Prompt Codebooks: Discrete Compositional Optimization for Language Model Instruction Refinement
Pith reviewed 2026-06-29 12:23 UTC · model grok-4.3
The pith
Prompt Codebooks recasts automatic prompt optimization as discrete learning over a finite vocabulary of reusable natural-language instincts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
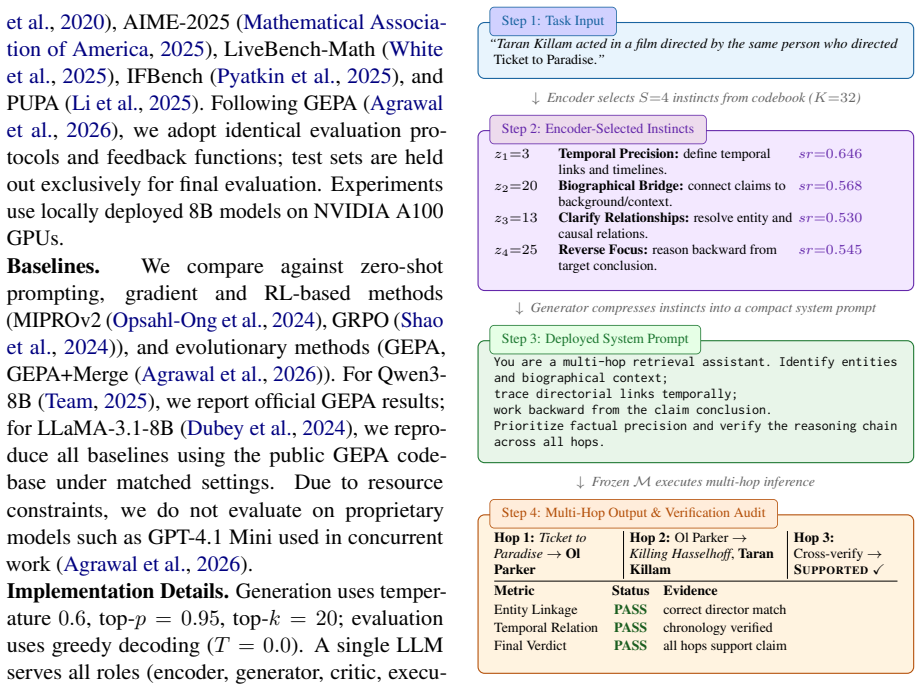
The paper claims that organizing prompt knowledge into a discrete codebook of instincts, routing each input to a small subset via an LLM encoder, composing them with a generator, and training the whole system with a critic under a language-valued min-max objective produces more effective and shorter prompts than monolithic optimization, delivering up to 30.36-point gains over zero-shot and length reductions of 14.1x versus MIPROv2 using only 16 instincts.
What carries the argument
The Prompt Codebook: a finite vocabulary of natural-language instincts together with an LLM encoder that routes inputs to small subsets, a generator that composes them into prompts, and a critic that emits structured verdicts for joint optimization under a language-valued min-max objective.
If this is right
- Per-instance routing lets different inputs inside the same task receive different instinct compositions, a regime impossible for instance-blind methods.
- Performance improves up to 30.36 points over zero-shot and 3.34 points over GEPA on HotpotQA across Qwen3-8B and LLaMA-3.1-8B.
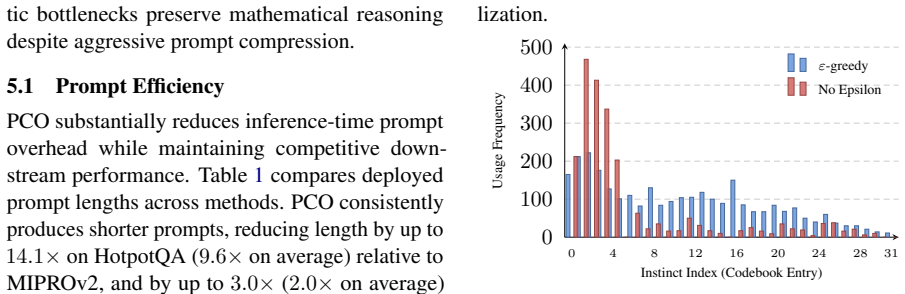
- Deployed prompt length drops by up to 14.1 times versus MIPROv2 and 3.0 times versus GEPA while using only K=16 instincts.
- The codebook structure separates reusable sub-behaviors from instance-specific selection, enabling reuse across tasks without re-optimizing entire prompts.
Where Pith is reading between the lines
- The same codebook-plus-encoder pattern could be applied to other adaptive-instruction settings such as tool-use chains or multi-agent coordination.
- Because instincts remain explicit natural-language units, the learned codebook may support human inspection and manual editing of individual sub-behaviors.
- If routing remains stable across model scales, the approach could reduce the need to store or transmit long task-specific prompts at inference time.
Load-bearing premise
The LLM encoder can reliably route each input to an effective small subset of instincts and the critic's structured verdicts supply usable textual gradients that jointly improve the encoder, generator, and codebook.
What would settle it
A controlled experiment on a held-out benchmark or model in which PCO fails to exceed the strongest baseline in aggregate accuracy or fails to produce shorter effective prompts than GEPA would falsify the performance and compression claims.
Figures

read the original abstract
Automatic prompt optimization (APO) has driven significant gains in LLM-based agentic workflows. However, existing methods treat each task's prompt as a monolithic, instance-blind string optimized through global edits, producing brittle updates and preventing the reuse of learned sub-behaviors. We propose Prompt Codebooks (PCO), a novel compositional prompt optimization framework that recasts APO as discrete learning over a finite vocabulary of natural-language instincts - atomic, reusable instruction units. PCO organizes prompt-construction knowledge in a discrete codebook and routes each input to a small subset of entries via an LLM-based encoder; a generator composes them into a prompt for the frozen target model; a critic emits a structured verdict that decomposes by attribution into per-variable textual gradients, jointly training the encoder, generator, and codebook under a language-valued min-max objective. The resulting routing is per-instance: different inputs in the same task receive different instinct compositions, a regime structurally inexpressible under instance-blind methods. Across six benchmarks on Qwen3-8B and LLaMA-3.1-8B, PCO improves over zero-shot by up to +30.36 points, surpasses the strongest prior baseline (GEPA) by +3.34 on HotpotQA and +1.11 in aggregate, and reduces deployed prompt length by up to 14.1x versus MIPROv2 and 3.0x versus GEPA using only K=16 instincts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Prompt Codebooks (PCO), a compositional automatic prompt optimization (APO) framework that represents prompt knowledge as a discrete codebook of K natural-language 'instincts.' An LLM encoder performs per-instance routing to a small subset of instincts; a generator composes them into a prompt for a frozen target LLM; and a critic produces structured, attribution-decomposed verdicts that supply textual gradients for joint min-max training of the encoder, generator, and codebook. Empirical claims include gains of up to +30.36 points over zero-shot, +3.34 on HotpotQA and +1.11 aggregate over GEPA, and prompt-length reductions of up to 14.1x vs. MIPROv2, all on Qwen3-8B and LLaMA-3.1-8B across six benchmarks using only K=16 instincts.
Significance. If the empirical results and training procedure hold under scrutiny, the work would be significant for introducing the first instance-specific, reusable compositional mechanism in APO, a regime that monolithic global-edit methods cannot express. The language-valued min-max objective and per-variable textual gradients constitute a concrete technical contribution that could influence future discrete optimization approaches for LLMs.
minor comments (1)
- The abstract states concrete performance numbers, length reductions, and comparisons to GEPA/MIPROv2, yet supplies no experimental protocol, ablation design, statistical tests, or implementation details on the min-max objective; the manuscript must include these to allow evaluation of the data-to-claim link.
Simulated Author's Rebuttal
We thank the referee for their summary of our work and for acknowledging its potential significance in introducing the first instance-specific, reusable compositional mechanism in automatic prompt optimization. The recommendation of 'uncertain' appears to stem from the absence of detailed major comments in the report. Below we provide point-by-point responses where applicable; since no specific major comments were enumerated, we focus on clarifying the core technical and empirical elements that may underlie the uncertainty.
Circularity Check
No significant circularity detected
full rationale
The paper's central claims consist of empirical performance gains on external benchmarks (Qwen3-8B, LLaMA-3.1-8B, HotpotQA, etc.) against independent baselines (GEPA, MIPROv2, zero-shot). No derivation, equation, or optimization step is shown that reduces by construction to a fitted parameter, self-citation, or renamed input; the codebook, encoder, and critic are presented as a new construction whose value is measured by held-out task accuracy and prompt length, not by internal identity. The abstract and reader's assessment confirm the results rest on falsifiable external comparisons rather than self-referential fitting.
Axiom & Free-Parameter Ledger
free parameters (1)
- K =
16
axioms (1)
- domain assumption LLMs can function as reliable encoders for routing, generators for composition, and critics providing attributional textual gradients.
invented entities (1)
-
instincts
no independent evidence
Reference graph
Works this paper leans on
-
[1]
InInternational Conference on Machine Learning (ICML)
Wasserstein generative adversarial networks. InInternational Conference on Machine Learning (ICML). Sara Câmara, Eduardo Luz, Valéria Carvalho, Ivan Meneghini, and Gladston Moreira. 2025. Moprompt: Multi-objective semantic evolution for prompt opti- mization.arXiv preprint arXiv:2508.01541. Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T. Freeman...
-
[2]
High Fidelity Neural Audio Compression
Trace is the next autodiff: Generative opti- mization with rich feedback, execution traces, and llms.(NeurIPS). Alexandre Defossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. 2022. High fidelity neural audio compres- sion.arXiv preprint arXiv:2210.13438. Mingkai Deng, Jianyu Wang, Cheng-Ping Hsieh, Yihan Wang, Han Guo, Tianmin Shu, Meng Song, Eric P. Xi...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Generating diverse high-fidelity images with vq-vae-2.NeurIPS. Zhihong Shao and 1 others. 2024. Deepseekmath: Push- ing the limits of mathematical reasoning in open lan- guage models.arXiv preprint arXiv:2402.03300. Taylor Shin, Yasaman Razeghi, Robert L. Logan IV, Eric Wallace, and Sameer Singh. 2020. AutoPrompt: Eliciting knowledge from language models ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.