Everything at Every Scale: Scale-Invariant Diffusion with Continuous Super-Resolution
Pith reviewed 2026-06-29 22:55 UTC · model grok-4.3
The pith
A single unconditional diffusion model performs both image generation and continuous super-resolution by varying only the starting timestep.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SKILD is a scale-invariant k-space image learning diffusion model whose forward process attenuates image content from fine to coarse scales while injecting spectrum-matched Gaussian noise, making scale an explicit coordinate of the diffusion dynamics. The same trained reverse process performs generation and continuous super-resolution by varying only the starting timestep, with no task-specific architecture, no conditioning branch, no classifier-free guidance, and no retraining per scale factor.
What carries the argument
The scale-invariant k-space forward process that attenuates content from fine to coarse scales while adding spectrum-matched noise, turning scale into an explicit coordinate of the diffusion dynamics.
If this is right
- The same checkpoint reaches FID 2.65 and Inception Score 9.63 on unconditional CIFAR-10 generation.
- The checkpoint performs 2x to 8x super-resolution on ImageNet and outperforms conditional models on perceptual metrics.
- The checkpoint reconstructs critical Ising models with connected four-point correlations that closely track ground truth.
- No retraining or architecture changes are needed when switching between generation and arbitrary-scale super-resolution.
Where Pith is reading between the lines
- The method could extend naturally to other domains where data exhibit scale invariance, such as physical simulations at multiple resolutions.
- Continuous variation of the starting timestep suggests the model could support arbitrary non-integer scale factors without interpolation artifacts.
- If the k-space attenuation truly encodes scale as a coordinate, the approach might allow zero-shot transfer to related multi-scale tasks like denoising at intermediate resolutions.
Load-bearing premise
The forward process that attenuates image content from fine to coarse scales while injecting spectrum-matched Gaussian noise makes scale an explicit coordinate that the reverse process can exploit without task-specific modifications or hidden conditioning.
What would settle it
A test showing that the same checkpoint, when started at different timesteps, fails to match the perceptual quality of scale-specific conditional models on 2x through 8x super-resolution of ImageNet images while also matching unconditional generation FID.
Figures



read the original abstract
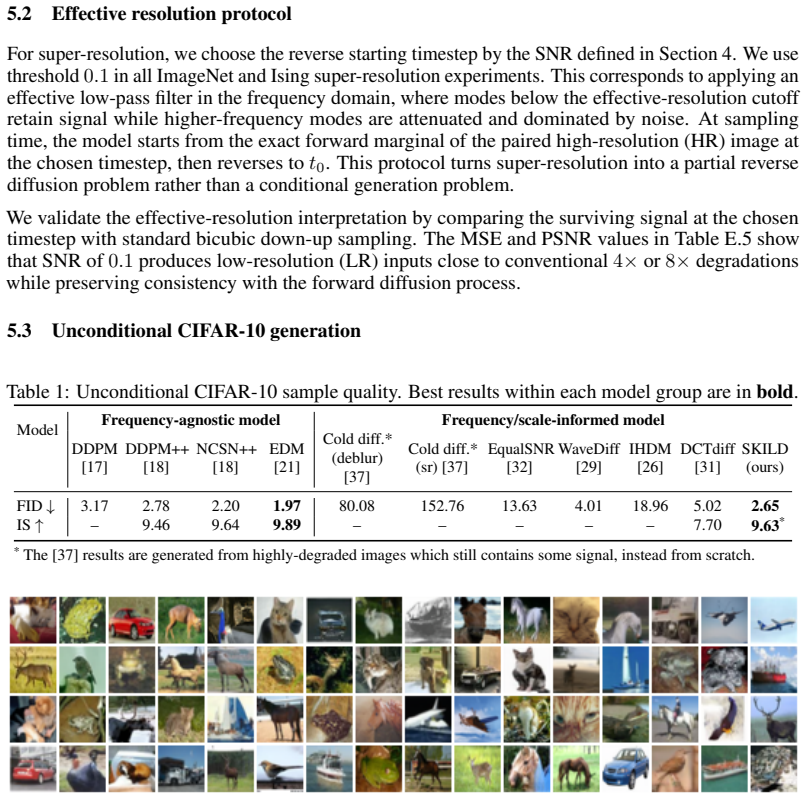
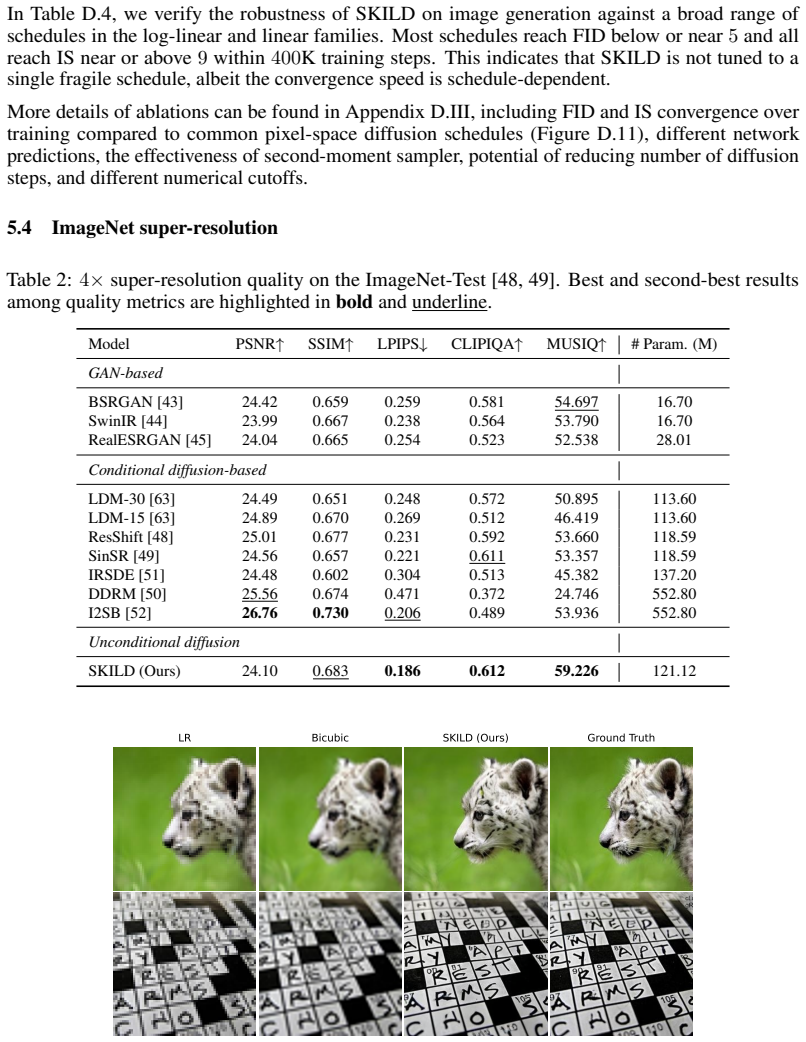
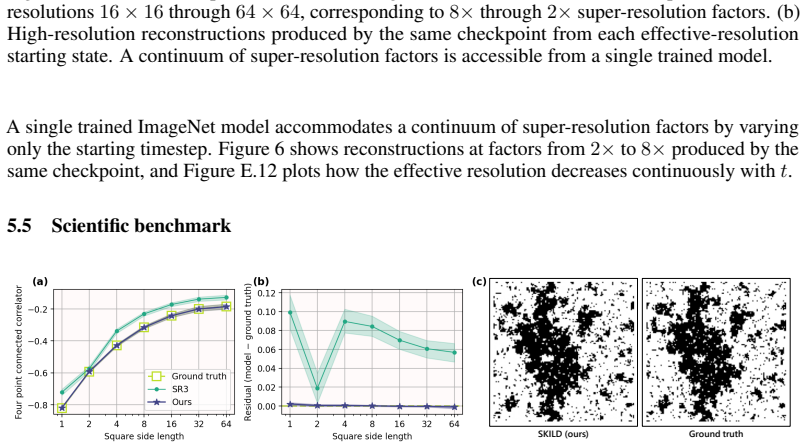
Creating images from noise is image generation; reconstructing fine details from coarse inputs is super-resolution. Despite their practical differences, both can be understood as reversing information loss across scales. We introduce $\textbf{SKILD}$, a $\textbf{S}$cale-invariant $\textbf{K}$-Space $\textbf{I}$mage $\textbf{L}$earning $\textbf{D}$iffusion model that unifies generation and continuous super-resolution within a single unconditional framework. Both natural images and critical physical systems exhibit scale invariance, and we leverage it to design a forward process that attenuates image content from fine to coarse scales while injecting spectrum-matched Gaussian noise, making scale an explicit coordinate of the diffusion dynamics. The same trained reverse process performs generation and continuous super-resolution by varying only the starting timestep: $\textit{no task-specific architecture, no conditioning branch, no classifier-free guidance, no retraining per scale factor}$. Empirically, SKILD reaches FID $2.65$ and Inception Score $9.63$ on unconditional CIFAR-10, performs $2\times$--$8\times$ super-resolution on ImageNet from a single unconditional checkpoint while outperforming conditional models across perceptual metrics, and reconstructs critical Ising models whose connected four-point correlations closely track the ground truth.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SKILD, a scale-invariant k-space diffusion model that unifies unconditional image generation and continuous super-resolution. A forward process attenuates image content across scales while injecting spectrum-matched Gaussian noise, making scale an explicit coordinate; the identical trained reverse process then performs both tasks by varying only the starting timestep, with no task-specific architecture, conditioning, or per-scale retraining. Reported results include FID 2.65 and IS 9.63 on unconditional CIFAR-10, competitive 2×–8× super-resolution on ImageNet from a single checkpoint, and reconstruction of Ising-model four-point correlations.
Significance. If the distributional alignment between arbitrary low-resolution inputs and the forward-process states holds, the work would provide a substantive unification of two core inverse problems in diffusion models, removing the need for conditioning branches or task-specific training. The extension to critical physical systems adds cross-domain value, and the single-checkpoint SR results would be practically useful if robust. The absence of explicit verification of the alignment assumption in the abstract, however, leaves the central unification claim difficult to assess from the provided summary alone.
major comments (3)
- [Forward process definition (likely §3)] The unification claim rests on the premise that an arbitrary low-resolution input (e.g., bicubic-downsampled ImageNet at 4×) is statistically interchangeable with the state reached by applying the forward process (k-space attenuation + spectrum-matched noise) to its high-resolution counterpart at the matching t. No quantitative evidence—such as spectrum histograms, Wasserstein distance, or KL divergence between the two distributions—is referenced in the abstract or summary; without this, the reverse process is solving a different inverse problem than the one on which it was trained.
- [Experiments (§4, ImageNet SR and CIFAR-10)] Abstract reports strong SR metrics from a single unconditional checkpoint but provides no ablation on the spectrum-matching parameters, no error bars on FID/IS, and no direct comparison of starting-point distributions for real low-res inputs versus forward-process trajectories. These omissions make it impossible to isolate whether performance gains derive from the scale-invariant design or from other implementation choices.
- [Physical systems experiment (likely §4.3)] The Ising four-point correlation results are presented as closely tracking ground truth, yet the abstract supplies no details on how the lattice data are embedded into the image diffusion framework, what (if any) modifications to the k-space operator are required, or whether the same unconditional checkpoint is used without retraining.
minor comments (2)
- [Abstract] The abstract would benefit from a single-sentence statement of the forward-process equation or the precise form of spectrum matching to allow readers to assess the scale-invariance claim immediately.
- [Method] Notation for the timestep coordinate t and the scale parameter should be introduced consistently when the forward process is first defined.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below with clarifications drawn from the full manuscript and indicate revisions that will strengthen the presentation of the unification claim and experimental details.
read point-by-point responses
-
Referee: The unification claim rests on the premise that an arbitrary low-resolution input (e.g., bicubic-downsampled ImageNet at 4×) is statistically interchangeable with the state reached by applying the forward process (k-space attenuation + spectrum-matched noise) to its high-resolution counterpart at the matching t. No quantitative evidence—such as spectrum histograms, Wasserstein distance, or KL divergence between the two distributions—is referenced in the abstract or summary; without this, the reverse process is solving a different inverse problem than the one on which it was trained.
Authors: Section 3 of the full manuscript presents spectrum histograms and qualitative comparisons supporting the alignment by construction via the k-space attenuation and spectrum-matched noise. We agree that explicit quantitative metrics would make the central claim easier to assess from the abstract alone, and we will add KL divergence and Wasserstein distance calculations between the low-resolution input distributions and forward-process states in the revised manuscript. revision: yes
-
Referee: Experiments (§4, ImageNet SR and CIFAR-10) Abstract reports strong SR metrics from a single unconditional checkpoint but provides no ablation on the spectrum-matching parameters, no error bars on FID/IS, and no direct comparison of starting-point distributions for real low-res inputs versus forward-process trajectories. These omissions make it impossible to isolate whether performance gains derive from the scale-invariant design or from other implementation choices.
Authors: Ablations on spectrum-matching parameters appear in the supplementary material, and FID/IS values are computed over multiple random seeds. We will move key ablations to the main text, explicitly include error bars on the reported metrics, and add a figure directly comparing the starting-point distributions of real low-resolution inputs versus forward-process trajectories to better isolate the contribution of the scale-invariant design. revision: yes
-
Referee: The Ising four-point correlation results are presented as closely tracking ground truth, yet the abstract supplies no details on how the lattice data are embedded into the image diffusion framework, what (if any) modifications to the k-space operator are required, or whether the same unconditional checkpoint is used without retraining.
Authors: Section 4.3 describes embedding the Ising lattice configurations as grayscale images, with no modifications to the k-space operator and using the identical unconditional checkpoint without retraining. We will add a concise summary of this experimental setup to the abstract and introduction in the revision. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper introduces a new forward process (k-space attenuation plus spectrum-matched noise) that explicitly encodes scale as timestep t, trains a single unconditional reverse network on it, and reports that varying only the starting t enables both generation and continuous SR. This chain rests on the explicit construction of the forward operator and on external empirical metrics (FID, IS, perceptual scores on CIFAR-10/ImageNet/Ising), not on any fitted parameter being renamed as a prediction, self-definitional equations, or load-bearing self-citations. No quoted step reduces the central claim to its own inputs by construction; the distributional-alignment prerequisite raised by the skeptic is a correctness question, not a circularity reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- spectrum-matching parameters
axioms (1)
- domain assumption Natural images and critical physical systems exhibit scale invariance.
Reference graph
Works this paper leans on
-
[1]
Field, D. J. Relations between the statistics of natural images and the response properties of cortical cells.J. Opt. Soc. Am. A4, 2379–2394 (1987). URL https://opg.optica.org/ josaa/abstract.cfm?URI=josaa-4-12-2379
1987
-
[2]
Ruderman, D. L. The statistics of natural images.Network: computation in neural systems5, 517 (1994)
1994
-
[3]
van der Schaaf, A. & van Hateren, J. Modelling the power spectra of natural images: Statistics and information.Vision Research36, 2759–2770 (1996). URL https://www. sciencedirect.com/science/article/pii/0042698996000028
-
[4]
Simoncelli, E. P. & Olshausen, B. A. Natural image statistics and neural representation.Annual review of neuroscience24, 1193–1216 (2001)
2001
-
[5]
Wilson, K. G. & Kogut, J. The renormalization group and the epsilon expansion.Physics Reports12, 75–199 (1974)
1974
-
[6]
A., Polyakov, A
Belavin, A. A., Polyakov, A. M. & Zamolodchikov, A. B. Infinite conformal symmetry in two-dimensional quantum field theory.Nuclear Physics B241, 333–380 (1984)
1984
-
[7]
& Hinton, G
Krizhevsky, A. & Hinton, G. Learning multiple layers of features from tiny images. Tech. Rep., University of Toronto (2009)
2009
-
[8]
In2009 IEEE Conference on Computer Vision and Pattern Recognition, 248–255 (2009)
Deng, J.et al.ImageNet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, 248–255 (2009)
2009
-
[9]
Scale-space filtering: A new approach to multi-scale description
Witkin, A. Scale-space filtering: A new approach to multi-scale description. InICASSP ’84. IEEE International Conference on Acoustics, Speech, and Signal Processing, vol. 9, 150–153 (1984)
1984
-
[10]
Koenderink, J. J. The structure of images.Biological Cybernetics50, 363–370 (1984). URL https://doi.org/10.1007/BF00336961
-
[11]
Scale-space theory: A basic tool for analyzing structures at different scales
Lindeberg, T. Scale-space theory: A basic tool for analyzing structures at different scales. Journal of applied statistics21, 225–270 (1994)
1994
-
[12]
Feature detection with automatic scale selection.International journal of computer vision30, 79–116 (1998)
Lindeberg, T. Feature detection with automatic scale selection.International journal of computer vision30, 79–116 (1998)
1998
-
[13]
Lowe, D. G. Distinctive image features from scale-invariant keypoints.International Journal of Computer Vision60, 91–110 (2004). URL https://doi.org/10.1023/B: VISI.0000029664.99615.94
work page doi:10.1023/b: 2004
-
[14]
Burt, P. J. & Adelson, E. H. The laplacian pyramid as a compact image code. InReadings in computer vision, 671–679 (Elsevier, 1987)
1987
-
[15]
Olshausen, B. A. & Field, D. J. Natural image statistics and efficient coding.Network: Compu- tation in Neural Systems7, 333 (1996). URL https://doi.org/10.1088/0954-898X/7/ 2/014
-
[16]
& Ganguli, S
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N. & Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, 2256–2265 (pmlr, 2015)
2015
-
[17]
& Abbeel, P
Ho, J., Jain, A. & Abbeel, P. Denoising diffusion probabilistic models.Advances in neural information processing systems33, 6840–6851 (2020). 10
2020
-
[18]
Song, Y .et al.Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[19]
Nichol, A. Q. & Dhariwal, P. Improved denoising diffusion probabilistic models. InInterna- tional conference on machine learning, 8162–8171 (PMLR, 2021)
2021
-
[20]
& Nichol, A
Dhariwal, P. & Nichol, A. Diffusion models beat gans on image synthesis.Advances in neural information processing systems34, 8780–8794 (2021)
2021
-
[21]
& Laine, S
Karras, T., Aittala, M., Aila, T. & Laine, S. Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems35, 26565–26577 (2022)
2022
-
[22]
On the importance of noise scheduling for diffusion models.arXiv preprint arXiv:2301.10972(2023)
Chen, T. On the importance of noise scheduling for diffusion models.arXiv preprint arXiv:2301.10972(2023)
-
[23]
Ho, J.et al.Cascaded diffusion models for high fidelity image generation.Journal of Machine Learning Research23, 1–33 (2022)
2022
-
[24]
arXiv preprint arXiv:2309.03350(2023)
Teng, J.et al.Relay diffusion: Unifying diffusion process across resolutions for image synthesis. arXiv preprint arXiv:2309.03350(2023)
-
[25]
Cotler, J. & Rezchikov, S. Renormalizing diffusion models.arXiv preprint arXiv:2308.12355 (2023)
-
[26]
Rissanen, S., Heinonen, M. & Solin, A. Generative modelling with inverse heat dissipation. arXiv preprint arXiv:2206.13397(2022)
-
[27]
Masuki, K. & Ashida, Y . Generative diffusion model with inverse renormalization group flows. arXiv preprint arXiv:2501.09064(2025)
-
[28]
& Avestimehr, S
Sheshmani, A., You, Y .-Z., Buyukates, B., Ziashahabi, A. & Avestimehr, S. Renormalization group flow, optimal transport, and diffusion-based generative model.Physical Review E111, 015304 (2025)
2025
-
[29]
& Mallat, S
Guth, F., Coste, S., De Bortoli, V . & Mallat, S. Wavelet score-based generative modeling. Advances in neural information processing systems35, 478–491 (2022)
2022
-
[30]
& Tran, A
Phung, H., Dao, Q. & Tran, A. Wavelet diffusion models are fast and scalable image generators. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 10199–10208 (2023)
2023
-
[31]
arXiv preprint arXiv:2412.15032(2024)
Ning, M.et al.Dctdiff: Intriguing properties of image generative modeling in the dct space. arXiv preprint arXiv:2412.15032(2024)
- [32]
- [33]
-
[34]
B., Frolov, S., Raue, F., Palacio, S
Moser, B. B., Frolov, S., Raue, F., Palacio, S. & Dengel, A. Waving goodbye to low-res: A diffusion-wavelet approach for image super-resolution. In2024 International Joint Conference on Neural Networks (IJCNN), 1–8 (IEEE, 2024)
2024
-
[35]
& Liu, J
Gao, X., Xu, Z., Zhao, J. & Liu, J. Frequency-controlled diffusion model for versatile text-guided image-to-image translation. InProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, 1824–1832 (2024)
2024
-
[36]
& Cattin, P
Friedrich, P., Wolleb, J., Bieder, F., Durrer, A. & Cattin, P. C. Wdm: 3d wavelet diffusion models for high-resolution medical image synthesis. InMICCAI workshop on deep generative models, 11–21 (Springer, 2024)
2024
-
[37]
Bansal, A.et al.Cold diffusion: Inverting arbitrary image transforms without noise.Advances in Neural Information Processing Systems36, 41259–41282 (2023). 11
2023
-
[38]
& Wang, L
Tian, K., Jiang, Y ., Yuan, Z., Peng, B. & Wang, L. Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems 37, 84839–84865 (2024)
2024
-
[39]
& Pasztor, E
Freeman, W. & Pasztor, E. Learning low-level vision. InProceedings of the Seventh IEEE International Conference on Computer Vision, vol. 2, 1182–1189 vol.2 (1999)
1999
-
[40]
C., He, K
Dong, C., Loy, C. C., He, K. & Tang, X. Image super-resolution using deep convolutional networks.IEEE transactions on pattern analysis and machine intelligence38, 295–307 (2015)
2015
-
[41]
& Mu Lee, K
Lim, B., Son, S., Kim, H., Nah, S. & Mu Lee, K. Enhanced deep residual networks for single image super-resolution. InProceedings of the IEEE conference on computer vision and pattern recognition workshops, 136–144 (2017)
2017
-
[42]
In Proceedings of the European conference on computer vision (ECCV) workshops, 0–0 (2018)
Wang, X.et al.Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European conference on computer vision (ECCV) workshops, 0–0 (2018)
2018
-
[43]
& Timofte, R
Zhang, K., Liang, J., Van Gool, L. & Timofte, R. Designing a practical degradation model for deep blind image super-resolution. InProceedings of the IEEE/CVF international conference on computer vision, 4791–4800 (2021)
2021
-
[44]
InProceedings of the IEEE/CVF international conference on computer vision, 1833–1844 (2021)
Liang, J.et al.Swinir: Image restoration using swin transformer. InProceedings of the IEEE/CVF international conference on computer vision, 1833–1844 (2021)
2021
-
[45]
& Shan, Y
Wang, X., Xie, L., Dong, C. & Shan, Y . Real-esrgan: Training real-world blind super-resolution with pure synthetic data. InProceedings of the IEEE/CVF international conference on computer vision, 1905–1914 (2021)
1905
-
[46]
Saharia, C.et al.Image super-resolution via iterative refinement.IEEE transactions on pattern analysis and machine intelligence45, 4713–4726 (2022)
2022
-
[47]
Li, H.et al.Srdiff: Single image super-resolution with diffusion probabilistic models.Neuro- computing479, 47–59 (2022)
2022
-
[48]
& Loy, C
Yue, Z., Wang, J. & Loy, C. C. Resshift: Efficient diffusion model for image super-resolution by residual shifting.Advances in neural information processing systems36, 13294–13307 (2023)
2023
-
[49]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 25796–25805 (2024)
Wang, Y .et al.Sinsr: diffusion-based image super-resolution in a single step. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 25796–25805 (2024)
2024
-
[50]
& Song, J
Kawar, B., Elad, M., Ermon, S. & Song, J. Denoising diffusion restoration models.Advances in neural information processing systems35, 23593–23606 (2022)
2022
-
[51]
Luo, Z., Gustafsson, F. K., Zhao, Z., Sjölund, J. & Schön, T. B. Image restoration with mean-reverting stochastic differential equations.arXiv preprint arXiv:2301.11699(2023)
- [52]
-
[53]
Crystal statistics
Onsager, L. Crystal statistics. i. a two-dimensional model with an order-disorder transition. Physical Review65, 117–149 (1944)
1944
-
[54]
& Hoyer, P
Hyvrinen, A., Hurri, J. & Hoyer, P. O.Natural Image Statistics: A Probabilistic Approach to Early Computational Vision.(Springer Publishing Company, Incorporated, 2009), 1st edn
2009
-
[55]
& Rao, K
Ahmed, N., Natarajan, T. & Rao, K. R. Discrete cosine transform.IEEE Transactions on ComputersC-23, 90–93 (1974)
1974
-
[56]
Collective monte carlo updating for spin systems.Physical Review Letters62, 361–364 (1989)
Wolff, U. Collective monte carlo updating for spin systems.Physical Review Letters62, 361–364 (1989)
1989
-
[57]
& Hochreiter, S
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B. & Hochreiter, S. GANs trained by a two time-scale update rule converge to a local nash equilibrium. InAdvances in Neural Information Processing Systems, vol. 30 (2017). 12
2017
-
[58]
InAdvances in Neural Information Processing Systems, vol
Salimans, T.et al.Improved techniques for training GANs. InAdvances in Neural Information Processing Systems, vol. 29 (2016)
2016
-
[59]
C., Sheikh, H
Wang, Z., Bovik, A. C., Sheikh, H. R. & Simoncelli, E. P. Image quality assessment: From error visibility to structural similarity.IEEE Transactions on Image Processing13, 600–612 (2004)
2004
-
[60]
A., Shechtman, E
Zhang, R., Isola, P., Efros, A. A., Shechtman, E. & Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 586–595 (2018)
2018
-
[61]
& Yang, F
Ke, J., Wang, Q., Wang, Y ., Milanfar, P. & Yang, F. MUSIQ: Multi-scale image quality transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision, 5148–5157 (2021)
2021
-
[62]
Wang, J., Chan, K. C. K. & Loy, C. C. Exploring CLIP for assessing the look and feel of images. InProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, 2555–2563 (2023)
2023
-
[63]
& Ommer, B
Rombach, R., Blattmann, A., Lorenz, D., Esser, P. & Ommer, B. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 10684–10695 (2022)
2022
-
[64]
Efthymiou, S., Beach, M. J. S. & Melko, R. G. Super-resolving the ising model with convolu- tional neural networks.Physical Review B99, 075113 (2019)
2019
-
[65]
Shiina, K., Mori, H., Tomita, Y ., Lee, H. K. & Okabe, Y . Inverse renormalization group based on image super-resolution using deep convolutional networks.Scientific Reports11, 9617 (2021). 13 A DDPM formulation This appendix derives the DDPM posterior used in the main text and lists the training targets supported by our implementation. Figure A.8 shows a...
-
[66]
Initialize the cluster and the active frontier to contain only this seed site
Choose a seed site uniformly at random and let s⋆ be its spin. Initialize the cluster and the active frontier to contain only this seed site
-
[67]
If a candidate site touches k∈ {1,2,3,4} frontier sites, add it to the cluster with probability 1−(1−p) k
Given the current frontier, inspect nearest-neighbor sites with spin s⋆ that are not already in the cluster. If a candidate site touches k∈ {1,2,3,4} frontier sites, add it to the cluster with probability 1−(1−p) k. This is equivalent to independently activating each bond from a frontier site with probabilityp
-
[68]
Set the newly added sites as the next frontier and repeat the previous step until the frontier is empty
-
[69]
We run several independent chains in parallel, each initialized with independent random spins in {−1,+1} 128×128
Flip every spin in the completed cluster:s i ← −s i. We run several independent chains in parallel, each initialized with independent random spins in {−1,+1} 128×128. Every chain is thermalized for 2,000 Wolff transitions. After thermalization, we save the current configuration from each chain whenever all of them have accumulated at least2L2 flipped spin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.