Case-Based Calibration of Adaptive Reasoning and Execution for LLM Tool Use
Pith reviewed 2026-06-30 20:12 UTC · model grok-4.3
The pith
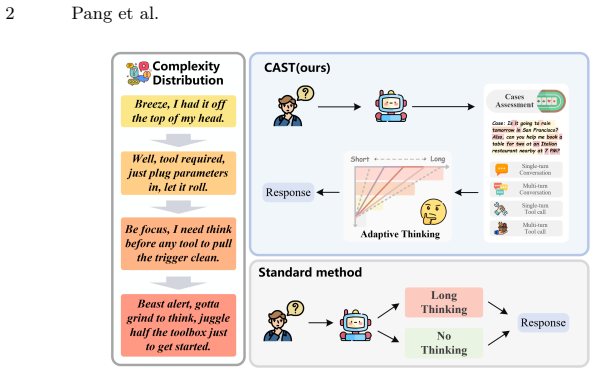
CAST extracts complexity and failure profiles from past tool-use trajectories to adapt reasoning depth and improve execution accuracy in LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
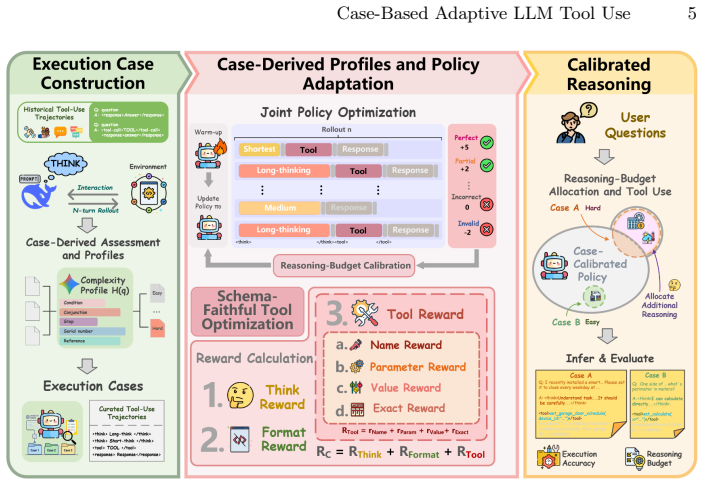
CAST treats historical execution trajectories as structured cases, extracts case-derived signals consisting of complexity profiles for estimating optimal reasoning strategies and failure profiles for mapping likely structural breakdowns, and translates this knowledge into fine-grained reward design and adaptive reasoning so that the model autonomously internalizes case-based strategies during reinforcement learning.
What carries the argument
Case-derived signals from complexity profiles and failure profiles that drive reward design and adaptive reasoning.
If this is right
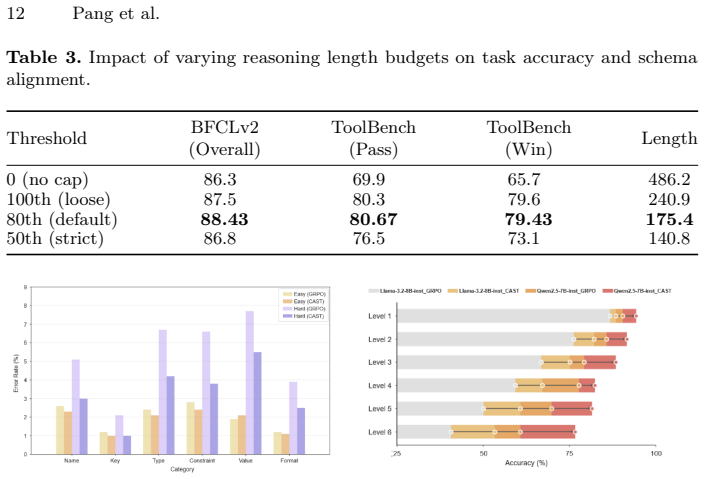
- Schema-faithful execution and task-level tool-use success both increase.
- Average reasoning length decreases by 26 percent.
- High-impact structural errors are reduced.
- Overall execution accuracy gains reach up to 5.85 percentage points on BFCLv2 and ToolBench.
Where Pith is reading between the lines
- The same case-extraction approach might apply to other domains where LLMs must decide how much internal reasoning to expend before acting.
- Profiles built from one set of tools could be tested for transfer to entirely different tool libraries.
- If profiles prove reusable, manual prompt tuning for tool-use prompts might become less necessary.
Load-bearing premise
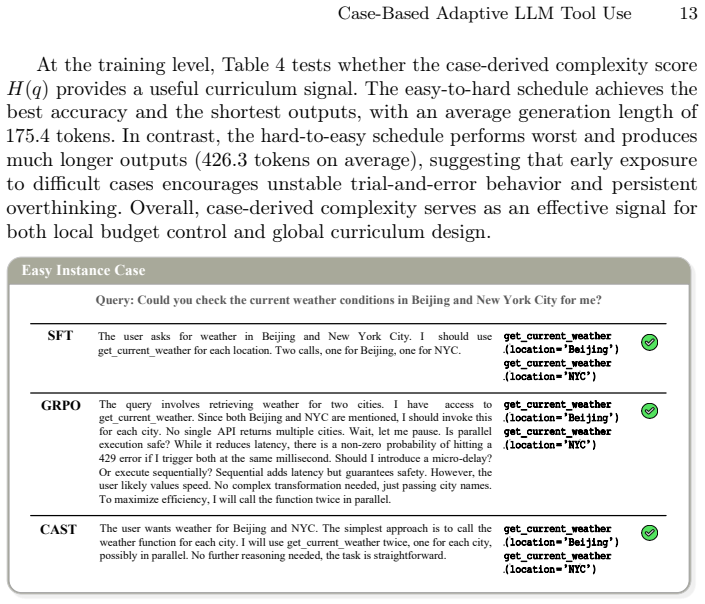
Historical execution trajectories contain extractable complexity profiles and failure profiles that translate into reusable signals for reward design and adaptive reasoning.
What would settle it
An experiment on new tool-use tasks where trajectories lack distinct complexity or failure patterns, after which CAST produces no measurable gain in execution accuracy or reasoning length compared with a non-case baseline.
Figures


read the original abstract
Tool use extends large language models beyond parametric knowledge, but reliable execution requires balancing appropriate reasoning depth with strict structural validity. We approach this problem from a case-based perspective to present CAST, a case-driven framework that treats historical execution trajectories as structured cases. Instead of reusing raw exemplar outputs, CAST extracts case-derived signals to identify complexity profiles for estimating optimal reasoning strategies, alongside failure profiles to map likely structural breakdowns. The framework translates this knowledge into a fine-grained reward design and adaptive reasoning, enabling the model to autonomously internalize case-based strategies during reinforcement learning. Experiments on BFCLv2 and ToolBench demonstrate that CAST improves both schema-faithful execution and task-level tool-use success while reducing unnecessary deliberation. The approach achieves up to 5.85 percentage points gain in overall execution accuracy and reduces average reasoning length by 26%, significantly mitigating high-impact structural errors. Ultimately, this demonstrates how historical execution cases can provide reusable adaptation knowledge for calibrated tool use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CAST, a case-based framework for LLM tool use that extracts complexity profiles and failure profiles from historical execution trajectories. These profiles are translated into fine-grained reward designs and adaptive reasoning policies, which are internalized via reinforcement learning. Experiments on BFCLv2 and ToolBench are reported to yield up to 5.85 percentage points gain in execution accuracy and a 26% reduction in average reasoning length while mitigating structural errors.
Significance. If the central claim holds, the work would demonstrate a practical mechanism for reusing historical trajectories as structured cases to calibrate reasoning depth and structural validity in tool-using agents. The reported efficiency and accuracy gains would be of interest to the LLM agent community, particularly if the profile extraction yields signals that transfer without retraining on new task distributions.
major comments (2)
- [Abstract] Abstract: The central claim that complexity and failure profiles supply 'reusable adaptation knowledge' that generalizes beyond the source trajectories is load-bearing for the contribution, yet the abstract supplies no description of held-out trajectory sets, cross-task validation, or distribution-shift experiments that would rule out overfitting or post-hoc fitting of the reward signals to the evaluation cases.
- [Abstract] Abstract: The reported 5.85 pp accuracy gain and 26% length reduction are presented without any ablation isolating the contribution of the extracted profiles versus the base RL loop or without error analysis breaking down structural versus semantic failures; this omission prevents verification that the improvements are attributable to the case-derived signals rather than selection effects in the reward design.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and will revise the abstract and experimental reporting to improve clarity on generalization and attribution of results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that complexity and failure profiles supply 'reusable adaptation knowledge' that generalizes beyond the source trajectories is load-bearing for the contribution, yet the abstract supplies no description of held-out trajectory sets, cross-task validation, or distribution-shift experiments that would rule out overfitting or post-hoc fitting of the reward signals to the evaluation cases.
Authors: The full manuscript evaluates on held-out test splits within BFCLv2 and on the separate ToolBench benchmark, treating these as distinct task distributions to demonstrate transfer of the extracted profiles. We agree the abstract is too terse on this point and will revise it to explicitly reference the held-out evaluation sets and cross-benchmark results as support for reusability. We do not report additional synthetic distribution-shift experiments beyond the two benchmarks; if the referee considers this a critical gap we can add a limitations paragraph acknowledging it. revision: yes
-
Referee: [Abstract] Abstract: The reported 5.85 pp accuracy gain and 26% length reduction are presented without any ablation isolating the contribution of the extracted profiles versus the base RL loop or without error analysis breaking down structural versus semantic failures; this omission prevents verification that the improvements are attributable to the case-derived signals rather than selection effects in the reward design.
Authors: The manuscript body contains component ablations (profile extraction, reward shaping, and adaptive reasoning) and a structural-error breakdown; however, these details are not summarized in the abstract. We will revise the abstract to note that ablations isolate the profile-derived signals and that error analysis shows primary reduction in structural failures. If the current ablations are judged insufficient, we can expand them in the revision. revision: yes
Circularity Check
No significant circularity detected; derivation remains self-contained
full rationale
The paper extracts complexity and failure profiles from historical execution trajectories, translates them into reward signals and adaptive reasoning policies, and applies the resulting framework via reinforcement learning. Evaluation is reported on the independent benchmarks BFCLv2 and ToolBench, with quantitative gains (5.85 pp accuracy, 26% length reduction) presented as empirical outcomes rather than re-derivations of the source trajectories. No equations, self-citations, or uniqueness claims are supplied in the abstract that would reduce any prediction to a fitted input by construction. The central claim therefore rests on observable transfer to held-out benchmarks rather than tautological reuse of the case data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Historical execution trajectories can be treated as structured cases that yield reusable adaptation knowledge
invented entities (2)
-
complexity profiles
no independent evidence
-
failure profiles
no independent evidence
Reference graph
Works this paper leans on
-
[1]
AI communications7(1), 39–59 (1994)
Aamodt, A., Plaza, E.: Case-based reasoning: Foundational issues, methodological variations, and system approaches. AI communications7(1), 39–59 (1994)
1994
-
[2]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track
Abdelaziz, I., Basu, K., Agarwal, M., Kumaravel, S., Stallone, M., Panda, R., et al.: Granite-function calling model: Introducing function calling abilities via multi-task learning of granular tasks. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track. pp. 1131–1139 (2024)
2024
-
[3]
In: International Conference on Case-Based Reasoning
Bergmann, R., Brand, F., Lenz, M., Malburg, L.: Exar: A unified experience- grounded agentic reasoning architecture. In: International Conference on Case-Based Reasoning. pp. 3–17. Springer (2025)
2025
-
[4]
Vicinagearth2(1), 16 (2025)
Chen, J., Wu, H., Pang, J., Wang, Y., Zhang, D., Sun, C.: Tool learning with language models: a comprehensive survey of methods, pipelines, and benchmarks. Vicinagearth2(1), 16 (2025)
2025
-
[5]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Chen, Z.Y., Shen, S., Shen, G., Zhi, G., Chen, X., Lin, Y.: Towards tool use alignment of large language models. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 1382–1400 (2024)
2024
-
[6]
Artificial Intelligence Review (2026)
Chowa, S.S., Alvi, R., Rahman, S.S., Rahman, M.A., Raiaan, M.A.K., et al.: From language to action: a review of large language models as autonomous agents and tool users. Artificial Intelligence Review (2026)
2026
-
[7]
Artificial intelligence170(16-17), 1175–1192 (2006)
Craw, S., Wiratunga, N., Rowe, R.C.: Learning adaptation knowledge to improve case-based reasoning. Artificial intelligence170(16-17), 1175–1192 (2006)
2006
-
[8]
Transportation Letters 2(2), 89–110 (2010)
El-Tantawy, S., Abdulhai, B.: Towards multi-agent reinforcement learning for integrated network of optimal traffic controllers (marlin-otc). Transportation Letters 2(2), 89–110 (2010)
2010
-
[9]
In: International Conference on Case-Based Reasoning
Ge, X., Xu, J.: Integrating case-based reasoning with llm for expense fraud detection. In: International Conference on Case-Based Reasoning. pp. 52–66. Springer (2025)
2025
-
[10]
In: International Conference on Case-Based Reasoning
Ghazouani, F., Giustozzi, F., Le Ber, F.: Llm-driven case-base populating for structuring and integrating restoration experiences. In: International Conference on Case-Based Reasoning. pp. 67–80. Springer (2025)
2025
-
[11]
In: International Conference on Case-Based Reasoning
Hanney, K., Keane, M.T.: The adaptation knowledge bottleneck: How to ease it by learning from cases. In: International Conference on Case-Based Reasoning. pp. 359–370. Springer (1997)
1997
-
[12]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
In: International Conference on Case-Based Reasoning
Lenz, M., Bergmann, R.: Case-based adaptation of argument graphs with wordnet and large language models. In: International Conference on Case-Based Reasoning. pp. 263–278. Springer (2023) 16 Pang et al
2023
-
[14]
In: International Conference on Case-Based Reasoning
Lenz, M., Hoffmann, M., Bergmann, R.: Llsim: large language models for similarity assessment in case-based reasoning. In: International Conference on Case-Based Reasoning. pp. 126–141. Springer (2025)
2025
-
[15]
In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Li, W., Li, D., Dong, K., Zhang, C., Zhang, H., Liu, W., Wang, Y., Tang, R., Liu, Y.: Adaptive tool use in large language models with meta-cognition trigger. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 13346–13370 (2025)
2025
-
[16]
In: ICLR 2026 Conference Proceedings (2026)
Lin, Z., Wang, X., Cao, J., Chai, J.: Rest: Reshaping token-level policy gradients for tool-use large language models. In: ICLR 2026 Conference Proceedings (2026)
2026
-
[17]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al.: Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
In: ICCBR 2025
Liu, H., Liu, Q., Wu, L., Shi, M., Cui, Z.: Offline-to-online: Case-based knowledge distillation with large language models for reinforcement learning. In: ICCBR 2025. LNCS, vol. 15662, pp. 142–156. Springer (2025)
2025
-
[19]
arXiv preprint arXiv:2505.11896 (2025)
Lou, C., Sun, Z., Liang, X., Qu, M., Shen, W., Wang, W., Li, Y., Yang, Q., Wu, S.: Adacot: Pareto-optimal adaptive chain-of-thought triggering via reinforcement learning. arXiv preprint arXiv:2505.11896 (2025)
-
[20]
In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Ma, X., Wan, G., Yu, R., Fang, G., Wang, X.: Cot-valve: Length-compressible chain- of-thought tuning. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 6025–6035 (2025)
2025
-
[21]
In: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Mohammadi, M., Li, Y., Lo, J., Yip, W.: Evaluation and benchmarking of llm agents: A survey. In: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. pp. 6129–6139 (2025)
2025
-
[22]
Patil, S.G., Mao, H., Yan, F., Ji, C.C.J., Suresh, V., Stoica, I., Gonzalez, J.E.: The berkeley function calling leaderboard (BFCL) (2025)
2025
-
[23]
In: Advances in Neural Information Processing Systems 37 (NeurIPS 2024) (2024)
Patil, S.G., Zhang, T., Wang, X., Gonzalez, J.E.: Gorilla: Large language model connected with massive apis. In: Advances in Neural Information Processing Systems 37 (NeurIPS 2024) (2024)
2024
-
[24]
In: The Twelfth International Conference on Learning Representations (ICLR) (2024)
Qin, Y., Liang, S., Ye, Y., Zhu, K., Yan, L., Lu, Y., Lin, Y., Cong, X., et al.: Toolllm: Facilitating large language models to master 16000+ real-world apis. In: The Twelfth International Conference on Learning Representations (ICLR) (2024)
2024
-
[25]
In: NeurIPS 2023 foundation models for decision making workshop (2023)
Ruan, J., Chen, Y., Zhang, B., Xu, Z., Bao, T., Mao, H., Li, Z., Zeng, X., Zhao, R., et al.: Tptu: Task planning and tool usage of large language model-based ai agents. In: NeurIPS 2023 foundation models for decision making workshop (2023)
2023
-
[26]
Advances in neural information processing systems36, 68539–68551 (2023)
Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Hambro, E., Zettle- moyer, L., Cancedda, N., Scialom, T.: Toolformer: Language models can teach themselves to use tools. Advances in neural information processing systems36, 68539–68551 (2023)
2023
-
[27]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Xu, H., Wang, Z., Zhu, Z., Pan, L., Chen, X., Fan, S., Chen, L., Yu, K.: Alignment for efficient tool calling of large language models. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 17787–17803 (2025)
2025
-
[28]
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., et al.: Qwen2.5 technical report (2025),https://arxiv.org/abs/2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
In: The eleventh international conference on learning representations (2022)
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K.R., Cao, Y.: React: Synergizing reasoning and acting in language models. In: The eleventh international conference on learning representations (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.