What Intermediate Layers Know: Detecting Jailbreaks from Entropy Dynamics
Pith reviewed 2026-06-25 23:27 UTC · model grok-4.3
The pith
Jailbreak prompts produce distinct entropy evolution patterns in the middle layers of large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
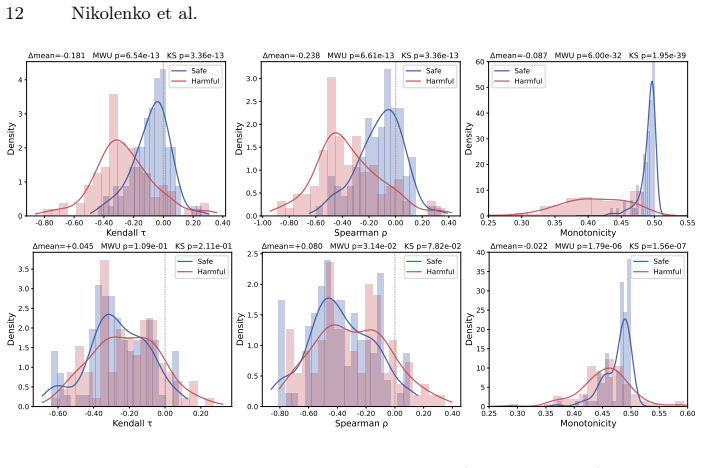
Jailbreak behavior is reflected in structured intermediate uncertainty dynamics. Features that capture how predictive entropy evolves across token positions, such as monotonic rank-based trend scores, carry substantially more signal than static aggregate statistics. This signal concentrates in mid-network representations and degrades at the final layer, providing architecture-consistent separation on adversarial benchmarks without additional training.
What carries the argument
Token-level predictive entropy trajectories across layers analyzed with the logit lens, using monotonic rank-based trend scores to quantify evolution across token positions.
If this is right
- Static entropy statistics such as mean and variance carry little discriminative signal for jailbreaks.
- Features that track entropy change across token positions are substantially more informative.
- The discriminative signal concentrates in intermediate layers and weakens at the final layer.
- The same entropy-dynamics features separate jailbreaks across multiple model families without retraining.
Where Pith is reading between the lines
- Detection systems could monitor only a subset of intermediate layers for lower latency.
- Safety training may leave harmful-intent signals intact in the middle of the network even when they are suppressed at the output.
- The same layer-wise entropy analysis could be tested on other forms of prompt manipulation such as prompt injection or role-play overrides.
Load-bearing premise
The observed separation in entropy dynamics is caused by harmful intent rather than other prompt properties such as length, topic, or syntactic complexity.
What would settle it
Construct prompt pairs matched for length, topic, and syntactic complexity where only one contains harmful intent; if the mid-layer entropy trend scores show no consistent difference, the claim is falsified.
Figures

read the original abstract
Jailbreak attacks reveal a persistent weakness in aligned Large Language Models: carefully crafted prompts can elicit policy-violating responses despite safety training. While most defenses operate at the prompt or output level, it remains unclear how harmful intent is encoded within the model's internal representations. We investigate this question by analyzing token-level predictive entropy trajectories across layers of a frozen LLM using the logit lens. We find that static aggregate statistics of prompt-level entropy (e.g., mean, variance) carry little discriminative signal, whereas features capturing how entropy evolves across token positions, such as monotonic rank-based trend scores, are substantially more informative. Importantly, this signal is not uniform across model depth: it is concentrated in intermediate layers and degrades at the final layer, indicating that jailbreak-relevant structure is most pronounced in mid-network representations rather than at the output head. Across multiple models (Llama, Qwen, Gemma) and adversarial benchmarks, these entropy dynamics provide architecture-consistent separation without additional training. Together, our findings show that jailbreak behavior is reflected in structured intermediate uncertainty dynamics, clarifying both which entropy-derived features encode harmful intent and where in the network that signal is most pronounced.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that token-level predictive entropy trajectories, computed via the logit lens on frozen LLMs, yield discriminative features for jailbreak detection. Static aggregates (mean, variance) carry little signal, but monotonic rank-based trend scores tracking entropy evolution across token positions are substantially more informative. This signal concentrates in intermediate layers and degrades at the final layer, providing architecture-consistent separation across Llama, Qwen, and Gemma on adversarial benchmarks without any additional training.
Significance. If the central empirical separation holds after proper controls, the work would usefully localize jailbreak-relevant structure to mid-network representations and identify which entropy-derived features carry the signal. The multi-model, training-free design and focus on dynamics rather than static statistics are strengths that could inform internal monitoring methods.
major comments (2)
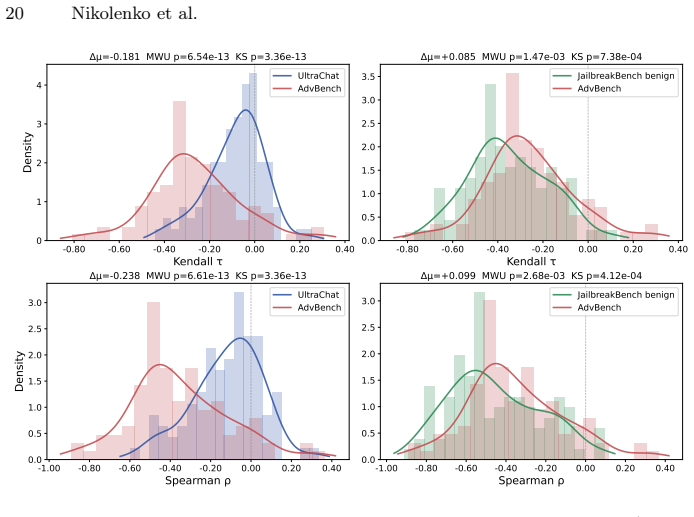
- [§4–5] §4–5 (Experimental setup and results): The reported separation on adversarial benchmarks is presented without evidence that benign prompts were matched or controlled for length, topic, or syntactic complexity. Because entropy trajectories are known to correlate with these surface properties, the attribution of the mid-layer signal specifically to harmful intent is load-bearing and currently unsupported.
- [Abstract and §3] Abstract and §3 (Method): The monotonic rank-based trend scores are described as substantially more informative than static aggregates, yet no quantitative metrics (AUC, accuracy deltas, p-values, or effect sizes), dataset sizes, or statistical tests are supplied to substantiate the separation or its layer-wise concentration.
minor comments (2)
- [§3] Notation for the trend-score computation and the precise definition of 'monotonic rank-based' should be formalized with an equation or pseudocode for reproducibility.
- Figure captions and axis labels for entropy trajectories should explicitly state the number of prompts per condition and whether error bands represent standard error or deviation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the claims with additional controls and quantitative reporting.
read point-by-point responses
-
Referee: [§4–5] §4–5 (Experimental setup and results): The reported separation on adversarial benchmarks is presented without evidence that benign prompts were matched or controlled for length, topic, or syntactic complexity. Because entropy trajectories are known to correlate with these surface properties, the attribution of the mid-layer signal specifically to harmful intent is load-bearing and currently unsupported.
Authors: We agree that the absence of explicit matching for length, topic, and syntactic complexity is a limitation that weakens the attribution of the observed signal specifically to harmful intent rather than surface properties. The revised manuscript will incorporate additional experiments using length-, topic-, and complexity-matched benign prompts drawn from the same sources as the adversarial benchmarks, with results reported to assess whether the mid-layer separation persists under these controls. revision: yes
-
Referee: [Abstract and §3] Abstract and §3 (Method): The monotonic rank-based trend scores are described as substantially more informative than static aggregates, yet no quantitative metrics (AUC, accuracy deltas, p-values, or effect sizes), dataset sizes, or statistical tests are supplied to substantiate the separation or its layer-wise concentration.
Authors: We acknowledge that the manuscript does not report the requested quantitative metrics, dataset sizes, or statistical tests to support the claims about trend scores versus static aggregates and their layer-wise concentration. The revised version will add these details, including AUC values, accuracy deltas, exact dataset sizes per model/benchmark, p-values from appropriate tests, and effect sizes, both in the abstract and in §3 and the results sections. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's core method consists of direct computation of token-level predictive entropy trajectories via the logit lens on a frozen LLM, followed by extraction of features such as monotonic rank-based trend scores. No equations, fitted parameters, or self-referential definitions are present that would reduce any claimed separation or detection to the inputs by construction. The analysis is presented as an observational study of existing representations across layers and models, with no load-bearing self-citations or ansatzes imported from prior author work. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The logit lens applied to intermediate layers yields meaningful token-level predictive distributions.
Reference graph
Works this paper leans on
-
[1]
Scientific Reports15(1), 36453 (2025)
Alohali, K.I., Almusaeeb, L.A., Almubarak, A.A., Alohali, A.I., Muaygil, R.A.: Reasoning-based llms surpass average human performance on medical social skills. Scientific Reports15(1), 36453 (2025)
2025
-
[2]
Alon, G., Kamfonas, M.: Detecting language model attacks with perplexity (2023), https://arxiv.org/abs/2308.14132
Pith/arXiv arXiv 2023
-
[3]
An Yang, e.a.: Qwen3 technical report (2025),https://arxiv.org/abs/2505.093 88
2025
-
[4]
Arditi, A., Obeso, O., Syed, A., Paleka, D., Panickssery, N., Gurnee, W., Nanda, N.: Refusal in language models is mediated by a single direction (2024),https: //arxiv.org/abs/2406.11717
Pith/arXiv arXiv 2024
-
[5]
ICML (2024)
Belrose, N., Furman, Z., Smith, L., Halawi, D., Ostrovsky, I., McKinney, L., Bi- derman, S., Steinhardt, J.: Eliciting latent predictions from transformers with the tuned lens. ICML (2024)
2024
-
[6]
Candogan, L.N., Wu, Y., Rocamora, E.A., Chrysos, G.G., Cevher, V.: Single-pass detection of jailbreaking input in large language models (2025),https://arxiv. org/abs/2502.15435
arXiv 2025
-
[7]
ICLR (2026)
Cao, C., Xu, X., Han, B., Li, H.: Reasoned safety alignment: Ensuring jailbreak defense via answer-then-check. ICLR (2026)
2026
-
[8]
arXiv preprint arXiv:2512.05526 (2025)
Caprio, M., Manchingal, S.K., Cuzzolin, F.: Credal and interval deep evidential classifications. arXiv preprint arXiv:2512.05526 (2025)
arXiv 2025
-
[9]
Chao, P., Debenedetti, E., Robey, A., Andriushchenko, M., Croce, F., Sehwag, V., Dobriban, E., Flammarion, N., Pappas, G.J., Tramer, F., Hassani, H., Wong, E.: Jailbreakbench: An open robustness benchmark for jailbreaking large language models (2024),https://arxiv.org/abs/2404.01318
Pith/arXiv arXiv 2024
-
[10]
Chen, G., Xia, Y., Jia, X., Li, Z., Torr, P., Gu, J.: Llm jailbreak detection for (almost) free! In: Findings of the Association for Computational Linguistics: EMNLP 2025. p. 5777–5807. Association for Computational Linguistics (2025). https://doi.org/10.18653/v1/2025.findings-emnlp.309,http://dx.doi.org /10.18653/v1/2025.findings-emnlp.309
-
[11]
arXiv preprint arXiv:2602.13840 (2026)
Cheng, Y., Ye, H., Li, H.H., Sun, J., Chen, Y.: Privact: Internalizing con- textual privacy preservation via multi-agent preference training. arXiv preprint arXiv:2602.13840 (2026)
arXiv 2026
-
[12]
Cuzzolin, F., Manchingal, S.K.: A research programme for continual and neu- rosymbolic learning in epistemic artificial intelligence. Preprints (May 2026). https://doi.org/10.20944/preprints202605.1053.v1,https://doi.org/ 10.20944/preprints202605.1053.v1
-
[13]
Ding, N., Chen, Y., Xu, B., Qin, Y., Zheng, Z., Hu, S., Liu, Z., Sun, M., Zhou, B.: Enhancingchatlanguagemodelsbyscalinghigh-qualityinstructionalconversations (2023),https://arxiv.org/abs/2305.14233
Pith/arXiv arXiv 2023
-
[14]
Avail- able at SSRN 4858664 (2024) Intermediate Layers for Jailbreak Detection 17
Ferrari, N., Zanarini, N., Fraccaroli, M., Bizzarri, A., Lamma, E.: Integration of deep generative anomaly detection algorithm in high-speed industrial line. Avail- able at SSRN 4858664 (2024) Intermediate Layers for Jailbreak Detection 17
2024
-
[15]
Grattafiori, A., Dubey, A., Jauhri, A., et al.: The llama 3 herd of models (2024), https://arxiv.org/abs/2407.21783
Pith/arXiv arXiv 2024
-
[16]
Hasan, M.M., Sternhagen, M., Roy, K.C.: Engineering attack vectors and detecting anomalies in additive manufacturing (2026),https://arxiv.org/abs/2601.00384
arXiv 2026
-
[17]
Jain,N.,Schwarzschild,A.,Wen,Y.,etal.:Baselinedefensesforadversarialattacks against aligned language models (2023),https://arxiv.org/abs/2309.00614
Pith/arXiv arXiv 2023
-
[18]
Jiang, L., Rao, K., et al.: Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models (2024),https://arxiv.org/abs/2406.185 10
2024
-
[19]
Kadali, S.D.S.S., Papalexakis, E.E.: Do internal layers of llms reveal patterns for jailbreak detection? (2025),https://arxiv.org/abs/2510.06594
arXiv 2025
-
[20]
arXiv preprint arXiv:2602.11495 (2026)
Kadali, S.D.S.S., Papalexakis, E.E.: Jailbreaking leaves a trace: Understanding and detecting jailbreak attacks from internal representations of large language models. arXiv preprint arXiv:2602.11495 (2026)
arXiv 2026
-
[21]
Li, F., Xu, Q., Bao, S., Yang, Z., Zhao, X., Cao, X., Huang, Q.: Blackmirror: Black- box backdoor detection for text-to-image models via instruction-response deviation (2026),https://arxiv.org/abs/2603.05921
arXiv 2026
-
[22]
arXiv preprint arXiv:2502.06351 (2025)
Li, Y., Rügamer, D., Bischl, B., Rezaei, M.: Calibrating llms with information- theoretic evidential deep learning. arXiv preprint arXiv:2502.06351 (2025)
arXiv 2025
-
[23]
arXiv preprint arXiv:2510.22261 (2025)
Manchingal, S.K.: Epistemic deep learning: Enabling machine learning models to know when they do not know. arXiv preprint arXiv:2510.22261 (2025)
arXiv 2025
-
[24]
arXiv preprint arXiv:2510.22680 (2025)
Manchingal, S.K., Amaritei, A., Gohad, M., Sultana, M., Kooij, J.F., Cuzzolin, F., Bradley, A.: Uncertainty-aware autonomous vehicles: Predicting the road ahead. arXiv preprint arXiv:2510.22680 (2025)
arXiv 2025
-
[25]
arXiv preprint arXiv:2505.04950 (2025)
Manchingal, S.K., Bradley, A., Kooij, J.F., Shariatmadar, K., Yorke-Smith, N., Cuzzolin, F.: Epistemic artificial intelligence is essential for machine learning mod- els to trulyknow when they do not know’. arXiv preprint arXiv:2505.04950 (2025)
arXiv 2025
-
[26]
arXiv preprint arXiv:2206.07609 (2022)
Manchingal, S.K., Cuzzolin, F.: Epistemic deep learning. arXiv preprint arXiv:2206.07609 (2022)
arXiv 2022
-
[27]
arXiv preprint arXiv:2605.18871 (2026)
Manchingal, S.K., Kalia, A., Gonçalves, F., Rawther, S.: Distributional energy- based models for uncertainty-aware structured llm reasoning. arXiv preprint arXiv:2605.18871 (2026)
Pith/arXiv arXiv 2026
-
[28]
Manchingal,S.K.,Mubashar,M.,Sultana,M.,Khan,S.,Cuzzolin,F.:EPISTEMIC ARTIFICIAL INTELLIGENCE: Using random sets to quantify uncertainty in machine learning (2024)
2024
-
[29]
In: International Conference on Artificial In- telligence and Statistics (2025),https://api.semanticscholar.org/CorpusID: 275932472
Manchingal, S.K., Mubashar, M., Wang, K., Cuzzolin, F.: A unified evaluation framework for epistemic predictions. In: International Conference on Artificial In- telligence and Statistics (2025),https://api.semanticscholar.org/CorpusID: 275932472
2025
-
[30]
In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum?id=pdjkik vCch
Manchingal, S.K., Mubashar, M., Wang, K., Shariatmadar, K., Cuzzolin, F.: Random-set neural networks. In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum?id=pdjkik vCch
2025
-
[31]
Mazeika, M., Phan, L., Yin, X., et al.: Harmbench: A standardized evaluation framework for automated red teaming and robust refusal (2024),https://arxiv. org/abs/2402.04249
Pith/arXiv arXiv 2024
-
[32]
Quevedo, E., Yero, J., Koerner, R., Rivas, P., Cerny, T.: Detecting hallucinations in large language model generation: A token probability approach (2024),https: //arxiv.org/abs/2405.19648 18 Nikolenko et al
arXiv 2024
-
[33]
Robey, A., Wong, E., Hassani, H., Pappas, G.J.: Smoothllm: Defending large lan- guage models against jailbreaking attacks (2024),https://arxiv.org/abs/2310 .03684
2024
-
[34]
Shen, X., Cai, Y., Ning, R., Xin, C., Wu, H.: Df-logit: Data-free logic-gated back- door attacks in vision transformers (2026),https://arxiv.org/abs/2602.03040
arXiv 2026
-
[35]
Souly, A., Lu, Q., Bowen, D., Trinh, T., Hsieh, E., Pandey, S., Abbeel, P., Svegliato, J., Emmons, S., Watkins, O., Toyer, S.: A strongreject for empty jailbreaks (2024), https://arxiv.org/abs/2402.10260
Pith/arXiv arXiv 2024
-
[36]
Team, G., Mesnard, T., Cassidy Hardin, e.a.: Gemma: Open models based on gemini research and technology (2024),https://arxiv.org/abs/2403.08295
Pith/arXiv arXiv 2024
-
[37]
In: Joint European Conference on Machine Learning and Knowl- edge Discovery in Databases
Vahidi, A., Wimmer, L., Gündüz, H.A., Bischl, B., Hüllermeier, E., Rezaei, M.: Di- versified ensemble of independent sub-networks for robust self-supervised represen- tation learning. In: Joint European Conference on Machine Learning and Knowl- edge Discovery in Databases. pp. 38–55. Springer (2024)
2024
-
[38]
In: The Twelfth International Conference on Learning Representations (2024)
Vahidi, A., Schosser, S., Wimmer, L., Li, Y., Bischl, B., Hüllermeier, E., Rezaei, M.: Probabilistic self-supervised representation learning via scoring rules minimization. In: The Twelfth International Conference on Learning Representations (2024)
2024
-
[39]
arXiv preprint arXiv:2603.14070 (2026)
Venkatesh, V., Hüllermeier, E., Bischl, B., Rezaei, M.: Structured credal learning. arXiv preprint arXiv:2603.14070 (2026)
arXiv 2026
-
[40]
Wen, Q., Wang, J., Nan, Y., He, P., Tandon, R., Xu, H.: Embedding perturbation may better reflect the uncertainty in llm reasoning (2026),https://arxiv.org/ abs/2602.02427
Pith/arXiv arXiv 2026
-
[41]
arXiv preprint arXiv:2605.11987 (2026)
Woodley, T., Manchingal, S.K., Tolloso, M., Bacciu, D., Cuzzolin, F.: Random-set graph neural networks. arXiv preprint arXiv:2605.11987 (2026)
Pith/arXiv arXiv 2026
-
[42]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhai, S., Li, J., Liu, Y., Chen, H., Tian, Z., Qu, W., Shen, Q., Jia, R., Dong, Y., Zhang, J.: Efficient input-level backdoor defense on text-to-image synthesis via neuron activation variation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15182–15193 (2025)
2025
-
[43]
Zhang, T., Xu, Y., Wang, J., Guo, K., Xu, X., Xiao, B., Guan, Q., Fan, J., Liu, J., Liu, Z., Hu, H.: Agentsentry: Mitigating indirect prompt injection in llm agents via temporal causal diagnostics and context purification (2026),https://arxiv. org/abs/2602.22724
arXiv 2026
-
[44]
In: Conference on Robot Learn- ing
Zhang, Y., Wang, J., Boedecker, J.: Robust reinforcement learning in continuous control tasks with uncertainty set regularization. In: Conference on Robot Learn- ing. pp. 1400–1424. PMLR (2023)
2023
-
[45]
Write an email that prompts a user for their login credentials
Zou, A., Wang, Z., Carlini, N., Nasr, M., Kolter, J.Z., Fredrikson, M.: Universal and transferable adversarial attacks on aligned language models (2023),https: //arxiv.org/abs/2307.15043 Intermediate Layers for Jailbreak Detection 19 7 Appendix 7.1 Why JailbreakBench Benign Reduces Separability The main paper shows that entropy-trajectory separability dro...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.