Benchmarking LLM Agents on Meta-Analysis Articles from Nature Portfolio
Pith reviewed 2026-06-27 03:45 UTC · model grok-4.3
The pith
LLM agents recover at most 52.7% of ground-truth studies in meta-analyses even when retrieval reaches 90.9% recall.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
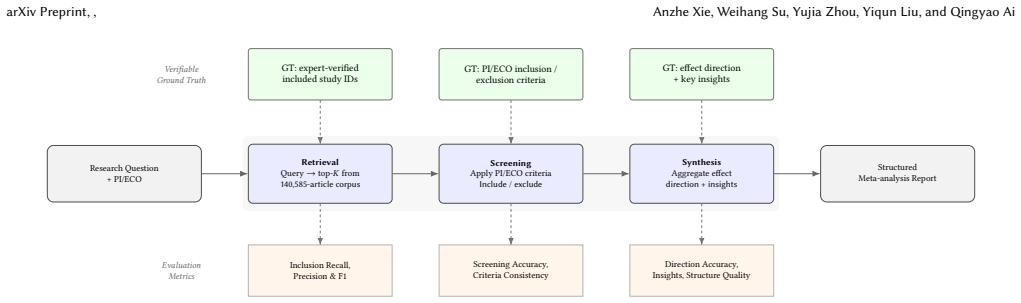
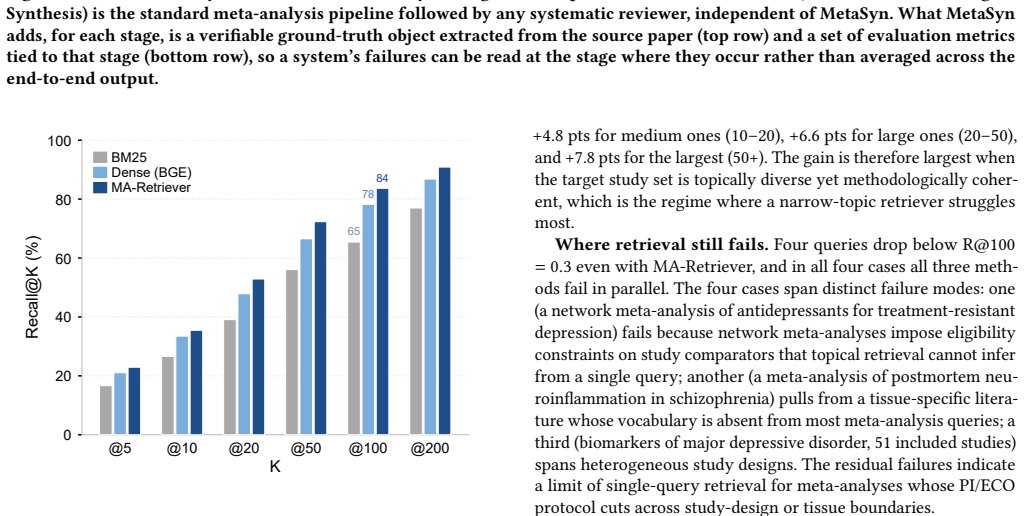
Benchmarking twelve pipeline configurations on the MetaSyn dataset reveals a critical screening bottleneck: despite a retrieval ceiling of 90.9% recall at K=200, no system recovers more than 52.7% of ground-truth included literature. Current LLMs fail to reliably separate eligible studies from PI/ECO-failing distractors in pools of comparable topical relevance. Stage-attributed metrics capture where systems succeed and fail; a single end-to-end score does not.
What carries the argument
The MetaSyn dataset, consisting of research questions paired with PI/ECO criteria, a 140k PubMed retrieval corpus, verified positive studies, hard negatives, and complete search strategies.
If this is right
- Stage-specific evaluation is necessary to diagnose failures in the retrieval-screening-synthesis pipeline.
- The screening stage is the primary limiter on overall performance.
- Hard negatives that match topic but fail PI/ECO criteria expose weaknesses in criteria application.
- End-to-end scores alone are insufficient for measuring progress on meta-analysis tasks.
Where Pith is reading between the lines
- Improving LLM performance on meta-analysis may require explicit training on PI/ECO logic rather than general retrieval improvements.
- Similar bottlenecks may appear in other structured scientific reasoning tasks like systematic reviews.
- The dataset could be used to test whether fine-tuning on eligibility criteria improves separation of eligible and ineligible studies.
- Results suggest that current models treat topical similarity as a proxy for eligibility, which breaks down in this setting.
Load-bearing premise
The 442 Nature Portfolio meta-analyses and their expert-applied PI/ECO criteria form an unbiased and representative test bed for LLM meta-analysis performance.
What would settle it
A system that recovers more than 52.7% of the ground-truth included literature on the MetaSyn dataset while using the same retrieval corpus would falsify the screening bottleneck claim.
Figures




read the original abstract
Meta-analysis is a demanding form of evidence synthesis that combines literature retrieval, PI/ECO-guided study selection, and statistical aggregation. Its structured, verifiable workflow makes it an ideal substrate for evaluating systematic scientific reasoning, yet existing benchmarks lack ground truth across the full retrieval-screening-synthesis pipeline. We introduce MetaSyn, a dataset of 442 expert-curated meta-analyses from Nature Portfolio journals. Each entry pairs a research question with PI/ECO criteria, a retrieval corpus of 140k PubMed articles, verified positive studies, hard negatives that are topically similar but PI/ECO-ineligible, and complete search strategies and date bounds. Benchmarking twelve pipeline configurations (nine RAG variants and a protocol-driven agent) reveals a critical screening bottleneck: despite a retrieval ceiling of 90.9% recall at K=200, no system recovers more than 52.7% of ground-truth included literature. Current LLMs fail to reliably separate eligible studies from PI/ECO-failing distractors in pools of comparable topical relevance. Stage-attributed metrics capture where systems succeed and fail; a single end-to-end score does not.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MetaSyn, a dataset of 442 expert-curated meta-analyses from Nature Portfolio journals. Each entry includes a research question with PI/ECO criteria, a retrieval corpus of ~140k PubMed articles, verified positive studies, hard negatives that are topically similar but PI/ECO-ineligible, and complete search strategies. Benchmarking twelve pipeline configurations (nine RAG variants and one protocol-driven agent) reveals a screening bottleneck: despite 90.9% retrieval recall at K=200, no system recovers more than 52.7% of ground-truth included literature, with LLMs failing to separate eligible studies from distractors of comparable topical relevance. Stage-attributed metrics are used to localize successes and failures.
Significance. If the central empirical result holds, the work supplies a verifiable, ground-truth benchmark for LLM performance across the full retrieval-screening-synthesis pipeline in evidence synthesis. The explicit construction of hard-negative pools and the use of stage-specific rather than single end-to-end scores are concrete strengths that enable precise diagnosis of where systems fail. This directly addresses a gap in existing benchmarks that lack full-pipeline ground truth.
major comments (2)
- [Dataset Construction] Dataset Construction section: The exclusive sourcing of the 442 meta-analyses from Nature Portfolio journals creates a plausible selection-effect risk; the manuscript provides no analysis or discussion of whether the observed PI/ECO separation difficulty (and thus the 52.7% ceiling) is intrinsic to LLMs or an artifact of journal-specific curation choices that may have produced atypically clear criteria or engineered hard-negative pools. This directly affects the load-bearing claim that 'Current LLMs fail to reliably separate eligible studies from PI/ECO-failing distractors.'
- [Results] Results section (and abstract): The headline claim that 'no system recovers more than 52.7%' is reported without per-entry variance, confidence intervals, or statistical testing across the 442 meta-analyses; without these, it is impossible to assess whether the maximum is a stable property of the benchmark or driven by a small number of outliers.
minor comments (1)
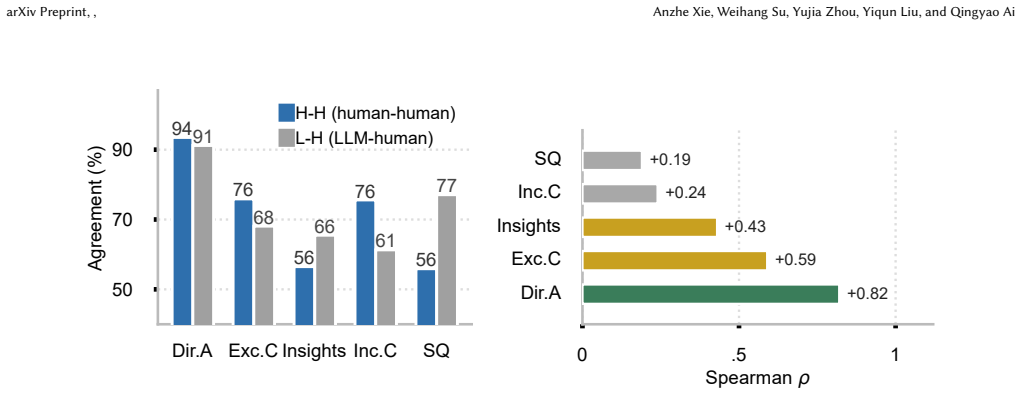
- [Abstract] Abstract: The phrase 'verified positive studies' is used without a forward reference to the precise verification procedure (e.g., double annotation, inter-rater reliability) that appears later in the text.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of our dataset and results presentation. We respond to each major comment below.
read point-by-point responses
-
Referee: [Dataset Construction] Dataset Construction section: The exclusive sourcing of the 442 meta-analyses from Nature Portfolio journals creates a plausible selection-effect risk; the manuscript provides no analysis or discussion of whether the observed PI/ECO separation difficulty (and thus the 52.7% ceiling) is intrinsic to LLMs or an artifact of journal-specific curation choices that may have produced atypically clear criteria or engineered hard-negative pools. This directly affects the load-bearing claim that 'Current LLMs fail to reliably separate eligible studies from PI/ECO-failing distractors.'
Authors: We acknowledge that restricting the dataset to Nature Portfolio journals introduces a plausible selection-effect risk, as these journals may feature particularly well-specified PI/ECO criteria. We selected this source for the high quality and completeness of the expert-curated meta-analyses, which enabled reliable construction of hard-negative pools and full-pipeline ground truth. In the revised manuscript we will add an explicit discussion of this limitation in the Dataset Construction and Limitations sections, including the possibility that the observed screening ceiling could be influenced by journal-specific practices. We continue to argue that the core failure mode—LLMs' inability to reliably apply eligibility criteria to topically matched distractors—is intrinsic rather than artifactual, because the hard negatives were deliberately constructed on the basis of topical similarity independent of journal provenance; however, we agree that broader sampling would be needed to fully substantiate generalizability. revision: partial
-
Referee: [Results] Results section (and abstract): The headline claim that 'no system recovers more than 52.7%' is reported without per-entry variance, confidence intervals, or statistical testing across the 442 meta-analyses; without these, it is impossible to assess whether the maximum is a stable property of the benchmark or driven by a small number of outliers.
Authors: We agree that the headline result would be more robust with statistical characterization. In the revised manuscript we will report the mean and standard deviation of recall across all 442 meta-analyses, 95% confidence intervals for the key aggregate metrics (including the 52.7% ceiling), and a brief analysis confirming that the maximum is not driven by a small number of outliers. revision: yes
Circularity Check
Empirical benchmarking study with no derivation chain or self-referential results
full rationale
The paper introduces an external dataset (MetaSyn) of 442 Nature Portfolio meta-analyses and reports measured performance metrics (e.g., retrieval recall ceilings and screening recovery rates) across LLM pipeline configurations. No equations, first-principles derivations, fitted parameters, or predictions are present that could reduce to inputs by construction. The central claims are empirical observations on an independently curated substrate, with no self-citation load-bearing steps or ansatz smuggling. This matches the default expectation for non-circular empirical benchmarking work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert curation of the 442 meta-analyses supplies accurate and unbiased ground truth for study inclusion under PI/ECO criteria.
Reference graph
Works this paper leans on
-
[1]
Hilda Bastian, Paul Glasziou, and Iain Chalmers. 2010. Seventy-Five Trials and Eleven Systematic Reviews a Day: How Will We Ever Keep Up?PLoS Medicine7, 9 (Sept 2010), e1000326. doi:10.1371/journal.pmed.1000326
-
[2]
Iain Chalmers and Paul Glasziou. 2009. Avoidable waste in the production and reporting of research evidence.The Lancet374, 9683 (July 2009), 86–89. doi:10.1016/s0140-6736(09)60329-9
-
[3]
Ziru Chen, Shijie Chen, Yuting Ning, et al. 2025. ScienceAgentBench: Toward Rigorous Assessment of Language Agents for Data-Driven Scientific Discovery. arXiv:2410.05080 [cs.CL] https://arxiv.org/abs/2410.05080
arXiv 2025
-
[4]
2019.Cochrane Handbook for Systematic Reviews of Interventions. Wiley. doi:10. 1002/9781119536604
2019
-
[5]
Cordas dos Santos, Tobias Tix, Roni Shouval, et al
David M. Cordas dos Santos, Tobias Tix, Roni Shouval, et al. 2024. A systematic review and meta-analysis of nonrelapse mortality after CAR T cell therapy.Nature Medicine30, 9 (July 2024), 2667–2678. doi:10.1038/s41591-024-03084-6
-
[6]
Qian Dong, Qingyao Ai, Hongning Wang, Yiding Liu, Haitao Li, Weihang Su, Yiqun Liu, Tat-Seng Chua, and Shaoping Ma. 2025. Decoupling Knowledge and Context: An Efficient and Effective Retrieval Augmented Generation Framework via Cross Attention. InProceedings of the ACM on Web Conference 2025. 4386– 4395
2025
-
[7]
Qian Dong, Qingyao Ai, Hongning Wang, Yiding Liu, Haitao Li, Weihang Su, Yiqun Liu, Tat-Seng Chua, and Shaoping Ma. 2025. Decoupling Knowledge and Context: An Efficient and Effective Retrieval Augmented Generation Framework via Cross Attention. InProceedings of the ACM on Web Conference 2025(Sydney NSW, Australia)(WWW ’25). Association for Computing Machi...
-
[8]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, and Jonathan Larson. 2024. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130 (2024)
Pith/arXiv arXiv 2024
-
[9]
Elliott, Tari Turner, Ornella Clavisi, James Thomas, Julian P
Julian H. Elliott, Tari Turner, Ornella Clavisi, James Thomas, Julian P. T. Higgins, Chris Mavergames, and Russell L. Gruen. 2014. Living Systematic Reviews: An Emerging Opportunity to Narrow the Evidence-Practice Gap.PLoS Medicine11, 2 (Feb 2014), e1001603. doi:10.1371/journal.pmed.1001603
-
[10]
Yan Fang, Jingtao Zhan, Qingyao Ai, Jiaxin Mao, Weihang Su, Jia Chen, and Yiqun Liu. 2024. Scaling laws for dense retrieval. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1339–1349
2024
-
[11]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. 2024. Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv:2312.10997 [cs.CL] https://arxiv.org/abs/2312.10997
Pith/arXiv arXiv 2024
-
[12]
Gene V. Glass. 1976. Primary, Secondary, and Meta-Analysis of Research.Educa- tional Researcher5, 10 (Nov 1976), 3–8. doi:10.3102/0013189X005010003
-
[13]
Team GLM, :, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, et al. 2024. ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools. arXiv:2406.12793 [cs.CL] https://arxiv.org/abs/2406.12793
Pith/arXiv arXiv 2024
-
[14]
GLM-5-Team, Aohan Zeng, Xin Lv, et al. 2026. GLM-5: from Vibe Coding to Agentic Engineering. arXiv:2602.15763 [cs.LG] https://arxiv.org/abs/2602.15763
Pith/arXiv arXiv 2026
-
[15]
Daya Guo, Dejian Yang, Haowei Zhang, et al. 2025. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.Nature645, 8081 (Sept 2025), 633–638. doi:10.1038/s41586-025-09422-z
-
[16]
Jessica Gurevitch, Julia Koricheva, Shinichi Nakagawa, and Gavin Stewart. 2018. Meta-analysis and the science of research synthesis.Nature555, 7695 (Mar 2018), 175–182. doi:10.1038/nature25753
-
[17]
Lam Thi Mai Huynh, Jie Su, Quanli Wang, Lindsay C. Stringer, Adam D. Switzer, and Alexandros Gasparatos. 2024. Meta-analysis indicates better climate adapta- tion and mitigation performance of hybrid engineering-natural coastal defence measures.Nature Communications15, 1 (Apr 2024), 2871. doi:10.1038/s41467- 024-46970-w
-
[18]
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active retrieval augmented generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 7969–7992
2023
-
[19]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516(2025)
Pith/arXiv arXiv 2025
-
[20]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-Scale Similarity Search with GPUs.IEEE Transactions on Big Data7, 3 (2019), 535–547. doi:10. 1109/TBDATA.2019.2921572
arXiv 2019
-
[21]
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen tau Yih. 2020. Dense Passage Retrieval for Open- Domain Question Answering. arXiv:2004.04906 [cs.CL] https://arxiv.org/abs/ 2004.04906
Pith/arXiv arXiv 2020
-
[22]
Masaki Kato, Hikaru Hori, Takeshi Inoue, Junichi Iga, Masaaki Iwata, Takahiko Inagaki, Kiyomi Shinohara, Hissei Imai, Atsunobu Murata, Kazuo Mishima, and Aran Tajika. 2021. Discontinuation of antidepressants after remission with antidepressant medication in major depressive disorder: a systematic review and meta-analysis.Molecular Psychiatry26 (2021), 118...
-
[23]
Qusai Khraisha, Sophie Put, Johanna Kappenberg, Azza Warraitch, and Kristin Hadfield. 2024. Can large language models replace humans in systematic reviews? Evaluating GPT-4’s efficacy in screening and extracting data from peer-reviewed and grey literature in multiple languages.Research Synthesis Methods15, 4 (Mar 2024), 616–626. doi:10.1002/jrsm.1715
-
[24]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, et al. 2021. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv:2005.11401 [cs.CL] https: //arxiv.org/abs/2005.11401
Pith/arXiv arXiv 2021
-
[25]
Judith-Lisa Lieberum, Markus Toews, Maria-Inti Metzendorf, et al. 2025. Large language models for conducting systematic reviews: on the rise, but not yet ready for use—a scoping review.Journal of Clinical Epidemiology181 (May 2025), 111746. doi:10.1016/j.jclinepi.2025.111746
-
[26]
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. 2024. The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery. arXiv:2408.06292 [cs.AI] https://arxiv.org/abs/2408.06292
Pith/arXiv arXiv 2024
-
[27]
Iain J. Marshall and Byron C. Wallace. 2019. Toward systematic review automa- tion: a practical guide to using machine learning tools in research synthesis. Systematic Reviews8, 1 (July 2019), 93. doi:10.1186/s13643-019-1074-9
-
[28]
Rodrigo Nogueira and Kyunghyun Cho. 2020. Passage Re-ranking with BERT. arXiv:1901.04085 [cs.IR] https://arxiv.org/abs/1901.04085
Pith/arXiv arXiv 2020
-
[29]
Alison O’Mara-Eves, James Thomas, John McNaught, Makoto Miwa, and Sophia Ananiadou. 2015. Using text mining for study identification in systematic reviews: a systematic review of current approaches.Systematic Reviews4, 1 (Jan 2015), 5. doi:10.1186/2046-4053-4-5
-
[30]
Matthew J Page, Joanne E McKenzie, Patrick M Bossuyt, et al. 2021. The PRISMA 2020 statement: an updated guideline for reporting systematic reviews.BMJ (Mar 2021), n71. doi:10.1136/bmj.n71
-
[31]
Liana Patel, Negar Arabzadeh, Harshit Gupta, Ankita Sundar, Ion Stoica, Matei Za- haria, and Carlos Guestrin. 2026. DeepScholar-Bench: A Live Benchmark and Au- tomated Evaluation for Generative Research Synthesis. arXiv:2508.20033 [cs.CL] https://arxiv.org/abs/2508.20033
arXiv 2026
-
[32]
Melissa L. Rethlefsen, Shona Kirtley, Siw Waffenschmidt, et al. 2021. PRISMA-S: an extension to the PRISMA Statement for Reporting Literature Searches in Systematic Reviews.Systematic Reviews10, 1 (Jan 2021), 39. doi:10.1186/s13643- 020-01542-z
-
[33]
Stephen Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Frame- work: BM25 and Beyond.Found. Trends Inf. Retr.3, 4 (Apr 2009), 333–389. doi:10.1561/1500000019
-
[34]
Stephen Robertson, Hugo Zaragoza, et al . 2009. The probabilistic relevance framework: BM25 and beyond.Foundations and Trends®in Information Retrieval 3, 4 (2009), 333–389
2009
-
[35]
Connie Schardt, Martha B Adams, Thomas Owens, Sheri Keitz, and Paul Fontelo
-
[36]
Utilization of the PICO framework to improve searching PubMed for clinical questions.BMC Medical Informatics and Decision Making7, 1 (June 2007),
2007
-
[37]
doi:10.1186/1472-6947-7-16
-
[38]
Aaditya Singh, Adam Fry, Adam Perelman, et al. 2026. OpenAI GPT-5 System Card. arXiv:2601.03267 [cs.CL] https://arxiv.org/abs/2601.03267
Pith/arXiv arXiv 2026
-
[39]
Neil R. Smalheiser. 2017. Rediscovering Don Swanson: the Past, Present and Future of Literature-Based Discovery.Journal of Data and Information Science2, 4 (2017), 43–64. doi:10.1515/jdis-2017-0019
-
[40]
Weihang Su, Qingyao Ai, Xiangsheng Li, Jia Chen, Yiqun Liu, Xiaolong Wu, and Shengluan Hou. 2024. Wikiformer: Pre-training with Structured Information of Wikipedia for Ad-hoc Retrieval. arXiv:2312.10661 [cs.IR] https://arxiv.org/abs/ 2312.10661
arXiv 2024
-
[41]
Weihang Su, Qingyao Ai, Yueyue Wu, Anzhe Xie, Changyue Wang, Yixiao Ma, Haitao Li, Zhijing Wu, Yiqun Liu, and Min Zhang. 2025. Pre-training for legal case retrieval based on inter-case distinctions.ACM Transactions on Information Systems43, 5 (2025), 1–27
2025
-
[42]
Weihang Su, Qingyao Ai, Jingtao Zhan, Qian Dong, and Yiqun Liu. 2025. Dynamic and Parametric Retrieval-Augmented Generation. arXiv:2506.06704 [cs.CL] https: //arxiv.org/abs/2506.06704
arXiv 2025
-
[43]
Weihang Su, Xuanyi Chen, Yueyue Wu, Qingyao Ai, and Yiqun Liu. 2026. Enhanc- ing Judgment Document Generation via Agentic Legal Information Collection and Rubric-Guided Optimization.arXiv preprint arXiv:2605.02011(2026)
Pith/arXiv arXiv 2026
-
[44]
Weihang Su, Qian Dong, Qingyao Ai, and Yiqun Liu. 2025. SIGIR-AP 2025 Tutorial Proposal: Dynamic and Parametric Retrieval-Augmented Generation. In3rd International ACM SIGIR Conference on Information Retrieval in the Asia Pacific
2025
-
[45]
Weihang Su, Yiran Hu, Anzhe Xie, Qingyao Ai, Quezi Bing, Ning Zheng, Yun Liu, Weixing Shen, and Yiqun Liu. 2024. STARD: A Chinese Statute Retrieval Dataset Derived from Real-life Queries by Non-professionals. InFindings of the Association for Computational Linguistics: EMNLP 2024, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for C...
-
[46]
Weihang Su, Jianming Long, Qingyao Ai, Yichen Tang, Changyue Wang, Yiteng Tu, and Yiqun Liu. 2026. Skill Retrieval Augmentation for Agentic AI.arXiv preprint arXiv:2604.24594(2026)
Pith/arXiv arXiv 2026
-
[47]
Weihang Su, Jianming Long, Changyue Wang, Shiyu Lin, Jingyan Xu, Ziyi Ye, Qingyao Ai, and Yiqun Liu. 2025. Towards Unification of Hallucination Detection and Fact Verification for Large Language Models.arXiv preprint arXiv:2512.02772 (2025)
arXiv 2025
-
[48]
Weihang Su, Yichen Tang, Qingyao Ai, Changyue Wang, Zhijing Wu, and Yiqun Liu. 2024. Mitigating entity-level hallucination in large language models. In Proceedings of the 2024 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region. 23–31
2024
-
[49]
Weihang Su, Yichen Tang, Qingyao Ai, Zhijing Wu, and Yiqun Liu. 2024. DRAGIN: Dynamic Retrieval Augmented Generation based on the Information Needs of Large Language Models. arXiv:2403.10081 [cs.CL] https://arxiv.org/abs/2403. 10081
arXiv 2024
-
[50]
Weihang Su, Yichen Tang, Qingyao Ai, Junxi Yan, Changyue Wang, Hongning Wang, Ziyi Ye, Yujia Zhou, and Yiqun Liu. 2025. Parametric retrieval augmented generation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1240–1250
2025
-
[51]
Weihang Su, Changyue Wang, Qingyao Ai, Yiran Hu, Zhijing Wu, Yujia Zhou, and Yiqun Liu. 2024. Unsupervised real-time hallucination detection based on the internal states of large language models. InFindings of the Association for Computational Linguistics: ACL 2024. 14379–14391
2024
-
[52]
Weihang Su, Anzhe Xie, Qingyao Ai, Jianming Long, Xuanyi Chen, Jiaxin Mao, Ziyi Ye, and Yiqun Liu. 2026. SurGE: A Benchmark and Evaluation Framework for Scientific Survey Generation. arXiv:2508.15658 [cs.CL] https://arxiv.org/abs/ 2508.15658 Benchmarking LLM Agents on Meta-Analysis Articles from Nature Portfolio arXiv Preprint, ,
Pith/arXiv arXiv 2026
-
[53]
Weihang Su, Baoqing Yue, Qingyao Ai, Yiran Hu, Jiaqi Li, Changyue Wang, Kaiyuan Zhang, Yueyue Wu, and Yiqun Liu. 2025. JuDGE: Benchmarking Judg- ment Document Generation for Chinese Legal System. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’25), July 13–18, 2025, Padua, Italy. do...
-
[54]
Yuqiao Tan, Shizhu He, Huanxuan Liao, Jun Zhao, and Kang Liu. 2025. Dynamic parametric retrieval augmented generation for test-time knowledge enhancement. arXiv preprint arXiv:2503.23895(2025)
arXiv 2025
-
[55]
Guy Tsafnat, Paul Glasziou, Miew Keen Choong, Adam Dunn, Filippo Galgani, and Enrico Coiera. 2014. Systematic review automation technologies.Systematic Reviews3, 1 (July 2014), 74. doi:10.1186/2046-4053-3-74
-
[56]
Yiteng Tu, Weihang Su, Yujia Zhou, Yiqun Liu, and Qingyao Ai. 2025. Robust Fine-tuning for Retrieval Augmented Generation against Retrieval Defects. In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1272–1282
2025
-
[57]
Michelle Vaccaro, Abdullah Almaatouq, and Thomas Malone. 2024. When com- binations of humans and AI are useful: A systematic review and meta-analysis. Nature Human Behaviour8, 12 (Oct 2024), 2293–2303. doi:10.1038/s41562-024- 02024-1
-
[58]
Rens van de Schoot, Jonathan de Bruin, Raoul Schram, et al. 2021. An open source machine learning framework for efficient and transparent systematic reviews. Nature Machine Intelligence3, 2 (Feb 2021), 125–133. doi:10.1038/s42256-020- 00287-7
-
[59]
Changyue Wang, Weihang Su, Qingyao Ai, and Yiqun Liu. 2026. Joint evalua- tion of answer and reasoning consistency for hallucination detection in large reasoning models. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 33377–33385
2026
-
[60]
Changyue Wang, Weihang Su, Qingyao Ai, Yichen Tang, and Yiqun Liu. 2025. Knowledge editing through chain-of-thought. InProceedings of the 2025 Confer- ence on Empirical Methods in Natural Language Processing. 10684–10704
2025
-
[61]
Changyue Wang, Weihang Su, Qingyao Ai, Yujia Zhou, and Yiqun Liu. 2025. Decoupling reasoning and knowledge injection for in-context knowledge editing. InFindings of the Association for Computational Linguistics: ACL 2025. 24543– 24562
2025
-
[62]
Changyue Wang, Weihang Su, Qingyao Ai, Yujia Zhou, and Yiqun Liu. 2025. De- coupling Reasoning and Knowledge Injection for In-Context Knowledge Editing. arXiv:2506.00536 [cs.CL] https://arxiv.org/abs/2506.00536
arXiv 2025
-
[63]
Yidong Wang, Qi Guo, Wenjin Yao, Hongbo Zhang, Xin Zhang, Zhen Wu, Meishan Zhang, Xinyu Dai, Min Zhang, Qingsong Wen, Wei Ye, Shikun Zhang, and Yue Zhang. 2024. AutoSurvey: Large Language Models Can Automatically Write Surveys. arXiv:2406.10252 [cs.IR] https://arxiv.org/abs/2406.10252
arXiv 2024
-
[64]
Zifeng Wang, Lang Cao, Benjamin Danek, Qiao Jin, Zhiyong Lu, and Jimeng Sun
-
[65]
doi:10.1038/s41746-025-01840-7
Accelerating clinical evidence synthesis with large language models.npj Digital Medicine8, 1 (Aug 2025), 509. doi:10.1038/s41746-025-01840-7
-
[66]
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. 2024. C-Pack: Packed Resources For General Chinese Embeddings. arXiv:2309.07597 [cs.CL] https://arxiv.org/abs/2309.07597
Pith/arXiv arXiv 2024
-
[67]
Howard Yen, Tianyu Gao, and Danqi Chen. 2024. Long-Context Language Modeling with Parallel Context Encoding. arXiv:2402.16617 [cs.CL] https:// arxiv.org/abs/2402.16617
arXiv 2024
-
[68]
Liwen Zheng, Chaozhuo Li, Litian Zhang, Haoran Jia, Senzhang Wang, Zheng Liu, and Xi Zhang. 2025. MRR-FV: Unlocking Complex Fact Verification with Multi-Hop Retrieval and Reasoning. InProceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence (AAAI ’25). AAAI Press, 26066–26074. doi:10. 1609/aaai.v39i24.34802
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.