Before and After Temperature: A Distributional View of Creative LLM Generation
Pith reviewed 2026-06-28 17:05 UTC · model grok-4.3
The pith
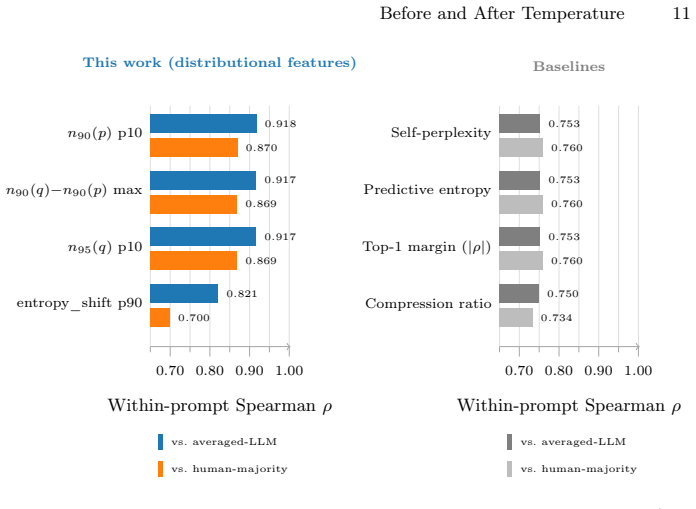
A feature tracking how temperature reshapes token distributions predicts LLM creativity ranks at Spearman rho 0.918.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
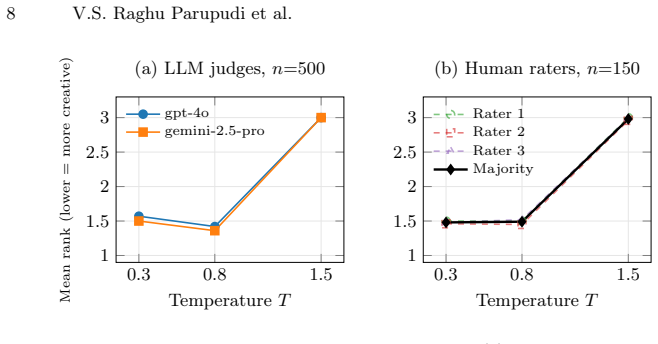
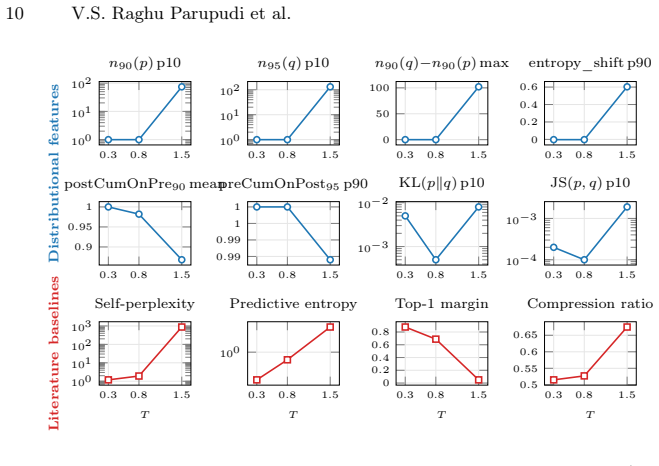
A single per-token feature derived from how sampling temperature reshapes the model's token distribution before the next token is drawn predicts the within-prompt creativity rank at Spearman ρ=0.918 against an averaged gpt-4o / gemini-2.5-pro judge (n=500) and ρ=0.870 against a three-rater human-majority ranking (n=150). Each of four standard reference-free baselines tops out at |ρ|≈0.76. Mechanistically the advantage stems from the distributional signature at T=1.5 where cumulative-mass width n95(q) inflates from ~1 to ~131 tokens and post-temperature mass leaks off the pre-temperature top-90% plausible set by about 13 percentage points.
What carries the argument
The per-token feature derived from temperature-induced reshaping of the token distribution, specifically via cumulative-mass width n95(q) and mass leakage from the top-90% plausible set.
If this is right
- The feature supplies a stronger reference-free signal than perplexity, entropy, top-1 margin, or compression for ranking creative generations.
- High-temperature incoherence is identified by inflation of cumulative-mass width and leakage of probability mass outside the pre-temperature top-90% set.
- Discrimination between the two coherent temperature regimes requires additional sequence-level features.
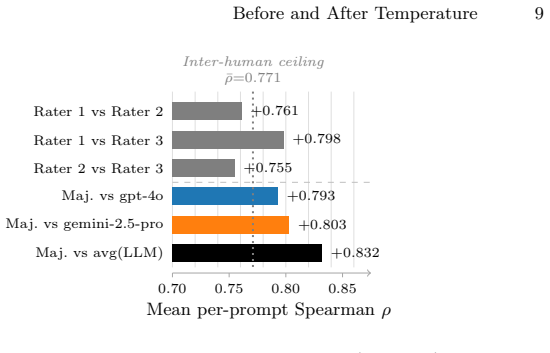
- The LLM-judge and human rankings agree at rho 0.83, which exceeds the inter-human ceiling of 0.77.
Where Pith is reading between the lines
- Generation pipelines could monitor the per-token reshaping feature in real time to adjust temperature or reject incoherent continuations.
- The same reshaping statistics might serve as a diagnostic for other sampling parameters such as top-p or repetition penalty.
- Creativity evaluation could shift from post-hoc text analysis to inspection of the pre-sampling distribution at each step.
- The approach invites tests on whether the feature generalizes across model families beyond Llama-3.1-8B-Instruct.
Load-bearing premise
The LLM-judge and human-majority rankings provide a stable ground truth for creativity rather than mainly reflecting coherence or incoherence.
What would settle it
Measure whether the feature still ranks generations correctly when high-temperature outputs are filtered to remain coherent or when low-temperature outputs are made deliberately repetitive while keeping creativity low.
Figures
read the original abstract
Reference-free evaluation of large language model (LLM) creativity relies on perplexity, entropy, and top-1 margin. We show that a much stronger signal lives one step earlier in the pipeline: in how sampling temperature \emph{reshapes} the model's token distribution before the next token is drawn. On Llama-3.1-8B-Instruct generations of 500 open-ended creative prompts at $T \in \{0.3, 0.8, 1.5\}$, a single per-token feature derived from this reshaping predicts the within-prompt creativity rank at Spearman $\rho{=}0.918$ against an averaged gpt-4o\,/\,gemini-2.5-pro judge ($n{=}500$) and $\rho{=}0.870$ against a three-rater human-majority ranking ($n{=}150$). Each of four standard reference-free baselines (self-perplexity, mean predictive entropy, top-1 margin, gzip compression ratio) tops out at $|\rho|\!\approx\!0.76$ on both ground truths: a gap of $+0.165$ on averaged-LLM and $+0.110$ on human-majority, both far larger than the spread among the baselines themselves. The two ground-truth panels agree with each other at $\rho{=}0.83$, above the inter-human ceiling of $\rho{=}0.77$, so the comparison is not bottlenecked by judge noise. Mechanistically, the win comes from a sharp distributional signature of the incoherence regime: at $T{=}1.5$ the cumulative-mass width $n_{95}(q)$ inflates from $\sim\!1$ to ${\sim}\!131$ tokens and post-temperature mass leaks off the pre-temperature top-$90\%$ plausible set by about $13$ percentage points. The per-token aggregates do not separate $T{=}0.8$ from $T{=}0.3$; discriminating the two coherent regimes is left to sequence-level features.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a single per-token feature extracted from how sampling temperature reshapes an LLM's pre-softmax token distribution provides a substantially stronger reference-free signal for ranking creative generations than standard baselines. On Llama-3.1-8B-Instruct outputs for 500 open-ended prompts at T in {0.3, 0.8, 1.5}, this feature achieves Spearman ρ=0.918 against averaged GPT-4o/Gemini-2.5-pro judgments and ρ=0.870 against three-rater human-majority rankings (n=150), outperforming self-perplexity, mean entropy, top-1 margin, and gzip ratio (all |ρ|≈0.76). The signal is attributed to a sharp increase in cumulative-mass width n95(q) and mass leakage at T=1.5; the feature does not separate the two coherent regimes.
Significance. If the central correlations hold after addressing interpretation issues, the work supplies a mechanistic distributional account of temperature effects that materially improves reference-free creativity evaluation. Strengths include the large performance gap over four established baselines, the fact that LLM-judge and human rankings agree at ρ=0.83 (above the inter-human ceiling of 0.77), and the explicit regime-separation analysis. These elements would constitute a useful contribution to evaluation methodology in creative text generation.
major comments (2)
- [Abstract] Abstract, paragraph on mechanistic signature and regime separation: the reported correlations are driven exclusively by the T=1.5 incoherence regime (n95(q) rising from ~1 to ~131 tokens and 13pp mass leakage), while the per-token aggregates explicitly do not separate T=0.3 from T=0.8. Because the ground-truth rankings may largely encode coherence penalties rather than creativity distinctions within coherent outputs, the claim that the feature measures creativity (rather than incoherence detection) requires additional evidence, such as within-regime rank correlations or an analysis showing that judge scores differentiate creativity independently of coherence.
- [Abstract] Abstract and methods (implied by free parameters listed in axiom ledger): the exact mathematical definition of the per-token feature, the precise cumulative-mass thresholds used to compute n95(q) or related quantities, and whether those thresholds or any aggregation choices were selected or tuned on the same 500-prompt evaluation set are not stated. Without this information, it is impossible to assess whether the reported ρ values reflect a fixed, parameter-free derivation or post-hoc optimization that could inflate the gap over baselines.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, agreeing where the manuscript requires clarification on scope and definitions. Revisions will be made to the abstract and methods to improve precision and interpretation.
read point-by-point responses
-
Referee: [Abstract] Abstract, paragraph on mechanistic signature and regime separation: the reported correlations are driven exclusively by the T=1.5 incoherence regime (n95(q) rising from ~1 to ~131 tokens and 13pp mass leakage), while the per-token aggregates explicitly do not separate T=0.3 from T=0.8. Because the ground-truth rankings may largely encode coherence penalties rather than creativity distinctions within coherent outputs, the claim that the feature measures creativity (rather than incoherence detection) requires additional evidence, such as within-regime rank correlations or an analysis showing that judge scores differentiate creativity independently of coherence.
Authors: We agree that the reported performance is driven by separation of the T=1.5 regime, consistent with the manuscript's explicit statement that per-token aggregates do not separate T=0.3 from T=0.8. The ground-truth rankings (both LLM and human) appropriately assign lower creativity to incoherent outputs, and the high inter-judge agreement (ρ=0.83) supports that this penalty reflects valid creativity assessment. We will revise the abstract to emphasize that the feature provides a strong signal via incoherence detection rather than within-coherent-regime distinctions. We will also add within-regime Spearman correlations and an analysis of judge scores versus independent coherence metrics to address the request for additional evidence. revision: yes
-
Referee: [Abstract] Abstract and methods (implied by free parameters listed in axiom ledger): the exact mathematical definition of the per-token feature, the precise cumulative-mass thresholds used to compute n95(q) or related quantities, and whether those thresholds or any aggregation choices were selected or tuned on the same 500-prompt evaluation set are not stated. Without this information, it is impossible to assess whether the reported ρ values reflect a fixed, parameter-free derivation or post-hoc optimization that could inflate the gap over baselines.
Authors: The full manuscript (Section 3, Methods) defines the per-token feature as the sequence-averaged difference in 95% cumulative-mass width n95(q) before versus after temperature scaling, where n95(q) is the minimal number of tokens whose probabilities sum to at least 95% of the total mass. The 95% threshold follows standard practice for effective support size and was fixed a priori without tuning on the 500-prompt set; no post-hoc optimization was performed. We will insert a concise version of this definition into the abstract and add an explicit statement in Methods confirming the parameter-free, pre-specified nature of all choices. revision: yes
Circularity Check
No circularity: feature derived independently from distributions and correlated with external judges
full rationale
The paper computes a per-token distributional feature (n95(q) width and mass leakage) directly from the model's token probabilities before and after temperature scaling on fixed prompts. This computation uses only the LLM's output logits at T in {0.3,0.8,1.5} and does not reference creativity labels, judge rankings, or any fitted parameters tied to the target variable. The reported Spearman correlations are post-hoc comparisons against independent external rankings (averaged GPT-4o/Gemini judges and human raters). No self-citations, ansatzes, or uniqueness theorems are invoked to justify the feature; the baselines are standard reference-free metrics evaluated on the same data. The derivation chain is therefore self-contained against external benchmarks and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- cumulative-mass thresholds
- temperature set
axioms (2)
- standard math Spearman rho measures monotonic agreement between rankings
- domain assumption LLM and human judge panels provide valid ground truth for creativity
Reference graph
Works this paper leans on
-
[1]
Achiam, J., et al.: GPT-4 technical report (2023), arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Brown, P.F., Pietra, V.J.D., Pietra, S.A.D., Mercer, R.L.: The mathematics of statistical machine translation: parameter estimation. Comput. Linguist.19(2), 263–311 (Jun 1993)
1993
- [3]
-
[4]
Transactions of the Association for Computational Linguistics9, 391–409 (2021)
Fabbri, A.R., Kryściński, W., McCann, B., Xiong, C., Socher, R., Radev, D.: Sum- mEval: Re-evaluating summarization evaluation. Transactions of the Association for Computational Linguistics9, 391–409 (2021)
2021
-
[5]
Hierarchical Neural Story Generation
Fan, A., Lewis, M., Dauphin, Y.: Hierarchical neural story generation. In: Proceed- ings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL). pp. 889–898 (2018), arXiv:1805.04833
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Detecting hallucinations in large language models using semantic entropy , volume =
Farquhar, S., Kossen, J., Kuhn, L., Gal, Y.: Detecting hallucinations in large language models using semantic entropy. Nature630, 625–630 (2024),https: //doi.org/10.1038/s41586-024-07421-0
-
[7]
In: Duh, K., Gomez, H., Bethard, S
Fu, J., Ng, S.K., Jiang, Z., Liu, P.: GPTScore: Evaluate as you desire. In: Duh, K., Gomez, H., Bethard, S. (eds.) Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). pp. 6556–6576. Association for Computational Linguistics, Mexico City, Mex...
2024
-
[8]
Grattafiori, A., et al.: The llama 3 herd of models (2024), arXiv:2407.21783; meta- llama/Llama-3.1-8B-Instruct
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
McGraw-Hill (1967)
Guilford, J.P.: The Nature of Human Intelligence. McGraw-Hill (1967)
1967
-
[10]
The Curious Case of Neural Text Degeneration
Holtzman, A., Buys, J., Du, L., Forbes, M., Choi, Y.: The curious case of neural text degeneration. In: International Conference on Learning Representations (ICLR) (2020), arXiv:1904.09751
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[11]
Journal of the Acoustical Society of America 62(1977),https://api.semanticscholar.org/CorpusID:121680873
Jelinek, F., Mercer, R.L., Bahl, L.R., Baker, J.M.: Perplexity—a measure of the difficulty of speech recognition tasks. Journal of the Acoustical Society of America 62(1977),https://api.semanticscholar.org/CorpusID:121680873
1977
-
[12]
In: International Conference on Learning Representations (ICLR) (2024), arXiv:2310.08491
Kim, S., Shin, J., Cho, Y., Jang, J., Longpre, S., Lee, H., Yun, S., Shin, S., Kim, S., Thorne, J., Seo, M.: Prometheus: Inducing fine-grained evaluation capability in Before and After Temperature 15 language models. In: International Conference on Learning Representations (ICLR) (2024), arXiv:2310.08491
-
[13]
Kuhn, L., Gal, Y., Farquhar, S.: Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. In: International Conference on Learning Representations (ICLR) (2023), arXiv:2302.09664
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
A Diversity-Promoting Objective Function for Neural Conversation Models
Li, J., Galley, M., Brockett, C., Gao, J., Dolan, B.: A diversity-promoting objective function for neural conversation models. In: Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT). pp. 110–119 (2016), arXiv:1510.03055
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[15]
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Liu, Y., Iter, D., Xu, Y., Wang, S., Xu, R., Zhu, C.: G-Eval: NLG evaluation using GPT-4 with better human alignment. In: Proceedings of the 2023 Confer- ence on Empirical Methods in Natural Language Processing (EMNLP) (2023), arXiv:2303.16634
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
In: International Conference on Learning Representations (ICLR) (2021), arXiv:2002.07650
Malinin, A., Gales, M.: Uncertainty estimation in autoregressive structured pre- diction. In: International Conference on Learning Representations (ICLR) (2021), arXiv:2002.07650
-
[17]
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
Manakul, P., Liusie, A., Gales, M.J.F.: SelfCheckGPT: Zero-resource black-box hallucination detection for generative large language models. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) (2023), arXiv:2303.08896
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Transactions of the Association for Computational Linguistics11, 102–121 (2023), arXiv:2202.00666
Meister, C., Pimentel, T., Wiher, G., Cotterell, R.: Locally typical sampling. Transactions of the Association for Computational Linguistics11, 102–121 (2023), arXiv:2202.00666
- [19]
-
[20]
In: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL)
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: BLEU: a method for automatic evaluation of machine translation. In: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL). pp. 311–318 (2002)
2002
- [21]
-
[22]
Shaib, C., Barrow, J., Sun, J., Siu, A.F., Wallace, B.C., Nenkova, A.: Standardizing the measurement of text diversity: A tool and a comparative analysis of scores. arXiv preprint (2024), arXiv:2403.00553
-
[23]
Stevenson, C., Smal, I., Baas, M., Grasman, R., van der Maas, H.: Putting GPT-3’s creativity to the (alternative uses) test. In: Proceedings of the 13th International Conference on Computational Creativity (ICCC) (2022), arXiv:2206.08932
-
[24]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Wang, X., Wei, J., Schuurmans, D., Le, Q.V., Chi, E.H., Narang, S., Chowdhery, A., Zhou, D.: Self-consistency improves chain of thought reasoning in language models. In: International Conference on Learning Representations (ICLR) (2023), arXiv:2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
In: Advances in Neural Information Processing Systems (NeurIPS) (2021)
Yuan, W., Neubig, G., Liu, P.: BARTScore: Evaluating generated text as text generation. In: Advances in Neural Information Processing Systems (NeurIPS) (2021)
2021
-
[26]
Zellers, R., Holtzman, A., Bisk, Y., Farhadi, A., Choi, Y.: HellaSwag: Can a machine really finish your sentence? In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL) (2019), arXiv:1905.07830
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[27]
BERTScore: Evaluating Text Generation with BERT
Zhang, T., Kishore, V., Wu, F., Weinberger, K.Q., Artzi, Y.: BERTScore: Evaluating text generation with BERT. In: International Conference on Learning Representa- tions (ICLR) (2020), arXiv:1904.09675 16 V.S. Raghu Parupudi et al
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[28]
Texygen: A Benchmarking Platform for Text Generation Models
Zhu, Y., Lu, S., Zheng, L., Guo, J., Zhang, W., Wang, J., Yu, Y.: Texygen: A benchmarking platform for text generation models. In: Proceedings of the 41st International ACM SIGIR Conference (2018), arXiv:1802.01886
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.