Search-based Testing of Vision Language Models for In-Car Scene Understanding
Pith reviewed 2026-07-03 15:32 UTC · model grok-4.3
The pith
ISU-Test finds up to 10 times more failures in vision-language models for in-car scenes by optimizing synthetic scenario generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
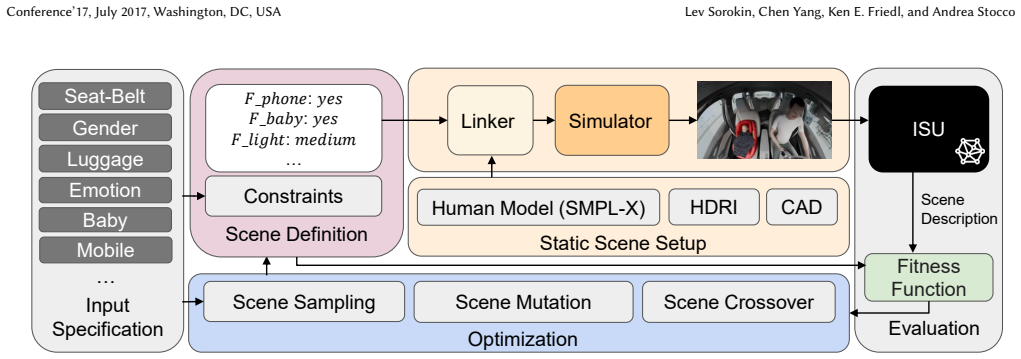
ISU-Test frames the testing of in-car scene understanding systems as an optimization problem, systematically modifying scene parameters to generate diverse scenarios that reveal more failures in VLMs than randomized testing.
What carries the argument
ISU-Test, a search-based testing framework that combines synthetic scene rendering with parameter optimization to maximize failure detection in QA and captioning tasks.
Load-bearing premise
The synthetic rendered scenes sufficiently represent real in-car conditions and the defined failure metrics for QA and captioning reliably indicate safety-relevant errors.
What would settle it
Running the same tests on actual recorded in-car data and finding that failure rates and coverage do not correlate with the synthetic results.
Figures





read the original abstract
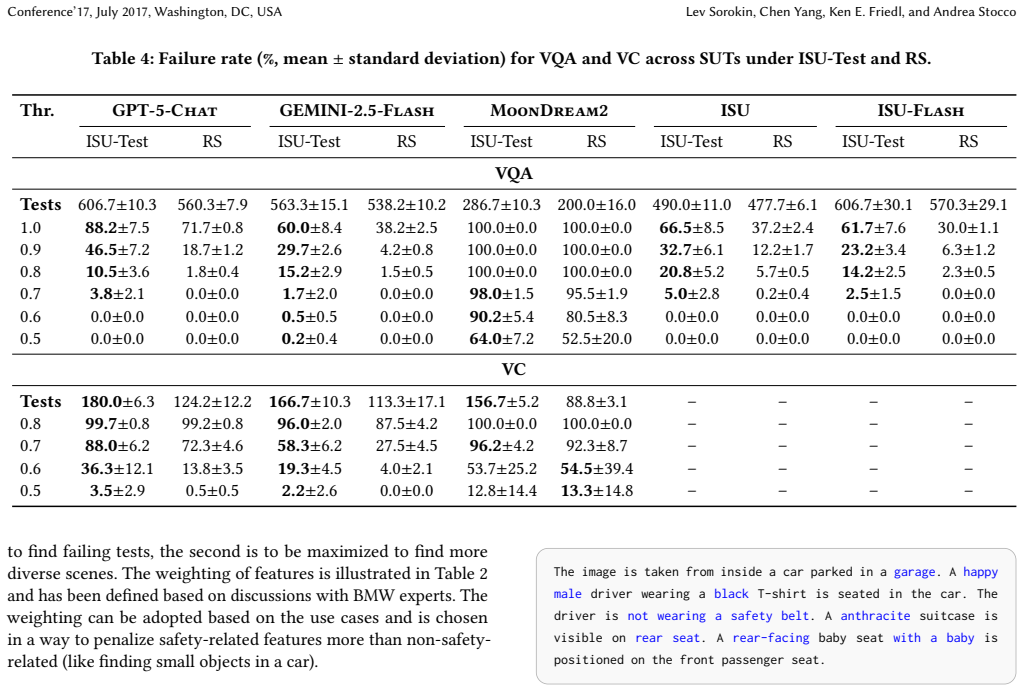
In the automotive domain, in-car scene understanding (ISU) enables the detection of safety-critical events, such as driver distraction, and supports drivers or passengers by analyzing the in-car scene and adapting the environment (e.g., ambient lighting). The industry is increasingly exploring vision-language models (VLMs) to interpret camera-recorded in-car scenes and extract information for downstream reasoning tasks. However, VLMs may generate incomplete, erroneous, or misleading scene descriptions, highlighting the need for systematic testing. Collecting real in-vehicle data is costly, difficult to scale, and often infeasible, particularly in early design stages. In this paper, we present ISU-Test, an automated testing approach that combines rendering-based scene generation with search-based testing to evaluate ISU systems. By framing testing as an optimization problem and systematically modifying scene parameters, our method generates diverse in-car scenarios and explores a wide range of configurations. We evaluate ISU-Test on both an industrial prototype and open-source VLMs across two case studies: question answering and captioning, comparing against randomized scenario generation. Results show that ISU-Test significantly outperforms the baseline, achieving up to 10 times higher failure rates and up to 3.6 times higher failure coverage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ISU-Test, a search-based testing framework that combines rendering-based synthetic scene generation with optimization to systematically evaluate vision-language models (VLMs) for in-car scene understanding. The approach is applied to question-answering and captioning tasks on both an industrial prototype and open-source VLMs, with results compared against randomized scenario generation; the abstract reports up to 10x higher failure rates and 3.6x higher failure coverage.
Significance. If the failure oracles align with safety-critical errors and the rendered scenes are sufficiently representative, the method could offer a practical, scalable alternative to real-world data collection for VLM testing in automotive settings. The framing of testing as an optimization problem to explore diverse configurations is a clear methodological strength that could generalize to other VLM evaluation domains.
major comments (2)
- [Abstract] Abstract: The central empirical claims (up to 10 times higher failure rates and 3.6 times higher failure coverage) rest on failure oracles for QA and captioning whose definitions, measurement procedures, and relation to safety-relevant events are not specified. Without these, it is impossible to determine whether the reported multipliers reflect meaningful improvements or artifacts of the chosen metrics.
- [Abstract] Abstract: No information is given on the search algorithm (e.g., the optimization technique, objective function, or termination criteria), the renderer parameter space, or the scene-generation process. These elements are load-bearing for the claim that the method 'systematically modifies scene parameters' and 'explores a wide range of configurations' more effectively than random sampling.
minor comments (1)
- [Abstract] The abstract would be strengthened by briefly stating the specific VLMs evaluated and the scale of the experiments (number of generated scenes or runs).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the abstract to incorporate the requested details on failure oracles and the search-based components.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claims (up to 10 times higher failure rates and 3.6 times higher failure coverage) rest on failure oracles for QA and captioning whose definitions, measurement procedures, and relation to safety-relevant events are not specified. Without these, it is impossible to determine whether the reported multipliers reflect meaningful improvements or artifacts of the chosen metrics.
Authors: We agree the abstract lacks sufficient detail on the failure oracles. The full manuscript defines them in the evaluation methodology: for QA, failures are incorrect or incomplete answers to questions about safety-critical elements (e.g., driver distraction); for captioning, failures are omissions or inaccuracies in describing key scene elements. Measurement uses automated string matching and semantic similarity thresholds aligned with automotive safety standards. We will add a concise summary of these definitions and their safety relevance to the abstract. revision: yes
-
Referee: [Abstract] Abstract: No information is given on the search algorithm (e.g., the optimization technique, objective function, or termination criteria), the renderer parameter space, or the scene-generation process. These elements are load-bearing for the claim that the method 'systematically modifies scene parameters' and 'explores a wide range of configurations' more effectively than random sampling.
Authors: The manuscript details these in the approach section: the search uses a genetic algorithm with an objective function that maximizes a weighted combination of failure rate and coverage, terminating after a fixed number of generations or convergence; the renderer parameter space covers variables such as lighting conditions, object placements, camera angles, and passenger positions; scene generation employs a physics-based renderer to produce synthetic in-car images. We will include a brief overview of the algorithm, objective, and parameter space in the abstract to support the claims. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript describes an empirical search-based testing framework (ISU-Test) that generates synthetic scenes via rendering and optimizes for failure detection in VLM QA/captioning tasks, then compares failure rate and coverage against random sampling. No equations, parameter-fitting steps presented as predictions, uniqueness theorems, or self-citation load-bearing arguments appear. The reported multipliers (10x failure rate, 3.6x coverage) are direct empirical outcomes of the described procedure on the chosen oracles and renderer; they do not reduce to the inputs by construction. The paper is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pioneering in-cabin monitoring: Unmasking the power of 2d and 3d cameras through sensor fusion,
F. Diederichs and F. IOSB, “Pioneering in-cabin monitoring: Unmasking the power of 2d and 3d cameras through sensor fusion, ” Fraunhofer Institute of Optronics, System Technologies and Image Exploitation (IOSB), Tech. Rep., — 2025, white Paper. [Online]. Available: https://www.iosb.fraunhofer.de/content/ dam/iosb/iosbtest/documents/kompetenzen/bildauswert...
2025
-
[2]
In-cabin monitoring system for autonomous vehicles,
A. Mishra, S. Lee, D. Kim, and S. Kim, “In-cabin monitoring system for autonomous vehicles, ”Sensors, vol. 22, no. 12, 2022. [Online]. Available: https://www.mdpi.com/1424-8220/22/12/4360
2022
-
[3]
Assessment protocol – assisted driving: Highways & interurban assist systems. technical bulletin sd 202 – driver monitoring test procedure,
E. N. C. A. P. E. NCAP), “Assessment protocol – assisted driving: Highways & interurban assist systems. technical bulletin sd 202 – driver monitoring test procedure, ” Euro NCAP, Tech. Rep., Mar. 2025, implementation January
2025
-
[4]
Available: https://www.euroncap.com/media/85831/euro-ncap- protocol-assisted-driving-v10.pdf
[Online]. Available: https://www.euroncap.com/media/85831/euro-ncap- protocol-assisted-driving-v10.pdf
-
[5]
Regulation (eu) 2019/2144 on type-approval requirements for motor vehicles,
European Parliament and Council, “Regulation (eu) 2019/2144 on type-approval requirements for motor vehicles, ” 2019, official Journal of the European Union
2019
-
[6]
The european new car assessment programme,
Euro NCAP, “The european new car assessment programme, ” https://www. euroncap.com/en, 2025, accessed: 2025-10-26
2025
-
[7]
Sviro: Synthetic vehicle interior rear seat occupancy
S. D. D. Cruz, O. Wasenm ¨uller, H.-P. Beise, T. Stifter, and D. Stricker, “Sviro: Synthetic vehicle interior rear seat occupancy. ” TIB, dec 2024. [Online]. Available: https://service.tib.eu/ldmservice/dataset/sviro--synthetic- vehicle-interior-rear-seat-occupancy
2024
-
[8]
Expressive body capture: 3D hands, face, and body from a single image,
G. Pavlakos, V. Choutas, N. Ghorbani, T. Bolkart, A. A. A. Osman, D. Tzionas, and M. J. Black, “Expressive body capture: 3D hands, face, and body from a single image, ” inProceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 10 975–10 985
2019
-
[9]
STELLAR: A search-based testing framework for large language model applications,
L. Sorokin, I. Vasilev, K. E. Friedl, and A. Stocco, “STELLAR: A search-based testing framework for large language model applications, ” inProceedings of the 33rd IEEE International Conference on Software Analysis, Evolution and Reengineering. IEEE, 2026
2026
-
[10]
[Online]
Blender Foundation,Shrinkwrap Modifier, Blender Foundation, 2023, blender 3.6 Manual, accessed 2026-04-23. [Online]. Available: https://docs.blender.org/ manual/id/3.6/modeling/modifiers/deform/shrinkwrap.html
2023
-
[11]
Bleu: a method for automatic evaluation of machine translation,
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation, ” inProceedings of the 40th Annual Meeting on Association for Computational Linguistics, ser. ACL ’02. USA: Association for Computational Linguistics, 2002, p. 311–318
2002
-
[12]
Meteor: an automatic metric for mt evaluation with high levels of correlation with human judgments,
A. Lavie and A. Agarwal, “Meteor: an automatic metric for mt evaluation with high levels of correlation with human judgments, ” inProceedings of the Second Workshop on Statistical Machine Translation, ser. StatMT ’07. USA: Association for Computational Linguistics, 2007, p. 228–231
2007
-
[13]
BERTScore: Evaluating Text Generation with BERT
T. Zhang, V. Kishore, F. Wu, K. Q. Weinberger, and Y. Artzi, “Bertscore: Evaluating text generation with bert, ”arXiv preprint arXiv:1904.09675, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[14]
Error detecting and error correcting codes,
R. W. Hamming, “Error detecting and error correcting codes, ”Bell System Techni- cal Journal, vol. 29, no. 2, pp. 147–160, 1950
1950
-
[15]
Testing of deep reinforcement learning agents with surrogate models,
M. Biagiola and P. Tonella, “Testing of deep reinforcement learning agents with surrogate models, ”ACM Trans. Softw. Eng. Methodol., vol. 33, no. 3, 2024
2024
-
[16]
Test set diameter: Quantifying the diversity of sets of test cases,
R. Feldt, S. Poulding, D. Clark, and S. Yoo, “Test set diameter: Quantifying the diversity of sets of test cases, ” in2016 IEEE International Conference on Software Testing, Verification and Validation (ICST), 2016
2016
-
[17]
Replication package,
Anonymous, “Replication package, ” https://figshare.com/s/ cb5b0eae0411e54b1bbd
-
[18]
Drive&act: A multi-modal dataset for fine-grained driver behavior recognition in autonomous vehicles,
M. Martin, A. Roitberg, M. Haurilet, M. Horne, S. Reiß, M. Voit, and R. Stiefelhagen, “Drive&act: A multi-modal dataset for fine-grained driver behavior recognition in autonomous vehicles, ” in2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 2801–2810
2019
-
[19]
Deep Visual-Semantic Alignments for Generating Image Descriptions
A. Karpathy and L. Fei-Fei, “Deep visual-semantic alignments for generating image descriptions, ” 2015. [Online]. Available: https://arxiv.org/abs/1412.2306
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[20]
Show and Tell: A Neural Image Caption Generator
O. Vinyals, A. Toshev, S. Bengio, and D. Erhan, “Show and tell: A neural image caption generator, ” 2015. [Online]. Available: https://arxiv.org/abs/1411.4555
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[21]
VQA: Visual Question Answering
A. Agrawal, J. Lu, S. Antol, M. Mitchell, C. L. Zitnick, D. Batra, and D. Parikh, “Vqa: Visual question answering, ” 2016. [Online]. Available: https://arxiv.org/abs/1505.00468
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[22]
Automatic Description Generation from Images: A Survey of Models, Datasets, and Evaluation Measures
R. Bernardi, R. Cakici, D. Elliott, A. Erdem, E. Erdem, N. Ikizler-Cinbis, F. Keller, A. Muscat, and B. Plank, “Automatic description generation from images: A survey of models, datasets, and evaluation measures, ” 2017. [Online]. Available: https://arxiv.org/abs/1601.03896
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
CIDEr: Consensus-based Image Description Evaluation
R. Vedantam, C. L. Zitnick, and D. Parikh, “Cider: Consensus-based image description evaluation, ” 2015. [Online]. Available: https://arxiv.org/abs/1411.5726
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[24]
Re-evaluating Automatic Metrics for Image Captioning
M. Kilickaya, A. Erdem, N. Ikizler-Cinbis, and E. Erdem, “Re-evaluating automatic metrics for image captioning, ” 2016. [Online]. Available: https: //arxiv.org/abs/1612.07600
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[25]
Individual comparisons by ranking methods,
F. Wilcoxon, “Individual comparisons by ranking methods, ”Biometrics Bulletin, vol. 1, no. 6, 1945
1945
-
[26]
A critique and improvement of the
A. Vargha and H. D. Delaney, “A critique and improvement of the "cl" common language effect size statistics of mcgraw and wong, ”Journal of Educational and Behavioral Statistics, vol. 25, no. 2, pp. 101–132, 2000. [Online]. Available: http://www.jstor.org/stable/1165329
-
[27]
Image style transfer using convolutional neural networks,
L. A. Gatys, A. S. Ecker, and M. Bethge, “Image style transfer using convolutional neural networks, ”Journal of Vision, vol. 16, no. 12, p. 326, 2016
2016
-
[28]
Assessing quality metrics for neural reality gap input mitigation in autonomous driving testing,
S. C. Lambertenghi and A. Stocco, “Assessing quality metrics for neural reality gap input mitigation in autonomous driving testing, ” inProceedings of 17th IEEE International Conference on Software Testing, Verification and Validation, ser. ICST ’24, 2024
2024
-
[29]
Nano banana ai image generator,
Nanobana, “Nano banana ai image generator, ” https://www.nanobana.net/, 2026, aI-based image generation and editing platform
2026
-
[30]
Nvidia cosmos: World foundation models for physical ai,
NVIDIA Corporation, “Nvidia cosmos: World foundation models for physical ai, ” https://www.nvidia.com/en-us/ai/cosmos/, 2026, open platform with world foundation models and data processing for robotics, autonomous systems, and physical-AI research
2026
-
[31]
Efficient domain augmentation for autonomous driving testing using diffusion models,
L. Baresi, D. Y. Xian Hu, A. Stocco, and P. Tonella, “Efficient domain augmentation for autonomous driving testing using diffusion models, ” in2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE), 2025, pp. 398–410
2025
-
[32]
P. Alimisis, I. Mademlis, P. Radoglou-Grammatikis, P. Sarigiannidis, and G. T. Papadopoulos, “Advances in diffusion models for image data augmentation: A review of methods, models, evaluation metrics and future research directions, ”Artificial Intelligence Review, vol. 58, p. 112, 2025. [Online]. Available: https://doi.org/10.1007/s10462-025-11116-x
-
[33]
Ticam: A time-of-flight in-car cabin monitoring dataset,
J. S. Katrolia, A. El-Sherif, H. Feld, B. Mirbach, J. R. Rambach, and D. Stricker, “Ticam: A time-of-flight in-car cabin monitoring dataset, ” in32nd British Machine Vision Conference 2021, BMVC 2021, Online, November 22-25,
2021
-
[34]
BMVA Press, 2021, p. 277. [Online]. Available: https://www.bmvc2021- virtualconference.com/assets/papers/0701.pdf
2021
-
[35]
Search-based dnn testing and retraining with gan-enhanced simulations,
M. O. Attaoui, F. Pastore, and L. C. Briand, “Search-based dnn testing and retraining with gan-enhanced simulations, ”IEEE Trans. Softw. Eng., vol. 51, no. 4, p. 1086–1103, Apr. 2025. [Online]. Available: https://doi.org/10.1109/TSE.2025. 3540549
-
[36]
F. U. Haq, D. Shin, L. C. Briand, T. Stifter, and J. Wang, “Automatic test suite generation for key-points detection dnns using many-objective search (experience paper), ” inProceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis, ser. ISSTA ’21. ACM, Jul. 2021, p. 91–102. [Online]. Available: http://dx.doi.org/10.1145...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.