DynamicNER: A Dynamic, Multilingual, and Fine-Grained Dataset for LLM-based Named Entity Recognition
Pith reviewed 2026-05-23 20:37 UTC · model grok-4.3
The pith
DynamicNER introduces varying entity type lists for identical entities across contexts to benchmark LLM named entity recognition more effectively than fixed datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
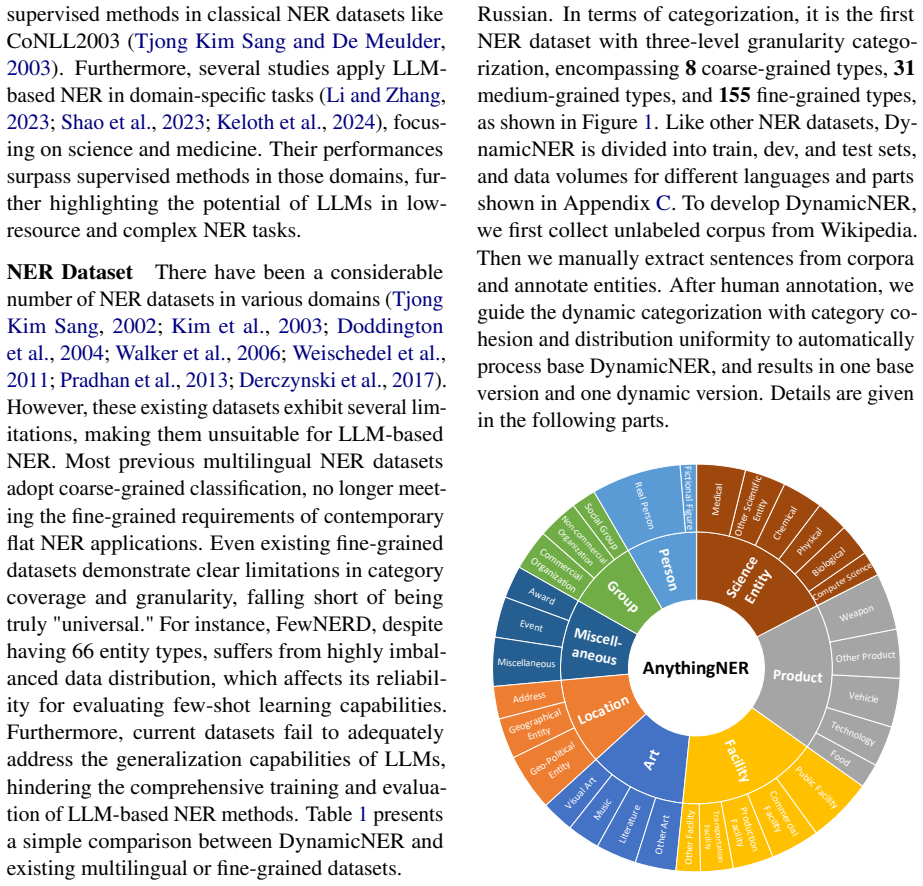
DynamicNER is the first NER dataset designed for LLM-based methods with dynamic categorization, introducing various entity types and entity type lists for the same entity in different context, leveraging the generalization of LLM-based NER better. The dataset is multilingual and multi-granular, covering 8 languages and 155 entity types, with corpora spanning a diverse range of domains. CascadeNER, a novel NER method based on a two-stage strategy and lightweight LLMs, achieves higher accuracy on fine-grained tasks while requiring fewer computational resources. Experiments show that DynamicNER serves as a robust and effective benchmark for LLM-based NER methods.
What carries the argument
Dynamic categorization, in which the same entity is assigned different entity type lists depending on context, to better expose LLM generalization and contextual understanding.
If this is right
- LLM-based NER methods can be evaluated on their ability to handle varying type lists for the same entities.
- CascadeNER demonstrates that a two-stage lightweight LLM approach can reach higher accuracy on fine-grained NER with lower resource use.
- Multilingual coverage across eight languages allows direct comparison of LLM NER performance across languages on the same dynamic framework.
- Analysis of both traditional and LLM methods on DynamicNER reveals differences in how each handles dynamic entity lists.
Where Pith is reading between the lines
- Dynamic label sets could be applied to other sequence labeling tasks to test model adaptability beyond NER.
- Training procedures that explicitly vary entity type lists during fine-tuning might further improve LLM robustness.
- The dataset design suggests that future benchmarks in information extraction should incorporate context-dependent label variation as a standard feature.
Load-bearing premise
Fixed and coarse-grained entity categories in existing datasets cannot adequately measure how LLMs use context and generalize across entity types.
What would settle it
An experiment in which LLM-based NER systems show no improvement in measured generalization or contextual performance on DynamicNER compared with performance on conventional fixed-category datasets would undermine the claim that dynamic categorization is needed.
Figures







read the original abstract
The advancements of Large Language Models (LLMs) have spurred a growing interest in their application to Named Entity Recognition (NER) methods. However, existing datasets are primarily designed for traditional machine learning methods and are inadequate for LLM-based methods, in terms of corpus selection and overall dataset design logic. Moreover, the prevalent fixed and relatively coarse-grained entity categorization in existing datasets fails to adequately assess the superior generalization and contextual understanding capabilities of LLM-based methods, thereby hindering a comprehensive demonstration of their broad application prospects. To address these limitations, we propose DynamicNER, the first NER dataset designed for LLM-based methods with dynamic categorization, introducing various entity types and entity type lists for the same entity in different context, leveraging the generalization of LLM-based NER better. The dataset is also multilingual and multi-granular, covering 8 languages and 155 entity types, with corpora spanning a diverse range of domains. Furthermore, we introduce CascadeNER, a novel NER method based on a two-stage strategy and lightweight LLMs, achieving higher accuracy on fine-grained tasks while requiring fewer computational resources. Experiments show that DynamicNER serves as a robust and effective benchmark for LLM-based NER methods. Furthermore, we also conduct analysis for traditional methods and LLM-based methods on our dataset. Our code and dataset are openly available at https://github.com/Astarojth/DynamicNER.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing NER datasets are inadequate for LLM-based methods due to their fixed, coarse-grained design, which fails to test generalization and contextual understanding. It introduces DynamicNER as the first dataset tailored for LLMs, featuring dynamic categorization (varying entity type lists for the same entity across contexts), multilingual coverage (8 languages), 155 entity types, and diverse domains. It also proposes CascadeNER, a two-stage method using lightweight LLMs that achieves higher accuracy on fine-grained tasks with lower computational cost. Experiments are said to demonstrate that DynamicNER is a robust benchmark, accompanied by analysis comparing traditional and LLM-based methods on the dataset. Code and data are released openly.
Significance. If the dataset construction, validation, and experimental results are sound, DynamicNER could fill a genuine gap by providing a benchmark that better evaluates LLM generalization in NER, moving beyond the limitations of fixed datasets. The open release of code and dataset is a clear strength that supports reproducibility and community use.
major comments (2)
- [Abstract] Abstract: The central claim that DynamicNER 'serves as a robust and effective benchmark' and that CascadeNER achieves 'higher accuracy' is stated without any quantitative results, baselines, dataset statistics, validation metrics, or error analysis. This absence prevents assessment of whether the dynamic design actually demonstrates the claimed LLM advantages.
- [Dataset Construction and Experiments] Dataset construction and experimental sections: No details are provided on how dynamic entity type lists are generated per context, how annotation consistency is ensured across the 155 types and 8 languages, inter-annotator agreement, or the exact experimental setup (train/test splits, baselines, metrics). These elements are load-bearing for the claim that the dataset is superior for assessing LLM capabilities.
minor comments (2)
- [Introduction] The motivation section would benefit from a concrete example of dynamic categorization (same entity, different type lists in different contexts) to illustrate the key innovation.
- [Dataset Description] Clarify the precise definition of 'multi-granular' and how the 155 types are organized hierarchically or otherwise.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive feedback. We address each major comment below and commit to revising the manuscript to strengthen clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that DynamicNER 'serves as a robust and effective benchmark' and that CascadeNER achieves 'higher accuracy' is stated without any quantitative results, baselines, dataset statistics, validation metrics, or error analysis. This absence prevents assessment of whether the dynamic design actually demonstrates the claimed LLM advantages.
Authors: We acknowledge that the abstract, in its current form, presents high-level claims without supporting numbers. While the body of the paper contains quantitative results, baselines, and analysis in the Experiments section, we agree the abstract would be strengthened by including key highlights. In the revision we will incorporate concise quantitative statements (e.g., accuracy gains on fine-grained tasks and basic dataset statistics) into the abstract. revision: yes
-
Referee: [Dataset Construction and Experiments] Dataset construction and experimental sections: No details are provided on how dynamic entity type lists are generated per context, how annotation consistency is ensured across the 155 types and 8 languages, inter-annotator agreement, or the exact experimental setup (train/test splits, baselines, metrics). These elements are load-bearing for the claim that the dataset is superior for assessing LLM capabilities.
Authors: We agree these procedural details are essential. The current manuscript provides an overview but lacks sufficient granularity. In the revised version we will expand the Dataset Construction section to explicitly describe the process for generating context-specific dynamic entity type lists, the annotation protocol and quality-control steps used across languages and the 155 types, inter-annotator agreement statistics, and the precise experimental configuration (splits, baselines, metrics, and evaluation protocol). revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces a new dataset (DynamicNER) and method (CascadeNER) for LLM-based NER without any mathematical derivations, parameter fitting, or predictive claims that reduce to inputs by construction. Claims rest on dataset construction details, multilingual coverage, and empirical experiments rather than self-citation chains or self-definitional loops. No load-bearing steps match the enumerated circularity patterns; the work is self-contained as an empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Anthropic. 2023. Claude: An ai assistant by anthropic. https://www.anthropic.com/index/claude. Accessed: [date of access]
work page 2023
- [5]
-
[6]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report. arXiv preprint arXiv:2309.16609
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Emily M Bender and Batya Friedman. 2018. Data statements for natural language processing: Toward mitigating system bias and enabling better science. Transactions of the Association for Computational Linguistics, 6:587--604
work page 2018
-
[8]
Tom B Brown. 2020. Language models are few-shot learners. arXiv preprint arXiv:2005.14165
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[9]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2023. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1--113
work page 2023
-
[10]
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzm \'a n, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020. Unsupervised cross-lingual representation learning at scale. arXiv preprint arXiv:1911.02116
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[11]
Badhan Chandra Das, M Hadi Amini, and Yanzhao Wu. 2024. Security and privacy challenges of large language models: A survey. ACM Computing Surveys
work page 2024
-
[12]
Jiangyi Deng, Xinfeng Li, Yanjiao Chen, Yijie Bai, Haiqin Weng, Yan Liu, Tao Wei, and Wenyuan Xu. 2025. RACONTEUR : A knowledgeable, insightful, and portable LLM -powered shell command explainer. In Proceedings of the 32nd Annual Network and Distributed System Security Symposium, NDSS
work page 2025
-
[13]
Leon Derczynski, Eric Nichols, Marieke van Erp, and Nut Limsopatham. 2017. Results of the wnut2017 shared task on novel and emerging entity recognition. In Proceedings of the 3rd Workshop on Noisy User-generated Text, pages 140--147
work page 2017
-
[14]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Ning Ding, Guangwei Xu, Yulin Chen, Xiaobin Wang, Xu Han, Pengjun Xie, Haitao Zheng, Zhiyuan Liu, Juanzi Li, Maosong Sun, and Jing Zhou. 2021. https://doi.org/10.18653/v1/2021.acl-long.491 F ew- NERD : A few-shot named entity recognition dataset . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th Inter...
-
[16]
George R Doddington, Alexis Mitchell, Mark Przybocki, Lance Ramshaw, Stephanie Strassel, and Ralph Weischedel. 2004. The automatic content extraction (ace) program-tasks, data, and evaluation. In LREC, pages 837--840
work page 2004
-
[17]
Besnik Fetahu, Anjie Fang, Oleg Rokhlenko, and Shervin Malmasi. 2022. Dynamic gazetteer integration in multilingual models for cross-lingual and cross-domain named entity recognition. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2777--2790
work page 2022
- [18]
-
[19]
Andrea Gasparetto, Matteo Marcuzzo, Alessandro Zangari, and Andrea Albarelli. 2022. A survey on text classification algorithms: From text to predictions. Information, 13(2):83
work page 2022
-
[20]
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. 2021. Datasheets for datasets. Communications of the ACM, 64(12):86--92
work page 2021
-
[21]
Corrado Gini. 1921. Measurement of inequality of incomes. The economic journal, 31(121):124--125
work page 1921
-
[22]
Dirk Hovy and Shannon L Spruit. 2016. The social impact of natural language processing. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, pages 591--598
work page 2016
-
[23]
Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, et al. 2024 a . Minicpm: Unveiling the potential of small language models with scalable training strategies. arXiv preprint arXiv:2404.06395
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Yan Hu, Qingyu Chen, Jingcheng Du, Xueqing Peng, Vipina Kuttichi Keloth, Xu Zuo, Yujia Zhou, Zehan Li, Xiaoqian Jiang, Zhiyong Lu, et al. 2024 b . Improving large language models for clinical named entity recognition via prompt engineering. Journal of the American Medical Informatics Association, page ocad259
work page 2024
-
[25]
HuggingFace. 2024. Open source ai year in review 2024. https://huggingface.co/spaces/huggingface/open-source-ai-year-in-review-2024
work page 2024
-
[26]
Vipina K Keloth, Yan Hu, Qianqian Xie, Xueqing Peng, Yan Wang, Andrew Zheng, Melih Selek, Kalpana Raja, Chih Hsuan Wei, Qiao Jin, et al. 2024. Advancing entity recognition in biomedicine via instruction tuning of large language models. Bioinformatics, 40(4):btae163
work page 2024
-
[27]
Jin-Dong Kim, Tomoko Ohta, Yuka Tateisi, and Jun'ichi Tsujii. 2003. Genia corpus—a semantically annotated corpus for bio-textmining. In Bioinformatics, volume 19, pages i180--i182. Oxford University Press
work page 2003
- [28]
- [29]
- [30]
-
[31]
Xuezhe Li and Xiaodan Sun. 2020. Dice loss for data-imbalanced nlp tasks: Application to named entity recognition. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4653--4661
work page 2020
-
[32]
Hongbin Liu, Ruixuan Xu, and Wei Xu. 2021. https://doi.org/10.18653/v1/2021.acl-long.385 C ross NER : Evaluating cross-domain named entity recognition . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4984--4...
-
[33]
Shervin Malmasi, Ning Zhang, Daniella Semedo, Ryan Ip, Aitor Gonzalez Aguirre, Leon Derczynski, and Isabelle Augenstein. 2022. https://aclanthology.org/2022.lrec-1.547 M ulti C o NER : A large-scale multilingual dataset for complex named entity recognition . In Proceedings of the 13th Language Resources and Evaluation Conference, pages 5102--5112. Europea...
work page 2022
-
[34]
Tao Meng, Anjie Fang, Oleg Rokhlenko, and Shervin Malmasi. 2021. https://doi.org/10.18653/v1/2021.naacl-main.118 Gemnet: Effective gated gazetteer representations for recognizing complex entities in low-context input . In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Techn...
-
[35]
Humza Naveed, Asad Ullah Khan, Shi Qiu, Muhammad Saqib, Saeed Anwar, Muhammad Usman, Naveed Akhtar, Nick Barnes, and Ajmal Mian. 2023. A comprehensive overview of large language models. arXiv preprint arXiv:2307.06435
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Thien Huu Nguyen and Hung Le Cao. 2010. Nested named entity recognition using maximum entropy models. In Proceedings of the 24th International Conference on Computational Linguistics (COLING), pages 2010--2018. ACL
work page 2010
-
[37]
Rasha Obeidat, Xiaoli Fern, Hamed Shahbazi, and Prasad Tadepalli. 2019. Description-based zero-shot fine-grained entity typing. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 807--814
work page 2019
-
[38]
Xiaoman Pan, Boliang Zhang, Jonathan May, Joel Nothman, Kevin Knight, and Heng Ji. 2017. https://doi.org/10.18653/v1/P17-1178 Cross-lingual name tagging and linking for 282 languages . In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1946--1958, Vancouver, Canada. Association for Com...
-
[39]
Sameer Pradhan, Alessandro Moschitti, Nianwen Xue, Hwee Tou Ng, Anders Bj \"o rkelund, Olga Uryupina, Yuchen Zhang, and Zhi Zhong. 2013. Towards robust linguistic analysis using OntoNotes . In Proceedings of the Seventeenth Conference on Computational Natural Language Learning, pages 143--152. Association for Computational Linguistics
work page 2013
-
[40]
Xiang Ren, Wenqi He, Meng Qu, Clare R Voss, Heng Ji, and Jiawei Han. 2016. Label noise reduction in entity typing by heterogeneous partial-label embedding. In Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining, pages 1825--1834
work page 2016
-
[41]
Prateek Sancheti, Kamalakar Karlapalem, and Kavita Vemuri. 2024. Llm driven web profile extraction for identical names. In Companion Proceedings of the ACM on Web Conference 2024, pages 1616--1625
work page 2024
- [42]
- [43]
-
[44]
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivi \`e re, Mihir Sanjay Kale, Juliette Love, et al. 2024. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Erik F. Tjong Kim Sang. 2002. https://aclanthology.org/W02-2024 Introduction to the C o NLL -2002 shared task: Language-independent named entity recognition . In Proceedings of the 6th Conference on Natural Language Learning ( C o NLL -2002) , pages 155--158
work page 2002
-
[46]
Tjong Kim Sang and Fien De Meulder
Erik F. Tjong Kim Sang and Fien De Meulder. 2003. https://aclanthology.org/W03-0419 Introduction to the C o NLL-2003 shared task: Language-independent named entity recognition . In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003 , pages 142--147. Association for Computational Linguistics
work page 2003
- [47]
-
[48]
Christopher Walker, Stephanie Strassel, Julie Medero, and Kazuaki Maeda. 2006. Ace 2005 multilingual training corpus. In Linguistic Data Consortium, Philadelphia
work page 2006
- [49]
- [50]
-
[51]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824--24837
work page 2022
-
[52]
Ralph Weischedel, Sameer Pradhan, Lance Ramshaw, Martha Palmer, Nianwen Xue, Mitchell Marcus, Ann Taylor, Claudette Greenberg, Eduard Hovy, Robert Belvin, et al. 2011. Ontonotes: A large training corpus for enhanced processing. In Handbook of Natural Language Processing and Machine Translation, pages 54--63. Springer
work page 2011
- [53]
- [54]
- [55]
- [56]
-
[57]
Dawen Zhang, Pamela Finckenberg-Broman, Thong Hoang, Shidong Pan, Zhenchang Xing, Mark Staples, and Xiwei Xu. 2024. Right to be forgotten in the era of large language models: Implications, challenges, and solutions. AI and Ethics, pages 1--10
work page 2024
-
[58]
Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. 2022. Automatic chain of thought prompting in large language models. arXiv preprint arXiv:2210.03493
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.