Soft-Prompt Tuning for Fair and Efficient LLM Benchmark Evaluation
Pith reviewed 2026-06-27 09:51 UTC · model grok-4.3
The pith
Soft-prompt tuning adapts base LLMs to benchmark formats by optimizing just 10 vectors, revealing knowledge missed by standard prompting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
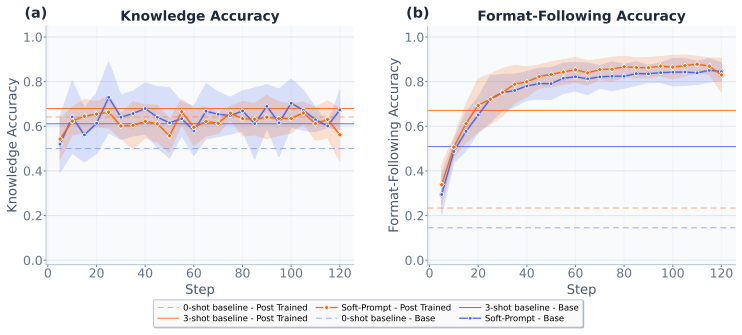
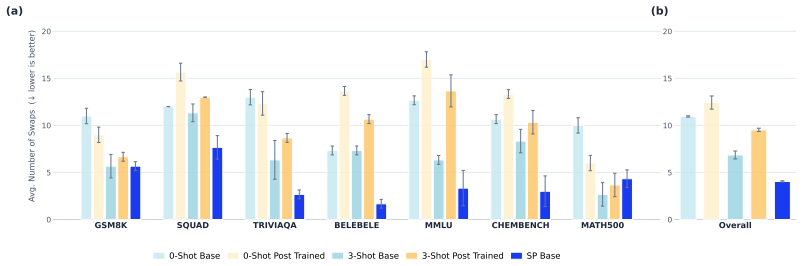
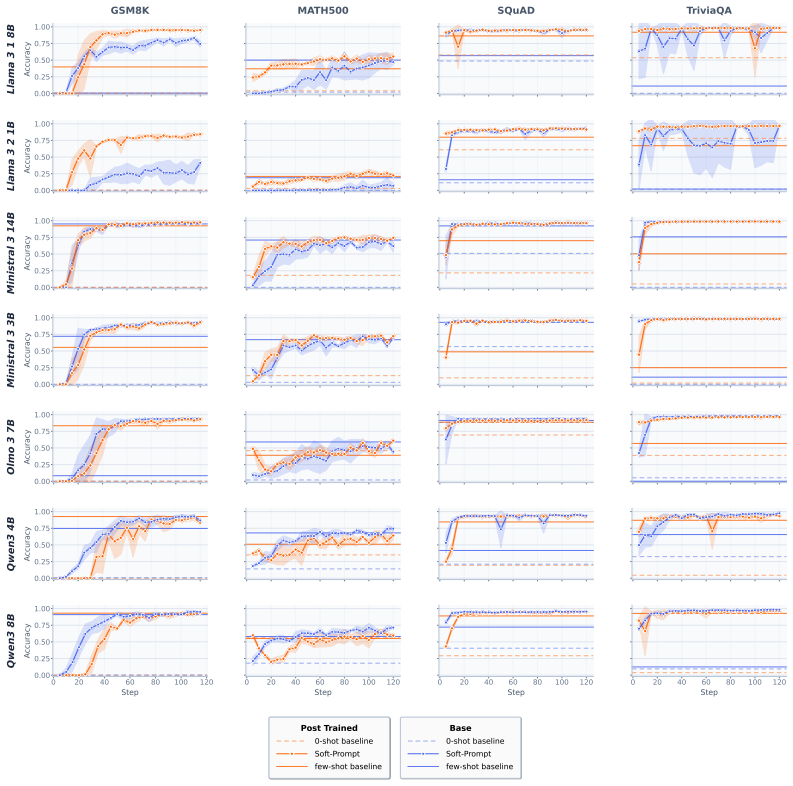
By optimizing only 10 soft-prompt vectors over roughly 640 samples, soft-prompt tuning saturates format-following ability in base models, allowing their underlying knowledge to be accurately measured on benchmarks. This approach outperforms zero- and few-shot prompting in surfacing correct answers, benefits even post-trained models for better compliance, and provides rankings that correlate more reliably with fully post-trained model performance across multiple models and datasets.
What carries the argument
Soft-prompt tuning of a small set of 10 prompt vectors that adapt the model to benchmark-specific formats without changing the core parameters.
If this is right
- Base models from different pre-training recipes can be ranked fairly using the same benchmarks.
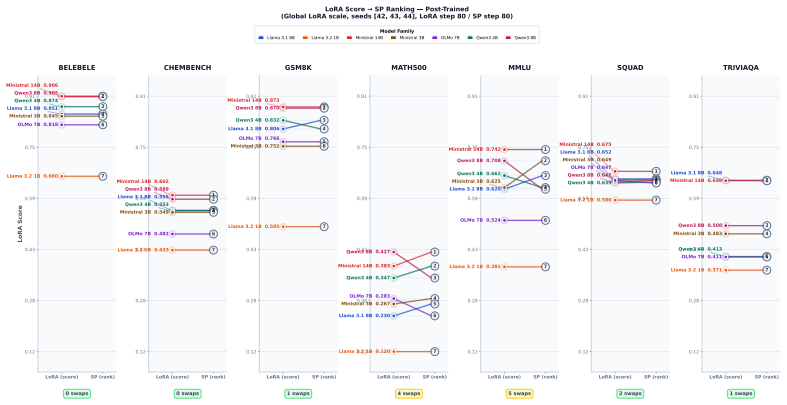
- Soft-prompted base model scores predict post-trained rankings better than standard prompting methods.
- Format-following saturates after about 80 tuning steps, making the method efficient.
- Post-trained models can still gain from soft-prompts to maximize compliance.
Where Pith is reading between the lines
- Developers could use this to quickly test many pre-training variants before committing to expensive post-training.
- This might extend to other structured output tasks beyond benchmarks.
- Metrics that separate format compliance from knowledge accuracy could become standard in evaluation protocols.
Load-bearing premise
That optimizing the soft prompts only teaches the model to format answers correctly without altering or biasing its underlying knowledge of the benchmark content.
What would settle it
Observe whether soft-prompt tuned base model performance on a benchmark correlates with the same model's performance after full post-training on that benchmark; lack of correlation would undermine the proxy claim.
Figures













read the original abstract
Benchmark scores often misrepresent a large language model's (LLM's) knowledge, because they rely, e.g., on the model's ability to follow specific formatting requirements. This especially penalizes base models that may know the correct answers but lack the ability -- typically introduced in post-training -- to structure them as instructed. To overcome this, we propose soft-prompt tuning, an efficient, fair, and architecture-agnostic model evaluation. By optimizing only 10 soft-prompt vectors (roughly 0.0006% parameters for a 7B model) over a short tuning period, we adapt models to specific benchmark formats, closing gaps in format-following and ensuring that underlying knowledge is accurately reflected in benchmark scores. This allows one to fairly compare different base models -- trained with various pre-training recipes -- on benchmarks without the need for full post-training. We evaluated soft-prompt tuning across 7 models and 7 datasets. The results show that (a) soft-prompt tuning saturates format-following within 80 steps (~640 samples) making it highly efficient, (b) soft-prompt tuning significantly outperforms zero- and few-shot prompting, surfacing base model knowledge that standard prompting misses, that (c) even post-trained models can benefit from soft-prompts to maximize format compliance, and that (d) soft-prompted base model performance predicts post-trained model rankings more reliably than zero- and few-shot baselines, offering a low-cost proxy for downstream model quality. Our contributions include (1) metrics which disentangle format-following and knowledge accuracy, (2) a fairer benchmarking protocol of LLM knowledge, and (3) a cost- and memory-effective recipe to identify optimal pre-training strategies early in LLM development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes soft-prompt tuning—optimizing only 10 soft-prompt vectors (~0.0006% of parameters) on ~640 samples—as an efficient, architecture-agnostic method to adapt LLMs to benchmark output formats. This is claimed to close format-following gaps in base models, surface knowledge missed by zero/few-shot prompting, allow fair comparison of base models without full post-training, and provide a low-cost proxy for predicting post-trained model rankings. The work evaluates the approach on 7 models and 7 datasets and introduces metrics to disentangle format compliance from knowledge accuracy.
Significance. If the central assumption holds—that soft-prompt optimization affects only formatting without shifting content-bearing logits or biasing knowledge distributions—the method would offer a practical, low-cost protocol for fairer base-model evaluation early in pre-training. The multi-model, multi-dataset empirical scope and the explicit disentangling metrics are positive elements; however, the absence of detailed controls leaves the practical significance uncertain.
major comments (3)
- [Abstract / §4] Abstract and §4 (Experiments): The claim that soft-prompt tuning 'only' adapts format without altering knowledge rests on the introduced disentangling metrics, yet the manuscript provides no equations, pseudocode, or validation procedure for these metrics (e.g., no control set of questions already answered correctly in zero-shot format, no measurement of logit shifts on content tokens before/after tuning).
- [§3 / §4] §3 (Method) and §4: No description is given of how the ~640 tuning samples are selected relative to the evaluation sets, whether any overlap or leakage exists, or what statistical tests and error analysis support the reported gains in format-following and ranking prediction.
- [§4.3] §4.3 (Ranking prediction): The assertion that soft-prompted base-model performance predicts post-trained rankings 'more reliably' lacks reported correlation coefficients, confidence intervals, or ablation against stronger few-shot baselines with format instructions, making the comparative claim difficult to assess.
minor comments (2)
- [§3] Notation for the 10 soft-prompt vectors and their initialization is introduced without a clear equation or diagram in the methods section.
- [Figures / Tables] Figure captions and table headers should explicitly state the number of runs and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract / §4] Abstract and §4 (Experiments): The claim that soft-prompt tuning 'only' adapts format without altering knowledge rests on the introduced disentangling metrics, yet the manuscript provides no equations, pseudocode, or validation procedure for these metrics (e.g., no control set of questions already answered correctly in zero-shot format, no measurement of logit shifts on content tokens before/after tuning).
Authors: We agree that the presentation of the disentangling metrics requires additional formalization. In the revised manuscript we will add the defining equations, pseudocode for computation, a validation procedure using control sets of zero-shot correct questions, and explicit measurements of logit shifts on content tokens before versus after tuning. revision: yes
-
Referee: [§3 / §4] §3 (Method) and §4: No description is given of how the ~640 tuning samples are selected relative to the evaluation sets, whether any overlap or leakage exists, or what statistical tests and error analysis support the reported gains in format-following and ranking prediction.
Authors: We will expand §3 with an explicit description of the sample selection procedure and confirm that the ~640 tuning examples are drawn from a held-out partition with zero overlap to any evaluation set. In §4 we will add the relevant statistical tests (paired significance tests) and error analysis for the format-following and ranking results. revision: yes
-
Referee: [§4.3] §4.3 (Ranking prediction): The assertion that soft-prompted base-model performance predicts post-trained rankings 'more reliably' lacks reported correlation coefficients, confidence intervals, or ablation against stronger few-shot baselines with format instructions, making the comparative claim difficult to assess.
Authors: We will augment §4.3 with Pearson and Spearman correlation coefficients together with confidence intervals. We will also add an ablation that directly compares soft-prompt tuning against few-shot prompting augmented with explicit format instructions. revision: yes
Circularity Check
No circularity: purely empirical protocol with no derivations or self-referential reductions
full rationale
The paper presents an empirical method (soft-prompt tuning on ~640 samples) and reports benchmark results across models and datasets. No equations, derivations, or parameter-fitting steps are described that would reduce any claimed prediction or metric to the tuning inputs by construction. The disentangling metrics are introduced as contributions but are not shown to be tautological with the tuning procedure itself. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify core claims. The work is therefore self-contained as an experimental protocol whose validity rests on external falsifiability rather than definitional equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Belebele Benchmark: a Parallel Reading Comprehension Dataset in 122 Language Variants
Lucas Bandarkar, Davis Liang, Benjamin Muller, Mikel Artetxe, Satya Narayan Shukla, Donald Husa, Naman Goyal, Abhinandan Krishnan, Luke Zettlemoyer, and Madian Khabsa. The Belebele Benchmark : a Parallel Reading Comprehension Dataset in 122 Language Variants . In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meetin...
-
[2]
Stella Biderman, Hailey Schoelkopf, Lintang Sutawika, Leo Gao, Jonathan Tow, Baber Abbasi, Alham Fikri Aji, Pawan Sasanka Ammanamanchi, Sidney Black, Jordan Clive, Anthony DiPofi, Julen Etxaniz, Benjamin Fattori, Jessica Zosa Forde, Charles Foster, Jeffrey Hsu, Mimansa Jaiswal, Wilson Y. Lee, Haonan Li, Charles Lovering, Niklas Muennighoff, Ellie Pavlick,...
Pith/arXiv arXiv 2024
-
[3]
Fine- Tune on the Format : First Improving Multiple - Choice Evaluation for Intermediate LLM Checkpoints
Alec Bunn, Sarah Wiegreffe, and Ben Bogin. Fine- Tune on the Format : First Improving Multiple - Choice Evaluation for Intermediate LLM Checkpoints . In Ofir Arviv, Miruna Clinciu, Kaustubh Dhole, Rotem Dror, Sebastian Gehrmann, Eliya Habba, Itay Itzhak, Simon Mille, Yotam Perlitz, Enrico Santus, João Sedoc, Michal Shmueli Scheuer, Gabriel Stanovsky, and ...
2025
-
[4]
On the Worst Prompt Performance of Large Language Models
Bowen Cao, Deng Cai, Zhisong Zhang, Yuexian Zou, and Wai Lam. On the Worst Prompt Performance of Large Language Models . November 2024. URL https://openreview.net/forum?id=Mi853QaJx6
2024
-
[5]
Scaling Laws for Predicting Downstream Performance in LLMs
Yangyi Chen, Binxuan Huang, Yifan Gao, Zhengyang Wang, Jingfeng Yang, and Heng Ji. Scaling Laws for Predicting Downstream Performance in LLMs . Transactions on Machine Learning Research, January 2025. ISSN 2835-8856. URL https://openreview.net/forum?id=PJUbMDkQVY
2025
-
[6]
Training Verifiers to Solve Math Word Problems , November 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training Verifiers to Solve Math Word Problems , November 2021. URL http://arxiv.org/abs/2110.14168. arXiv:2110.14168 [cs]
Pith/arXiv arXiv 2021
-
[7]
Selection via Proxy : Efficient Data Selection for Deep Learning
Cody Coleman, Christopher Yeh, Stephen Mussmann, Baharan Mirzasoleiman, Peter Bailis, Percy Liang, Jure Leskovec, and Matei Zaharia. Selection via Proxy : Efficient Data Selection for Deep Learning . September 2019. URL https://openreview.net/forum?id=HJg2b0VYDr
2019
-
[8]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, et al. Gemini 2.5: Pushing the Frontier with Advanced Reasoning , Multimodality , Long Context , and Next Generation Agentic Capabilities , December 2025. URL http://arxiv.org/abs/2507.06261. arXiv:2507.06261 [cs]
Pith/arXiv arXiv 2025
-
[9]
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenhao Xu, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Erhang Li, Fangqi Zhou, Fangyun Lin, Fucong Dai, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Ha...
Pith/arXiv arXiv 2025
-
[10]
QLoRA : Efficient Finetuning of Quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA : Efficient Finetuning of Quantized LLMs . November 2023. URL https://openreview.net/forum?id=OUIFPHEgJU
2023
-
[11]
Fernando Diaz and Michael Madaio. Scaling Laws Do Not Scale . Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, 7 0 (1): 0 341--357, October 2024. ISSN 3065-8365. doi:10.1609/aies.v7i1.31641. URL https://ojs.aaai.org/index.php/AIES/article/view/31641
-
[12]
Understanding Emergent Abilities of Language Models from the Loss Perspective
Zhengxiao Du, Aohan Zeng, Yuxiao Dong, and Jie Tang. Understanding Emergent Abilities of Language Models from the Loss Perspective . November 2024. URL https://openreview.net/forum?id=35DAviqMFo
2024
-
[13]
Sensitivity and Robustness of Large Language Models to Prompt Template in Japanese Text Classification Tasks
Chengguang Gan and Tatsunori Mori. Sensitivity and Robustness of Large Language Models to Prompt Template in Japanese Text Classification Tasks . In Chu-Ren Huang, Yasunari Harada, Jong-Bok Kim, Si Chen, Yu-Yin Hsu, Emmanuele Chersoni, Pranav A, Winnie Huiheng Zeng, Bo Peng, Yuxi Li, and Junlin Li, editors, Proceedings of the 37th Pacific Asia Conference ...
2023
-
[14]
The Llama 3 Herd of Models , November 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, et al. The Llama 3 Herd of Models , November 2024. URL http://arxiv.org/abs/2407.21783. arXiv:2407.21783 [cs]
Pith/arXiv arXiv 2024
-
[15]
DOVE : A Large - Scale Multi - Dimensional Predictions Dataset Towards Meaningful LLM Evaluation
Eliya Habba, Ofir Arviv, Itay Itzhak, Yotam Perlitz, Elron Bandel, Leshem Choshen, Michal Shmueli-Scheuer, and Gabriel Stanovsky. DOVE : A Large - Scale Multi - Dimensional Predictions Dataset Towards Meaningful LLM Evaluation . In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Findings of the Association for Computa...
-
[16]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring Massive Multitask Language Understanding . October 2020. URL https://openreview.net/forum?id=d7KBjmI3GmQ
2020
-
[17]
Parameter- Efficient Transfer Learning for NLP
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter- Efficient Transfer Learning for NLP . In Proceedings of the 36th International Conference on Machine Learning , pages 2790--2799. PMLR, May 2019. URL https://proceedings.mlr.press/v97/houlsby19a.html
2019
-
[18]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA : Low - Rank Adaptation of Large Language Models . October 2021. URL https://openreview.net/forum?id=nZeVKeeFYf9
2021
-
[19]
Scaling Laws for Downstream Task Performance of Large Language Models
Berivan Isik, Natalia Ponomareva, Hussein Hazimeh, Dimitris Paparas, Sergei Vassilvitskii, and Sanmi Koyejo. Scaling Laws for Downstream Task Performance of Large Language Models . April 2024. URL https://openreview.net/forum?id=QASo5yumt4
2024
-
[20]
Zico Kolter
Yiding Jiang, Allan Zhou, Zhili Feng, Sadhika Malladi, and J. Zico Kolter. Adaptive Data Optimization : Dynamic Sample Selection with Scaling Laws . October 2024. URL https://openreview.net/forum?id=aqok1UX7Z1
2024
-
[21]
Weld and Luke Zettlemoyer , editor =
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. TriviaQA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension . In Regina Barzilay and Min-Yen Kan, editors, Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pages 1601--1611, Vancouver, Canada, July ...
-
[22]
Donald E. Knuth. The Art of Computer Programming : Sorting and Searching , Volume 3 . Addison-Wesley Professional, April 1998. ISBN 978-0-321-63578-5. Google-Books-ID: cYULBAAAQBAJ
1998
-
[23]
Komal Kumar, Tajamul Ashraf, Omkar Thawakar, Rao Muhammad Anwer, Hisham Cholakkal, Mubarak Shah, Ming-Hsuan Yang, Phillip H. S. Torr, Fahad Shahbaz Khan, and Salman Khan. LLM Post - Training : A Deep Dive into Reasoning Large Language Models , March 2025. URL http://arxiv.org/abs/2502.21321. arXiv:2502.21321 [cs]
arXiv 2025
-
[24]
Brian Lester, Rami Al-Rfou, and Noah Constant. The Power of Scale for Parameter - Efficient Prompt Tuning . In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors, Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages 3045--3059, Online and Punta Cana, Dominican Republic, November 202...
-
[25]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Xiang Lisa Li and Percy Liang. Prefix- Tuning : Optimizing Continuous Prompts for Generation . In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors, Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing ( Volume 1: Long Papers ) , pa...
-
[26]
Let' s Verify Step by Step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let' s Verify Step by Step . In B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. Sun, editors, International Conference on Learning Representations , volume 2024, pages 39578--39601, 2024. URL https...
2024
-
[27]
Selecting Large Language Model to Fine -tune via Rectified Scaling Law
Haowei Lin, Baizhou Huang, Haotian Ye, Qinyu Chen, Zihao Wang, Sujian Li, Jianzhu Ma, Xiaojun Wan, James Zou, and Yitao Liang. Selecting Large Language Model to Fine -tune via Rectified Scaling Law . In Proceedings of the 41st International Conference on Machine Learning , pages 30080--30107. PMLR, July 2024. URL https://proceedings.mlr.press/v235/lin24j.html
2024
-
[28]
Alexander H. Liu, Kartik Khandelwal, Sandeep Subramanian, Victor Jouault, Abhinav Rastogi, Adrien Sadé, Alan Jeffares, Albert Jiang, Alexandre Cahill, Alexandre Gavaudan, Alexandre Sablayrolles, Amélie Héliou, Amos You, Andy Ehrenberg, Andy Lo, Anton Eliseev, Antonia Calvi, Avinash Sooriyarachchi, Baptiste Bout, Baptiste Rozière, Baudouin De Monicault, Cl...
Pith/arXiv arXiv 2026
-
[29]
Few- Shot Parameter - Efficient Fine - Tuning is Better and Cheaper than In - Context Learning
Haokun Liu, Derek Tam, Mohammed Muqeeth, Jay Mohta, Tenghao Huang, Mohit Bansal, and Colin Raffel. Few- Shot Parameter - Efficient Fine - Tuning is Better and Cheaper than In - Context Learning . Advances in Neural Information Processing Systems, 35: 0 1950--1965, December 2022 a . URL https://papers.nips.cc/paper_files/paper/2022/hash/0cde695b83bd186c1fd...
1950
-
[30]
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. Pre-train, Prompt , and Predict : A Systematic Survey of Prompting Methods in Natural Language Processing . ACM Comput. Surv., 55 0 (9): 0 195:1--195:35, January 2023. ISSN 0360-0300. doi:10.1145/3560815. URL https://dl.acm.org/doi/10.1145/3560815
-
[31]
P -Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks
Xiao Liu, Kaixuan Ji, Yicheng Fu, Weng Tam, Zhengxiao Du, Zhilin Yang, and Jie Tang. P- Tuning : Prompt Tuning Can Be Comparable to Fine -tuning Across Scales and Tasks . In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors, Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics ( Volume 2: Short Papers ) ,...
-
[32]
Rethinking Data Mixture for Large Language Models : A Comprehensive Survey and New Perspectives
Yajiao Liu, Congliang Chen, Junchi Yang, and Ruoyu Sun. Rethinking Data Mixture for Large Language Models : A Comprehensive Survey and New Perspectives . In Vera Demberg, Kentaro Inui, and Lluís Marquez, editors, Findings of the Association for Computational Linguistics : EACL 2026 , pages 275--289, Rabat, Morocco, March 2026 b . Association for Computati...
-
[33]
Do Xuan Long, Ngoc-Hai Nguyen, Tiviatis Sim, Hieu Dao, Shafiq Joty, Kenji Kawaguchi, Nancy F. Chen, and Min-Yen Kan. LLMs Are Biased Towards Output Formats ! Systematically Evaluating and Mitigating Output Format Bias of LLMs . In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors, Proceedings of the 2025 Conference of the Nations of the Americas Chapter of...
-
[34]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization . September 2018. URL https://openreview.net/forum?id=Bkg6RiCqY7
2018
-
[35]
Sheng Lu, Hendrik Schuff, and Iryna Gurevych. How are Prompts Different in Terms of Sensitivity ? In Kevin Duh, Helena Gomez, and Steven Bethard, editors, Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics : Human Language Technologies ( Volume 1: Long Papers ) , pages 5833--5856, Mexico City,...
-
[36]
Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. Rethinking the Role of Demonstrations : What Makes In - Context Learning Work ? In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors, Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages 11048--11064, A...
-
[37]
Adrian Mirza, Nawaf Alampara, Sreekanth Kunchapu, Martiño Ríos-García, Benedict Emoekabu, Aswanth Krishnan, Tanya Gupta, Mara Schilling-Wilhelmi, Macjonathan Okereke, Anagha Aneesh, Mehrdad Asgari, Juliane Eberhardt, Amir Mohammad Elahi, Hani M. Elbeheiry, María Victoria Gil, Christina Glaubitz, Maximilian Greiner, Caroline T. Holick, Tim Hoffmann, Abdelr...
-
[38]
Prateek Munjal, Clement Christophe, Ronnie Rajan, and Praveenkumar Kanithi. Do Instruction - Tuned Models Always Perform Better Than Base Models ? Evidence from Math and Domain - Shifted Benchmarks , January 2026. URL http://arxiv.org/abs/2601.13244. arXiv:2601.13244 [cs]
arXiv 2026
-
[39]
Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, Robert Berry, Saumya Malik, Saurabh Shah, Scott Geng, Shan...
Pith/arXiv arXiv 2026
-
[40]
Revisiting the Superficial Alignment Hypothesis , September 2024
Mohit Raghavendra, Vaskar Nath, and Sean Hendryx. Revisiting the Superficial Alignment Hypothesis , September 2024. URL http://arxiv.org/abs/2410.03717. arXiv:2410.03717 [cs]
arXiv 2024
-
[41]
doi:10.18653/V1/D16-1264 , url =
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD : 100,000+ Questions for Machine Comprehension of Text . In Jian Su, Kevin Duh, and Xavier Carreras, editors, Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , pages 2383--2392, Austin, Texas, November 2016. Association for Computational Linguis...
-
[42]
Quantifying Language Models ' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying Language Models ' Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting. October 2023. URL https://openreview.net/forum?id=RIu5lyNXjT
2023
-
[43]
Beyond the Imitation Game : Quantifying and extrapolating the capabilities of language models
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, et al. Beyond the Imitation Game : Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research, January 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=uyTL5Bvosj
2023
-
[44]
Scale Efficiently : Insights from Pretraining and Finetuning Transformers
Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, and Donald Metzler. Scale Efficiently : Insights from Pretraining and Finetuning Transformers . October 2021. URL https://openreview.net/forum?id=f2OYVDyfIB
2021
-
[45]
Wang, Tong Wu, Kaifeng Lyu, James Zou, Dawn Song, Ruoxi Jia, and Prateek Mittal
Jiachen T. Wang, Tong Wu, Kaifeng Lyu, James Zou, Dawn Song, Ruoxi Jia, and Prateek Mittal. Can Small Training Runs Reliably Guide Data Curation ? Rethinking Proxy - Model Practice . October 2025. URL https://openreview.net/forum?id=2FZC0c06jP
2025
-
[46]
Addressing Order Sensitivity of In - Context Demonstration Examples in Causal Language Models
Yanzheng Xiang, Hanqi Yan, Lin Gui, and Yulan He. Addressing Order Sensitivity of In - Context Demonstration Examples in Causal Language Models . In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Findings of the Association for Computational Linguistics : ACL 2024 , pages 6467--6481, Bangkok, Thailand, August 2024. Association for Computational L...
-
[47]
Qwen3 Technical Report , May 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
Pith/arXiv arXiv 2025
-
[48]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model ? October 2025
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model ? October 2025. URL https://openreview.net/forum?id=4OsgYD7em5
2025
-
[49]
Train-before- Test Harmonizes Language Model Rankings
Guanhua Zhang, Ricardo Dominguez-Olmedo, and Moritz Hardt. Train-before- Test Harmonizes Language Model Rankings . October 2025. URL https://openreview.net/forum?id=ORv3SAzus1
2025
-
[50]
Calibrate Before Use : Improving Few -shot Performance of Language Models
Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. Calibrate Before Use : Improving Few -shot Performance of Language Models . In Proceedings of the 38th International Conference on Machine Learning , pages 12697--12706. PMLR, July 2021. URL https://proceedings.mlr.press/v139/zhao21c.html
2021
-
[51]
LIMA : Less Is More for Alignment
Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, and Omer Levy. LIMA : Less Is More for Alignment . November 2023. URL https://openreview.net/forum?id=KBMOKmX2he
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.