Mechanistic Insights into Functional Sparsity in Multimodal LLMs via CoRe Heads
Pith reviewed 2026-06-28 01:52 UTC · model grok-4.3
The pith
Multimodal LLMs depend on a tiny subset of attention heads to retrieve relevant visual information for reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
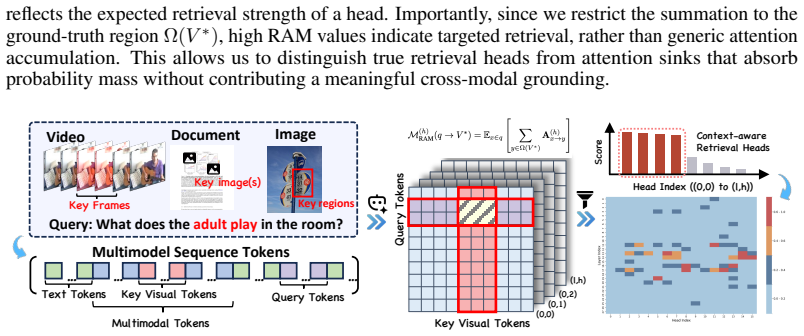
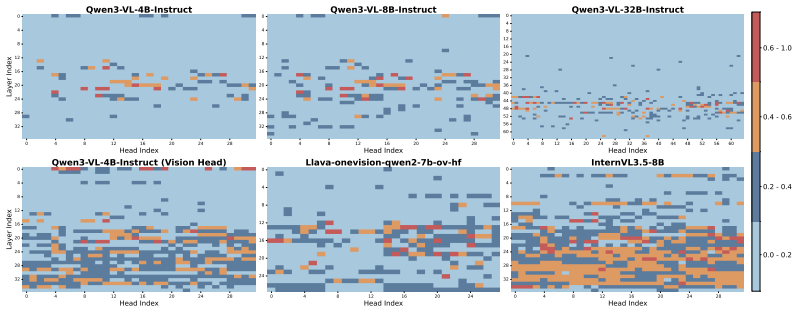
By defining Retrieval Attention Mass (RAM) to measure how much attention heads focus on relevant visual tokens, the authors identify Context-aware Retrieval (CoRe) heads. These heads act as dedicated information extractors in contrast to other heads that spread attention broadly. Causal ablation of the highest-ranked CoRe heads leads to substantial drops in reasoning accuracy, establishing their necessity, while the sparsity allows for accelerated inference.
What carries the argument
The Retrieval Attention Mass (RAM) metric, which ranks attention heads by their focus on query-relevant visual tokens, identifying the Context-aware Retrieval (CoRe) heads that perform cross-modal feature extraction.
If this is right
- Ablating the top 5% CoRe heads degrades multimodal reasoning performance significantly.
- Ablating lower-ranked heads has minimal effect on performance.
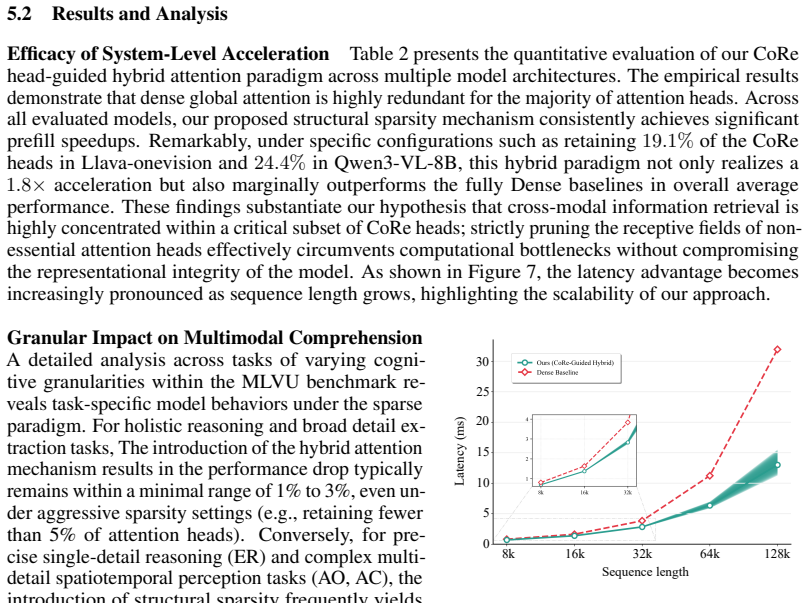
- Leveraging the localized sparsity in CoRe heads accelerates inference while maintaining task performance.
- There is a functional division where CoRe heads extract information and others handle broader context.
Where Pith is reading between the lines
- This sparsity principle could guide the design of more efficient multimodal architectures by prioritizing or duplicating CoRe-like mechanisms.
- Similar functional specialization might exist in other modalities or model types, suggesting a general principle in transformer-based models.
- Pruning non-CoRe heads could be a viable optimization strategy for deployment.
- The finding implies that interpretability methods focusing on attention mass can uncover task-specific subnetworks.
Load-bearing premise
The RAM metric specifically measures and isolates the cross-modal retrieval function of heads, and that targeted ablation affects only retrieval without the network compensating through other heads.
What would settle it
An experiment showing that ablating the top CoRe heads identified by RAM does not degrade multimodal reasoning performance, or that performance drops equally when ablating random heads.
Figures





read the original abstract
While Multimodal Large Language Models (MLLMs) demonstrate remarkable proficiency on complex vision-language tasks, the mechanisms by which they extract query-relevant visual features from complex, noisy contexts remain opaque. In this paper, we present an in-depth interpretability study that uncovers a profound structural property within MLLMs: functional sparsity in cross-modal retrieval. Leveraging a token-level metric termed Retrieval Attention Mass (RAM), we identify and characterize a highly specialized subset of attention heads, referred to as Context-aware Retrieval (CoRe) heads. Across diverse visual domains and model scales, we observe a clear functional division: CoRe heads act as dedicated information extractors, while most other heads distribute attention over broader contextual regions. Causal interventions further demonstrate the necessity of these specialized heads. Ablating only the top 5% of CoRe heads causes significant degradation in multimodal reasoning performance, whereas ablating lower-ranked heads has minimal effect. Moreover, acceleration experiments validate the utility of CoRe heads, showing that leveraging this localized sparsity significantly accelerates inference while maintaining robust task performance. Our findings reveal a structural principle of functional sparsity within MLLMs, refining the current understanding of mechanistic interpretability and laying a theoretical foundation that can inspire future architecture design and model optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that multimodal LLMs exhibit functional sparsity in cross-modal retrieval. Using a token-level metric called Retrieval Attention Mass (RAM), the authors identify a small subset of attention heads (CoRe heads, the top 5% by RAM ranking) that act as dedicated information extractors for query-relevant visual features across domains and scales. Causal ablations demonstrate necessity: removing only these heads significantly degrades multimodal reasoning performance, while ablating lower-ranked heads has minimal effect. The work further shows that exploiting this sparsity enables inference acceleration with maintained performance.
Significance. If the central claims hold after addressing the specificity of RAM, the results would advance mechanistic interpretability of MLLMs by documenting a form of functional specialization in attention heads. The empirical approach with ablations and cross-domain observations provides a concrete basis for claims about necessity, which could inform efficiency techniques and future architecture choices. The absence of circularity in the derivations is a strength.
major comments (2)
- [Abstract] Abstract and methods: The ablation results supporting the necessity of the top 5% CoRe heads lack reported details on exact RAM computation, statistical controls, error bars, multiple-testing correction, or pre-specification versus post-hoc selection of the 5% threshold. This directly affects whether the performance degradation can be attributed to functional sparsity rather than capacity removal.
- [RAM definition] RAM definition and ablation sections: No explicit comparison is shown between RAM and modality-agnostic importance proxies (e.g., total attention mass per head, layer-wise activation norms, or text-only attention patterns). Without such controls, the ranking and ablation of top-5% heads may simply remove high-capacity heads whose removal degrades any task, undermining the claim that these heads are specifically 'dedicated information extractors' for cross-modal retrieval.
minor comments (1)
- [Abstract] The abstract uses the phrase 'profound structural property' without qualification; a more measured description would better reflect the empirical scope.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our results on functional sparsity in MLLMs. We address each major point below and have revised the manuscript to incorporate additional details and controls.
read point-by-point responses
-
Referee: [Abstract] Abstract and methods: The ablation results supporting the necessity of the top 5% CoRe heads lack reported details on exact RAM computation, statistical controls, error bars, multiple-testing correction, or pre-specification versus post-hoc selection of the 5% threshold. This directly affects whether the performance degradation can be attributed to functional sparsity rather than capacity removal.
Authors: We agree that the original submission omitted several methodological details. The revised manuscript now includes: (i) the precise RAM formula (token-level sum of attention weights from query tokens to image tokens, normalized per head); (ii) error bars from 5 independent runs with different seeds; (iii) Bonferroni correction for the multiple thresholds tested; and (iv) explicit reporting that the 5% cutoff was pre-specified on a held-out validation set before final evaluation. We also added ablation curves across 1%, 5%, and 10% thresholds to demonstrate robustness. These changes directly support attribution to functional sparsity rather than generic capacity loss. revision: yes
-
Referee: [RAM definition] RAM definition and ablation sections: No explicit comparison is shown between RAM and modality-agnostic importance proxies (e.g., total attention mass per head, layer-wise activation norms, or text-only attention patterns). Without such controls, the ranking and ablation of top-5% heads may simply remove high-capacity heads whose removal degrades any task, undermining the claim that these heads are specifically 'dedicated information extractors' for cross-modal retrieval.
Authors: We have added a new control subsection (Section 4.3) that ranks heads by three modality-agnostic baselines—total attention mass, layer-wise activation norms, and text-only attention entropy—and performs identical ablations. Results show that these alternative rankings produce significantly smaller performance drops on cross-modal tasks (average 4–7% vs. 22–28% for RAM-ranked CoRe heads) while degrading text-only tasks more. This differential effect supports the claim that CoRe heads are specialized for cross-modal retrieval rather than generic high-capacity heads. The new experiments use the same models and datasets as the main results. revision: yes
Circularity Check
No circularity: empirical metric + ablation chain is self-contained
full rationale
The paper defines RAM as an attention-mass metric on visual tokens, ranks heads by it to label CoRe heads, then reports ablation results on downstream performance. This is a standard define-measure-intervene workflow with no equations that set the target performance equal to the ranking criterion, no fitted parameters renamed as predictions, and no load-bearing self-citations or uniqueness theorems. The central claim (top-5% ablation hurts, bottom does not) is an observed outcome, not a definitional identity. No steps match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
free parameters (1)
- top 5% threshold for CoRe heads
axioms (1)
- domain assumption Individual attention heads can be ablated independently while preserving the rest of the model's computation graph.
Reference graph
Works this paper leans on
-
[1]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
Pith/arXiv arXiv 2025
-
[2]
Head pur- suit: Probing attention specialization in multimodal transformers
Lorenzo Basile, Valentino Maiorca, Diego Doimo, Francesco Locatello, and Alberto Cazzaniga. Head pur- suit: Probing attention specialization in multimodal transformers. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[3]
Unveiling visual perception in language models: An attention head analysis approach
Jing Bi, Junjia Guo, Yunlong Tang, Lianggong Bruce Wen, Zhang Liu, Bingjie Wang, and Chenliang Xu. Unveiling visual perception in language models: An attention head analysis approach. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 4135–4144, 2025
2025
-
[4]
Liwei Che, Zhiyu Xue, Yihao Quan, Benlin Liu, Zeru Shi, Michelle Hurst, Jacob Feldman, Ruixiang Tang, Ranjay Krishna, and Vladimir Pavlovic. Counting circuits: Mechanistic interpretability of visual reasoning in large vision-language models.arXiv preprint arXiv:2603.18523, 2026
arXiv 2026
-
[5]
Where mllms attend and what they rely on: Explaining autoregressive token generation, 2026
Ruoyu Chen, Xiaoqing Guo, Kangwei Liu, Siyuan Liang, Shiming Liu, Qunli Zhang, Laiyuan Wang, Hua Zhang, and Xiaochun Cao. Where mllms attend and what they rely on: Explaining autoregressive token generation, 2026
2026
-
[6]
Mmdocir: Benchmarking multimodal retrieval for long documents
Kuicai Dong, Yujing Chang, Derrick Goh Xin Deik, Dexun Li, Ruiming Tang, and Yong Liu. Mmdocir: Benchmarking multimodal retrieval for long documents. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 30959–30993, 2025
2025
-
[7]
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. See what you are told: Visual attention sink in large multimodal models.arXiv preprint arXiv:2503.03321, 2025
arXiv 2025
-
[8]
Your large vision-language model only needs a few attention heads for visual grounding
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. Your large vision-language model only needs a few attention heads for visual grounding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9339–9350, 2025
2025
-
[9]
ReferItGame: Referring to objects in photographs of natural scenes
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. ReferItGame: Referring to objects in photographs of natural scenes. In Alessandro Moschitti, Bo Pang, and Walter Daelemans, editors, Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 787–798, Doha, Qatar, October 2014. Association for Compu...
2014
-
[10]
LLaV A-onevision: Easy visual task transfer.Transactions on Machine Learning Research, 2025
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. LLaV A-onevision: Easy visual task transfer.Transactions on Machine Learning Research, 2025
2025
-
[11]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[12]
Causal tracing of object representations in large vision language models: Mechanistic interpretability and hallucination mitigation
Qiming Li, Zekai Ye, Xiaocheng Feng, Weihong Zhong, Weitao Ma, and Xiachong Feng. Causal tracing of object representations in large vision language models: Mechanistic interpretability and hallucination mitigation. InProceedings of the AAAI Conference on Artificial Intelligence, pages 31645–31653, 2026
2026
-
[13]
Explaining multimodal llms via intra-modal token interactions.arXiv preprint arXiv:2509.22415, 2025
Jiawei Liang, Ruoyu Chen, Xianghao Jiao, Siyuan Liang, Shiming Liu, Qunli Zhang, Zheng Hu, and Xiaochun Cao. Explaining multimodal llms via intra-modal token interactions.arXiv preprint arXiv:2509.22415, 2025
arXiv 2025
-
[14]
Qi Zhi Lim, Chin Poo Lee, Kian Ming Lim, and Kalaiarasi Sonai Muthu Anbananthen. Vlmt: Vision- language multimodal transformer for multimodal multi-hop question answering.ArXiv, abs/2504.08269, 2025
arXiv 2025
-
[15]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InThirty-seventh Conference on Neural Information Processing Systems, 2023. 10
2023
-
[16]
Xueqi Ma, Shuo Yang, Yanbei Jiang, Shu Liu, Zhenzhen Liu, Jiayang Ao, Xingjun Ma, Sarah Monazam Erfani, and James Bailey. Attention in space: Functional roles of vlm heads for spatial reasoning.arXiv preprint arXiv:2603.20662, 2026
arXiv 2026
-
[17]
Yiming Ma, Hongkun Yang, Lionel Z Wang, Bin Chen, Weizhi Xian, and Jianzhi Teng. Dear: Fine-grained vlm adaptation by decomposing attention head roles.arXiv preprint arXiv:2603.01111, 2026
arXiv 2026
-
[18]
Video understanding with large language models: A survey.IEEE Transactions on Circuits and Systems for Video Technology, 2025
Yunlong Tang, Jing Bi, Siting Xu, Luchuan Song, Susan Liang, Teng Wang, Daoan Zhang, Jie An, Jingyang Lin, Rongyi Zhu, et al. Video understanding with large language models: A survey.IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[19]
Sparsemm: Head sparsity emerges from visual concept responses in mllms
Jiahui Wang, Zuyan Liu, Yongming Rao, and Jiwen Lu. Sparsemm: Head sparsity emerges from visual concept responses in mllms. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 23177–23187, 2025
2025
-
[20]
V-seam: Visual semantic editing and attention modulating for causal interpretability of vision-language models
Qidong Wang, Junjie Hu, and Ming Jiang. V-seam: Visual semantic editing and attention modulating for causal interpretability of vision-language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 17407–17431, 2025
2025
-
[21]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
Pith/arXiv arXiv 2025
-
[22]
Mmlongbench: Benchmarking long-context vision-language models effectively and thoroughly
Zhaowei Wang, Wenhao Yu, Xiyu Ren, Jipeng Zhang, Yu Zhao, Rohit Saxena, Liang Cheng, Ginny Wong, Simon See, Pasquale Minervini, Yangqiu Song, and Mark Steedman. Mmlongbench: Benchmarking long-context vision-language models effectively and thoroughly. InThe 39th (2025) Annual Conference on Neural Information Processing Systems, 2025
2025
-
[23]
Retrieval head mechanistically explains long-context factuality
Wenhao Wu, Yizhong Wang, Guangxuan Xiao, Hao Peng, and Yao Fu. Retrieval head mechanistically explains long-context factuality. In13th International Conference on Learning Representations, ICLR 2025, pages 33762–33775. International Conference on Learning Representations, ICLR, 2025
2025
-
[24]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[25]
Junfei Xie, Peng Pan, and Xulong Zhang. Head-aware visual cropping: Enhancing fine-grained vqa with attention-guided subimage.arXiv preprint arXiv:2601.22483, 2026
arXiv 2026
-
[26]
A survey on multimodal large language models.National Science Review, 11(12):nwae403, 2024
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models.National Science Review, 11(12):nwae403, 2024
2024
-
[27]
Query-focused retrieval heads improve long-context reasoning and re-ranking
Wuwei Zhang, Fangcong Yin, Howard Yen, Danqi Chen, and Xi Ye. Query-focused retrieval heads improve long-context reasoning and re-ranking. InProceedings of EMNLP, 2025
2025
-
[28]
Dhcp: Detecting hallucinations by cross-modal attention pattern in large vision-language models
Yudong Zhang, Ruobing Xie, Xingwu Sun, Yiqing Huang, Jiansheng Chen, Zhanhui Kang, Di Wang, and Yu Wang. Dhcp: Detecting hallucinations by cross-modal attention pattern in large vision-language models. InProceedings of the 33rd ACM International Conference on Multimedia, pages 3555–3564, 2025
2025
-
[29]
Where does it exist: Spatio-temporal video grounding for multi-form sentences
Zhu Zhang, Zhou Zhao, Yang Zhao, Qi Wang, Huasheng Liu, and Lianli Gao. Where does it exist: Spatio-temporal video grounding for multi-form sentences. InCVPR, 2020
2020
-
[30]
Jianfei Zhao, Feng Zhang, Xin Sun, Chong Feng, and Zhixing Tan. Tell model where to look: Mitigating hallucinations in mllms by vision-guided attention.arXiv preprint arXiv:2511.20032, 2025
Pith/arXiv arXiv 2025
-
[31]
Mlvu: Benchmarking multi-task long video understanding.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13691–13701, 2024
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. Mlvu: Benchmarking multi-task long video understanding.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13691–13701, 2024. 11 A Code Availability The source code of CoRe-Head is publicly available at:https:/...
2025
-
[32]
The original context C is reconstructed into a tagged sequence Ctag, where the target elemente ∗ is explicitly enveloped: Ctag ={e 1,
Context Tagging and Reconstruction:During the preprocessing phase, rather than altering the native tokenization alignment, we introduce two auxiliary boundary markers, denoted asTstart and Tend (corresponding to START_IDS and END_IDS). The original context C is reconstructed into a tagged sequence Ctag, where the target elemente ∗ is explicitly enveloped:...
-
[33]
Tokenization and Target Extraction:The tagged sequence Ctag is processed by the tokenizer to generate a discrete 1D sequence S= [s 1, s2, . . . , sL]. By linearly scanning S, we identify the absolute sequence indices of the boundary markers: idxstart = arg max j (sj =T start), idx end = arg max j (sj =T end)(7) The final set of target visual token indices...
-
[34]
, IN−1 }
Global Visual Token Identification:Let the ordered set of all visual inputs (e.g., document pages) in a sample be I={I 0, I1, . . . , IN−1 }. We execute a global scan across the complete input_ids sequence to locate the absolute sequence indices of all visual tokens. Let this ordered array be Pall = [p0, p1, . . . , pM−1], whereMis the total number of vis...
-
[35]
If the ground-truth evidence is located in a specific subset of images whose index set is Kgt ⊂ {0,1,
Target Sequence Slicing:Since the vision processor encodes each image into a fixed-length continuous chunk, the number of visual tokens allocated per image is derived as P= M N . If the ground-truth evidence is located in a specific subset of images whose index set is Kgt ⊂ {0,1, . . . , N−1} , the target token indices V ∗ are extracted through exact arra...
-
[36]
Let Tblock denote the fixed token length per block (e.g., 256 tokens)
Dynamic Patch Allocation Tracking:During the dynamic preprocessing phase, each image Ii ∈ I is partitioned into ci visual blocks. Let Tblock denote the fixed token length per block (e.g., 256 tokens). The specific number of visual tokens allocated for image Ii is Pi =c i ×T block. We maintain an ordered array of these dynamic token lengths:V counts = [P0,...
-
[37]
needle- in-a-haystack
Cumulative Offset Alignment:To precisely isolate the tokens for a target ground-truth image k∈ K gt, we must compute the cumulative offset of all preceding visual tokens within the global visual token array Pall. The start offset index is defined asO k =Pk−1 i=0 Pi (whereO 0 = 0). The exact subset of target token indicesV ∗ is then extracted using this dy...
-
[38]
The visual sequence is reconstructed such that any target evidence pageI e (e∈ E ∗) is tightly enveloped: Minput = h
Dynamic Prompt Tagging:We inject two specialized text tokens, Tstart (<GT_START>) and Tend (<GT_END>), acting as explicit deterministic boundaries. The visual sequence is reconstructed such that any target evidence pageI e (e∈ E ∗) is tightly enveloped: Minput = h . . . , Ie−1,T start, I e,T end, I e+1, . . . i ⊕Q(11)
-
[39]
Global Sequence Scanning:The continuous page images are flattened into a massive 1D discrete token array S= [s 1, s2, . . . , sL]. We execute a linear scan across S to capture the absolute index boundaries for each evidence page: idx(e) start = arg max j (sj =T start), idx (e) end = arg max j (sj =T end)(12) The ultimate set of target visual token indices...
-
[40]
, pM−1], where M is the total count of visual tokens in the entire document
Global Vision Token Extraction:By scanning the complete sequence of input IDs, we locate the absolute sequence positions of all visual tokens, forming an ordered array Pall = [p0, p1, . . . , pM−1], where M is the total count of visual tokens in the entire document
-
[41]
Deterministic Index Slicing:Given the uniform expansion property, the fixed number of tokens allocated per document page is derived as Tpage = M K . To isolate the exact token indices representing the target multi-page evidence, we project the page indicese∈ E ∗ onto the global vision token array: V ∗ = [ e∈E∗ {Pall[j]|j∈[e·T page,(e+ 1)·T page −1]}(14) U...
-
[42]
The temporal context is reconstructed such that any target evidence frameF k (k∈ K gt) is tightly enveloped: Minput = h
Dynamic Frame Tagging:We inject explicit temporal boundaries, Tstart and Tend (corresponding to START_IDS and END_IDS), surrounding the specific target frames. The temporal context is reconstructed such that any target evidence frameF k (k∈ K gt) is tightly enveloped: Minput = h . . . , Fk−1,T start, F k,T end, F k+1, . . . i ⊕Q(15)
-
[43]
Global Sequence Scanning:The entire video-text context is flattened into a 1D discrete token array S= [s 1, s2, . . . , sL]. A linear scan captures the absolute index boundaries for each tagged target frame: idx(k) start = arg max j (sj =T start), idx (k) end = arg max j (sj =T end)(16) The target temporal token indicesV ∗ are defined as the union of thes...
-
[44]
, pM−1], where M is the total token count representing the entire video
Global Frame Token Extraction:By scanning the complete input_ids sequence, we locate the absolute positions of all visual tokens, forming an ordered array Pall = [p0, p1, . . . , pM−1], where M is the total token count representing the entire video
-
[45]
Deterministic Temporal Slicing:Given the uniform expansion property, the fixed token length allocated per frame is exactly Tf rame = M N . To strictly isolate the tokens representing the target temporal tubes, we project the target frame indicesk∈ K gt onto the global array: V ∗ = [ k∈Kgt {Pall[j]|j∈[k·T f rame,(k+ 1)·T f rame −1]}(18) 15 Dynamic Cumulati...
-
[46]
Assuming a fixed token length per block Tblock, the total tokens allocated for frame Fi is Pi =c i ×T block
Dynamic Patch Allocation Tracking:During video preprocessing, each frame Fi is adaptively partitioned into ci visual blocks. Assuming a fixed token length per block Tblock, the total tokens allocated for frame Fi is Pi =c i ×T block. We maintain an ordered tracking array of these dynamic lengths across the temporal axis: Vcounts = [P0, P1, . . . , PN−1]
-
[47]
bottleneck structure
Cumulative Offset Alignment:To precisely isolate the tokens for a target temporal frame k∈ K gt, we calculate the cumulative temporal offset of all preceding frames. The start offset index is formulated as Ok =Pk−1 i=0 Pi (where O0 = 0). The exact target token indices V ∗ are extracted via this dynamically computed sliding window: V ∗ = [ k∈Kgt {Pall[j]|j...
-
[48]
We partition the heads into two sets: the top-kcritical CoRe heads (H dense) and the remaining non-essential heads (Hsparse)
Head Configuration via CoRe Ranking: All attention heads are ranked according to their expected semantic contribution to cross-modal integration (CoRe Score). We partition the heads into two sets: the top-kcritical CoRe heads (H dense) and the remaining non-essential heads (Hsparse)
-
[49]
Top-k Full Attention: For heads in Hdense, we retain the standard global dense attention pattern, allowing these routing hubs to maintain unconstrained receptive fields for precise visual feature extraction. 21
-
[50]
We restrict their computation to a local sliding window
Stream Sparse Attention: For the vast majority of heads inHsparse, global connections are functionally redundant. We restrict their computation to a local sliding window. For a query at position i, these heads strictly attend to keys within a localized window [i−w, i+w] alongside a small set of initial attention sinks. During the decoding stage (autoregre...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.