It's Not the Capability: Harness Sensitivity Is Non-Monotone Across LLM Agent Tiers
Pith reviewed 2026-06-29 17:51 UTC · model grok-4.3
The pith
Harness sensitivity in LLM agents is non-monotone across capability tiers, breaking the expected inverse link to model power.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
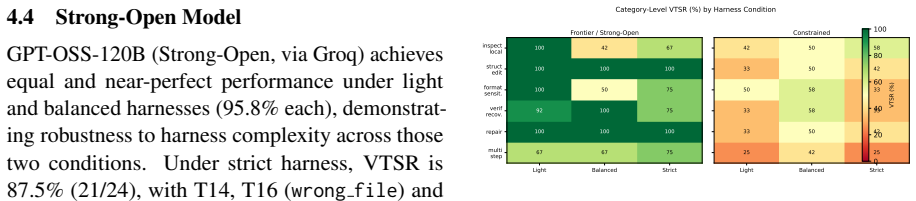
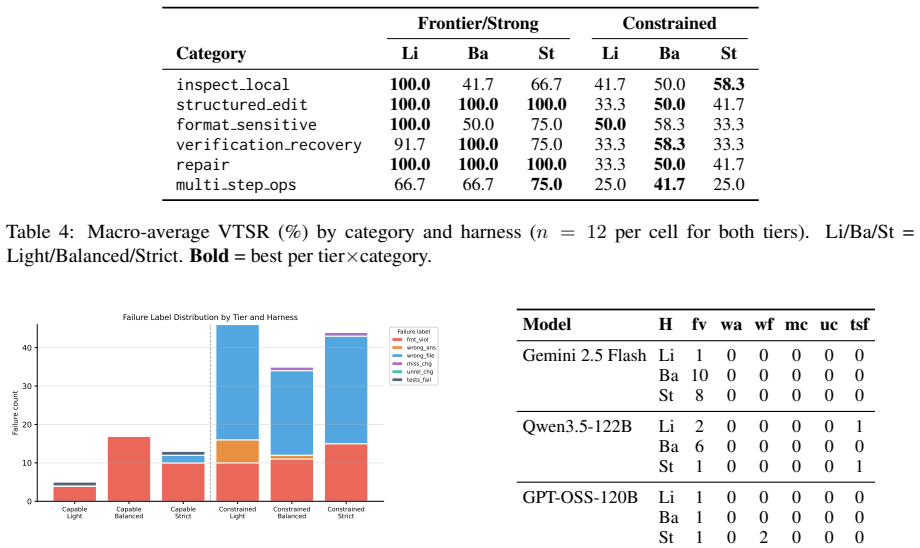
The paper establishes that the hypothesized monotone inverse relationship between model capability tier and optimal harness complexity does not hold. For the frontier chat model, increased harness verbosity lowers verified task success rate by 29-38 percentage points. For the frontier reasoning model with extended thinking, the strict harness produces the highest VTSR of 91.7 percent together with the lowest latency. A 2B model achieves 91.7 percent stability across every harness level, matching stronger tiers. Harness sensitivity is therefore non-monotone and tied to whether the model is chat-oriented or reasoning-oriented.
What carries the argument
The controlled crossing of three harness conditions (light, balanced, strict) with models from four capability tiers, measured by verified task success rate on the HEAT-24 benchmark.
If this is right
- Frontier chat models can lose substantial performance when harness verbosity increases.
- Frontier reasoning models achieve both higher success and lower latency under strict harness conditions.
- Constrained-tier models can maintain high stability across all harness levels.
- Failure modes shift from format violations in capable models to wrong-file errors in low-capability models.
- Practical harness selection rules can be stated in terms of model type and tier.
Where Pith is reading between the lines
- Agent deployment pipelines may need separate harness templates for chat versus reasoning models even at similar capability levels.
- The non-monotonic pattern could be tested on additional benchmarks that use different verification methods.
- Component-level ablation of harness elements might isolate which parts drive the opposing effects in chat and reasoning models.
Load-bearing premise
The single model chosen for each capability tier and the three defined harness conditions are sufficient to show that harness sensitivity is non-monotone in general rather than only for these specific models and tasks.
What would settle it
A larger experiment that samples multiple models per tier and finds a consistent drop in required harness complexity as capability rises would falsify the non-monotone claim.
Figures

read the original abstract
A prevalent assumption in LLM agent deployment holds that more structured harnesses universally improve reliability, and that higher-capability models need proportionally less structural guidance -- together implying a monotone inverse relationship between model capability tier and optimal harness complexity. We test this hypothesis through a controlled 432-run experiment crossing six models across four capability tiers with three harness conditions (light, balanced, strict) on HEAT-24, a 24-task synthetic benchmark with git-based workspace verification. Our results refute the monotone inverse relationship on two fronts. First, for the frontier chat model evaluated (Gemini 2.5 Flash), increased harness verbosity lowers VTSR by 29-38 percentage points -- a harness-complexity paradox. Second, for the frontier reasoning model evaluated (Qwen3.5-122B, extended thinking enabled), strict harness achieves the highest VTSR (91.7%) and the lowest latency, the opposite of the prediction. Within the constrained tier, a 2B model (Gemma4:e2B) matches strong-open-tier stability at 91.7% across all harnesses. Because each tier is represented by a single model in this study, these results should be interpreted as model-specific observations; harness sensitivity appears non-monotone across the models evaluated, and depends critically on model type (chat vs. reasoning). We introduce a six-label failure taxonomy showing that format_violation dominates capable-model failures while wrong_file dominates low-capability failures, and we derive practical tier-aware harness selection guidelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the assumption of a monotone inverse relationship between LLM capability tier and optimal harness complexity is refuted by a 432-run controlled experiment crossing six models in four tiers with three harness conditions (light, balanced, strict) on the HEAT-24 benchmark. Key results include a 29-38 percentage point VTSR drop for Gemini 2.5 Flash under stricter harnesses and 91.7% VTSR with lowest latency for Qwen3.5-122B under strict harness; a six-label failure taxonomy is introduced showing format_violation vs. wrong_file dominance by capability, along with tier-aware guidelines. The abstract qualifies findings as model-specific observations dependent on model type (chat vs. reasoning).
Significance. If the non-monotonic patterns hold, the work would usefully challenge a common deployment heuristic and support model-type-specific harness choices. The controlled design with explicit run counts (432) and git-based verification on a synthetic benchmark provides a reproducible empirical foundation for the specific model observations reported.
major comments (1)
- [Abstract] Abstract: the title and central claim that harness sensitivity 'is non-monotone across LLM Agent Tiers' (refuting the 'monotone inverse relationship' assumption) rests on a single-model-per-tier design. Although the abstract correctly qualifies results as 'model-specific observations' and notes dependence on 'model type (chat vs. reasoning)', this design choice prevents generalizing the observed patterns to capability tiers in general, which is load-bearing for the refutation.
minor comments (2)
- [Abstract] Abstract: the reported VTSR values (e.g., 91.7%) and percentage-point differences lack any reference to error bars, per-task variance, or statistical tests; if these appear in the methods or results sections, cross-reference them from the abstract to support the quantitative claims.
- The description 'crossing six models across four capability tiers' should be clarified with the exact per-tier model counts to resolve any ambiguity with the single-model-per-tier limitation discussion.
Simulated Author's Rebuttal
We thank the referee for this precise observation on the scope of our claims. We agree that the single-model-per-tier design precludes generalizing patterns to capability tiers as a whole and that this is material to the strength of the refutation. We will revise the manuscript to align the title, abstract, and discussion more tightly with the model-specific nature of the results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the title and central claim that harness sensitivity 'is non-monotone across LLM Agent Tiers' (refuting the 'monotone inverse relationship' assumption) rests on a single-model-per-tier design. Although the abstract correctly qualifies results as 'model-specific observations' and notes dependence on 'model type (chat vs. reasoning)', this design choice prevents generalizing the observed patterns to capability tiers in general, which is load-bearing for the refutation.
Authors: We accept the critique. Although the abstract already states that results are model-specific observations, the title and framing of the central claim use 'tiers' in a way that could imply broader generalization. We will (1) revise the title to 'It's Not the Capability: Harness Sensitivity Is Non-Monotone Across Evaluated LLM Agent Models', (2) add an explicit sentence in the abstract and Section 1 stating that tier-level generalization would require multiple models per tier, and (3) adjust the discussion to frame the findings as counterexamples to the universal assumption rather than a direct refutation at the tier level. These changes preserve the empirical contribution while removing any overstatement. revision: yes
Circularity Check
No circularity: purely empirical controlled experiment
full rationale
The paper reports results from a 432-run controlled experiment crossing six models, three harness conditions, and the HEAT-24 benchmark. It measures VTSR and latency directly from runs and presents model-specific observations without any equations, fitted parameters renamed as predictions, or derivations. The text explicitly qualifies results as model-specific and notes dependence on model type. No self-citations, uniqueness theorems, or ansatzes appear in the provided text; the central claim rests on the experimental data rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The VTSR metric on HEAT-24 with git-based verification measures agent reliability comparably across harness conditions and model tiers.
Reference graph
Works this paper leans on
-
[1]
Decoupling task-solving and output formatting in LLM generation.arXiv preprint arXiv:2510.03595. Saibo Geng, Hudson Cooper, Michał Moskal, Samuel Jenkins, Julian Berman, Nathan Ranchin, Robert West, Eric Horvitz, and Harsha Nori
-
[2]
JSON- SchemaBench: A rigorous benchmark of struc- tured outputs for language models.arXiv preprint arXiv:2501.10868. MD Azizul Hakim
- [3]
- [4]
-
[5]
Decomposing LLM self-correction: The accuracy-correction paradox and error depth hypoth- esis.arXiv preprint arXiv:2601.00828. Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, and 1 others
-
[6]
The Prompt Report: A Systematic Survey of Prompt Engineering Techniques
The prompt report: A systematic survey of prompt engineering techniques.arXiv preprint arXiv:2406.06608. Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Reflexion: Language Agents with Verbal Reinforcement Learning
Reflexion: Language agents with verbal reinforcement learning.arXiv preprint arXiv:2303.11366. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.