Coarse-to-Control: Action-Token Planning for Vision-Language-Action Models
Pith reviewed 2026-06-27 21:55 UTC · model grok-4.3
The pith
VLA models that first predict a compact sequence of coarse action tokens in a shared discrete vocabulary outperform direct action generation on long-horizon tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper shows that a plan-execute VLA architecture succeeds by letting the policy predict a compact sequence of coarse action tokens first, then generate executable tokens conditioned on this plan, where both stages share one unified discrete action vocabulary so that the plan supplies directly usable guidance rather than an abstract hint.
What carries the argument
The unified discrete action vocabulary that lets coarse planning tokens and fine execution tokens occupy the same space and thereby keep the plan on the control manifold.
If this is right
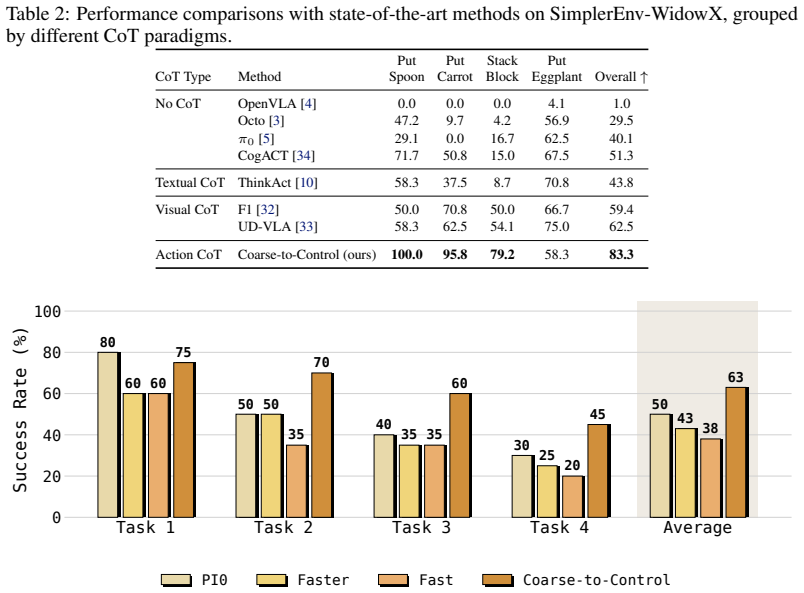
- Gains appear consistently across LIBERO, SimplerEnv-WidowX, and real manipulation tasks, with the largest margins on long-horizon multi-stage problems.
- Planning occurs inside the existing action vocabulary, so no separate language planner or translation module is required.
- The shared vocabulary ensures the plan remains executable without drifting into abstract representations.
- The same architecture can be applied to existing VLA backbones by extending their output sequences to include planning tokens before execution tokens.
Where Pith is reading between the lines
- The method could be tested on tasks with changing goals by regenerating the coarse plan periodically rather than once at the start.
- Optimal length and granularity of the coarse sequence remain open parameters that future work could tune per task class.
- Exposing the coarse plan tokens during execution might allow human operators to intervene at the trajectory level instead of the low-level command level.
- The same coarse-to-fine structure might stabilize other long-sequence prediction problems that currently suffer from compounding token errors.
Load-bearing premise
A compact sequence of coarse action tokens predicted in the shared discrete vocabulary will supply directly actionable guidance that stays close to the control manifold without any additional translation.
What would settle it
A controlled experiment on LIBERO or real-world tasks in which inserting the coarse planning stage produces equal or lower success rates than direct action generation would falsify the claimed benefit.
Figures






read the original abstract
Most vision-language-action (VLA) models map observations directly to actions without explicit intermediate planning, which limits performance on long-horizon tasks where early mistakes compound. We propose Coarse-to-Control, a plan-execute VLA that introduces planning natively in the action-token space. The key idea is to let the policy first predict a compact sequence of coarse action tokens that summarize the intended future trajectory, and then generate executable action tokens conditioned on this plan. Because both planning and execution share a unified discrete action vocabulary, the plan stays close to the control manifold and provides directly actionable guidance rather than an abstract hint that must be translated back to motor commands. Experiments on LIBERO, SimplerEnv-WidowX, and real-world manipulation tasks show that action-token planning consistently improves over direct action generation, with the largest gains on long-horizon multi-stage tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Coarse-to-Control, a plan-execute vision-language-action (VLA) model. It first predicts a compact sequence of coarse action tokens summarizing the intended future trajectory in a shared discrete action vocabulary, then generates executable action tokens conditioned on this plan. The shared vocabulary is intended to keep the plan close to the control manifold and directly actionable. Experiments on LIBERO, SimplerEnv-WidowX, and real-world manipulation tasks are claimed to show consistent improvements over direct action generation, with largest gains on long-horizon multi-stage tasks.
Significance. If the experimental results hold with proper controls, the approach could be significant for VLA research by integrating planning natively in the action-token space rather than relying on abstract language plans that require translation. The unified vocabulary is a clean design choice that avoids additional modules. However, the absence of any reported metrics, baselines, ablations, or statistical details in the available text prevents assessment of whether the claimed gains are real, robust, or merely incremental.
major comments (1)
- [Abstract] Abstract: The central claim that 'action-token planning consistently improves over direct action generation, with the largest gains on long-horizon multi-stage tasks' is asserted without any baselines, metrics (e.g., success rate, horizon length), statistical details, or ablation results. This renders the experimental contribution impossible to evaluate and is load-bearing for the paper's main thesis.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the lack of quantitative support in the abstract. We address the point directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'action-token planning consistently improves over direct action generation, with the largest gains on long-horizon multi-stage tasks' is asserted without any baselines, metrics (e.g., success rate, horizon length), statistical details, or ablation results. This renders the experimental contribution impossible to evaluate and is load-bearing for the paper's main thesis.
Authors: We agree that the abstract presents the central claim without accompanying numbers, baselines, or statistical details, which makes it difficult for a reader to assess the strength of the result from the abstract alone. The full manuscript contains the supporting experiments (success rates, direct-action baselines, horizon-stratified results, and ablations) in the results section. To resolve the referee's concern we will revise the abstract to include a concise statement of the key quantitative findings (e.g., average success-rate lift and the differential gain on long-horizon tasks) drawn from those experiments. This change keeps the abstract self-contained while preserving the original claims. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes an empirical method (Coarse-to-Control) for VLA models that predicts coarse action tokens before executable ones, sharing a discrete vocabulary. The abstract and description contain no equations, derivations, fitted parameters presented as predictions, or self-citation chains. The central claim rests on experimental results across LIBERO, SimplerEnv-WidowX, and real-world tasks rather than any self-referential reduction. No load-bearing step reduces by construction to its inputs, satisfying the criteria for a self-contained empirical contribution with score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022. doi:10.48550/arXiv.2212.06817. URLhttps://arxiv.org/abs/2212.06817
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.06817 2022
-
[2]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control.arXiv preprint arXiv:2307.15818, 2023. doi:10.48550/arXiv.2307.15818. URLhttps://arxiv.org/abs/2307.15818
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.15818 2023
-
[3]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024. doi:10.48550/arXiv.2405. 12213. URLhttps://arxiv.org/abs/2405.12213
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405 2024
-
[5]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164,
-
[6]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
doi:10.48550/arXiv.2410.24164. URLhttps://arxiv.org/abs/2410.24164
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.24164
-
[7]
D. A. Rosenbaum.Human motor control. Academic press, 2009
2009
-
[8]
N. A. Bernstein.The Co-ordination and Regulation of Movements. Pergamon Press, Oxford, 1967
1967
-
[9]
K. S. Lashley. The problem of serial order in behavior. In L. A. Jeffress, editor,Cerebral Mechanisms in Behavior, pages 112–136. Wiley, New York, 1951
1951
-
[10]
M. Zawalski, W. Chen, K. Pertsch, O. Mees, C. Finn, and S. Levine. Robotic control via embodied chain-of-thought reasoning.arXiv preprint arXiv:2407.08693, 2024. doi:10.48550/ arXiv.2407.08693. URLhttps://arxiv.org/abs/2407.08693
Pith/arXiv arXiv 2024
-
[11]
ThinkAct: Vision-Language-Action Reasoning via Reinforced Visual Latent Planning
C.-P. Huang, Y .-H. Wu, M.-H. Chen, Y .-C. F. Wang, and F.-E. Yang. Thinkact: Vision-language-action reasoning via reinforced visual latent planning.arXiv preprint arXiv:2507.16815, 2025. doi:10.48550/arXiv.2507.16815. URLhttps://arxiv.org/abs/ 2507.16815
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.16815 2025
-
[12]
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finn, A. Handa, M.-Y . Liu, D. Xiang, G. Wetzstein, and T.-Y . Lin. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models.arXiv preprint arXiv:2503.22020, 2025. doi:10.48550/ arXiv.2503.22020. URLhttps://arxiv.org/abs/2503.22020
Pith/arXiv arXiv 2025
-
[13]
DreamVLA: A Vision-Language-Action Model Dreamed with Comprehensive World Knowledge
W. Zhang, H. Liu, Z. Qi, Y . Wang, X. Yu, J. Zhang, R. Dong, J. He, F. Lu, H. Wang, Z. Zhang, L. Yi, W. Zeng, and X. Jin. Dreamvla: A vision-language-action model dreamed with compre- hensive world knowledge.arXiv preprint arXiv:2507.04447, 2025. doi:10.48550/arXiv.2507. 04447. URLhttps://arxiv.org/abs/2507.04447
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507 2025
-
[14]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wang, and X. Li. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025. doi:10.48550/arXiv.2501.15830. URLhttps://arxiv. org/abs/2501.15830
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.15830 2025
-
[16]
H. Huang, M. Cen, K. Tan, X. Quan, G. Huang, and H. Zhang. Graphcot-vla: A 3d spatial- aware reasoning vision-language-action model for robotic manipulation with ambiguous in- structions.arXiv preprint arXiv:2508.07650, 2025. doi:10.48550/arXiv.2508.07650. URL https://arxiv.org/abs/2508.07650
-
[17]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025. doi:10.48550/arXiv.2501.09747. URLhttps://arxiv.org/abs/ 2501.09747
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.09747 2025
-
[18]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025. doi:10.48550/arXiv.2502.19645. URLhttps://arxiv.org/abs/2502.19645
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.19645 2025
-
[19]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fu- sai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, et al.π 0.5: a vision-language- action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025. doi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.16054 2025
-
[20]
Z. Zhong, J. Li, J. He, H. Yan, X. Gong, G. Zhao, Y . Cai, J. Gao, X. Yan, B. Liu, Y . Chen, L. Yang, and H. Li. Dualcot-vla: Visual-linguistic chain of thought via parallel reasoning for vision-language-action models.arXiv preprint arXiv:2603.22280, 2026. doi:10.48550/arXiv. 2603.22280. URLhttps://arxiv.org/abs/2603.22280
work page internal anchor Pith review doi:10.48550/arxiv 2026
-
[21]
J. Lee, J. Duan, H. Fang, Y . Deng, S. Liu, B. Li, B. Fang, J. Zhang, Y . R. Wang, S. Lee, W. Han, W. Pumacay, A. Wu, R. Hendrix, K. Farley, E. VanderBilt, A. Farhadi, D. Fox, and R. Krishna. Molmoact: Action reasoning models that can reason in space.arXiv preprint arXiv:2508.07917, 2025. doi:10.48550/arXiv.2508.07917. URLhttps://arxiv.org/abs/ 2508.07917
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.07917 2025
-
[22]
H. Fang, J. Duan, D. Clay, S. Wang, S. Liu, W. Huang, X. Fan, W.-C. Tsai, S. Chen, Y . R. Wang, S. Xing, J. Cho, J. S. Park, A. Eftekhar, P. Sushko, K. Farley, A. Wadhwa, C. Harrison, W. Han, Y .-C. Lee, E. VanderBilt, R. Hendrix, S. Ellawela, L. Ngoo, J. Chai, Z. Ren, A. Farhadi, D. Fox, and R. Krishna. Molmoact2: Action reasoning models for real-world d...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.02881 2026
-
[23]
L. Zhong, Y . Liu, Y . Wei, Z. Xiong, M. Yao, S. Liu, and G. Ren. Acot-vla: Action chain- of-thought for vision-language-action models.arXiv preprint arXiv:2601.11404, 2026. doi: 10.48550/arXiv.2601.11404. URLhttps://arxiv.org/abs/2601.11404
-
[24]
Y . Liu, S. Zhang, Z. Dong, B. Ye, T. Yuan, X. Yu, L. Yin, C. Lu, J. Shi, L. J.-T. Yu, L. Zheng, T. Jiang, J. Gong, X. Qiu, and H. Zhao. Faster: Toward efficient autoregressive vision language action modeling via neural action tokenization.arXiv preprint arXiv:2512.04952, 2025. doi: 10.48550/arXiv.2512.04952. URLhttps://arxiv.org/abs/2512.04952
-
[25]
Z. Dong, Y . Liu, S. Zhang, B. Ye, Y . Yuan, F. Ni, J. Gong, X. Qiu, H. Zhao, Y . Li, et al. Actioncodec: What makes for good action tokenizers.arXiv preprint arXiv:2602.15397, 2026
arXiv 2026
-
[26]
Y . Wang, H. Zhu, M. Liu, J. Yang, H.-S. Fang, and T. He. Vq-vla: Improving vision-language- action models via scaling vector-quantized action tokenizers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11089–11099, 2025
2025
-
[27]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning. InAdvances in Neural Information Processing Systems, volume 36, 2023. URLhttps://proceedings.neurips.cc/paper_files/ paper/2023/hash/8c3c666820ea055a77726d66fc7d447f-Abstract-Datasets_and_ Benchmarks.html. 10
2023
-
[28]
X. Li, K. Hsu, J. Gu, K. Pertsch, O. Mees, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kir- mani, S. Levine, J. Wu, C. Finn, H. Su, Q. Vuong, and T. Xiao. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941, 2024
Pith/arXiv arXiv 2024
-
[29]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Ar- actingi, C. Pascal, M. Russi, A. Marafioti, S. Alibert, M. Cord, T. Wolf, and R. Cadene. Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025. doi:10.48550/arXiv.2506.01844. URLhttps://arxiv.org/abs/ 2506.01844
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.01844 2025
-
[30]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA, J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z. Y...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.14734 2025
-
[31]
J. Cen, C. Yu, H. Yuan, Y . Jiang, S. Huang, J. Guo, X. Li, Y . Song, H. Luo, F. Wang, D. Zhao, and H. Chen. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025. doi:10.48550/arXiv.2506.21539. URLhttps://arxiv.org/abs/ 2506.21539
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.21539 2025
-
[32]
Y . Wang, X. Li, W. Wang, J. Zhang, Y . Li, Y . Chen, X. Wang, and Z. Zhang. Unified vision- language-action model.arXiv preprint arXiv:2506.19850, 2025. doi:10.48550/arXiv.2506. 19850. URLhttps://arxiv.org/abs/2506.19850
-
[33]
Q. Lv, W. Kong, H. Li, J. Zeng, Z. Qiu, D. Qu, H. Song, Q. Chen, X. Deng, and J. Pang. F1: A vision-language-action model bridging understanding and generation to actions.arXiv preprint arXiv:2509.06951, 2025. doi:10.48550/arXiv.2509.06951. URLhttps://arxiv. org/abs/2509.06951
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.06951 2025
-
[34]
J. Chen, W. Song, P. Ding, Z. Zhou, H. Zhao, F. Tang, D. Wang, and H. Li. Unified diffusion vla: Vision-language-action model via joint discrete denoising diffusion process. arXiv preprint arXiv:2511.01718, 2025. doi:10.48550/arXiv.2511.01718. URLhttps: //arxiv.org/abs/2511.01718
-
[35]
Q. Li, Y . Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y . Deng, S. Xu, Y . Zhang, X. Wang, B. Liu, J. Fu, J. Bao, D. Chen, Y . Shi, J. Yang, and B. Guo. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation. arXiv preprint arXiv:2411.19650, 2024. doi:10.48550/arXiv.2411.19650. URLhttps:// a...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.19650 2024
-
[36]
K. Li, L. Clouatre, R. Pathak, and S. Ermon. Chain of thought empowers transformers to solve inherently serial problems.arXiv preprint arXiv:2402.12875, 2024. doi:10.48550/arXiv.2402. 12875. URLhttps://arxiv.org/abs/2402.12875
-
[37]
M. Nye, A. J. Andreassen, G. Gur-Ari, H. Michalewski, J. Austin, D. Bieber, D. Do- han, A. Lewkowycz, M. Bosma, D. Luan, C. Sutton, L. Soares, Y . Hu, D. Chen, and O. Habryka. Show your work: Scratchpads for intermediate computation with language models.arXiv preprint arXiv:2112.00114, 2021. doi:10.48550/arXiv.2112.00114. URL https://arxiv.org/abs/2112.00114
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2112.00114 2021
-
[38]
X. Wang, J. Wei, D. Schuurmans, Q. V . Le, E. H. Chi, and S. Narang. Self-consistency im- proves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2023. doi:10.48550/arXiv.2203.11171. URLhttps://arxiv.org/abs/2203.11171. 11
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.11171 2023
-
[39]
K. Tian, Y . Jiang, Z. Yuan, B. Peng, and L. Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction.arXiv preprint arXiv:2404.02905, 2024. doi:10. 48550/arXiv.2404.02905. URLhttps://arxiv.org/abs/2404.02905
arXiv 2024
-
[40]
BridgeData V2: A dataset for robot learning at scale
H. Walke, K. Black, A. Lee, M. J. Kim, M. Du, C. Zheng, T. Zhao, P. Hansen-Estruch, Q. Vuong, A. He, V . Myers, K. Fang, C. Finn, and S. Levine. Bridgedata v2: A dataset for robot learning at scale.arXiv preprint arXiv:2308.12952, 2023. doi:10.48550/arXiv.2308.12952. URLhttps://arxiv.org/abs/2308.12952
-
[41]
QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation
D. Kalashnikov, A. Irpan, P. Pastor, J. Ibarz, A. Herzog, E. Jang, D. Quillen, E. Holly, M. Kalakrishnan, V . Vanhoucke, and S. Levine. Qt-opt: Scalable deep reinforcement learn- ing for vision-based robotic manipulation.arXiv preprint arXiv:1806.10293, 2018. doi: 10.48550/arXiv.1806.10293. URLhttps://arxiv.org/abs/1806.10293
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1806.10293 2018
-
[42]
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945,
-
[43]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
doi:10.48550/arXiv.2403.12945. URLhttps://arxiv.org/abs/2403.12945. 12 Appendix A Additional Ablations The main paper reports the core simulation, real-world, and design-ablation results. Here we provide additional diagnostic breakdowns and implementation details that support the design choices. A.1 LIBERO Design Ablations Planning Horizon.Table 3 reports...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.12945 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.