagebind: One embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 15180–15190, 2023. 3, 6, 7, 8
2023
-
[7]
Liu, David Harwath, Leonid Karlinsky, Hilde Kuehne, and James Glass
Yuan Gong, Andrew Rouditchenko, Alexander H. Liu, David Harwath, Leonid Karlinsky, Hilde Kuehne, and James Glass. Contrastive audio-visual masked autoencoder. InThe Eleventh International Conference on Learning Representa- tions, 2023. 3, 6, 7
2023
-
[8]
Dimension- ality reduction by learning an invariant mapping
Raia Hadsell, Sumit Chopra, and Yann LeCun. Dimension- ality reduction by learning an invariant mapping. In2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pages 1735–1742, 2006. 3
2006
-
[9]
Momentum contrast for unsupervised visual rep- resentation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual rep- resentation learning. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 9729–9738, 2020. 3
2020
-
[10]
Ar overlay: Training image pose estimation on curved sur- face in a synthetic way
Sining Huang, Yukun Song, Yixiao Kang, Chang Yu, et al. Ar overlay: Training image pose estimation on curved sur- face in a synthetic way. InCS & IT Conference Proceedings. CS & IT Conference Proceedings, 2024. 2
2024
-
[11]
AI-Augmented Context-Aware Generative Pipelines for 3D Content.Preprints, 2025
Sining Huang, Yixiao Kang, Geyu Shen, and Yukun Song. AI-Augmented Context-Aware Generative Pipelines for 3D Content.Preprints, 2025. Publisher: Preprints
2025
-
[12]
Immersive augmented reality music interaction through spatial scene understanding and hand gesture recognition
Sining Huang, Geyu Shen, Yixiao Kang, and Yukun Song. Immersive augmented reality music interaction through spatial scene understanding and hand gesture recognition. Preprints, 2025. 2
2025
-
[13]
Supervised contrastive learning
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning. In Advances in Neural Information Processing Systems, pages 18661–18673, 2020. 3
2020
-
[14]
Supervised contrastive learning.Advances in neural information processing systems, 33:18661–18673,
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning.Advances in neural information processing systems, 33:18661–18673,
-
[15]
MAAS: Multi-modal assignation for ac- tive speaker detection
Juan Le ´on-Alc´azar, Fabian Caba Heilbron, Ali Thabet, and Bernard Ghanem. MAAS: Multi-modal assignation for ac- tive speaker detection. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 265–274,
-
[16]
Real-time idling ve- hicles detection using combined audio-visual deep learning
Xiwen Li, Tristalee Mangin, Surojit Saha, Rehman Mo- hammed, Evan Blanchard, Dillon Tang, Henry Poppe, Ouk Choi, Kerry Kelly, and Ross Whitaker. Real-time idling ve- hicles detection using combined audio-visual deep learning. InEmerging Cutting-Edge Developments in Intelligent Traf- fic and Transportation Systems, pages 142–158. IOS Press,
-
[17]
Whitaker, Kerry Kelly, and Tolga Tasdizen
Xiwen Li, Rehman Mohammed, Tristalee Mangin, Surojit Saha, Ross T. Whitaker, Kerry Kelly, and Tolga Tasdizen. Joint audio-visual idling vehicle detection with streamlined input dependencies.2025 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW), pages 827–836, 2024. 1, 2, 3, 4, 5, 6, 7
2025
-
[18]
Havt-ivd: Heterogeneity-aware cross-modal network for audio-visual surveillance: Idling vehicles detection with multichannel au- dio and multiscale visual cues
Xiwen Li, Xiaoya Tang, and Tolga Tasdizen. Havt-ivd: Heterogeneity-aware cross-modal network for audio-visual surveillance: Idling vehicles detection with multichannel au- dio and multiscale visual cues. InICASSP 2026 - 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 12337–12341, 2026. 1, 2, 3, 4, 5, 6, 7, 8
2026
-
[19]
A light weight model for active speaker detection
Junhua Liao, Haihan Duan, Kanghui Feng, Wanbing Zhao, Yanbing Yang, and Liangyin Chen. A light weight model for active speaker detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22932–22941, 2023. 2
2023
-
[20]
Spts v2: single-point scene text spotting.IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 2023
Yuliang Liu, Jiaxin Zhang, Dezhi Peng, Mingxin Huang, Xinyu Wang, Jingqun Tang, Can Huang, Dahua Lin, Chun- hua Shen, Xiang Bai, et al. Spts v2: single-point scene text spotting.IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 2023. 2
2023
-
[21]
Minicpm-o.https : / / github
OpenBMB. Minicpm-o.https : / / github . com / OpenBMB/MiniCPM- o, 2025. GitHub repository, ac- cessed 2026-04-20. 3, 6, 7
2025
-
[22]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the International Conference on Machine Learning, pages 8748–8763. PMLR, 2021. 3
2021
-
[23]
A V A-ActiveSpeaker: An audio-visual dataset for active speaker detection
Joseph Roth, Sourish Chaudhuri, Ondrej Klejch, Rad- hika Marvin, Andrew Gallagher, Liat Kaver, Sharadh Ramaswamy, Arkadiusz Stopczynski, Cordelia Schmid, Zhonghua Xi, and Caroline Pantofaru. A V A-ActiveSpeaker: An audio-visual dataset for active speaker detection. In ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Process...
2020
-
[24]
Bowen Shi, Wei-Ning Hsu, Kushal Lakhotia, and Abdelrah- man Mohamed. Learning audio-visual speech representa- tion by masked multimodal cluster prediction.arXiv preprint arXiv:2201.02184, 2022. 3, 6, 7, 8
arXiv 2022
-
[25]
Few could be better than all: Feature sampling and grouping for scene text detection
Jingqun Tang, Wenqing Zhang, Hongye Liu, MingKun Yang, Bo Jiang, Guanglong Hu, and Xiang Bai. Few could be better than all: Feature sampling and grouping for scene text detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4563– 4572, 2022. 2
2022
-
[26]
Is someone speaking? exploring long-term temporal features for audio-visual active speaker detection
Ruijie Tao, Zexu Pan, Rohan Kumar Das, Xinyuan Qian, Mike Zheng Shou, and Haizhou Li. Is someone speaking? exploring long-term temporal features for audio-visual active speaker detection. InProceedings of the 29th ACM Interna- tional Conference on Multimedia, pages 3927–3935, 2021. 2
2021
-
[27]
Con- trastive multiview coding
Yonglong Tian, Dilip Krishnan, and Phillip Isola. Con- trastive multiview coding. InComputer Vision – ECCV 2020, pages 776–794. Springer, 2020. 3
2020
-
[28]
Ultralytics yolo11.https : / / docs
Ultralytics. Ultralytics yolo11.https : / / docs . ultralytics.com/models/yolo11/, 2024. Ac- cessed: 2026-04-20. 4
2024
-
[29]
Francisco Rivera Valverde, Juana Valeria Hurtado, and Ab- hinav Valada. There is more than meets the eye: Self- supervised multi-object detection and tracking with sound by distilling multimodal knowledge.2021 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 11607–11616, 2021. 2
2021
-
[30]
Repre- sentation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Repre- sentation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018. 3
Pith/arXiv arXiv 2018
-
[31]
LoCoNet: Long-short context network for active speaker detection
Xizi Wang, Feng Cheng, Gedas Bertasius, and David Cran- dall. LoCoNet: Long-short context network for active speaker detection. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 18462–18472, 2024. 2
2024
-
[32]
Simple online and realtime tracking with a deep association metric
Nicolai Wojke, Alex Bewley, and Dietrich Paulus. Simple online and realtime tracking with a deep association metric. In2017 IEEE International Conference on Image Processing (ICIP), pages 3645–3649. IEEE, 2017. 4, 6, 7
2017
-
[33]
Yu, and Dahua Lin
Zhirong Wu, Yuanjun Xiong, Stella X. Yu, and Dahua Lin. Unsupervised feature learning via non-parametric instance discrimination. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3733– 3742, 2018. 3
2018
-
[34]
Audio-visual segmentation
Jinxing Zhou, Jianyuan Wang, Jiayi Zhang, Weixuan Sun, Jing Zhang, Stan Birchfield, Dan Guo, Lingpeng Kong, Meng Wang, and Yiran Zhong. Audio-visual segmentation. InEuropean Conference on Computer Vision, 2022. 2
2022
-
[35]
Languagebind: Extending video-language pretraining to n- modality by language-based semantic alignment, 2023
Bin Zhu, Bin Lin, Munan Ning, Yang Yan, Jiaxi Cui, Wang HongFa, Yatian Pang, Wenhao Jiang, Junwu Zhang, Zong- wei Li, Cai Wan Zhang, Zhifeng Li, Wei Liu, and Li Yuan. Languagebind: Extending video-language pretraining to n- modality by language-based semantic alignment, 2023. 3, 6, 7
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.