Reasoning Text-to-Video Retrieval for Operating Room Clips via Action-Driven Digital Twins
Pith reviewed 2026-06-27 03:23 UTC · model grok-4.3
The pith
Action-driven digital twins let text-to-video retrieval handle implicit queries in operating room clips by reasoning over temporal action sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
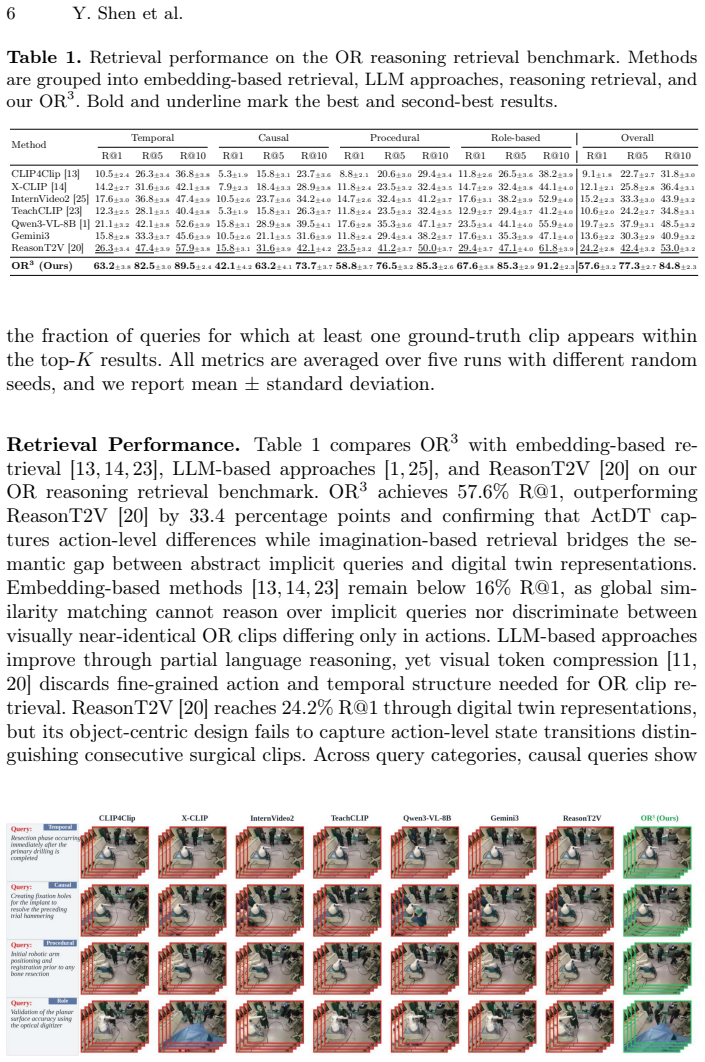
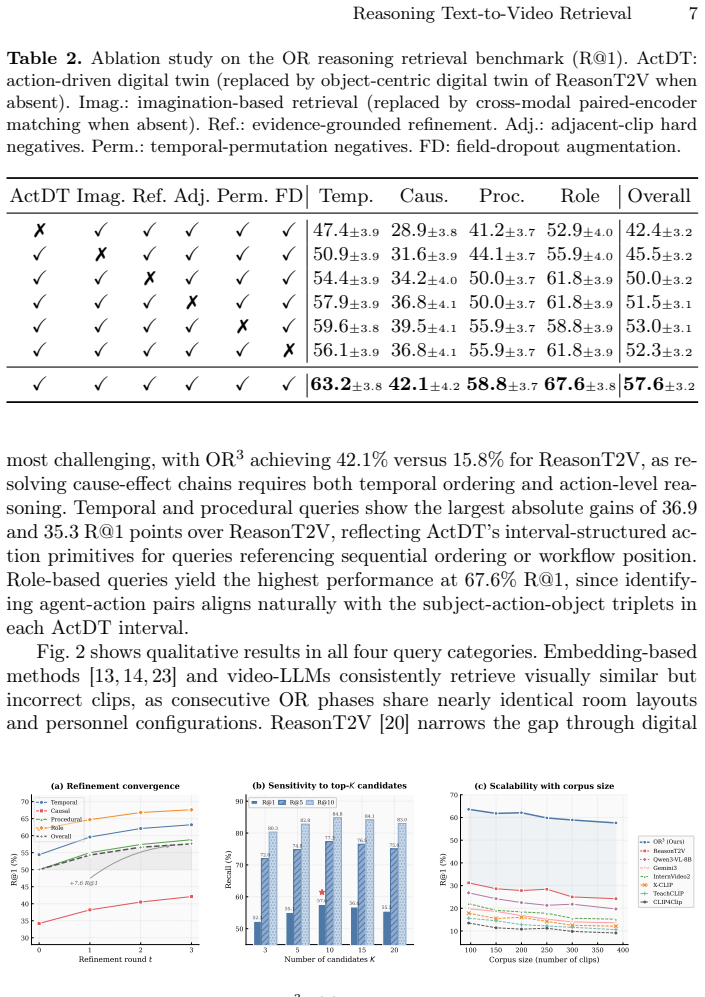
OR3 converts clips into action-driven digital twins by grouping concurrent subject-action-object triplets under non-overlapping temporal intervals, generates hypothetical ActDTs from text queries via LLM, performs intra-modal matching with a single encoder trained on ActDT-specific hard negatives, and applies evidence-grounded refinement that revises the imagined twins based on discrepancies with top video candidates, yielding 57.6 R@1 and 77.3 R@5 on a benchmark of 276 implicit queries over 386 robotic knee procedure clips.
What carries the argument
action-driven digital twins (ActDTs), formed by grouping concurrent subject-action-object triplets under non-overlapping temporal intervals, which carry the temporal structure needed for LLM imagination and intra-modal matching.
If this is right
- Retrieval becomes possible for safety-critical events that deviate from typical procedure flow.
- Fine-grained discrimination is achieved between clips that look similar but differ in action sequence or timing.
- A single encoder suffices for matching without separate text and video towers.
- Procedure-specific patterns can be captured through iterative refinement against real video evidence.
Where Pith is reading between the lines
- The same interval-based triplet representation could be applied to other procedural domains such as industrial assembly or sports coaching.
- Real-time ActDT extraction during live procedures might support predictive alerts before an unsafe step occurs.
- Iterative refinement opens a path to conversational retrieval where a user can correct or extend the imagined twin.
Load-bearing premise
Grouping concurrent subject-action-object triplets into non-overlapping temporal intervals to form ActDTs, combined with LLM-generated hypothetical ActDTs and evidence-grounded refinement, sufficiently captures the reasoning needed to identify the correct clip for implicit queries.
What would settle it
A controlled test set of query-clip pairs where two clips differ only in the temporal ordering of two overlapping actions; if OR3 retrieval accuracy drops to baseline levels on these pairs, the ActDT interval grouping does not capture the required reasoning.
Figures

read the original abstract
Text-to-video retrieval in operating rooms (OR) is an enabling technology for OR safety, as it allows stakeholders to retrieve and inspect recordings of specific events. However, because the most safety-critical events may not follow the common structure, to unlock its full potential text-to-video retrieval must be able to handle implicit queries that require reasoning to identify the right video (e.g., the step right before clipping). However, existing methods rely on global embeddings that cannot reason over such queries. We propose OR3, a text-to-video retrieval method that converts clips into action-driven digital twins (ActDTs), grouping concurrent subject-action-object triplets under non-overlapping temporal intervals. Moreover, rather than cross-modal matching through paired encoders, OR3 performs imagination-based retrieval where an LLM generates hypothetical ActDTs from queries. This enables intra-modal matching via a single encoder trained with ActDT-tailored hard negatives. Finally, evidence-grounded refinement revises imagined ActDTs based on discrepancies with top candidates to capture procedure-specific patterns. We construct a benchmark from MM-OR with 276 implicit queries across four reasoning categories over 386 clips from robotic knee procedures. OR3 achieves 57.6 R@1 and 77.3 R@5, outperforming the strongest baseline. These results demonstrate that OR3 enables fine-grained discrimination between visually similar OR video clips through temporal action reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces OR3 for text-to-video retrieval on operating room clips, converting videos to action-driven digital twins (ActDTs) by grouping concurrent subject-action-object triplets into non-overlapping temporal intervals. It performs imagination-based retrieval by having an LLM generate hypothetical ActDTs from implicit queries (e.g., 'the step right before clipping'), followed by intra-modal matching via a single encoder trained with ActDT-tailored hard negatives and evidence-grounded refinement of the imagined ActDTs. A new benchmark is constructed from MM-OR comprising 276 implicit queries across four reasoning categories on 386 robotic knee procedure clips; OR3 reports 57.6 R@1 and 77.3 R@5, outperforming the strongest baseline and enabling fine-grained discrimination via temporal action reasoning.
Significance. If the central results hold, the work offers a concrete advance in reasoning-capable retrieval for safety-critical procedural video, moving beyond global embeddings to handle implicit queries that standard methods cannot address. The ActDT representation, LLM imagination pipeline, and new benchmark provide a reusable framework with direct applicability to OR safety inspection; the reported margins on a non-trivial query set constitute a falsifiable starting point for the community.
major comments (2)
- [Abstract and ActDT construction description] The central claim (57.6 R@1 on implicit queries) rests on the assertion that grouping concurrent triplets into non-overlapping temporal intervals plus LLM-generated/refined ActDTs suffices to model the required reasoning. The manuscript provides no quantitative assessment of triplet extraction accuracy, information loss from discarding overlaps/ordering, or how often evidence-grounded refinement corrects hallucinations; without these, the performance margin cannot be attributed to the proposed mechanism rather than benchmark artifacts.
- [Evaluation / benchmark section] Benchmark construction (276 queries, four reasoning categories, 386 clips from MM-OR): the outperformance claim is load-bearing on the queries being genuinely implicit and free of selection effects, yet no details are given on query generation process, inter-annotator agreement, or per-category breakdown of results, making it impossible to rule out that the reported gains are driven by easier subsets or construction biases.
minor comments (2)
- The four reasoning categories are referenced but not explicitly defined or exemplified; adding a table or appendix listing representative queries per category would improve reproducibility.
- Clarify the exact form of the ActDT representation (e.g., how intervals are encoded for the single encoder) and whether any temporal ordering information is explicitly preserved beyond the non-overlapping grouping.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for additional validation of the ActDT pipeline and benchmark construction. We address each major comment below and will incorporate revisions to strengthen the attribution of results to the proposed mechanisms.
read point-by-point responses
-
Referee: [Abstract and ActDT construction description] The central claim (57.6 R@1 on implicit queries) rests on the assertion that grouping concurrent triplets into non-overlapping temporal intervals plus LLM-generated/refined ActDTs suffices to model the required reasoning. The manuscript provides no quantitative assessment of triplet extraction accuracy, information loss from discarding overlaps/ordering, or how often evidence-grounded refinement corrects hallucinations; without these, the performance margin cannot be attributed to the proposed mechanism rather than benchmark artifacts.
Authors: We agree that quantitative assessments of triplet extraction accuracy, the effects of discarding overlaps/ordering, and the correction rate of evidence-grounded refinement would strengthen the paper and help attribute gains to the ActDT representation. The current manuscript focuses on end-to-end retrieval performance and does not include these component-level analyses. In revision we will add: (1) triplet extraction accuracy measured against available annotations in MM-OR, (2) an analysis of information loss by comparing ActDTs with and without overlap handling on a subset of clips, and (3) statistics on the frequency and nature of changes introduced by the refinement step across the 276 queries. revision: yes
-
Referee: [Evaluation / benchmark section] Benchmark construction (276 queries, four reasoning categories, 386 clips from MM-OR): the outperformance claim is load-bearing on the queries being genuinely implicit and free of selection effects, yet no details are given on query generation process, inter-annotator agreement, or per-category breakdown of results, making it impossible to rule out that the reported gains are driven by easier subsets or construction biases.
Authors: We agree that explicit documentation of the query generation process, inter-annotator agreement, and per-category results is necessary to substantiate that the queries are implicit and that gains are not driven by construction artifacts. The manuscript states only the final counts and categories. In the revision we will add: (1) a detailed description of the expert-driven query generation protocol used to create the 276 implicit queries across the four reasoning categories, (2) inter-annotator agreement statistics computed during query validation, and (3) a per-category breakdown of R@1 and R@5 for OR3 and baselines. revision: yes
Circularity Check
No circularity; new components and benchmark are self-contained
full rationale
The paper defines ActDTs, the non-overlapping triplet grouping procedure, LLM imagination step, hard-negative training, and evidence-grounded refinement entirely within the present work; the benchmark is newly built from MM-OR rather than reusing prior fitted quantities. No equations, uniqueness claims, or performance predictions reduce by construction to self-citations or to the inputs themselves. The reported R@1/R@5 numbers are empirical outcomes on the new implicit-query set and do not collapse to tautological renaming or fitted-input predictions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Action-driven digital twins formed by grouping concurrent subject-action-object triplets under non-overlapping temporal intervals capture the temporal and semantic structure needed for reasoning over implicit OR queries.
invented entities (1)
-
Action-driven digital twins (ActDTs)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
SAM 3: Segment Anything with Concepts
Nicolas Carion et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Cross-modal video retrieval model based on video- text dual alignment.International Journal of Advanced Computer Science & Ap- plications, 15(2), 2024
Zhanbin Che and Huaili Guo. Cross-modal video retrieval model based on video- text dual alignment.International Journal of Advanced Computer Science & Ap- plications, 15(2), 2024
2024
-
[4]
A sim- ple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A sim- ple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PmLR, 2020
2020
-
[5]
Tecno: Surgical phase recognition with multi-stage temporal convolutional networks
Tobias Czempiel et al. Tecno: Surgical phase recognition with multi-stage temporal convolutional networks. InInternational conference on medical image computing and computer-assisted intervention, pages 343–352. Springer, 2020
2020
-
[6]
Therbligsinaction:Videounderstandingthroughmotionprimitives
Eadom Dessalene, Michael Maynord, Cornelia Fermüller, and Yiannis Aloimonos. Therbligsinaction:Videounderstandingthroughmotionprimitives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10618–10626, 2023
2023
-
[7]
Bert: Pre-training of deep bidirectional transformers for lan- guage understanding
Jacob Devlin et al. Bert: Pre-training of deep bidirectional transformers for lan- guage understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technolo- gies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[8]
Video-based tools for surgical quality assessment of technical skills in laparoscopic procedures: a systematic review.Surgical endoscopy, 37(6):4279–4297, 2023
Alexander AJ Grüter et al. Video-based tools for surgical quality assessment of technical skills in laparoscopic procedures: a systematic review.Surgical endoscopy, 37(6):4279–4297, 2023
2023
-
[9]
Grant M Henning et al. A step toward modernization of urologic training: Incor- poration of a novel surgical intelligence platform for robotic prostatectomy video review.Journal of endourology, 39(11):1204–1210, 2025
2025
-
[10]
Surgical data recording in the operating room: a systematic review of modalities and metrics.British Journal of Surgery, 108(6):613–621, 2021
Marc Levin et al. Surgical data recording in the operating room: a systematic review of modalities and metrics.British Journal of Surgery, 108(6):613–621, 2021
2021
-
[11]
Jianjian Li et al. Fcot-vl: Advancing text-oriented large vision-language models with efficient visual token compression.arXiv preprint arXiv:2502.18512, 2025
-
[12]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin et al. Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Huaishao Luo et al. Clip4clip: An empirical study of clip for end to end video clip retrieval.arXiv preprint arXiv:2104.08860, 2021
-
[14]
X-clip: End-to-end multi-grained contrastive learning for video-text retrieval
Yiwei Ma et al. X-clip: End-to-end multi-grained contrastive learning for video-text retrieval. InProceedings of the 30th ACM international conference on multimedia, pages 638–647, 2022. 10 Y. Shen et al
2022
-
[15]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[16]
Mm-or: A large multimodal operating room dataset for seman- tic understanding of high-intensity surgical environments
Ege Özsoy et al. Mm-or: A large multimodal operating room dataset for seman- tic understanding of high-intensity surgical environments. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19378–19389, 2025
2025
-
[17]
Contrastive learning with hard negative samples.arXiv preprint arXiv:2010.04592, 2020
JoshuaRobinson,Ching-YaoChuang,SuvritSra,andStefanieJegelka. Contrastive learning with hard negative samples.arXiv preprint arXiv:2010.04592, 2020
-
[18]
Saurav Sharma et al. fine-clip: Enhancing zero-shot fine-grained surgical action recognition with vision-language models.arXiv preprint arXiv:2503.19670, 2025
-
[19]
Online reasoning video segmentation with just-in-time digital twins
Yiqing Shen et al. Online reasoning video segmentation with just-in-time digital twins. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 24698–24706, 2025
2025
-
[20]
Yiqing Shen et al. Reasoning text-to-video retrieval via digital twin video repre- sentations and large language models.arXiv preprint arXiv:2511.12371, 2025
-
[21]
Temporally-constrained video reasoning segmentation and auto- mated benchmark construction
Yiqing Shen et al. Temporally-constrained video reasoning segmentation and auto- mated benchmark construction. InInternational Workshop on Foundation Models for General Medical AI, pages 150–158. Springer, 2025
2025
-
[22]
Operating room workflow analysis via reasoning segmentation over digital twins
Yiqing Shen, Chenjia Li, Bohan Liu, Cheng-Yi Li, Tito Porras, and Mathias Un- berath. Operating room workflow analysis via reasoning segmentation over digital twins. InInternational Conference on Medical Image Computing and Computer- Assisted Intervention, pages 415–424. Springer, 2025
2025
-
[23]
Kaibin Tian, Ruixiang Zhao, Hu Hu, Runquan Xie, Fengzong Lian, Zhanhui Kang, and Xirong Li. Teachclip: Multi-grained teaching for efficient text-to-video re- trieval.arXiv preprint arXiv:2308.01217, 2023
-
[24]
T2vlad: global-local sequence alignment for text-video re- trieval
Xiaohan Wang et al. T2vlad: global-local sequence alignment for text-video re- trieval. InProceedings of the IEEE/CVF conference on computer vision and pat- tern recognition, pages 5079–5088, 2021
2021
-
[25]
Internvideo2: Scaling foundation models for multimodal video un- derstanding
Yi Wang et al. Internvideo2: Scaling foundation models for multimodal video un- derstanding. InEuropean conference on computer vision, pages 396–416. Springer, 2024
2024
-
[26]
Learning surgical skills through video-based education: a systematic review.Surgical Innovation, 30(2):220–238, 2023
Samy Cheikh Youssef et al. Learning surgical skills through video-based education: a systematic review.Surgical Innovation, 30(2):220–238, 2023
2023
-
[27]
Live laparoscopic video retrieval with compressed uncertainty
Tong Yu et al. Live laparoscopic video retrieval with compressed uncertainty. Medical Image Analysis, 88:102866, 2023
2023
-
[28]
Text-video retrieval with global-local semantic consistent learning.IEEE Transactions on Image Processing, 2025
Haonan Zhang et al. Text-video retrieval with global-local semantic consistent learning.IEEE Transactions on Image Processing, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.