Early Warning Signals for OpenVLA Failure under Visual Distribution Shift
Pith reviewed 2026-06-30 06:54 UTC · model grok-4.3
The pith
OpenVLA internal activations at layer 16 contain linearly decodable signals of impending task failure under visual occlusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
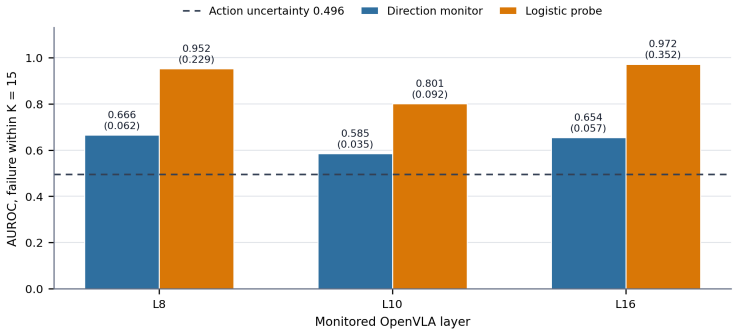
OpenVLA feedforward activations contain linearly decodable information about near-term task failure in LIBERO manipulation rollouts. Under occlusion, a logistic probe at layer 16 reaches AUROC 0.972 and AUPRC 0.352 for predicting failure within a 15-step horizon and outperforms both a mean-difference direction and an action-disagreement baseline. A sparse layer sweep shows uneven decodability, with layer 16 strongest, layer 8 still informative, and layer 10 weaker. The occlusion-trained monitor stays above random on camera jitter without retraining, while color shift induces no failures and serves as a control.
What carries the argument
Logistic regression probe on layer-16 activations that predicts binary failure labels within a 15-step horizon.
If this is right
- The probe outperforms both a mean-difference direction and an action-disagreement baseline under the same occlusion condition.
- Decodability varies across depth: layer 16 is strongest, layer 8 remains informative, and layer 10 is weaker.
- The monitor trained only on occlusion data stays above random when evaluated on camera jitter that also induces failures.
- Color shift produces no task failures and leaves the monitor at chance, consistent with it not being a generic visual-change detector.
Where Pith is reading between the lines
- If the same probe generalizes across tasks, lightweight linear monitors could be added to existing VLA deployments for real-time reliability checks without retraining the policy.
- The mid-layer peak in decodability suggests that similar models may carry the most usable failure signals in intermediate rather than final layers.
- Extending the horizon or testing on held-out tasks would show whether the signal supports proactive recovery rather than only post-hoc diagnosis.
Load-bearing premise
The probe trained on occlusion-induced failures is reading signals of genuine impending task failure rather than simply registering the presence of occlusion.
What would settle it
Apply the occlusion-trained probe to a new visual shift that produces task failures but is visually dissimilar to occlusion; performance falling to chance would falsify the claim that the activations carry general failure-relevant structure.
Figures
read the original abstract
Vision Language Action models combine perception, language grounding, and control in a single policy, but their failures are hard to diagnose once visual conditions shift. We test whether OpenVLA feedforward activations contain linearly decodable information about near term task failure in LIBERO manipulation rollouts. The policy is fixed throughout. We log internal activations during execution and fit lightweight monitors after the rollouts are collected. Occlusion is the main controlled stress test. It reduces OpenVLA success from $57\%$ to $17\%$ over $100$ episodes per condition. Under this shift, a logistic probe at layer 16 reaches AUROC $0.972$ and AUPRC $0.352$ for predicting failure within a $15$ step horizon. It outperforms both a mean difference direction and an action disagreement baseline. A sparse layer sweep finds uneven decodability across depth: layer 16 is strongest among the tested layers, layer 8 remains informative, and layer 10 is weaker. To check whether the monitor is just an occlusion detector, we also evaluate color shift and camera jitter without refitting. Color shift produces no failures in this setting, so it is a benign control rather than a failure benchmark. Camera jitter does induce failures, and the occlusion trained monitor remains above random. The result is deliberately limited: OpenVLA internal states contain failure relevant structure under controlled perceptual shift, but these experiments do not establish a causal mechanism, task held out generalization, or a deployable recovery system.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that OpenVLA feedforward activations contain linearly decodable information about near-term task failure under visual distribution shift. In LIBERO manipulation rollouts with a fixed policy, occlusion reduces success from 57% to 17%. Post-hoc logistic probes fitted on logged activations yield AUROC 0.972 and AUPRC 0.352 at layer 16 for failure prediction within a 15-step horizon, outperforming a mean-difference direction and an action-disagreement baseline. A layer sweep shows uneven decodability (layer 16 strongest, layer 8 informative). Color-shift episodes (no failures) serve as a control; the occlusion-trained probe transfers above chance to camera-jitter failures. The work explicitly limits its scope to correlational evidence without causal claims, held-out generalization, or a deployable system.
Significance. If the central empirical result holds, the work demonstrates that VLA representations encode failure-relevant linear structure under controlled perceptual shift, providing a concrete starting point for activation-based monitors. Credit is due for the controlled stress-test design (occlusion as primary shift, color shift as benign control, transfer to jitter), the explicit acknowledgment of correlational limits, and the post-hoc but lightweight probe methodology. The finding is modest in scope but directly addresses a practical gap in diagnosing VLA failures.
major comments (2)
- [main results on occlusion condition] The main results paragraph reporting AUROC 0.972 / AUPRC 0.352 and outperformance of the two baselines provides no error bars, standard errors, or statistical significance tests across the 100 episodes per condition. Because the central claim rests on the probe outperforming the baselines, the absence of variance estimates is load-bearing for assessing whether the reported margins are reliable.
- [main results on occlusion condition] Given the reported 83% failure rate under occlusion, the AUPRC of 0.352 for the failure class is low relative to the AUROC of 0.972; the manuscript does not discuss this discrepancy or clarify whether AUPRC is computed with failure as the positive class and what the random baseline would be.
minor comments (3)
- [layer sweep paragraph] The abstract and main text refer to a 'sparse layer sweep' but do not state how many layers were tested in total or the precise selection procedure for the reported layers 8, 10, and 16.
- [experimental setup] The 15-step prediction horizon is stated without justification or sensitivity analysis; a brief note on why this horizon was chosen relative to task length would improve clarity.
- [control experiments] The color-shift control is described as producing no failures, but the probe's AUROC/AUPRC on those episodes is not numerically reported, only the qualitative statement that it is a benign control.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comments. We address the two major comments below and will revise the manuscript to incorporate statistical reporting and metric clarification.
read point-by-point responses
-
Referee: [main results on occlusion condition] The main results paragraph reporting AUROC 0.972 / AUPRC 0.352 and outperformance of the two baselines provides no error bars, standard errors, or statistical significance tests across the 100 episodes per condition. Because the central claim rests on the probe outperforming the baselines, the absence of variance estimates is load-bearing for assessing whether the reported margins are reliable.
Authors: We agree that variance estimates are needed to assess the reliability of the reported margins. The manuscript currently omits them. In revision we will add bootstrap standard errors (resampling over the 100 episodes) for both AUROC and AUPRC, together with paired significance tests (DeLong test for AUROC differences and Wilcoxon signed-rank on per-episode scores) comparing the logistic probe to the two baselines. revision: yes
-
Referee: [main results on occlusion condition] Given the reported 83% failure rate under occlusion, the AUPRC of 0.352 for the failure class is low relative to the AUROC of 0.972; the manuscript does not discuss this discrepancy or clarify whether AUPRC is computed with failure as the positive class and what the random baseline would be.
Authors: We will revise the text to state explicitly that AUPRC treats failure as the positive class. The random baseline is the positive prevalence (≈0.83). We will add a short discussion explaining that the high AUROC still demonstrates useful ranking of failure-relevant states while the lower AUPRC is expected under severe class imbalance and a short prediction horizon; the relationship between the two metrics will be clarified in the results section. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's central result is an empirical measurement: a logistic probe fitted to OpenVLA layer activations achieves AUROC 0.972 on held-out failure labels collected from occlusion rollouts. Failure labels are determined independently by whether the manipulation task succeeded or failed in each episode; the probe is a standard linear classifier whose performance metric does not reduce by construction to any quantity defined solely from its own fitted weights. No self-citation chain, uniqueness theorem, or ansatz is invoked to justify the existence of the signal. The color-shift control (no failures) and camera-jitter transfer test are external checks that further separate the probe from merely detecting the shift itself. The derivation is therefore self-contained against the reported data and metrics.
Axiom & Free-Parameter Ledger
free parameters (1)
- logistic probe weights at each tested layer
axioms (1)
- domain assumption Failure-relevant information is linearly decodable from feedforward activations at the tested layers
Reference graph
Works this paper leans on
-
[1]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Rt-2: Vision-language-action models transfer web knowledge to robotic control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[3]
Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, and Pete Florence. Palm-e: An embodied ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Joshi, Kyle Jeffrey, Rosario Jauregui Ruano, Jasmine Hsu, Keerthana Gopalakrishnan, Byron David, Andy Zeng, and Chuyuan Kelly Fu
brian ichter, Anthony Brohan, Yevgen Chebotar, Chelsea Finn, Karol Hausman, Alexander Herzog, Daniel Ho, Julian Ibarz, Alex Irpan, Eric Jang, Ryan Julian, Dmitry Kalashnikov, Sergey Levine, Yao Lu, Carolina Parada, Kanishka Rao, Pierre Sermanet, Alexander T Toshev, Vincent Vanhoucke, Fei Xia, Ted Xiao, Peng Xu, Mengyuan Yan, Noah Brown, Michael Ahn, Omar ...
2023
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020
2020
-
[8]
Richards, Yixiao Sun, Edward Schmerling, and Marco Pavone
Rohan Sinha, Apoorva Sharma, Somrita Banerjee, Thomas Lew, Rachel Luo, Spencer M. Richards, Yixiao Sun, Edward Schmerling, and Marco Pavone. A system-level view on out-of- distribution data in robotics.CoRR, abs/2212.14020, 2022
-
[9]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. volume 44, pages 1684–1704. Sage Publications Sage UK: London, England, 2025
2025
-
[10]
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
Dan Hendrycks and Kevin Gimpel. A baseline for detecting misclassified and out-of-distribution examples in neural networks.arXiv preprint arXiv:1610.02136, 2016. 7
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
Can we detect failures without failure data? uncertainty-aware runtime failure detection for imitation learning policies
Chen Xu, Tony Khuong Nguyen, Emma Dixon, Christopher Rodriguez, Patrick Miller, Robert Lee, Paarth Shah, Rares Ambrus, Haruki Nishimura, and Masha Itkina. Can we detect failures without failure data? uncertainty-aware runtime failure detection for imitation learning policies. InRobotics: Science and Systems, 2025
2025
-
[12]
AHA: A vision-language-model for detecting and reasoning over failures in robotic manipulation
Jiafei Duan, Wilbert Pumacay, Nishanth Kumar, Yi Ru Wang, Shulin Tian, Wentao Yuan, Ranjay Krishna, Dieter Fox, Ajay Mandlekar, and Yijie Guo. AHA: A vision-language-model for detecting and reasoning over failures in robotic manipulation. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[13]
Qiao Gu, Yuanliang Ju, Shengxiang Sun, Igor Gilitschenski, Haruki Nishimura, Masha Itkina, and Florian Shkurti. Safe: Multitask failure detection for vision-language-action models.arXiv preprint arXiv:2506.09937, 2025. NeurIPS 2025 camera ready
-
[14]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Bear Häon, Kaylene C. Stocking, Ian Chuang, and Claire J. Tomlin. Mechanistic interpretability for steering vision-language-action models.arXiv preprint arXiv:2509.00328, 2025. CoRL 2025
-
[16]
all episodes
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023. 8 A Additional warning policy results A.1 Implementation details used in the reported runs This appendix records details that are ei...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.