Analyzing and Improving Fine-grained Preference Optimization in Medical LVLMs
Pith reviewed 2026-06-27 09:50 UTC · model grok-4.3
The pith
A bidirectional token-wise KL regularizer plus visual-contrastive grounding from clean and lesion images improves fine-grained on-policy alignment for medical LVLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Existing preference optimization methods treat all tokens equally, introduce distribution shift from static references, and lack explicit visual grounding, so the authors combine a bidirectional token-wise KL regularizer with a visual-contrastive objective that penalizes outputs generated from corrupted images; this yields a fine-grained on-policy framework whose preference pairs are created by editing only erroneous clinical spans in model-generated text while preserving linguistic style.
What carries the argument
Bidirectional token-wise KL regularizer paired with a visual-contrastive grounding objective that contrasts clean and lesion-corrupted images to enforce visual evidence in responses.
If this is right
- Token-level rather than sequence-level signals allow correction of only clinically erroneous spans.
- On-policy minimal edits avoid steering optimization toward stylistic artifacts from supervised references.
- Explicit pairing of clean and corrupted images forces sensitivity to subtle pathological features.
- The resulting models show improved performance on both medical imaging tasks and clinical text generation benchmarks.
Where Pith is reading between the lines
- The same minimal-edit construction of preference data could lower the cost of creating alignment datasets in any domain where expert editing is expensive.
- The visual-contrastive term may transfer to other vision-language settings that require grounding in specific image regions rather than global captions.
- Because the regularizer operates at token granularity, it could be combined with existing safety or factuality methods that also act on individual tokens.
Load-bearing premise
Minimally editing model-generated outputs will produce clinically valid preference pairs without introducing new biases or distribution shifts.
What would settle it
A controlled test on a medical imaging benchmark in which the trained model still generates responses that ignore visible lesions at the same rate as the unaligned baseline.
Figures







read the original abstract
Large Vision-Language Models (LVLMs) have achieved strong performance across medical imaging tasks, yet they remain prone to factual inconsistencies, poor visual grounding, and misalignment with clinically meaningful feedback. Existing post-training alignment approaches, including Direct Preference Optimization (DPO) and its variants, face three critical limitations in the medical domain: (1) sequence-level reward signals treat clinically critical tokens identically to generic filler text; (2) reliance on static supervised fine-tuning references as preferred responses introduces an off-policy distribution shift, steering optimization toward stylistic artifacts over clinical correctness; and (3) alignment objectives lack explicit visual grounding constraints, leaving models insensitive to subtle yet diagnostically decisive pathological features. Our method leverages a bidirectional token-wise KL regularizer alongside a visual-contrastive grounding objective that pairs clean and lesion-corrupted images to penalize responses generated without adequate visual evidence. Together, these components form a fine-grained, on-policy alignment framework that constructs preference pairs by minimally editing model-generated outputs, correcting only clinically erroneous spans while preserving the original linguistic style. Extensive experiments across medical imaging tasks and clinical text generation benchmarks validate the effectiveness of our approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing post-training alignment approaches for medical LVLMs, including DPO and variants, suffer from three limitations: sequence-level rewards that treat all tokens equally, off-policy distribution shifts from static SFT references, and lack of explicit visual grounding. It proposes a fine-grained on-policy framework using a bidirectional token-wise KL regularizer combined with a visual-contrastive grounding objective that pairs clean and lesion-corrupted images to penalize responses lacking visual evidence. Preference pairs are constructed by minimally editing model-generated outputs to correct only clinically erroneous spans while preserving linguistic style. The authors assert that extensive experiments across medical imaging tasks and clinical text generation benchmarks validate the approach.
Significance. If the proposed regularizer and contrastive objective deliver the claimed fine-grained, on-policy alignment with reliable visual grounding and without introducing new biases, the work could meaningfully advance the clinical reliability of LVLMs by improving sensitivity to pathological features and reducing factual inconsistencies in safety-critical medical applications.
major comments (3)
- [Abstract] Abstract: the claim that 'extensive experiments across medical imaging tasks and clinical text generation benchmarks validate the effectiveness of our approach' supplies no quantitative results, baselines, error bars, dataset details, or performance metrics, so the central empirical validation assertion is unevidenced.
- [Abstract] Abstract: the visual-contrastive grounding objective is described only at a high level ('pairs clean and lesion-corrupted images to penalize responses generated without adequate visual evidence'); no corruption operator, loss formulation for the bidirectional token-wise KL regularizer, or computation of the contrastive signal is provided, which are load-bearing for the proposed framework.
- [Abstract] Abstract: the on-policy preference-pair construction ('minimally editing model-generated outputs, correcting only clinically erroneous spans while preserving the original linguistic style') does not specify the span-identification procedure (human, rule-based, or auxiliary model), leaving open risks of annotator bias, distribution shift, or circularity that directly affect the on-policy claim.
minor comments (1)
- [Abstract] Abstract: the three listed limitations are stated without citations to specific prior works that exemplify each issue.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback focused on the abstract. We agree that the abstract can be strengthened with additional concrete details without exceeding typical length constraints, and we will revise it accordingly while ensuring the main text already contains the supporting technical descriptions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'extensive experiments across medical imaging tasks and clinical text generation benchmarks validate the effectiveness of our approach' supplies no quantitative results, baselines, error bars, dataset details, or performance metrics, so the central empirical validation assertion is unevidenced.
Authors: We agree the abstract claim would be more compelling with quantitative support. In the revision we will add concise references to key metrics (e.g., accuracy and grounding improvements), primary datasets, and main baselines from the experimental section. revision: yes
-
Referee: [Abstract] Abstract: the visual-contrastive grounding objective is described only at a high level ('pairs clean and lesion-corrupted images to penalize responses generated without adequate visual evidence'); no corruption operator, loss formulation for the bidirectional token-wise KL regularizer, or computation of the contrastive signal is provided, which are load-bearing for the proposed framework.
Authors: The abstract supplies a high-level summary per convention; the corruption operator, bidirectional token-wise KL formulation, and contrastive signal are defined in Section 3. We will insert one additional sentence in the abstract that briefly names these elements to address the concern. revision: yes
-
Referee: [Abstract] Abstract: the on-policy preference-pair construction ('minimally editing model-generated outputs, correcting only clinically erroneous spans while preserving the original linguistic style') does not specify the span-identification procedure (human, rule-based, or auxiliary model), leaving open risks of annotator bias, distribution shift, or circularity that directly affect the on-policy claim.
Authors: We acknowledge that the abstract omits the identification procedure. Section 4 describes the hybrid rule-based plus auxiliary-model approach used to locate erroneous spans. We will add a short clause in the abstract to indicate this procedure and thereby strengthen the on-policy claim. revision: yes
Circularity Check
No circularity; no equations or self-referential reductions present
full rationale
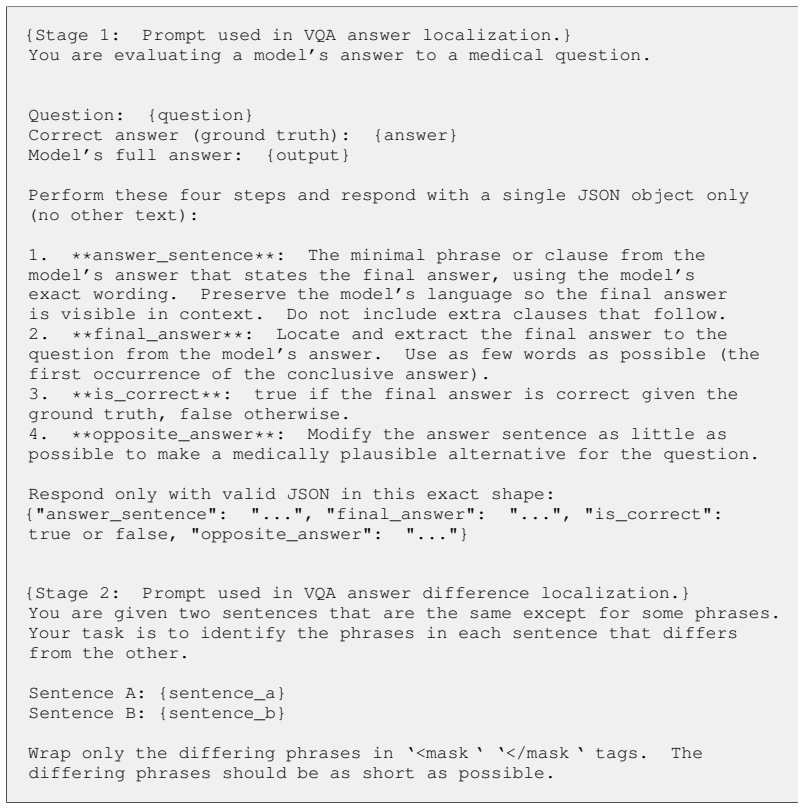
The provided abstract and description contain no equations, derivations, or explicit mathematical steps. The method is described at a high level as combining a bidirectional token-wise KL regularizer with a visual-contrastive objective and minimal editing of outputs, but no component is shown reducing to a fitted input by construction, a self-citation chain, or a renamed known result. No load-bearing claim is justified solely by self-citation or ansatz smuggling. The framework is presented as an empirical improvement without a derivation chain that collapses to its inputs, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[2]
Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[3]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Pith/arXiv arXiv 2025
-
[4]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[5]
Llava-med: Training a large language-and-vision assistant for biomedicine in one day
Chunyuan Li, Cliff Wong, Zirui Zhang, Yan Luo, Jianwei Yang, Haotian Liu, Kai-Wei Cheng, Yu Yue, Jianfeng Peng, Jianfeng Gao, et al. Llava-med: Training a large language-and-vision assistant for biomedicine in one day. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[6]
Zhihong Chen, Maya Varma, Jean-Benoit Delbrouck, Magdalini Paschali, et al. Chexagent: Towards a foundation model for chest x-ray interpretation.arXiv preprint arXiv:2401.12208, 2024
arXiv 2024
-
[7]
Towards injecting medical visual knowledge into multimodal llms at scale
Junying Chen, Chi Gui, Ruyi Ouyang, Anningzhe Gao, Shunian Chen, Guiming Hardy Chen, Xidong Wang, Zhenyang Cai, Ke Ji, Xiang Wan, et al. Towards injecting medical visual knowledge into multimodal llms at scale. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 7346–7370, 2024
2024
-
[8]
Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
Pith/arXiv arXiv 2025
-
[9]
Multimodal large language models in health care: ap- plications, challenges, and future outlook.Journal of medical Internet research, 26:e59505, 2024
Rawan AlSaad, Alaa Abd-Alrazaq, Sabri Boughorbel, Arfan Ahmed, Max-Antoine Renault, Rafat Damseh, and Javaid Sheikh. Multimodal large language models in health care: ap- plications, challenges, and future outlook.Journal of medical Internet research, 26:e59505, 2024
2024
-
[10]
Capabilities of gemini models in medicine.arXiv preprint arXiv:2404.18416, 2024
Khaled Saab, Tao Tu, Wei-Hung Weng, Ryutaro Tanno, David Stutz, Ellery Wulczyn, Fan Zhang, Tim Strother, Chunjong Park, Elahe Vedadi, et al. Capabilities of gemini models in medicine.arXiv preprint arXiv:2404.18416, 2024
Pith/arXiv arXiv 2024
-
[11]
et al. Zhang. Detecting and evaluating medical hallucinations in large vision language models. arXiv preprint arXiv:2406.10185, 2024
Pith/arXiv arXiv 2024
-
[12]
Hallucinogen: Benchmarking hallucination in implicit reasoning within large vision language models
Ashish Seth, Dinesh Manocha, and Chirag Agarwal. Hallucinogen: Benchmarking hallucination in implicit reasoning within large vision language models. InProceedings of the 2nd Workshop on Uncertainty-Aware NLP (UncertaiNLP 2025), pages 89–102, 2025
2025
-
[13]
Ai reliability gap: Why large language models fail in safety-critical systems
Praneeth Vadlapati. Ai reliability gap: Why large language models fail in safety-critical systems. ResearchGate / Independent Report, 2026. URL https://www.researchgate.net/ publication/401422885
arXiv 2026
-
[14]
Cares: A comprehensive benchmark of trustworthiness in medical vision language models.Advances in Neural Information Processing Systems, 37: 140334–140365, 2024
Peng Xia, Ze Chen, Juanxi Tian, Yangrui Gong, Ruibo Hou, Yue Xu, Zhenbang Wu, Zhiyuan Fan, Yiyang Zhou, Kangyu Zhu, et al. Cares: A comprehensive benchmark of trustworthiness in medical vision language models.Advances in Neural Information Processing Systems, 37: 140334–140365, 2024
2024
-
[15]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023. 11
2023
-
[16]
Kto: Model alignment as prospect theoretic optimization, 2024.URL https://arxiv
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Kto: Model alignment as prospect theoretic optimization, 2024.URL https://arxiv. org/abs/2402.01306, 14, 2023
Pith/arXiv arXiv 2024
-
[17]
A general theoretical paradigm to understand learning from human preferences
Mohammad Gheshlaghi Azar, Zhaohan Daniel Guo, Bilal Piot, Remi Munos, Mark Rowland, Michal Valko, and Daniele Calandriello. A general theoretical paradigm to understand learning from human preferences. InInternational Conference on Artificial Intelligence and Statistics, pages 4447–4455. PMLR, 2024
2024
-
[18]
CheXalign: Preference fine-tuning in chest X-ray interpretation models without hu- man feedback
Dennis Hein, Zhihong Chen, Sophie Ostmeier, Justin Xu, Maya Varma, Eduardo Pontes Reis, Arne Edward Michalson, Christian Bluethgen, Hyun Joo Shin, Curtis Langlotz, and Akshay S Chaudhari. CheXalign: Preference fine-tuning in chest X-ray interpretation models without hu- man feedback. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pi...
- [19]
-
[20]
Thomas Savage, Stephen P Ma, Abdessalem Boukil, Ekanath Rangan, Vishwesh Patel, Ivan Lopez, and Jonathan Chen. Fine-tuning methods for large language models in clinical medicine by supervised fine-tuning and direct preference optimization: Comparative evaluation.Journal of Medical Internet Research, 27:e76048, 2025
2025
-
[21]
Self-training large language and vision assistant for medical question answering
Guohao Sun, Can Qin, Huazhu Fu, Linwei Wang, and Zhiqiang Tao. Self-training large language and vision assistant for medical question answering. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 20052–20060, 2024
2024
-
[22]
Benchmarking direct preference optimization for medical large vision-language models
Dain Kim, Jiwoo Lee, Jaehoon Yun, Yong Hoe Koo, Qingyu Chen, Hyunjae Kim, and Jaewoo Kang. Benchmarking direct preference optimization for medical large vision-language models. arXiv preprint arXiv:2601.17918, 2026
arXiv 2026
-
[23]
Alexandra DeLucia, Heyuan Huang, Sonal Joshi, Mahsa Yarmohammadi, Ahmed Hassoon, and Mark Dredze. Same verdict, different reasons: Llm-as-a-judge and clinician disagreement on medical chatbot completeness.arXiv preprint arXiv:2604.16383, 2026
Pith/arXiv arXiv 2026
-
[24]
Reliability of supervised machine learning using synthetic data in health care: Model to preserve privacy for data sharing.JMIR medical informatics, 8(7):e18910, 2020
Debbie Rankin, Michaela Black, Raymond Bond, Jonathan Wallace, Maurice Mulvenna, and Gorka Epelde. Reliability of supervised machine learning using synthetic data in health care: Model to preserve privacy for data sharing.JMIR medical informatics, 8(7):e18910, 2020
2020
-
[25]
Rrg-dpo: Direct preference optimization for clinically accurate radiology report generation
Hong Liu, Dong Wei, Zhe Xu, Xian Wu, Yefeng Zheng, and Liansheng Wang. Rrg-dpo: Direct preference optimization for clinically accurate radiology report generation. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 552–562. Springer, 2025
2025
-
[26]
Mitigating hallucina- tions in large vision-language models via dpo: On-policy data hold the key
Zhihe Yang, Xufang Luo, Dongqi Han, Yunjian Xu, and Dongsheng Li. Mitigating hallucina- tions in large vision-language models via dpo: On-policy data hold the key. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10610–10620, 2025
2025
-
[27]
Pritam Sarkar and Ali Etemad. Self-alignment of large video language models with refined regularized preference optimization.arXiv preprint arXiv:2504.12083, 2025
arXiv 2025
-
[28]
Shusheng Xu, Wei Fu, Jiaxuan Gao, Wenjie Ye, Weilin Liu, Zhiyu Mei, Guangju Wang, Chao Yu, and Yi Wu. Is dpo superior to ppo for llm alignment? a comprehensive study.arXiv preprint arXiv:2404.10719, 2024
arXiv 2024
-
[29]
Yuzi Yan, Yibo Miao, Jialian Li, Yipin Zhang, Jian Xie, Zhijie Deng, and Dong Yan. 3d-properties: Identifying challenges in dpo and charting a path forward.arXiv preprint arXiv:2406.07327, 2024. 12
arXiv 2024
-
[30]
Jay Hyeon Cho, JunHyeok Oh, Myunsoo Kim, and Byung-Jun Lee. Rethinking dpo: The role of rejected responses in preference misalignment.arXiv preprint arXiv:2506.12725, 2025
arXiv 2025
-
[31]
Yuzhe Gu, Wenwei Zhang, Chengqi Lyu, Dahua Lin, and Kai Chen. Mask-dpo: Generalizable fine-grained factuality alignment of llms.arXiv preprint arXiv:2503.02846, 2025
arXiv 2025
-
[32]
Token- level direct preference optimization.arXiv preprint arXiv:2404.11999, 2024
Yongcheng Zeng, Guoqing Liu, Weiyu Ma, Ning Yang, Haifeng Zhang, and Jun Wang. Token- level direct preference optimization.arXiv preprint arXiv:2404.11999, 2024
arXiv 2024
-
[33]
Mingkang Zhu, Xi Chen, Zhongdao Wang, Bei Yu, Hengshuang Zhao, and Jiaya Jia. Tgdpo: Harnessing token-level reward guidance for enhancing direct preference optimization.arXiv preprint arXiv:2506.14574, 2025
arXiv 2025
-
[34]
A. Puli et al. Rad-DPO: Reducing hallucinations in medical visual question answering.arXiv preprint arXiv:2406.06496, 2024
arXiv 2024
-
[35]
mdpo: Conditional preference optimization for multimodal large language models
Fei Wang, Wenxuan Zhou, James Y Huang, Nan Xu, Sheng Zhang, Hoifung Poon, and Muhao Chen. mdpo: Conditional preference optimization for multimodal large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8078–8088, 2024
2024
-
[36]
Chenhang Cui, An Zhang, Yiyang Zhou, Zhaorun Chen, Gelei Deng, Huaxiu Yao, and Tat-Seng Chua. Fine-grained verifiers: Preference modeling as next-token prediction in vision-language alignment.arXiv preprint arXiv:2410.14148, 2024
arXiv 2024
-
[37]
A dataset of clinically generated visual questions and answers about radiology images.Scientific data, 5(1): 180251, 2018
Jason J Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. A dataset of clinically generated visual questions and answers about radiology images.Scientific data, 5(1): 180251, 2018
2018
-
[38]
Slake: A semantically- labeled knowledge-enhanced dataset for medical visual question answering
Bo Liu, Li-Ming Zhan, Li Xu, Lin Ma, Yan Yang, and Xiao-Ming Wu. Slake: A semantically- labeled knowledge-enhanced dataset for medical visual question answering. In2021 IEEE 18th international symposium on biomedical imaging (ISBI), pages 1650–1654. IEEE, 2021
2021
-
[39]
Preparing a collection of radiology examinations for distribution and retrieval.Journal of the American Medical Informatics Association, 23(2):304–310, 2016
Dina Demner-Fushman, Marc D Kohli, Marc B Rosenman, Sonya E Shooshan, Laritza Ro- driguez, Sameer Antani, George R Thoma, and Clement J McDonald. Preparing a collection of radiology examinations for distribution and retrieval.Journal of the American Medical Informatics Association, 23(2):304–310, 2016
2016
-
[40]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
2022
-
[41]
Medsam3: Delving into segment anything with medical concepts.arXiv preprint arXiv:2511.19046, 2025
Anglin Liu, Rundong Xue, Xu R Cao, Yifan Shen, Yi Lu, Xiang Li, Qianqian Chen, and Jintai Chen. Medsam3: Delving into segment anything with medical concepts.arXiv preprint arXiv:2511.19046, 2025
arXiv 2025
-
[42]
Green: Generative radiology report evaluation and error notation
Sophie Ostmeier, Justin Xu, Zhihong Chen, Maya Varma, Louis Blankemeier, Christian Blueth- gen, Arne Edward Michalson Md, Michael Moseley, Curtis Langlotz, Akshay S Chaudhari, et al. Green: Generative radiology report evaluation and error notation. InFindings of the association for computational linguistics: EMNLP 2024, pages 374–390, 2024
2024
- [43]
-
[44]
Mllms know where to look: Training-free perception of small visual details with multimodal llms
Mahyar Khayatkhoei, Prateek Chhikara, Filip Ilievski, et al. Mllms know where to look: Training-free perception of small visual details with multimodal llms. InInternational Confer- ence on Learning Representations, volume 2025, pages 68194–68213, 2025
2025
-
[45]
Wang et al
H. Wang et al. ASPO: Adaptive sentence-level preference optimization for multimodal large language models. InFindings of the Association for Computational Linguistics (ACL), 2025
2025
-
[46]
X. Yang et al. OPA-DPO: On-policy alignment for preference optimization.arXiv preprint arXiv:2501.09695, 2025. 13
arXiv 2025
- [47]
-
[48]
S. Shukla et al. SymPO: Symmetric preference optimization for vision-language models.arXiv preprint arXiv:2506.11712, 2025
arXiv 2025
-
[49]
Hein et al
D. Hein et al. CheXalign: Preference fine-tuning in chest X-ray interpretation models without human feedback. InProceedings of the Association for Computational Linguistics (ACL), 2025
2025
-
[50]
Liu et al
Y . Liu et al. R-DPO: Recursive direct preference optimization for medical vision-language models. InMedical Image Computing and Computer Assisted Intervention (MICCAI), 2025. 14 A Impact Statement The broader impact of this work lies in its potential to enhance the reliability and factual consistency of AI-driven medical diagnostics. Our framework advanc...
2025
-
[51]
Preserve the model’s language so the final answer is visible in context
**answer_sentence**: The minimal phrase or clause from the model’s answer that states the final answer, using the model’s exact wording. Preserve the model’s language so the final answer is visible in context. Do not include extra clauses that follow
-
[52]
Use as few words as possible (the first occurrence of the conclusive answer)
**final_answer**: Locate and extract the final answer to the question from the model’s answer. Use as few words as possible (the first occurrence of the conclusive answer)
-
[53]
**is_correct**: true if the final answer is correct given the ground truth, false otherwise
-
[54]
answer_sentence
**opposite_answer**: Modify the answer sentence as little as possible to make a medically plausible alternative for the question. Respond only with valid JSON in this exact shape: {"answer_sentence": "...", "final_answer": "...", "is_correct": true or false, "opposite_answer": "..."} {Stage 2: Prompt used in VQA answer difference localization.} You are gi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.