UniT: Unified Geometry Learning with Group Autoregressive Transformer
Pith reviewed 2026-05-21 04:48 UTC · model grok-4.3
The pith
A Group Autoregressive Transformer unifies online and offline 3D geometry perception in one model by processing observation groups as autoregressive units.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
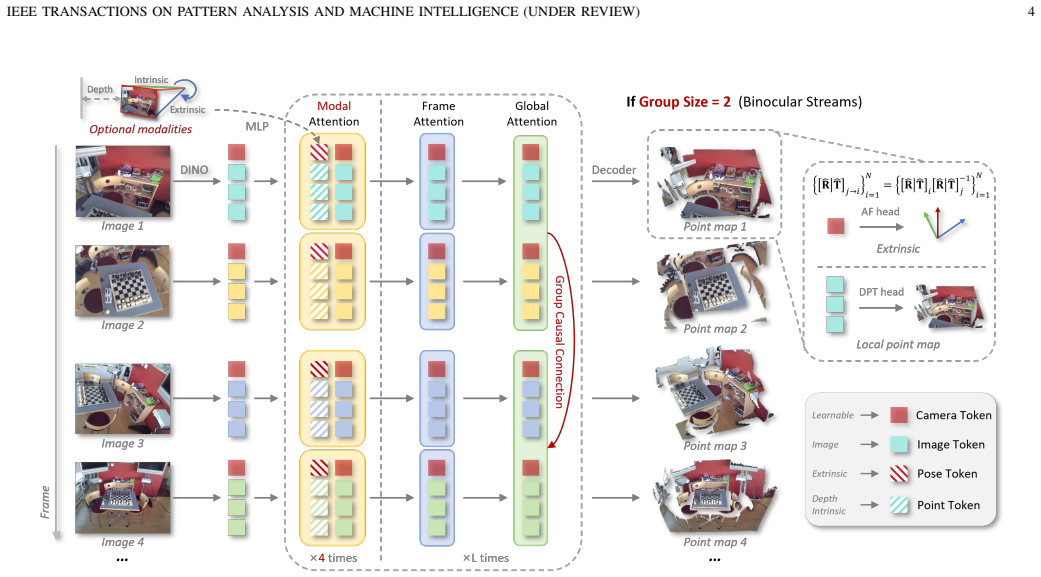
UniT reformulates online perception, offline reconstruction, multi-modal integration, long-horizon scalability, and metric-scale estimation inside one framework. Groups of sensor observations serve as the autoregressive units; point maps are predicted in an anchor-free, scale-adaptive manner. Online mode runs multiple steps on single-frame groups while offline mode consumes a multi-frame group in one pass. A queue-style KV cache keeps memory bounded by discarding outdated early-frame dependencies, and a scale-adaptive geometry loss couples relative constraints with a partial absolute scale term to improve metric generalization.
What carries the argument
The Group Autoregressive Transformer, which treats groups of observations as the basic autoregressive unit to predict point maps while allowing group size to switch between online and offline modes.
If this is right
- Online perception runs over multiple autoregressive steps using single-frame groups.
- Offline reconstruction consumes an entire multi-frame group in one forward pass.
- Long sequences remain feasible because the KV cache discards early-frame memory on the fly.
- Metric-scale estimates improve across scenes through the scale-adaptive loss that mixes relative and partial absolute terms.
- Auxiliary modalities integrate via a dedicated modal attention module without changing the core pipeline.
Where Pith is reading between the lines
- A single trained network could replace separate real-time and batch pipelines in robotics or mapping applications.
- The same grouping idea might extend to other dense prediction tasks such as optical flow or semantic segmentation.
- Further tests on sequences longer than the reported benchmarks would expose any hidden limits of the cache eviction rule.
- If the scale-adaptive loss generalizes, similar partial-absolute terms could be added to other geometry networks to reduce the need for per-scene calibration.
Load-bearing premise
That varying group size at inference time together with the queue-style KV cache and scale-adaptive loss will keep accuracy and scalability intact across all seven tasks without task-specific retraining or post-processing.
What would settle it
Measure reconstruction accuracy on a long outdoor sequence when the model is forced to alternate between single-frame and multi-frame groups without any fine-tuning; a clear drop relative to separate task-specific baselines would falsify the unification claim.
Figures







read the original abstract
Recent feed-forward models have significantly advanced geometry perception for inferring dense 3D structure from sensor observations. However, its essential capabilities remain fragmented across multiple incompatible paradigms, including online perception, offline reconstruction, multi-modal integration, long-horizon scalability, and metric-scale estimation. We present UniT, a unified model built upon a novel Group Autoregressive Transformer, which reformulates these seemingly disparate capabilities within a single framework. The key idea is to treat groups of sensor observations as the basic autoregressive units and predict the corresponding point maps in an anchor-free and scale-adaptive manner. More specifically, diverse view configurations in both online and offline settings are naturally unified within a single group autoregression process. By varying the group size, online mode operates over multiple autoregressive steps with single-frame groups, whereas offline mode aggregates a multi-frame group in a single forward pass. Meanwhile, a queue-style KV caching mechanism ensures bounded autoregressive memory over long horizons. This is enabled by reducing long-range dependencies on early frames through anchor-free relational modeling, thereby allowing outdated memory to be discarded on the fly. To improve metric-scale generalization across scenes, a scale-adaptive geometry loss is further introduced within this framework. It couples relative geometric constraints with a partial absolute scale term, implicitly regularizing global scale and inducing a progressive transition from scale-invariant geometry to metric-scale solutions. Together with a dedicated modal attention module for integrating auxiliary modalities, UniT achieves state-of-the-art performance in unified geometry perception, as validated on ten benchmarks spanning seven representative tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UniT, a unified model for geometry perception tasks based on a novel Group Autoregressive Transformer. It reformulates online perception, offline reconstruction, multi-modal fusion, long-horizon scalability, and metric-scale estimation into a single framework by treating groups of sensor observations as autoregressive units and predicting anchor-free, scale-adaptive point maps. Online mode uses single-frame groups over multiple steps while offline aggregates multi-frame groups in one pass; a queue-style KV cache bounds memory by discarding early frames (enabled by reduced long-range dependencies via anchor-free modeling), and a scale-adaptive loss couples relative constraints with a partial absolute scale term. A modal attention module integrates auxiliary inputs. The model claims SOTA results across ten benchmarks spanning seven tasks.
Significance. If the empirical claims hold, the work would be significant for consolidating fragmented geometry perception paradigms into one architecture, potentially simplifying real-world deployment in robotics and AR where both online and offline operation are required. The anchor-free design and scale-adaptive loss target practical challenges in long-horizon inference and metric generalization; the provision of a single model supporting variable group sizes without task-specific retraining would represent a meaningful advance over prior specialized feed-forward approaches.
major comments (2)
- [Abstract / §3] Abstract and §3 (Group Autoregressive Transformer description): The central unification claim for long-horizon online inference rests on the queue-style KV cache safely evicting early-frame entries without accuracy loss, justified by anchor-free relational modeling reducing long-range dependencies. However, no ablation is presented that quantifies attention scores to early versus recent frames or directly compares full-cache versus queue-eviction performance on extended sequences across the seven tasks. This is load-bearing for the scalability and online-mode claims; residual coupling would require task-specific fixes that undermine the single-framework assertion.
- [§4 / scale-adaptive loss] §4 (Experiments) and scale-adaptive loss definition: The scale-adaptive geometry loss is described as coupling relative constraints with a partial absolute scale term to induce progressive transition to metric-scale solutions, yet the exact weighting schedule, the definition of the partial absolute term, and its interaction with the group autoregression process lack sufficient detail or sensitivity analysis. This affects the metric-scale generalization claim across scenes and benchmarks.
minor comments (2)
- [Abstract] The abstract asserts SOTA performance on ten benchmarks but does not include any quantitative numbers, error bars, or comparison tables; these should be summarized in the abstract or a dedicated results overview for immediate verifiability.
- [§3] Notation for the modal attention module and the precise formulation of the group autoregressive process (e.g., how group size is varied at inference) could be clarified with a compact equation or pseudocode to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important aspects of our claims on long-horizon scalability and the scale-adaptive loss. We address each point below and have revised the manuscript to incorporate additional details and experiments.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (Group Autoregressive Transformer description): The central unification claim for long-horizon online inference rests on the queue-style KV cache safely evicting early-frame entries without accuracy loss, justified by anchor-free relational modeling reducing long-range dependencies. However, no ablation is presented that quantifies attention scores to early versus recent frames or directly compares full-cache versus queue-eviction performance on extended sequences across the seven tasks. This is load-bearing for the scalability and online-mode claims; residual coupling would require task-specific fixes that undermine the single-framework assertion.
Authors: We agree that direct empirical validation strengthens the long-horizon claims. Section 3 explains that anchor-free point map prediction focuses on local relational geometry, thereby attenuating long-range dependencies and permitting safe eviction of early frames via the queue-style KV cache. To address the request, the revised manuscript includes new ablations: (i) average attention scores to early versus recent frames across sequence lengths for representative tasks, and (ii) performance comparison of full-cache versus queue-eviction modes on extended sequences spanning the seven tasks. These results show negligible degradation upon eviction, supporting the unified framework without task-specific adjustments. revision: yes
-
Referee: [§4 / scale-adaptive loss] §4 (Experiments) and scale-adaptive loss definition: The scale-adaptive geometry loss is described as coupling relative constraints with a partial absolute scale term to induce progressive transition to metric-scale solutions, yet the exact weighting schedule, the definition of the partial absolute term, and its interaction with the group autoregression process lack sufficient detail or sensitivity analysis. This affects the metric-scale generalization claim across scenes and benchmarks.
Authors: We thank the referee for noting the need for greater precision. The original description in §4 states that the loss couples relative geometric constraints with a partial absolute scale term to induce progressive transition to metric-scale solutions. In the revision we have added: the exact mathematical definition of the partial absolute term, the weighting schedule (linear ramp from 0 to 1 over the first 50% of training epochs), and its per-group application within the autoregressive process. We also include a sensitivity study varying the absolute-term coefficient and reporting metric-scale errors across scenes and benchmarks, confirming improved generalization. revision: yes
Circularity Check
No significant circularity; derivation is self-contained architectural design
full rationale
The paper introduces UniT as a new Group Autoregressive Transformer architecture that unifies geometry perception tasks by treating sensor observation groups as autoregressive units, employing anchor-free relational modeling to enable queue-style KV caching, and adding a scale-adaptive loss that couples relative constraints with partial absolute scale. These are presented as explicit design choices and modeling decisions rather than derivations that reduce to fitted parameters, self-definitions, or prior self-citations. No equations or claims equate predictions to inputs by construction, and the unification across online/offline modes via group size variation is justified structurally without reducing to the same data fits. The central claims rest on the model's novel components and empirical validation across benchmarks, remaining independent of the input quantities.
Axiom & Free-Parameter Ledger
free parameters (2)
- group size
- partial absolute scale term weight
axioms (1)
- domain assumption Transformer attention and KV caching can be applied to geometric point-map prediction without breaking relational consistency across frames.
invented entities (2)
-
Group Autoregressive Transformer
no independent evidence
-
modal attention module
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
treat groups of sensor observations as the basic autoregressive units and predict the corresponding point maps in an anchor-free and scale-adaptive manner... queue-style KV caching mechanism ensures bounded autoregressive memory... reducing long-range dependencies on early frames through anchor-free relational modeling
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By varying the group size, online mode operates over multiple autoregressive steps with single-frame groups, whereas offline mode aggregates a multi-frame group in a single forward pass
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketiet al., “Openvla: An open- source vision-language-action model,”arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
An overview of augmented reality,
F. Arena, M. Collotta, G. Pau, and F. Termine, “An overview of augmented reality,”Computers, vol. 11, no. 2, p. 28, 2022
work page 2022
-
[3]
End-to-end autonomous driving: Challenges and frontiers,
L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger, and H. Li, “End-to-end autonomous driving: Challenges and frontiers,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[4]
Structure-from-motion revisited,
J. L. Sch ¨onberger and J.-M. Frahm, “Structure-from-motion revisited,” inConference on Computer Vision and Pattern Recognition (CVPR), 2016
work page 2016
-
[5]
Orb-slam3: An accurate open-source library for visual, visual– inertial, and multimap slam,
C. Campos, R. Elvira, J. J. G. Rodr ´ıguez, J. M. Montiel, and J. D. Tard´os, “Orb-slam3: An accurate open-source library for visual, visual– inertial, and multimap slam,”IEEE transactions on robotics, vol. 37, no. 6, pp. 1874–1890, 2021
work page 2021
-
[6]
Dust3r: Geometric 3d vision made easy,
S. Wang, V . Leroy, Y . Cabon, B. Chidlovskii, and J. Revaud, “Dust3r: Geometric 3d vision made easy,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 20 697–20 709
work page 2024
-
[7]
Streaming 4D Visual Geometry Transformer
D. Zhuo, W. Zheng, J. Guo, Y . Wu, J. Zhou, and J. Lu, “Streaming 4d visual geometry transformer,”arXiv preprint arXiv:2507.11539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Y . Wang, J. Zhou, H. Zhu, W. Chang, Y . Zhou, Z. Li, J. Chen, J. Pang, C. Shen, and T. He, “π 3: Permutation-equivariant visual geometry learning,”arXiv preprint arXiv:2507.13347, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Pow3r: Empowering unconstrained 3d reconstruction with camera and scene priors,
W. Jang, P. Weinzaepfel, V . Leroy, L. Agapito, and J. Revaud, “Pow3r: Empowering unconstrained 3d reconstruction with camera and scene priors,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 1071–1081
work page 2025
-
[10]
TTT3R: 3D Reconstruction as Test-Time Training
X. Chen, Y . Chen, Y . Xiu, A. Geiger, and A. Chen, “Ttt3r: 3d reconstruction as test-time training,”arXiv preprint arXiv:2509.26645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Depth anything 3: Recovering the visual space from any views,
H. Lin, S. Chen, J. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang, “Depth anything 3: Recovering the visual space from any views,” 2025. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE (UNDER REVIEW) 14
work page 2025
-
[12]
Continuous 3d perception model with persistent state,
Q. Wang, Y . Zhang, A. Holynski, A. A. Efros, and A. Kanazawa, “Continuous 3d perception model with persistent state,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 10 510–10 522
work page 2025
-
[13]
Vggt: Visual geometry grounded transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “Vggt: Visual geometry grounded transformer,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 5294– 5306
work page 2025
-
[14]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
N. Keetha, N. M ¨uller, J. Sch ¨onberger, L. Porzi, Y . Zhang, T. Fischer, A. Knapitsch, D. Zauss, E. Weber, N. Antuneset al., “Mapany- thing: Universal feed-forward metric 3d reconstruction,”arXiv preprint arXiv:2509.13414, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inPro- ceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186
work page 2019
-
[16]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu, and J. Dai, “Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[18]
Infinitevggt: Visual geometry grounded transformer for endless streams,
S. Yuan, Y . Yang, X. Yang, X. Zhang, Z. Zhao, L. Zhang, and Z. Zhang, “Infinitevggt: Visual geometry grounded transformer for endless streams,”arXiv preprint arXiv:2601.02281, 2026
-
[19]
Z. Wang and D. Xu, “Flashvggt: Efficient and scalable visual geome- try transformers with compressed descriptor attention,”arXiv preprint arXiv:2512.01540, 2025
-
[20]
FastVGGT: Training-Free Acceleration of Visual Geometry Transformer
Y . Shen, Z. Zhang, Y . Qu, X. Zheng, J. Ji, S. Zhang, and L. Cao, “Fastvggt: Training-free acceleration of visual geometry transformer,” arXiv preprint arXiv:2509.02560, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Towards robust monocular depth estimation: Mixing datasets for zero-shot cross- dataset transfer,
R. Ranftl, K. Lasinger, D. Hafner, K. Schindler, and V . Koltun, “Towards robust monocular depth estimation: Mixing datasets for zero-shot cross- dataset transfer,”IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 3, pp. 1623–1637, 2020
work page 2020
-
[22]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
R. Wang, S. Xu, Y . Dong, Y . Deng, J. Xiang, Z. Lv, G. Sun, X. Tong, and J. Yang, “Moge-2: Accurate monocular geometry with metric scale and sharp details,”arXiv preprint arXiv:2507.02546, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Unidepthv2: Universal monocular metric depth estimation made simpler,
L. Piccinelli, C. Sakaridis, Y .-H. Yang, M. Segu, S. Li, W. Abbeloos, and L. Van Gool, “Unidepthv2: Universal monocular metric depth estimation made simpler,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[24]
G2-monodepth: A general frame- work of generalized depth inference from monocular rgb+ x data,
H. Wang, M. Yang, and N. Zheng, “G2-monodepth: A general frame- work of generalized depth inference from monocular rgb+ x data,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 5, pp. 3753–3771, 2023
work page 2023
-
[25]
D. Nist ´er, O. Naroditsky, and J. Bergen, “Visual odometry,” inProceed- ings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2004. CVPR 2004., vol. 1. Ieee, 2004, pp. I–I
work page 2004
-
[26]
Depthcrafter: Generating consistent long depth sequences for open-world videos,
W. Hu, X. Gao, X. Li, S. Zhao, X. Cun, Y . Zhang, L. Quan, and Y . Shan, “Depthcrafter: Generating consistent long depth sequences for open-world videos,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 2005–2015
work page 2025
-
[27]
Depth map prediction from a single image using a multi-scale deep network,
D. Eigen, C. Puhrsch, and R. Fergus, “Depth map prediction from a single image using a multi-scale deep network,”Advances in neural information processing systems, vol. 27, 2014
work page 2014
-
[28]
Grounding image matching in 3d with mast3r,
V . Leroy, Y . Cabon, and J. Revaud, “Grounding image matching in 3d with mast3r,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 71–91
work page 2024
-
[29]
Mast3r-slam: Real- time dense slam with 3d reconstruction priors,
R. Murai, E. Dexheimer, and A. J. Davison, “Mast3r-slam: Real- time dense slam with 3d reconstruction priors,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 16 695– 16 705
work page 2025
-
[30]
Mast3r-sfm: a fully-integrated solution for unconstrained structure-from-motion,
B. P. Duisterhof, L. Zust, P. Weinzaepfel, V . Leroy, Y . Cabon, and J. Revaud, “Mast3r-sfm: a fully-integrated solution for unconstrained structure-from-motion,” in2025 International Conference on 3D Vision (3DV). IEEE, 2025, pp. 1–10
work page 2025
-
[31]
Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass,
J. Yang, A. Sax, K. J. Liang, M. Henaff, H. Tang, A. Cao, J. Chai, F. Meier, and M. Feiszli, “Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 21 924–21 935
work page 2025
-
[32]
3d reconstruction with spatial memory,
H. Wang and L. Agapito, “3d reconstruction with spatial memory,” in 2025 International Conference on 3D Vision (3DV). IEEE, 2025, pp. 78–89
work page 2025
-
[33]
Y . Wu, W. Zheng, J. Zhou, and J. Lu, “Point3r: Streaming 3d reconstruction with explicit spatial pointer memory,”arXiv preprint arXiv:2507.02863, 2025
-
[34]
Worldmirror: Universal 3d world reconstruction with any-prior prompting,
Y . Liu, Z. Min, Z. Wang, J. Wu, T. Wang, Y . Yuan, Y . Luo, and C. Guo, “Worldmirror: Universal 3d world reconstruction with any-prior prompting,”arXiv preprint arXiv:2510.10726, 2025
-
[35]
Omnivggt: Omni-modality driven visual geometry grounded,
H. Peng, H. Li, Y . Dai, Y . Lan, Y . Luo, T. Qi, Z. Zhang, Y . Zhan, J. Zhang, W. Xuet al., “Omnivggt: Omni-modality driven visual geometry grounded,”arXiv preprint arXiv:2511.10560, 2025
-
[36]
G-cut3r: Guided 3d reconstruction with camera and depth prior inte- gration,
R. Khafizov, A. Komarichev, R. Rakhimov, P. Wonka, and E. Burnaev, “G-cut3r: Guided 3d reconstruction with camera and depth prior inte- gration,”arXiv preprint arXiv:2508.11379, 2025
-
[37]
K. Deng, Z. Ti, J. Xu, J. Yang, and J. Xie, “Vggt-long: Chunk it, loop it, align it–pushing vggt’s limits on kilometer-scale long rgb sequences,” arXiv preprint arXiv:2507.16443, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Vision transformers for dense prediction,
R. Ranftl, A. Bochkovskiy, and V . Koltun, “Vision transformers for dense prediction,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 12 179–12 188
work page 2021
-
[40]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[42]
Scale propagation network for generalizable depth completion,
H. Wang, M. Yang, X. Zheng, and G. Hua, “Scale propagation network for generalizable depth completion,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[43]
Prompting depth anything for 4k resolution accurate metric depth estimation,
H. Lin, S. Peng, J. Chen, S. Peng, J. Sun, M. Liu, H. Bao, J. Feng, X. Zhou, and B. Kang, “Prompting depth anything for 4k resolution accurate metric depth estimation,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 17 070–17 080
work page 2025
-
[44]
Scannet++: A high- fidelity dataset of 3d indoor scenes,
C. Yeshwanth, Y .-C. Liu, M. Nießner, and A. Dai, “Scannet++: A high- fidelity dataset of 3d indoor scenes,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 12–22
work page 2023
-
[45]
ARKitScenes: A Diverse Real-World Dataset For 3D Indoor Scene Understanding Using Mobile RGB-D Data
G. Baruch, Z. Chen, A. Dehghan, T. Dimry, Y . Feigin, P. Fu, T. Gebauer, B. Joffe, D. Kurz, A. Schwartzet al., “Arkitscenes: A diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data,” arXiv preprint arXiv:2111.08897, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[46]
Scannet: Richly-annotated 3d reconstructions of indoor scenes,
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “Scannet: Richly-annotated 3d reconstructions of indoor scenes,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 5828–5839
work page 2017
-
[47]
Matterport3D: Learning from RGB-D Data in Indoor Environments
A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niessner, M. Savva, S. Song, A. Zeng, and Y . Zhang, “Matterport3d: Learning from rgb-d data in indoor environments,”arXiv preprint arXiv:1709.06158, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[48]
Dynamicstereo: Consistent dynamic depth from stereo videos,
N. Karaev, I. Rocco, B. Graham, N. Neverova, A. Vedaldi, and C. Rup- precht, “Dynamicstereo: Consistent dynamic depth from stereo videos,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 13 229–13 239
work page 2023
-
[49]
Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding,
M. Roberts, J. Ramapuram, A. Ranjan, A. Kumar, M. A. Bautista, N. Paczan, R. Webb, and J. M. Susskind, “Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 912–10 922
work page 2021
-
[50]
Scalability in perception for autonomous driving: Waymo open dataset,
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caineet al., “Scalability in perception for autonomous driving: Waymo open dataset,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2446–2454
work page 2020
-
[51]
Map-free visual relocalization: Metric pose relative to a single image,
E. Arnold, J. Wynn, S. Vicente, G. Garcia-Hernando, A. Monszpart, V . Prisacariu, D. Turmukhambetov, and E. Brachmann, “Map-free visual relocalization: Metric pose relative to a single image,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 690–708
work page 2022
-
[52]
Y . Cabon, N. Murray, and M. Humenberger, “Virtual kitti 2,”arXiv preprint arXiv:2001.10773, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[53]
Deepmvs: Learning multi-view stereopsis,
P.-H. Huang, K. Matzen, J. Kopf, N. Ahuja, and J.-B. Huang, “Deepmvs: Learning multi-view stereopsis,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 2821–2830
work page 2018
-
[54]
Generative camera dolly: Extreme monocular dynamic novel view synthesis,
B. Van Hoorick, R. Wu, E. Ozguroglu, K. Sargent, R. Liu, P. Tokmakov, A. Dave, C. Zheng, and C. V ondrick, “Generative camera dolly: Extreme monocular dynamic novel view synthesis,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 313–331. IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE (UNDER REVIEW) 15
work page 2024
-
[55]
Flow-motion and depth network for monocular stereo and beyond,
K. Wang and S. Shen, “Flow-motion and depth network for monocular stereo and beyond,”IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 3307–3314, 2020
work page 2020
-
[56]
Matrixcity: A large-scale city dataset for city-scale neural rendering and beyond,
Y . Li, L. Jiang, L. Xu, Y . Xiangli, Z. Wang, D. Lin, and B. Dai, “Matrixcity: A large-scale city dataset for city-scale neural rendering and beyond,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3205–3215
work page 2023
-
[57]
Mid-air: A multi-modal dataset for extremely low altitude drone flights,
M. Fonder and M. V . Droogenbroeck, “Mid-air: A multi-modal dataset for extremely low altitude drone flights,” inConference on Computer Vision and Pattern Recognition Workshop (CVPRW), June 2019
work page 2019
-
[58]
Smd-nets: Stereo mixture density networks,
F. Tosi, Y . Liao, C. Schmitt, and A. Geiger, “Smd-nets: Stereo mixture density networks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8942–8952
work page 2021
-
[59]
Tartanair: A dataset to push the limits of visual slam,
W. Wang, D. Zhu, X. Wang, Y . Hu, Y . Qiu, C. Wang, Y . Hu, A. Kapoor, and S. Scherer, “Tartanair: A dataset to push the limits of visual slam,” in2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 4909–4916
work page 2020
-
[60]
Pointodyssey: A large-scale synthetic dataset for long-term point track- ing,
Y . Zheng, A. W. Harley, B. Shen, G. Wetzstein, and L. J. Guibas, “Pointodyssey: A large-scale synthetic dataset for long-term point track- ing,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 19 855–19 865
work page 2023
-
[61]
Spring: A high-resolution high-detail dataset and benchmark for scene flow, optical flow and stereo,
L. Mehl, J. Schmalfuss, A. Jahedi, Y . Nalivayko, and A. Bruhn, “Spring: A high-resolution high-detail dataset and benchmark for scene flow, optical flow and stereo,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 4981–4991
work page 2023
-
[62]
Rgbd objects in the wild: Scaling real-world 3d object learning from rgb-d videos,
H. Xia, Y . Fu, S. Liu, and X. Wang, “Rgbd objects in the wild: Scaling real-world 3d object learning from rgb-d videos,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 22 378–22 389
work page 2024
-
[63]
T. Wu, J. Zhang, X. Fu, Y . Wang, J. Ren, L. Pan, W. Wu, L. Yang, J. Wang, C. Qianet al., “Omniobject3d: Large-vocabulary 3d object dataset for realistic perception, reconstruction and generation,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 803–814
work page 2023
-
[64]
Humman: Multi-modal 4d human dataset for versatile sensing and modeling,
Z. Cai, D. Ren, A. Zeng, Z. Lin, T. Yu, W. Wang, X. Fan, Y . Gao, Y . Yu, L. Panet al., “Humman: Multi-modal 4d human dataset for versatile sensing and modeling,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 557–577
work page 2022
-
[65]
Virtual normal: Enforcing geometric constraints for accurate and robust depth prediction,
W. Yin, Y . Liu, and C. Shen, “Virtual normal: Enforcing geometric constraints for accurate and robust depth prediction,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 10, pp. 7282– 7295, 2021
work page 2021
-
[66]
Pacgdc: Label- efficient generalizable depth completion with projection ambiguity and consistency,
H. Wang, A. Xiao, X. Zhang, M. Yang, and S. Lu, “Pacgdc: Label- efficient generalizable depth completion with projection ambiguity and consistency,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 7709–7720
work page 2025
-
[67]
An analysis of svd for deep rotation esti- mation,
J. Levinson, C. Esteves, K. Chen, N. Snavely, A. Kanazawa, A. Ros- tamizadeh, and A. Makadia, “An analysis of svd for deep rotation esti- mation,”Advances in Neural Information Processing Systems, vol. 33, pp. 22 554–22 565, 2020
work page 2020
-
[68]
On the continuity of rotation representations in neural networks,
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li, “On the continuity of rotation representations in neural networks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 5745–5753
work page 2019
-
[69]
Scene coordinate regression forests for camera relocalization in rgb-d images,
J. Shotton, B. Glocker, C. Zach, S. Izadi, A. Criminisi, and A. Fitzgib- bon, “Scene coordinate regression forests for camera relocalization in rgb-d images,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2013, pp. 2930–2937
work page 2013
-
[70]
Neural rgb-d surface reconstruction,
D. Azinovi ´c, R. Martin-Brualla, D. B. Goldman, M. Nießner, and J. Thies, “Neural rgb-d surface reconstruction,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 6290–6301
work page 2022
-
[71]
Large scale multi-view stereopsis evaluation,
R. Jensen, A. Dahl, G. V ogiatzis, E. Tola, and H. Aanæs, “Large scale multi-view stereopsis evaluation,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2014, pp. 406–413
work page 2014
-
[72]
A naturalistic open source movie for optical flow evaluation,
D. J. Butler, J. Wulff, G. B. Stanley, and M. J. Black, “A naturalistic open source movie for optical flow evaluation,” inEuropean conference on computer vision. Springer, 2012, pp. 611–625
work page 2012
-
[73]
A benchmark for the evaluation of rgb-d slam systems,
J. Sturm, N. Engelhard, F. Endres, W. Burgard, and D. Cremers, “A benchmark for the evaluation of rgb-d slam systems,” in2012 IEEE/RSJ international conference on intelligent robots and systems. IEEE, 2012, pp. 573–580
work page 2012
-
[74]
Re- fusion: 3d reconstruction in dynamic environments for rgb-d cameras exploiting residuals,
E. Palazzolo, J. Behley, P. Lottes, P. Giguere, and C. Stachniss, “Re- fusion: 3d reconstruction in dynamic environments for rgb-d cameras exploiting residuals,” in2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2019, pp. 7855–7862
work page 2019
-
[75]
A multi-view stereo benchmark with high- resolution images and multi-camera videos,
T. Schops, J. L. Schonberger, S. Galliani, T. Sattler, K. Schindler, M. Pollefeys, and A. Geiger, “A multi-view stereo benchmark with high- resolution images and multi-camera videos,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 3260– 3269
work page 2017
-
[76]
Vision meets robotics: The kitti dataset,
A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The kitti dataset,”The international journal of robotics research, vol. 32, no. 11, pp. 1231–1237, 2013
work page 2013
-
[77]
Indoor segmentation and support inference from rgbd images,
N. Silberman, D. Hoiem, P. Kohli, and R. Fergus, “Indoor segmentation and support inference from rgbd images,” inEuropean conference on computer vision. Springer, 2012, pp. 746–760
work page 2012
-
[78]
MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion
J. Zhang, C. Herrmann, J. Hur, V . Jampani, T. Darrell, F. Cole, D. Sun, and M.-H. Yang, “Monst3r: A simple approach for estimating geometry in the presence of motion,”arXiv preprint arXiv:2410.03825, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[79]
Omni-dc: Highly robust depth completion with multiresolution depth integration,
Y . Zuo, W. Yang, Z. Ma, and J. Deng, “Omni-dc: Highly robust depth completion with multiresolution depth integration,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 9287–9297
work page 2025
-
[80]
Sparsedc: Depth completion from sparse and non-uniform inputs,
C. Long, W. Zhang, Z. Chen, H. Wang, Y . Liu, P. Tong, Z. Cao, Z. Dong, and B. Yang, “Sparsedc: Depth completion from sparse and non-uniform inputs,”Information Fusion, vol. 110, p. 102470, 2024. Haotian Wang(Member, IEEE) received the Ph.D. degree from the Institute of Artificial Intelligence and Robotics, Xi’an Jiaotong University, Xi’an, China, in 2025...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.