Meaning in Order, Order in Meaning: Semantic R-precision for Keyphrase Evaluation
Pith reviewed 2026-06-27 20:53 UTC · model grok-4.3
The pith
Semantic R-Precision integrates semantic similarity into rank-aware evaluation for keyphrases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Semantic R-Precision (SemR-p) is a rank-aware metric that replaces exact lexical matching in the R-Precision calculation with semantic similarity scores, thereby rewarding lists in which semantically relevant keyphrases occupy higher positions and aligning the evaluation more closely with human judgments of informativeness and relevance.
What carries the argument
Semantic R-Precision (SemR-p), a modification of R-Precision that substitutes semantic similarity for binary matches when scoring the top-k portion of a ranked keyphrase list.
If this is right
- SemR-p supplies a complementary signal to lexical matching and pure semantic metrics when judging keyphrase output quality.
- The metric demonstrates sensitivity to semantic differences while remaining aware of prediction ranking.
- It exhibits discriminative power that distinguishes performance across different generation models and source datasets.
- Use of SemR-p can help evaluation better reflect user-centred notions of relevance in keyphrase tasks.
Where Pith is reading between the lines
- Keyphrase generation systems trained or selected with SemR-p feedback may produce lists that humans find more immediately useful.
- The same rank-plus-semantics principle could be adapted to evaluate other ordered outputs such as search result snippets or summarization sentences.
- Datasets that currently rely only on exact-match or unordered semantic scores may need re-annotation with rank-aware semantic judgments to serve as reliable benchmarks.
Load-bearing premise
Traditional metrics misalign with human judgments of relevance because they either ignore semantics or ignore the order of predictions.
What would settle it
A study in which human raters directly compare pairs of keyphrase lists for the same document and consistently prefer the list with the higher SemR-p score would support the metric; consistent preference for the lower-scoring list would falsify it.
Figures

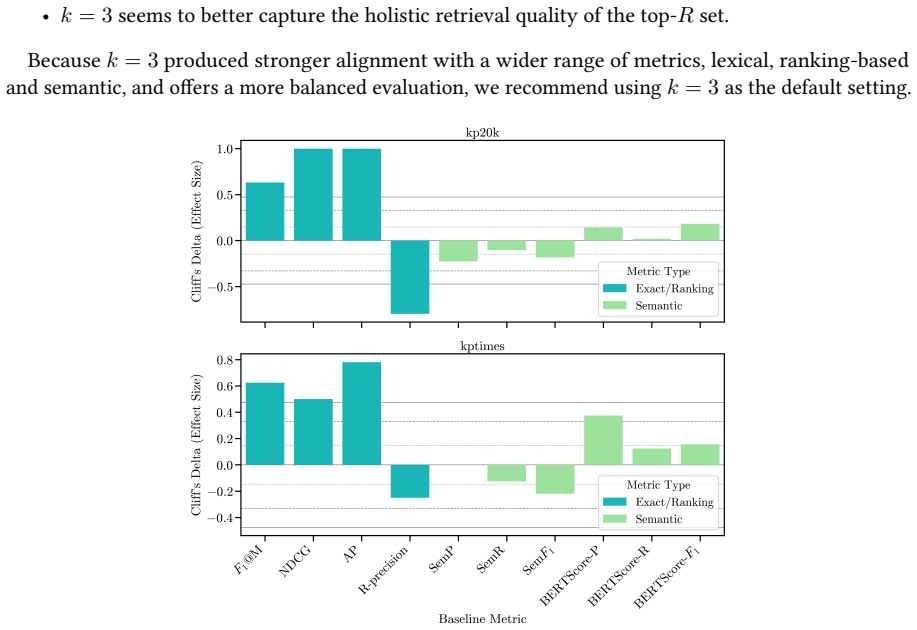
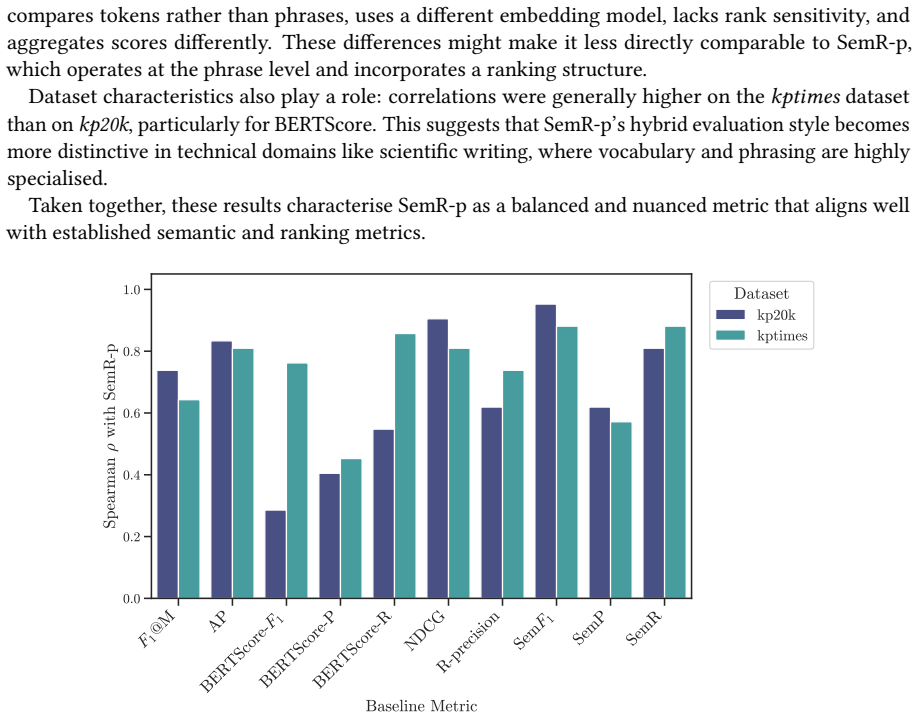

read the original abstract
Evaluating the quality of automatically generated keyphrases remains a complex challenge. Traditional metrics either rely on exact lexical matching or consider semantic similarity while ignoring prediction ranking, both of which misalign with how humans judge informativeness and relevance. We introduce Semantic R-Precision (SemR-p), a novel evaluation metric that integrates semantic similarity into the rank-aware R-Precision framework. Designed from a human-centric perspective and inspired by Information Retrieval metrics, SemR-p rewards semantically relevant keyphrases that appear early in the output list. We conducted extensive analyses to assess its semantic sensitivity, ranking awareness, and discriminative power across models and datasets. The results suggest that SemR-p offers a complementary lens for evaluating keyphrase predictions, helping to better reflect user-centred notions of relevance alongside traditional lexical and semantic matching metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Semantic R-Precision (SemR-p), a novel metric that integrates semantic similarity into the rank-aware R-Precision framework for evaluating keyphrase predictions. It argues that existing lexical matching and semantic metrics (while ignoring ranking) misalign with human notions of informativeness and relevance, and that SemR-p corrects this by rewarding semantically relevant keyphrases that appear early. The authors report analyses of semantic sensitivity, ranking awareness, and discriminative power across models and datasets, concluding that SemR-p offers a complementary lens alongside traditional metrics.
Significance. If the central claim holds, SemR-p could provide a useful complementary tool for keyphrase evaluation in NLP and IR by jointly handling semantics and ranking from a human-centric view. The reported analyses across multiple models and datasets constitute a strength in breadth, though the absence of direct human validation limits the immediate impact.
major comments (2)
- [Abstract] Abstract and motivation: the claim that 'traditional metrics ... misalign with how humans judge informativeness and relevance' and that SemR-p 'better reflect[s] user-centred notions of relevance' is load-bearing for the contribution, yet the manuscript supplies no direct evidence (e.g., correlation of SemR-p scores with human ratings of keyphrase lists) and relies only on indirect proxies such as semantic sensitivity and discriminative power.
- [Analyses (semantic sensitivity, ranking awareness, discriminative power)] No section presents a controlled comparison showing that SemR-p achieves higher alignment with human judgments than lexical R-Precision or semantic F1; without this, the central motivation remains an untested premise rather than a demonstrated improvement.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. The two major comments both concern the strength of evidence supporting the central motivation. We respond to each below and note that we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract and motivation: the claim that 'traditional metrics ... misalign with how humans judge informativeness and relevance' and that SemR-p 'better reflect[s] user-centred notions of relevance' is load-bearing for the contribution, yet the manuscript supplies no direct evidence (e.g., correlation of SemR-p scores with human ratings of keyphrase lists) and relies only on indirect proxies such as semantic sensitivity and discriminative power.
Authors: We agree that the manuscript does not contain direct human correlation studies. The motivation section and abstract draw from the metric's design (rank-aware semantic matching inspired by IR) and from the reported indirect analyses. We will revise the abstract and introduction to remove or qualify the stronger phrasing ('better reflect user-centred notions') and instead state that SemR-p is offered as a complementary metric whose alignment with human notions is supported by the sensitivity, ranking, and discriminative analyses but remains to be confirmed by future human studies. revision: yes
-
Referee: [Analyses (semantic sensitivity, ranking awareness, discriminative power)] No section presents a controlled comparison showing that SemR-p achieves higher alignment with human judgments than lexical R-Precision or semantic F1; without this, the central motivation remains an untested premise rather than a demonstrated improvement.
Authors: The manuscript indeed contains no head-to-head human-judgment correlation experiment. The three analyses demonstrate that SemR-p behaves differently from lexical R-Precision and from non-rank-aware semantic metrics, but they do not directly measure correlation with human ratings. We will add an explicit limitations paragraph acknowledging the absence of such validation and will adjust the conclusion to present SemR-p as a new tool whose practical utility for human-aligned evaluation requires further study. revision: yes
- A controlled human study correlating SemR-p (and baselines) with human ratings of keyphrase lists would require new data collection and annotation effort that cannot be completed within the revision timeline.
Circularity Check
No circularity: metric is a direct definitional proposal with no self-referential reduction.
full rationale
The provided abstract and context contain no equations, no parameter fitting, and no self-citations. SemR-p is introduced as an explicit integration of semantic similarity into the existing R-Precision framework; this is a construction by definition rather than a derivation that reduces to its own inputs. No load-bearing step relies on prior author work or renames a fitted result as a prediction. The paper's analyses are presented as empirical checks on the new metric, not as proofs that presuppose the metric's superiority. This is the normal case of a self-contained definitional contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J. Cai, S. Leckner, J. Björklund, From precision to perception: User-centred evaluation of keyword extraction algorithms for internet-scale contextual advertising, 2025. URL: https://arxiv.org/abs/ 2504.21667. doi:10.48550/ARXIV.2504.21667
-
[2]
BERTScore: Evaluating Text Generation with BERT
T. Zhang, V. Kishore, F. Wu, K. Q. Weinberger, Y. Artzi, Bertscore: Evaluating text generation with bert, 2019. URL: https://arxiv.org/abs/1904.09675. doi:10.48550/ARXIV.1904.09675
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1904.09675 2019
-
[3]
Zesch, I
T. Zesch, I. Gurevych, Approximate matching for evaluating keyphrase extraction, in: G. Angelova, R. Mitkov (Eds.), Proceedings of the International Conference RANLP-2009, Association for Compu- tational Linguistics, Borovets, Bulgaria, 2009, pp. 484–489. URL: https://aclanthology.org/R09-1086/
2009
-
[4]
C. D. Manning, P. Raghavan, H. Schütze, Introduction to Information Retrieval, Cambridge Univer- sity Press, Cambridge, UK, 2008. URL: https://nlp.stanford.edu/IR-book/information-retrieval-book. html
2008
-
[5]
A. Sutcliffe, M. Ennis, Towards a cognitive theory of information retrieval, Interacting with Com- puters 10 (1998) 321–351. URL: http://dx.doi.org/10.1016/S0953-5438(98)00013-7. doi: 10.1016/ s0953-5438(98)00013-7
-
[6]
N. Firoozeh, A. Nazarenko, F. Alizon, B. Daille, Keyword extraction: Issues and methods, Natural Language Engineering 26 (2020) 259–291. doi:10.1017/S1351324919000457
-
[7]
S. N. Kim, T. Baldwin, M.-Y. Kan, Evaluating n-gram based evaluation metrics for automatic keyphrase extraction, in: C.-R. Huang, D. Jurafsky (Eds.), Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010), Coling 2010 Organizing Committee, Beijing, China, 2010, pp. 572–580. URL: https://aclanthology.org/C10-1065/
2010
-
[8]
R. Meng, S. Zhao, S. Han, D. He, P. Brusilovsky, Y. Chi, Deep keyphrase generation, in: R. Barzilay, M.-Y. Kan (Eds.), Proceedings of the 55th Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), Association for Computational Linguistics, Vancouver, Canada, 2017, pp. 582–592. URL: https://aclanthology.org/P17-1054/. d...
-
[9]
D. Wu, D. Yin, K.-W. Chang, KPEval: Towards fine-grained semantic-based keyphrase evaluation, in: L.-W. Ku, A. Martins, V. Srikumar (Eds.), Findings of the Association for Computational Linguistics: ACL 2024, Association for Computational Linguistics, Bangkok, Thailand, 2024, pp. 1959–1981. URL: https://aclanthology.org/2024.findings-acl.117/. doi: 10.186...
-
[10]
Cumulated gain-based evaluation of ir techniques.ACM Trans
K. Järvelin, J. Kekäläinen, Cumulated gain-based evaluation of ir techniques, ACM Transactions on Information Systems 20 (2002) 422–446. URL: http://dx.doi.org/10.1145/582415.582418. doi:10. 1145/582415.582418
-
[11]
X. Yuan, T. Wang, R. Meng, K. Thaker, P. Brusilovsky, D. He, A. Trischler, One size does not fit all: Generating and evaluating variable number of keyphrases, in: D. Jurafsky, J. Chai, N. Schluter, J. Tetreault (Eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Online...
-
[12]
B. J. Jansen, A. Spink, How are we searching the world wide web? a comparison of nine search engine transaction logs, Information Processing & Management 42 (2006) 248–263. URL: http: //dx.doi.org/10.1016/j.ipm.2004.10.007. doi:10.1016/j.ipm.2004.10.007
-
[13]
Rosch, Cognitive representations of semantic categories, Journal of Experimental Psychology: General 104 (1975) 192–233
E. Rosch, Cognitive representations of semantic categories, Journal of Experimental Psychology: General 104 (1975) 192–233
1975
-
[14]
Ingwersen, K
P. Ingwersen, K. Järvelin, The Turn: Integration of Information Seeking and Retrieval in Context, Springer, Dordrecht, 2005
2005
-
[15]
Y. Gallina, F. Boudin, B. Daille, KPTimes: A large-scale dataset for keyphrase generation on news documents, in: K. van Deemter, C. Lin, H. Takamura (Eds.), Proceedings of the 12th International Conference on Natural Language Generation, Association for Computa- tional Linguistics, Tokyo, Japan, 2019, pp. 130–135. URL: https://aclanthology.org/W19-8617/. ...
-
[16]
Sparck Jones, A statistical interpretation of term specificity and its application in retrieval, Taylor Graham Publishing, GBR, 1988, pp
K. Sparck Jones, A statistical interpretation of term specificity and its application in retrieval, Taylor Graham Publishing, GBR, 1988, pp. 132–142
1988
-
[17]
Mihalcea, P
R. Mihalcea, P. Tarau, TextRank: Bringing order into text, in: D. Lin, D. Wu (Eds.), Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Barcelona, Spain, 2004, pp. 404–411. URL: https://aclanthology.org/ W04-3252/
2004
-
[18]
Boudin, Unsupervised keyphrase extraction with multipartite graphs, in: M
F. Boudin, Unsupervised keyphrase extraction with multipartite graphs, in: M. Walker, H. Ji, A. Stent (Eds.), Proceedings of the 2018 Conference of the North American Chapter of the Associ- ation for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), Association for Computational Linguistics, New Orleans, Louisiana, 2018, pp....
-
[19]
D. Wu, W. U. Ahmad, K.-W. Chang, Pre-trained language models for keyphrase generation: A thorough empirical study, 2022. URL: https://arxiv.org/abs/2212.10233. doi: 10.48550/ARXIV. 2212.10233
work page internal anchor Pith review doi:10.48550/arxiv 2022
-
[20]
M. Song, Y. Feng, L. Jing, Hyperbolic relevance matching for neural keyphrase extraction, in: M. Carpuat, M.-C. de Marneffe, I. V. Meza Ruiz (Eds.), Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Lan- guage Technologies, Association for Computational Linguistics, Seattle, United Sta...
-
[21]
J. Ye, T. Gui, Y. Luo, Y. Xu, Q. Zhang, One2Set: Generating diverse keyphrases as a set, in: C. Zong, F. Xia, W. Li, R. Navigli (Eds.), Proceedings of the 59th Annual Meeting of the Association for Com- putational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Association for Computational L...
-
[22]
N. Reimers, I. Gurevych, Sentence-BERT: Sentence embeddings using Siamese BERT-networks, in: K. Inui, J. Jiang, V. Ng, X. Wan (Eds.), Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Association for Computational Linguistics, Hon...
-
[23]
Porter, An algorithm for suffix stripping, Program 40 (2006) 211–218
M. Porter, An algorithm for suffix stripping, Program 40 (2006) 211–218. URL: http://dx.doi.org/10. 1108/00330330610681286. doi:10.1108/00330330610681286
-
[24]
Jin, M.-Y
Y. Jin, M.-Y. Kan, J.-P. Ng, X. He, Mining scientific terms and their definitions: A study of the ACL Anthology, in: D. Yarowsky, T. Baldwin, A. Korhonen, K. Livescu, S. Bethard (Eds.), Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Seattle, Washington, USA, 2013, pp. 780–...
2013
-
[25]
J. Xing, D. Luo, C. Xue, R. Xing, Comparative analysis of pooling mechanisms in llms: A sentiment analysis perspective, 2024. URL: https://arxiv.org/abs/2411.14654. doi:10.48550/ARXIV.2411. 14654
-
[26]
Munkres, Algorithms for the assignment and transportation problems, Journal of the Society for Industrial and Applied Mathematics 5 (1957) 32–38
J. Munkres, Algorithms for the assignment and transportation problems, Journal of the Society for Industrial and Applied Mathematics 5 (1957) 32–38
1957
- [27]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.