VT-WAM: Visual-Tactile World Action Model for Contact-Rich Manipulation
Pith reviewed 2026-07-03 10:30 UTC · model grok-4.3
The pith
VT-WAM jointly predicts visual futures, tactile deformations, and actions in a flow-matching model to handle contact-rich robot tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
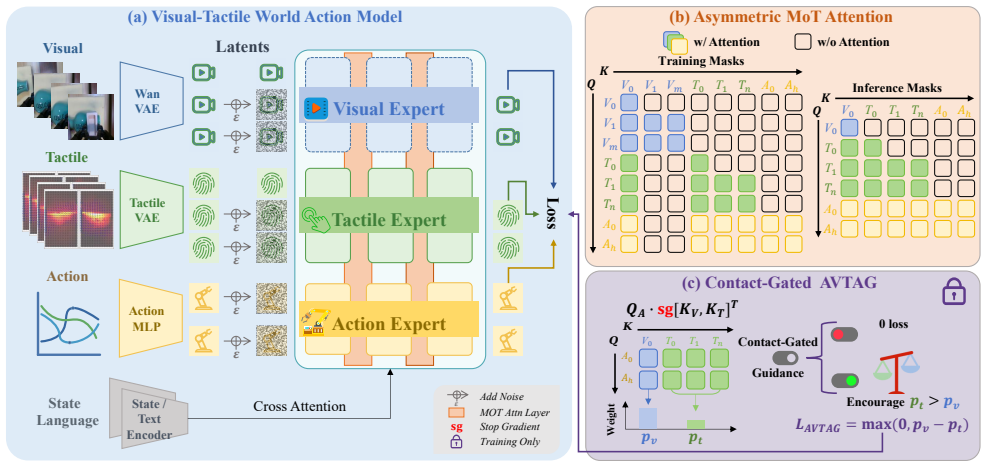
VT-WAM is a Visual-Tactile World Action Model that jointly learns future visual prediction, tactile deformation prediction, and action prediction within a unified flow matching framework. It introduces Asymmetric Mixture-of-Transformers attention to bridge a first-frame visual anchor with temporal tactile dynamics, and contact-gated Action-Visual-Tactile Attention Guidance to encourage action queries to rely on tactile evidence during contact phases. Across six real-world contact-rich manipulation tasks, VT-WAM achieves a 71.67% average success rate, outperforming Fast-WAM by 26.67% and OmniVTLA by 35.84%. Ablations demonstrate that modeling tactile deformation dynamics and guiding contact-p
What carries the argument
Asymmetric Mixture-of-Transformers (MoT) attention and contact-gated Action-Visual-Tactile Attention Guidance (AVTAG) inside a unified flow-matching generative model for joint visual, tactile deformation, and action prediction.
Load-bearing premise
The Asymmetric Mixture-of-Transformers attention and contact-gated AVTAG will produce action predictions that benefit from modeling tactile deformation dynamics when trained inside the flow-matching framework on the evaluated tasks and hardware.
What would settle it
Training and testing a version of VT-WAM on the same six tasks with the tactile deformation prediction head removed and checking whether success rates fall to the level of the prior baselines would test whether the deformation modeling component is necessary.
Figures


read the original abstract
Contact-rich manipulation requires policies to react to local deformation, pressure, slip, and friction, yet these cues are temporally sparse and often invisible in visual observations. Existing visual-tactile policies usually feed tactile observations directly into action prediction, but rarely model tactile deformation dynamics during action generation. In this paper, we introduce VT-WAM, a Visual-Tactile World Action Model that jointly learns future visual prediction, tactile deformation prediction, and action prediction within a unified flow matching framework. In particular, VT-WAM introduces (1) Asymmetric Mixture-of-Transformers (MoT) attention to bridge a first-frame visual anchor with temporal tactile dynamics, and (2) contact-gated Action-Visual-Tactile Attention Guidance (AVTAG) to encourage action queries to rely on tactile evidence during contact phases. Across six real-world contact-rich manipulation tasks, VT-WAM achieves a 71.67% average success rate, outperforming Fast-WAM by 26.67% and OmniVTLA by 35.84%. Ablations demonstrate that modeling tactile deformation dynamics and guiding contact-phase tactile attention are both important for contact-rich tasks. Project website: https://vt-wam.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
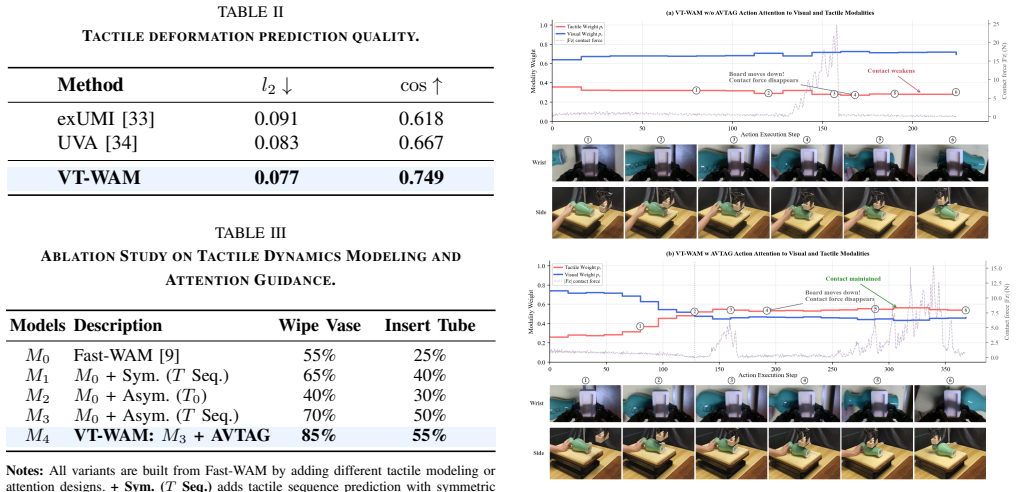
Summary. The manuscript introduces VT-WAM, a Visual-Tactile World Action Model that jointly predicts future visual observations, tactile deformations, and actions inside a single flow-matching framework. It proposes two architectural components—Asymmetric Mixture-of-Transformers attention that anchors on the first visual frame while attending to temporal tactile dynamics, and contact-gated AVTAG that routes action queries to tactile evidence only during contact phases—and evaluates the model on six real-world contact-rich manipulation tasks, reporting a 71.67 % mean success rate that exceeds Fast-WAM by 26.67 % and OmniVTLA by 35.84 %. Ablations are cited to show that both tactile-deformation modeling and contact-phase guidance contribute measurably to performance.
Significance. If the reported gains and ablation results hold under full experimental scrutiny, the work supplies concrete evidence that explicit, dynamics-aware tactile modeling inside a generative action framework improves reliability on contact-rich tasks where visual cues alone are insufficient. The joint flow-matching objective and the two attention mechanisms constitute a reusable design pattern that could be adopted by other multi-modal manipulation pipelines.
minor comments (3)
- [Abstract] The abstract states that ablations confirm the importance of the two proposed components, yet no quantitative drops (e.g., success-rate deltas or per-task breakdowns) are supplied; these numbers should appear in the main results table or a dedicated ablation subsection.
- The description of the Asymmetric MoT attention and contact-gated AVTAG would benefit from an explicit diagram or pseudocode block showing how the first-frame visual anchor is injected and how the contact gate is computed from tactile signals.
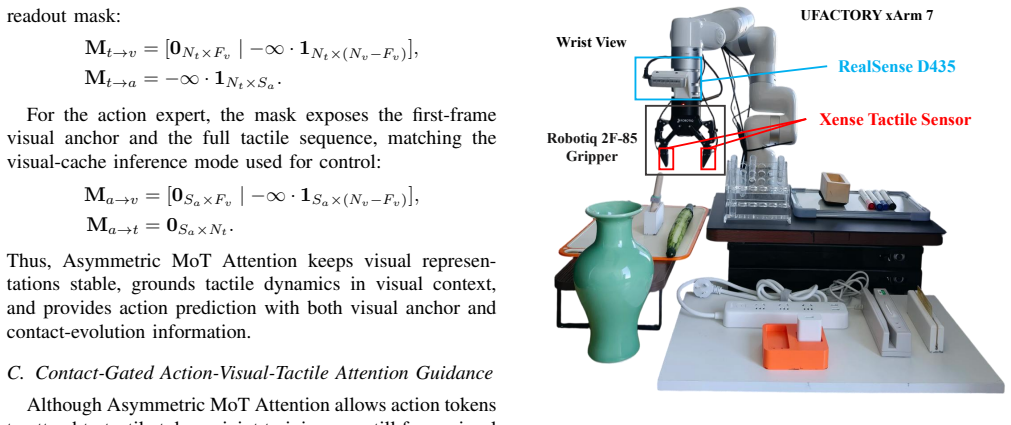
- Task definitions, success criteria, and hardware specifications (sensor models, robot platform, force thresholds) are referenced only at a high level; a concise table listing these details would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive summary of VT-WAM and the recommendation for minor revision. No specific major comments were provided in the report, so we have no individual points requiring rebuttal or revision at this stage. We remain available to address any additional feedback or minor clarifications during the revision process.
Circularity Check
No significant circularity; empirical claims rest on external data and ablations
full rationale
The paper reports an empirical performance result (71.67% success rate on six real-world tasks) from training a flow-matching model with Asymmetric MoT attention and contact-gated AVTAG. No equations, parameter-fitting procedures, or derivation steps are described that would reduce the reported success rates or ablation outcomes to quantities defined by the same fitted parameters. The central claims are supported by direct experimental evidence (ablations) rather than by self-referential definitions or imported uniqueness theorems. This is the normal case of a self-contained empirical robotics paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,”The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
2025
-
[2]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Es- mail, M. Equi, C. Finn, N. Fusaiet al., “π 0.5: A Vision-Language- Action Model with Open-World Generalization,”arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Reactive Diffusion Policy: Slow-Fast Visual-Tactile Policy Learning for Contact-Rich Manipulation,
H. Xue, J. Ren, W. Chen, G. Zhang, Y . Fang, G. Gu, H. Xu, and C. Lu, “Reactive Diffusion Policy: Slow-Fast Visual-Tactile Policy Learning for Contact-Rich Manipulation,” inProceedings of Robotics: Science and Systems (RSS), 2025
2025
-
[4]
VLA-Touch: Enhancing Vision-Language-Action Model with Dual-Level Tactile Feedback,
J. Bi, K. Y . Ma, C. Hao, M. S. Zheng, and H. Soh, “VLA-Touch: Enhancing Vision-Language-Action Model with Dual-Level Tactile Feedback,”IEEE Robotics and Automation Letters, 2026
2026
- [5]
-
[6]
VisuoTactile-RL: Learning multimodal manipulation policies with deep reinforcement learning,
J. Hansen, F. Hogan, D. Rivkin, D. Meger, M. Jenkin, and G. Dudek, “VisuoTactile-RL: Learning multimodal manipulation policies with deep reinforcement learning,” in2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 8298–8304
2022
-
[7]
Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets,
C. Zhu, R. Yu, S. Feng, B. Burchfiel, P. Shah, and A. Gupta, “Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets,” inProceedings of Robotics: Science and Systems (RSS), 2025
2025
-
[8]
Causal World Modeling for Robot Control,
L. Li, Q. Zhang, Y . Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhuet al., “Causal World Modeling for Robot Control,” inProceedings of Robotics: Science and Systems (RSS), 2026
2026
-
[9]
Fast-WAM: Do World Action Models Need Test-time Future Imagination?
T. Yuan, Z. Dong, Y . Liu, and H. Zhao, “Fast-W AM: Do World Action Models Need Test-Time Future Imagination?”arXiv preprint arXiv:2603.16666, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
E. Helmut, N. Funk, T. Schneider, C. de Farias, and J. Peters, “Tactile- Conditioned Diffusion Policy for Force-Aware Robotic Manipulation,” arXiv preprint arXiv:2510.13324, 2025
-
[11]
TacDiffusion: Force-Domain Diffusion Policy for Precise Tactile Manipulation,
Y . Wu, Z. Chen, F. Wu, L. Chen, L. Zhanget al., “TacDiffusion: Force-Domain Diffusion Policy for Precise Tactile Manipulation,” in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2025, pp. 11 831–11 837
2025
-
[12]
PolyTouch: A Robust Multi-Modal Tactile Sensor for Contact-Rich Manipulation Using Tactile-Diffusion Policies,
J. Zhao, N. Kuppuswamy, S. Feng, B. Burchfiel, and E. Adelson, “PolyTouch: A Robust Multi-Modal Tactile Sensor for Contact-Rich Manipulation Using Tactile-Diffusion Policies,” inProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2025, pp. 104–110
2025
- [13]
-
[14]
Force Policy: Learning hybrid force-position control policy under interaction frame for contact-rich manipulation,
H. Fang, S. Tang, M. Mei, H. Qin, Z. He, J. Chen, Y . Feng, C. Wang, W. Liu, Z. Heet al., “Force Policy: Learning hybrid force-position control policy under interaction frame for contact-rich manipulation,” inProceedings of Robotics: Science and Systems (RSS), 2026
2026
-
[15]
X. Li, Y . Xie, H. Liu, W. Hou, G. Chen, S. Li, and W. Ding, “Master Micro Residual Correction with Adaptive Tactile Fusion and Force-Mixed Control for Contact-Rich Manipulation,”arXiv preprint arXiv:2603.15152, 2026
-
[16]
BiTLA: A Bimanual Tactile-Language-Action Model for Contact-Rich Robotic Manipulation,
S. Yang, H. Li, J. Hu, S. Zhang, G. Yao, Z. Ni, and B. Fang, “BiTLA: A Bimanual Tactile-Language-Action Model for Contact-Rich Robotic Manipulation,” inProceedings of the 1st International Workshop on Multi-Sensorial Media and Applications, 2025, pp. 12–17
2025
- [17]
-
[18]
J. Huang, S. Wang, F. Lin, Y . Hu, C. Wen, and Y . Gao, “Tactile-VLA: Unlocking Vision-Language-Action Model’s Physical Knowledge for Tactile Generalization,”arXiv preprint arXiv:2507.09160, 2025
-
[19]
Tactile-Force Alignment in Vision-Language-Action Models for Force-Aware Manipulation,
Y . Huang, P. Lin, W. Li, D. Li, J. Li, J. Jiang, C. Xiao, and Z. Jiao, “Tactile-Force Alignment in Vision-Language-Action Models for Force-Aware Manipulation,”arXiv preprint arXiv:2601.20321, 2026
-
[20]
C. Higuera, S. Arnaud, B. Boots, M. Mukadam, F. R. Hogan, and F. Meier, “Visuo-Tactile World Models,”arXiv preprint arXiv:2602.06001, 2026
-
[21]
Y . Zheng, S. Gu, W. Li, Y . Zheng, Y . Zang, S. Tian, X. Li, C. Hao, C. Gao, S. Liuet al., “OmniVTA: Visuo-Tactile World Modeling for Contact-Rich Robotic Manipulation,”arXiv preprint arXiv:2603.19201, 2026
-
[22]
World Action Models: The Next Frontier in Embodied AI
S. Wang, J. Shi, Z. Fu, X. He, F. Liu, C. Yang, Y . Zhou, Z. Fei, J. Gong, J. Fuet al., “World Action Models: The Next Frontier in Embodied AI,”arXiv preprint arXiv:2605.12090, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Learning Universal Policies via Text-Guided Video Generation,
Y . Du, S. Yang, B. Dai, H. Dai, O. Nachum, J. Tenenbaum, D. Schu- urmans, and P. Abbeel, “Learning Universal Policies via Text-Guided Video Generation,”Advances in Neural Information Processing Sys- tems, vol. 36, pp. 9156–9172, 2023
2023
-
[24]
Video Language Planning,
Y . Du, S. Yang, P. Florence, F. Xia, A. Wahid, P. Sermanet, T. Yu, P. Abbeel, J. B. Tenenbaum, L. Kaelblinget al., “Video Language Planning,” inProceedings of the International Conference on Learning Representations (ICLR), vol. 2024, 2024, pp. 31 138–31 155
2024
-
[25]
RoboEnvision: A Long-Horizon Video Generation Model for Multi-Task Robot Ma- nipulation,
L. Yang, Y . Bai, G. Eskandar, F. Shen, M. Altillawi, D. Chen, S. Majumder, Z. Liu, G. Kutyniok, and A. Valada, “RoboEnvision: A Long-Horizon Video Generation Model for Multi-Task Robot Ma- nipulation,” inProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025, pp. 21 281–21 288
2025
-
[26]
S. Gu, Y . Cai, T. Wang, S. Wu, and Y . Fu, “Say, Dream, and Act: Learning Video World Models for Instruction-Driven Robot Manipulation,”arXiv preprint arXiv:2602.10717, 2026
-
[27]
World Action Models are Zero-shot Policies
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xianget al., “World Action Models Are Zero-Shot Policies,”arXiv preprint arXiv:2602.15922, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Motus: A Unified Latent Action World Model
H. Bi, H. Tan, S. Xie, Z. Wang, S. Huang, H. Liu, R. Zhao, Y . Feng, C. Xiang, Y . Ronget al., “Motus: A Unified Latent Action World Model,”arXiv preprint arXiv:2512.13030, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
A. Ye, B. Wang, C. Ni, G. Huang, G. Zhao, H. Li, H. Li, J. Li, J. Lv, J. Liuet al., “GigaWorld-Policy: An Efficient Action-Centered World–Action Model,”arXiv preprint arXiv:2603.17240, 2026
-
[30]
Wan: Open and Advanced Large-Scale Video Generative Models
A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yanget al., “Wan: Open and Advanced Large-Scale Video Generative Models,”arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Attention Is All You Need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention Is All You Need,”Ad- vances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017
2017
-
[32]
Mixture-of- Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models,
W. Liang, L. Yu, L. Luo, S. Iyer, N. Dong, C. Zhou, G. Ghosh, M. Lewis, W.-t. Yih, L. Zettlemoyer, and X. V . Lin, “Mixture-of- Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models,”Transactions on Machine Learning Research, 2025
2025
-
[33]
exUMI: Extensible Robot Teaching System with Action-Aware Task-Agnostic Tactile Representation,
Y . Xu, L. Wei, P. An, Q. Zhang, and Y .-L. Li, “exUMI: Extensible Robot Teaching System with Action-Aware Task-Agnostic Tactile Representation,” inProceedings of the Conference on Robot Learning (CoRL), 2025
2025
-
[34]
S. Li, Y . Gao, D. Sadigh, and S. Song, “Unified Video Action Model,” arXiv preprint arXiv:2503.00200, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.