HARP: Hadamard-Preconditioned Adaptive Rotation Processor for Extreme LLM Quantization
Pith reviewed 2026-06-29 09:14 UTC · model grok-4.3
The pith
A learnable structured rotation processor adapts the quantization basis to each layer and improves 2-4 bit LLM performance over fixed Hadamard transforms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HARP is a learnable structured two-sided orthogonal processor that replaces fixed randomized Hadamard transforms, represents each rotation as a product of sparse butterfly-like block-orthogonal stages, supports non-power-of-two dimensions via Mixed-Radix schedules, initializes to the RHT up to fixed permutation, and when fitted only on calibration data adapts the quantization basis per layer and backend to improve robustness under extreme low-bit settings.
What carries the argument
HARP, the Hadamard-preconditioned Adaptive Rotation Processor: a learnable product of sparse block-orthogonal stages forming an adaptive two-sided orthogonal transformation.
If this is right
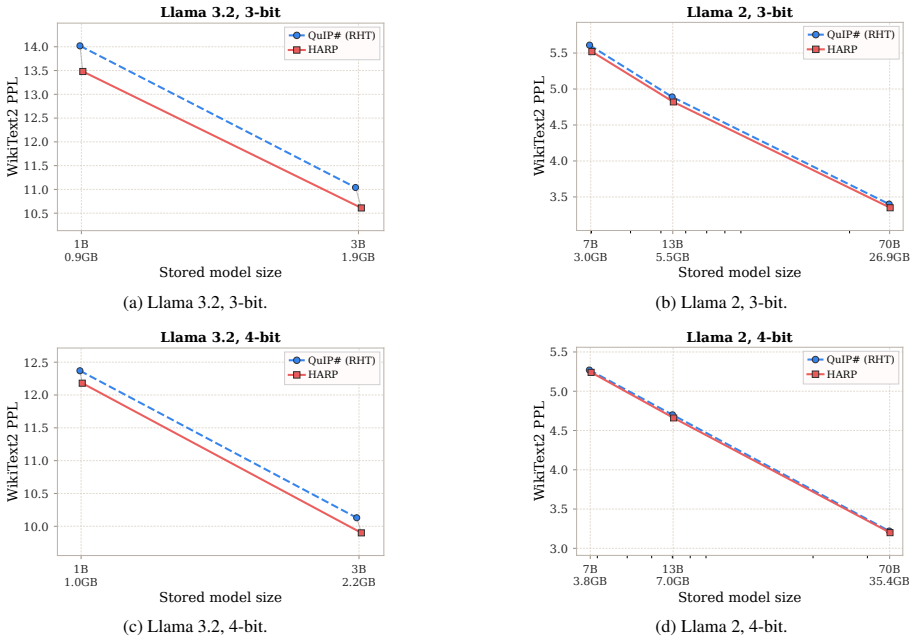
- Lower perplexity and higher zero-shot accuracy than fixed RHT across 2-4 bit quantization.
- Consistent gains on models from 1B to 70B parameters.
- Exact preservation of full-precision mathematical equivalence.
- Inference speed of 128 tokens per second, exceeding FP16 throughput.
- Compatibility with non-power-of-two dimensions through Mixed-Radix schedules.
Where Pith is reading between the lines
- The per-layer adaptation may reduce reliance on manual quantizer hyperparameter search in production pipelines.
- Similar structured learnable orthogonal stages could be applied to other transforms that currently rely on fixed random matrices.
- Because the processor remains exactly equivalent at full precision, it can be inserted into existing training or fine-tuning loops without changing numerical results until quantization is applied.
Load-bearing premise
A rotation processor fitted only on calibration data will generalize to test distributions without losing exact full-precision equivalence or introducing deployment overhead.
What would settle it
Running the same 2-4 bit quantization benchmarks on a 7B or 70B model and observing that HARP produces higher perplexity or lower zero-shot accuracy than the fixed RHT baseline, or measuring inference throughput below 61 tokens per second.
Figures


read the original abstract
Post-training quantization (PTQ) is essential for deploying LLMs under memory and bandwidth constraints. However, extreme low-bit quantization remains highly sensitive to activation outliers and anisotropic weight curvature. Existing incoherence-based PTQ methods mitigate this issue with fixed randomized Hadamard transforms (RHTs), which improve quantization robustness but cannot adapt the rotated basis to the layer, calibration distribution, or quantizer. We introduce HARP (Hadamard-preconditioned Adaptive Rotation Processor), a learnable structured two-sided orthogonal processor that replaces fixed Hadamard mixing while preserving exact full-precision equivalence. HARP represents each rotation as a product of sparse butterfly-like block-orthogonal stages, supports non-power-of-two dimensions via Mixed-Radix schedules, and initializes to the RHT processor up to a fixed permutation. Fitted only on calibration data, HARP adapts the quantization basis to each layer and backend. Across 2-4 bit settings on models ranging from 1B to 70B parameters, HARP improves perplexity and zero-shot accuracy over fixed RHT. Importantly, HARP preserves deployment efficiency, reaching 128 tok/s versus 61 tok/s for FP16.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HARP, a learnable structured two-sided orthogonal rotation processor built from sparse butterfly-like block-orthogonal stages. It initializes to a fixed randomized Hadamard transform (RHT), is fitted exclusively on calibration data to adapt the quantization basis per layer and backend, supports mixed-radix schedules for non-power-of-two dimensions, and claims to preserve exact full-precision equivalence via orthogonality while delivering improved perplexity and zero-shot accuracy over static RHT in 2-4 bit regimes for models from 1B to 70B parameters, all without deployment overhead (128 tok/s vs. 61 tok/s FP16).
Significance. If the empirical improvements prove robust and the exact-equivalence plus zero-overhead properties hold under deployment, the work would meaningfully extend incoherence-based PTQ by replacing fixed transforms with layer-adaptive yet structured orthogonal processors, addressing sensitivity to outliers and curvature while retaining the deployability advantages of RHT-style methods.
major comments (2)
- [Abstract] Abstract: the central empirical claim that HARP 'improves perplexity and zero-shot accuracy over fixed RHT' across 2-4 bit settings and 1B-70B models is stated without any reference to datasets, number of calibration samples, evaluation protocols, error bars, or statistical significance, preventing assessment of whether the gains are load-bearing or reproducible.
- [Abstract] Abstract: the claim that adaptation 'only on calibration data' yields generalization to test distributions while preserving exact equivalence rests on an unverified assumption; no argument or experiment is supplied showing that the learned sparse factors remain distribution-agnostic rather than capturing calibration-specific statistics, which directly threatens the reported gains if overfitting occurs.
minor comments (1)
- [Abstract] The efficiency claim (128 tok/s) assumes the mixed-radix factorization incurs literally zero overhead relative to static RHT once frozen, but the abstract provides no implementation or profiling details confirming identical compilation and execution paths.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the manuscript accordingly where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that HARP 'improves perplexity and zero-shot accuracy over fixed RHT' across 2-4 bit settings and 1B-70B models is stated without any reference to datasets, number of calibration samples, evaluation protocols, error bars, or statistical significance, preventing assessment of whether the gains are load-bearing or reproducible.
Authors: We agree the abstract is overly concise on experimental specifics. In the revised version we will expand the abstract to reference the primary evaluation datasets (WikiText-2 and C4 for perplexity; standard zero-shot tasks including ARC, HellaSwag, PIQA, Winogrande), calibration protocol (128 sequences from C4), and note that reported numbers are means over three random seeds with standard deviations shown in the main tables. Full protocols, including the exact calibration set construction and statistical reporting, remain in Section 4. revision: yes
-
Referee: [Abstract] Abstract: the claim that adaptation 'only on calibration data' yields generalization to test distributions while preserving exact equivalence rests on an unverified assumption; no argument or experiment is supplied showing that the learned sparse factors remain distribution-agnostic rather than capturing calibration-specific statistics, which directly threatens the reported gains if overfitting occurs.
Authors: The empirical evidence for generalization is the consistent improvement on held-out test perplexity splits and on zero-shot tasks whose distributions differ from the calibration set. Because each HARP processor is constrained to remain exactly orthogonal (hence distribution-agnostic in the equivalence sense) and is initialized from the fixed RHT, the learned adaptation is limited to re-weighting the sparse factors to better align with per-layer activation statistics. We will add a short paragraph in Section 3.3 of the revision explaining this inductive bias and why it reduces the risk of capturing calibration-specific noise. A dedicated distribution-shift ablation is not present and would require new experiments; we therefore treat this as a partial revision. revision: partial
Circularity Check
No circularity: derivation self-contained with no equations or self-citation chains shown
full rationale
The provided abstract and context contain no equations, fitting procedures, or derivation steps that reduce to their own inputs by construction. Claims about fitting on calibration data and generalization are stated at a high level without any visible self-definitional loops, fitted-input predictions, or load-bearing self-citations. The paper's central mechanism (learnable orthogonal processor initialized to RHT) is described as preserving exact equivalence via orthogonality, but no specific reduction to calibration statistics or prior self-work is exhibited. This is the normal case of an honest non-finding when the source text supplies no load-bearing steps to inspect.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Extreme Low-Bit Inference in Reasoning Models: Failure Modes and Targeted Recovery
2-bit quantized reasoning models exhibit process failures like loops and delayed commitment that degrade end-to-end performance, but FP16 planning and loop rescue recover accuracy on MATH-500 from 17.2% to 74.2% for Q...
-
Rethinking the Role of Tensor Decompositions in Post-Training LLM Compression
Tensor decompositions face practical limits in large-scale LLM compression due to mismatch between assumed shared subspaces and heterogeneous model representations.
Reference graph
Works this paper leans on
-
[1]
Extreme compression of large language models via additive quantization.arXiv preprint arXiv:2401.06118. Elias Frantar and Dan Alistarh. 2022. Optimal brain compression: A framework for accurate post- trainingquantizationandpruning.AdvancesinNeu- ral Information Processing Systems, 35:4475–4488. Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alist...
-
[2]
Table 12: Fine-tuning compatibility on Llama 2 7B, 2-bit, context length4096
Table 12 reports the result. Table 12: Fine-tuning compatibility on Llama 2 7B, 2-bit, context length4096. HARP uses Mixed-Radix. Method W2 PPL↓C4 PPL↓ QuIP# + RHT + FT-quant only 6.44 8.30 QuIP# + RHT + FT-quant + E2E FT 6.19 8.16 HARP + FT-quant only 6.16 8.08 Even with only FT-quant, HARP improves over the corresponding RHT setting. It also slightly im...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.