Scaffold, Not Vocabulary? A Controlled, Two-Tier, Pre-Registered Study of a Popperian Code-Generation Skill
Pith reviewed 2026-06-28 00:06 UTC · model grok-4.3
The pith
Popperian prompt skill for code generation adds no separable correctness benefit beyond a labels-only scaffold.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
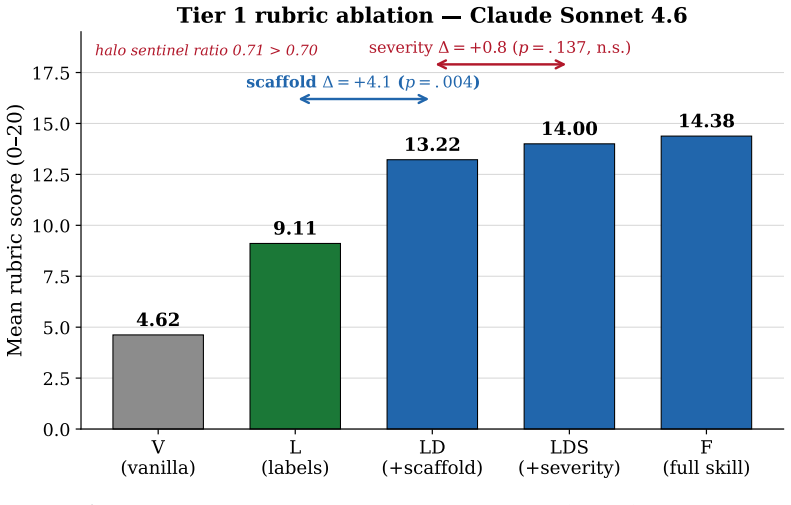
In the two settings tested, the skill's Popperian procedural content adds no separable execution-correctness benefit beyond a labels-only scaffold, so the gains track scaffold structure.
What carries the argument
Two-tier pre-registered ablation with length-matched placebo, labels-only scaffold (Popperian headers without procedure), execution oracle via HumanEval+ unit tests, vocabulary-halo sentinel, and same-model self-judge audit.
Load-bearing premise
The labels-only scaffold successfully isolates the Popperian procedural content while the length-matched placebo and execution oracle provide unbiased measures of any added value from that content.
What would settle it
A replication experiment on the same or similar models and benchmarks that finds the full Popperian skill produces a statistically significant improvement in execution correctness over the labels-only scaffold with adequate sample size and no ceiling effects.
Figures



read the original abstract
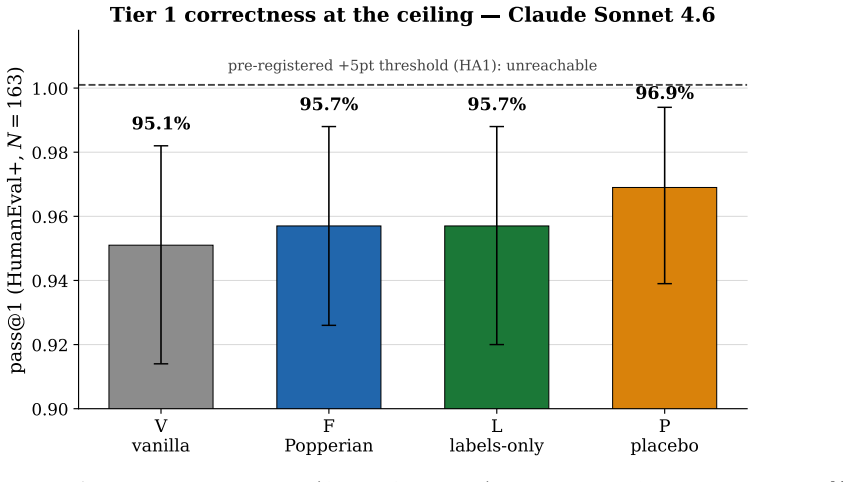
Large language models increasingly write, review, and judge code, and a fast-growing practice equips them with prompt 'skills' that ask the model to reason like a scientist. A prominent example tells the model to act as a Popperian falsificationist, and such skills are reported to improve generated code. But these gains are almost always read off an LLM-as-a-judge, an instrument with documented positional, self-preference, and stylistic biases. We ask: if it appears to help, is the gain from the skill's Popperian content, or from the structure any scaffold imposes? We pre-register a two-tier ablation with three controls: a length-matched placebo, a labels-only scaffold that keeps the Popperian headers but strips the procedure, and an execution oracle (HumanEval+ unit tests), plus a vocabulary-halo sentinel and a same-model self-judge audit. On a frontier model (Claude Sonnet 4.6, N=163) all conditions sit near the benchmark ceiling and do not separate, so the pre-registered +5-point improvement is not supported (a ceiling-limited non-detection). On a small model (Qwen2.5-Coder-0.5B, N=164) structured arms lift best-of-eight correctness by 20-22 points, but the full skill shows no separable benefit over a labels-only scaffold (aggregate F@8=L@8 vs V@8=34.8%), and the placebo trails by only 2.4 points. A 0.5B self-judge applying the Popperian rubric does not beat random selection and concentrates 60% of its picks on one index. In the two settings tested, the skill's Popperian procedural content adds no separable execution-correctness benefit beyond a labels-only scaffold, so the gains track scaffold structure. We contribute a calibrated negative result and a reusable disambiguation protocol; the finding bounds an engineering claim about one prompt-skill family and is not an evaluation of Popperian methodology in general.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a pre-registered two-tier ablation study testing whether a Popperian falsificationist prompt skill for code generation provides execution-correctness gains beyond those from scaffold structure alone. Using HumanEval+ unit tests as oracle on Claude Sonnet 4.6 (N=163) and Qwen2.5-Coder-0.5B (N=164), with controls including a labels-only scaffold, length-matched placebo, vocabulary-halo sentinel, and same-model self-judge, it finds ceiling-limited non-separation on the frontier model and, on the small model, ~20-point gains from structured scaffolds but no separable benefit from the full Popperian procedure over the labels-only version (F@8=L@8 vs V@8 at 34.8%).
Significance. If the central result holds, the work supplies a calibrated negative finding that bounds engineering claims for one prompt-skill family, demonstrates the value of execution oracles over LLM-as-judge, and supplies a reusable disambiguation protocol. Strengths include explicit pre-registration, multiple models, length/structure-matched controls, and avoidance of self-referential evaluation; these elements make the negative result more informative than typical positive prompt-engineering reports.
major comments (1)
- Abstract and results sections: the non-detection on Claude Sonnet 4.6 is explicitly attributed to ceiling effects, yet without reported per-condition variances, confidence intervals on the +5-point target, or a post-hoc power calculation, the strength of evidence for 'no separable benefit' in that setting remains limited and should be quantified to support the aggregate claim.
minor comments (2)
- Abstract: the self-judge audit result (random selection not beaten, 60% concentration on one index) is reported but its exact selection procedure and tie-breaking rule are not stated, which would aid reproducibility of the audit.
- Methods: the length-matching procedure for the placebo scaffold and the precise token counts or structural elements retained in the labels-only condition should be tabulated for direct verification that procedural content was isolated.
Simulated Author's Rebuttal
We thank the referee for the constructive comment and the recommendation for minor revision. We address the single major comment below and will strengthen the quantification of the non-detection result.
read point-by-point responses
-
Referee: Abstract and results sections: the non-detection on Claude Sonnet 4.6 is explicitly attributed to ceiling effects, yet without reported per-condition variances, confidence intervals on the +5-point target, or a post-hoc power calculation, the strength of evidence for 'no separable benefit' in that setting remains limited and should be quantified to support the aggregate claim.
Authors: We agree that additional quantification would make the ceiling-limited non-detection claim more robust. In the revised manuscript we will add (1) per-condition variances (or standard deviations) for the Claude Sonnet 4.6 results, (2) 95% confidence intervals on all pairwise differences, explicitly including the interval around the pre-registered +5-point target, and (3) a brief post-hoc power discussion based on the observed variances and N=163. These additions will be placed in the results section and referenced from the abstract; they do not alter the pre-registered analysis plan or the interpretation that the experiment was under-powered to detect small effects near ceiling. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper reports a pre-registered empirical ablation study on prompt skills for code generation. It measures outcomes via an external execution oracle (HumanEval+ unit tests) and includes controls such as a labels-only scaffold, length-matched placebo, and vocabulary-halo sentinel. No load-bearing derivation, equation, or self-citation reduces the central claim (that gains track scaffold structure rather than Popperian procedural content) to fitted parameters or self-referential definitions by construction. The analysis is self-contained against external benchmarks and pre-registered protocols.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions for comparing correctness rates across prompt conditions (e.g., independence of trials, appropriate statistical tests for proportions).
Reference graph
Works this paper leans on
-
[1]
2021 , eprint =
Mark Chen and Jerry Tworek and Heewoo Jun and Qiming Yuan and Henrique Ponde de Oliveira Pinto and Jared Kaplan and others , title =. 2021 , eprint =
2021
-
[2]
Koo and Mae Y
Terry K. Koo and Mae Y. Li , title =. Journal of Chiropractic Medicine , volume =. 2016 , doi =
2016
-
[3]
DiCiccio and Bradley Efron , title =
Thomas J. DiCiccio and Bradley Efron , title =. Statistical Science , volume =. 1996 , doi =
1996
-
[4]
Popper , title =
Karl R. Popper , title =. 1959 , publisher =
1959
-
[5]
Popper , title =
Karl R. Popper , title =. 1963 , publisher =
1963
-
[6]
2004 , publisher =
Klaus Krippendorff , title =. 2004 , publisher =
2004
-
[7]
Findings of the Association for Computational Linguistics:
Jiwon Moon and Yerin Hwang and Dongryeol Lee and Taegwan Kang and Yongil Kim and Kyomin Jung , title =. Findings of the Association for Computational Linguistics:. 2026 , month =. doi:10.18653/v1/2026.findings-eacl.70 , note =
-
[8]
2026 , eprint =
Zixiao Zhao and Amirreza Esmaeili and Fatemeh Fard , title =. 2026 , eprint =
2026
-
[9]
Proceedings of the 31st International Conference on Computational Linguistics , pages =
Yuwei Zhao and Ziyang Luo and Yuchen Tian and Hongzhan Lin and Weixiang Yan and Annan Li and Jing Ma , title =. Proceedings of the 31st International Conference on Computational Linguistics , pages =. 2025 , month =
2025
-
[10]
Haolin Jin and Huaming Chen , title =. 2025 40th. 2025 , publisher =. doi:10.1109/ASE63991.2025.00323 , isbn =
-
[11]
Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or:
Sclar, Melanie and Choi, Yejin and Tsvetkov, Yulia and Suhr, Alane , booktitle =. Quantifying Language Models' Sensitivity to Spurious Features in Prompt Design or:. 2024 , note =
2024
-
[12]
Understanding the Prompt Sensitivity , author =. 2026 , month =. 2604.18389 , archivePrefix =
Pith/arXiv arXiv 2026
-
[13]
ACM Transactions on Software Engineering and Methodology , year =
Guoqing Wang and Zeyu Sun and Sixiang Ye and Zhihao Gong and Yizhou Chen and Yifan Zhao and Qingyuan Liang and Dan Hao , title =. ACM Transactions on Software Engineering and Methodology , year =. doi:10.1145/3771933 , note =
-
[14]
A Looming Replication Crisis in Evaluating Behavior in Language Models?
Vaugrante, Laur. A Looming Replication Crisis in Evaluating Behavior in Language Models?. 2024 , eprint =
2024
-
[15]
Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (EACL 2026), Volume 1: Long Papers , pages =
Yujia Zheng and Tianhao Li and Haotian Huang and Tianyu Zeng and Jingyu Lu and Chuangxin Chu and Yuekai Huang and Ziyou Jiang and Qian Xiong and Yuyao Ge and Mingyang Li , title =. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (EACL 2026), Volume 1: Long Papers , pages =. 2026 , month =
2026
-
[16]
Tattva-Journal of Philosophy , year =
Suddhachit Mitra , title =. Tattva-Journal of Philosophy , year =. doi:10.12726/tjp.23.1 , issn =
-
[17]
Passmore, J. A. , title =. Philosophy , year =
-
[18]
2019 , note =
Shea, Brendan , title =. 2019 , note =
2019
-
[19]
Deborah G. Mayo , title =. British Journal for the Philosophy of Science , year =. doi:10.1086/736950 , url =
-
[20]
Mayo and Aris Spanos , title =
Deborah G. Mayo and Aris Spanos , title =. The British Journal for the Philosophy of Science , year =. doi:10.1093/bjps/axl003 , publisher =
-
[21]
, title =
Mayo, Deborah G. , title =. Rationality and Reality: Conversations with Alan Musgrave , editor =. 2006 , isbn =
2006
-
[22]
Studies in History and Philosophy of Science Part A , year =
Niiniluoto, Ilkka , title =. Studies in History and Philosophy of Science Part A , year =. doi:10.1016/j.shpsa.2014.02.002 , url =
-
[23]
Ilkka Niiniluoto , title =. Synthese , year =. doi:10.1007/s11229-018-01975-z , note =
-
[24]
The Philosophical Quarterly , year =
Samir Okasha , title =. The Philosophical Quarterly , year =. doi:10.1111/1467-9213.00270 , url =
-
[25]
Proceedings of the Aristotelian Society , series =
Lakatos, Imre , title =. Proceedings of the Aristotelian Society , series =. 1968 , pages =
1968
-
[26]
Falsificationism and the structure of theories: the
Jos. Falsificationism and the structure of theories: the. Studies in History and Philosophy of Science Part. 2007 , volume =. doi:10.1016/j.shpsa.2007.06.007 , url =
-
[27]
Vranje. Design Principles for Falsifiable, Replicable and Reproducible Empirical Machine Learning Research , booktitle =. 2024 , publisher =. doi:10.4230/OASIcs.DX.2024.7 , arxiv =
-
[28]
Groce, Alex and Ahmed, Iftekhar and Jensen, Carlos and McKenney, Paul E. , title =. Proceedings of the 2015 30th. 2015 , month = nov, publisher =. doi:10.1109/ASE.2015.40 , note =
-
[29]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
Peiyi Wang and Lei Li and Liang Chen and Zefan Cai and Dawei Zhu and Binghuai Lin and Yunbo Cao and Lingpeng Kong and Qi Liu and Tianyu Liu and Zhifang Sui , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , month =
2024
-
[30]
Quantifying and Mitigating Self-Preference Bias of
Yang, Jinming and Hu, Zheng and Qiu, Chuxian and Deng, Zhenyu and Jiao, Xinshan and Zhou, Tao , year =. Quantifying and Mitigating Self-Preference Bias of. 2604.22891 , archivePrefix=
-
[31]
Play Favorites: A Statistical Method to Measure Self-Bias in
Evangelia Spiliopoulou and Riccardo Fogliato and Hanna Burnsky and Tamer Soliman and Jie Ma and Graham Horwood and Miguel Ballesteros , year =. Play Favorites: A Statistical Method to Measure Self-Bias in. 2508.06709 , archivePrefix=
-
[32]
Marzi, Giacomo and Balzano, Marco and Marchiori, Davide , title =. MethodsX , year =. doi:10.1016/j.mex.2023.102545 , url =
-
[33]
and Sun, Yijun and Zhu, Ray and Murphy, Diane K
Mehta, Shraddha and Bastero-Caballero, Rowena F. and Sun, Yijun and Zhu, Ray and Murphy, Diane K. and Hardas, Bhushan and Koch, Gary , title =. Statistics in Medicine , year =. doi:10.1002/sim.7679 , url =
-
[34]
Xiangkun Sun and Lingkai Kong and Aoqi Zhang and Liang Zeng and Tonghan Wang , year =. How. 2605.09314 , archivePrefix =
-
[35]
2026 , eprint =
Andrew Lauziere and Jonathan Daugherty and Taisa Kushner , title =. 2026 , eprint =
2026
-
[36]
Yu and Hong-Han Shuai , title =
Tzu-Ling Lin and Wei-Chih Chen and Teng-Fang Hsiao and Hou-I Liu and Ya-Hsin Yeh and Yu-Kai Chan and Wen-Sheng Lien and Po-Yen Kuo and Philip S. Yu and Hong-Han Shuai , title =. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages =. 2025 , month =
2025
-
[37]
Proceedings of the 31st International Conference on Computational Linguistics , month = jan, year =
Style Over Substance: Evaluation Biases for Large Language Models , author =. Proceedings of the 31st International Conference on Computational Linguistics , month = jan, year =
-
[38]
Planning in Natural Language Improves
Evan Wang and Federico Cassano and Catherine Wu and Yunfeng Bai and William Song and Vaskar Nath and Ziwen Han and Sean Hendryx and Summer Yue and Hugh Zhang , booktitle =. Planning in Natural Language Improves. 2025 , note =
2025
-
[39]
Adian Liusie and Potsawee Manakul and Mark J. F. Gales , title =. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , month =
2024
-
[40]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
Zongjie Li and Chaozheng Wang and Pingchuan Ma and Daoyuan Wu and Shuai Wang and Cuiyun Gao and Yang Liu , title =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =. 2024 , month =
2024
-
[41]
Journal of Software: Evolution and Process , year =
Xiangyue Liu and Xiaobing Sun and Lili Bo and Yufei Hu and Xinwei Liu and Zhenlei Ye , title =. Journal of Software: Evolution and Process , year =. doi:10.1002/smr.70034 , url =
-
[42]
Advances in Neural Information Processing Systems , volume =
Jiawei Liu and Chunqiu Steven Xia and Yuyao Wang and Lingming Zhang , title =. Advances in Neural Information Processing Systems , volume =. 2023 , note =
2023
-
[43]
Proceedings of the Fortieth AAAI Conference on Artificial Intelligence (AAAI-26) , pages =
Hongli Zhou and Hui Huang and Ziqing Zhao and Lvyuan Han and Huicheng Wang and Kehai Chen and Muyun Yang and Wei Bao and Jian Dong and Bing Xu and Conghui Zhu and Hailong Cao and Tiejun Zhao , title =. Proceedings of the Fortieth AAAI Conference on Artificial Intelligence (AAAI-26) , pages =. 2026 , publisher =
2026
-
[44]
On Leakage of Code Generation Evaluation Datasets , booktitle =
Alexandre Matton and Tom Sherborne and Dennis Aumiller and Elena Tommasone and Milad Alizadeh and Jingyi He and Raymond Ma and Maxime Voisin and Ellen Gilsenan-McMahon and Matthias Gall\'. On Leakage of Code Generation Evaluation Datasets , booktitle =. 2024 , month = nov, address =
2024
-
[45]
and Lydersen, Stian and Laake, Petter , title =
Fagerland, Morten W. and Lydersen, Stian and Laake, Petter , title =. BMC Medical Research Methodology , year =. doi:10.1186/1471-2288-13-91 , url =
-
[46]
Statistics in Medicine , year =
Toshiro Tango , title =. Statistics in Medicine , year =. doi:10.1002/(SICI)1097-0258(19980430)17:8<891::AID-SIM780>3.0.CO;2-B , url =
-
[47]
2025 , eprint =
Wei Ma and Yixiao Yang and Jingquan Ge and Xiaofei Xie and Lingxiao Jiang , title =. 2025 , eprint =
2025
-
[48]
Yash Mundhra and Max Valk and Maliheh Izadi , title =. 2025 , howpublished =. 2509.12395 , archivePrefix=
arXiv 2025
-
[49]
The Twelfth International Conference on Learning Representations , year =
Teaching Large Language Models to Self-Debug , author =. The Twelfth International Conference on Learning Representations , year =
-
[50]
Qingjie Zhang and Di Wang and Haoting Qian and Yiming Li and Tianwei Zhang and Minlie Huang and Ke Xu and Hewu Li and Yan Liu and Han Qiu , title =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2025 , month =. doi:10.18653/v1/2025.acl-long.1314 , note =
-
[51]
: Larger and more instructable language models become less reliable
Lexin Zhou and Wout Schellaert and Fernando Mart. Larger and more instructable language models become less reliable , journal =. 2024 , volume =. doi:10.1038/s41586-024-07930-y , url =
-
[52]
Advances in Neural Information Processing Systems , volume =
Takeshi Kojima and Shixiang Shane Gu and Machel Reid and Yutaka Matsuo and Yusuke Iwasawa , title =. Advances in Neural Information Processing Systems , volume =. 2022 , publisher =
2022
-
[53]
Ionut Daniel Fagadau and Leonardo Mariani and Daniela Micucci and Oliviero Riganelli , title =. Proceedings of the 32nd IEEE/ACM International Conference on Program Comprehension (ICPC '24) , pages =. 2024 , month =. doi:10.1145/3643916.3644409 , isbn =
-
[54]
When Prompt Under-Specification Improves Code Correctness: An Exploratory Study of Prompt Wording and Structure Effects on
Amal Akli and Mike Papadakis and Maxime Cordy and Yves. When Prompt Under-Specification Improves Code Correctness: An Exploratory Study of Prompt Wording and Structure Effects on. 2026 , eprint =
2026
-
[55]
IEEE Transactions on Software Engineering , volume =
Ranim Khojah and Francisco Gomes de Oliveira Neto and Mazen Mohamad and Philipp Leitner , title =. IEEE Transactions on Software Engineering , volume =. 2025 , month = aug, doi =
2025
-
[56]
The Twelfth International Conference on Learning Representations , year =
Large Language Models Cannot Self-Correct Reasoning Yet , author =. The Twelfth International Conference on Learning Representations , year =. 2310.01798 , archivePrefix =
-
[57]
2023 , eprint =
Karthik Valmeekam and Matthew Marquez and Subbarao Kambhampati , title =. 2023 , eprint =
2023
-
[58]
2024 , eprint =
Confidence Matters: Revisiting Intrinsic Self-Correction Capabilities of Large Language Models , author =. 2024 , eprint =
2024
-
[59]
Fabian Lukassen and Jan Herrmann and Christoph Weisser and Alexander Silbersdorff and Benjamin Saefken and Thomas Kneib , title =. 2026 , note =. 2605.26770 , archivePrefix =
Pith/arXiv arXiv 2026
-
[60]
Examining Reasoning
Yixin Liu and Yue Yu and DiJia Su and Sid Wang and Xuewei Wang and Song Jiang and Bo Liu and Arman Cohan and Yuandong Tian and Zhengxing Chen , year =. Examining Reasoning
-
[61]
Label Effects: Shared Heuristic Reliance in Trust Assessment by Humans and
Xin Sun and Di Wu and Sijing Qin and Isao Echizen and Abdallah. Label Effects: Shared Heuristic Reliance in Trust Assessment by Humans and. 2026 , eprint =
2026
-
[62]
Vaccaro, Michelle , title =. 2026 , howpublished =. doi:10.2139/ssrn.6732238 , url =
-
[63]
Cohn and José Hernández-Orallo , title =
María Victoria Carro and Ryan Burnell and Carlos Mougan and Anka Reuel and Wout Schellaert and Olawale Elijah Salaudeen and Lexin Zhou and Patricia Paskov and Anthony G. Cohn and José Hernández-Orallo , title =. 2026 , note =
2026
-
[64]
A Two-Sided Discussion of Preregistration of
Anders S. A Two-Sided Discussion of Preregistration of. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages =. 2023 , month =. doi:10.18653/v1/2023.eacl-main.6 , note =
-
[65]
Bowman , title =
Miles Turpin and Julian Michael and Ethan Perez and Samuel R. Bowman , title =. Advances in Neural Information Processing Systems , volume =. 2023 , note =
2023
-
[66]
Anna Neumann and Elisabeth Kirsten and Muhammad Bilal Zafar and Jatinder Singh , title =. The 2025 ACM Conference on Fairness, Accountability, and Transparency (FAccT '25) , year =. doi:10.1145/3715275.3732038 , isbn =
-
[67]
Abeba Birhane and Pratyusha Kalluri and Dallas Card and William Agnew and Ravit Dotan and Michelle Bao , title =. Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency , series =. 2022 , pages =. doi:10.1145/3531146.3533083 , isbn =
-
[68]
Smith and Saleema Amershi and Solon Barocas and Hanna Wallach and Jennifer Wortman Vaughan , title =
Jessie J. Smith and Saleema Amershi and Solon Barocas and Hanna Wallach and Jennifer Wortman Vaughan , title =. Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency , series =. 2022 , pages =. doi:10.1145/3531146.3533122 , isbn =
-
[69]
Penn F. Rainford and Annalisa Occhipinti and Bo Wang and Susan Stepney and Claudio Angione and Suraj Verma and Lucia Marucci and Kieren Sharma and Sarah A. Harris and Rudolf M. F. Knowledge preservation in the era of big science and. Nature Communications , year =. doi:10.1038/s41467-026-72667-3 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.