VTOS: Learning to Orchestrate Vision Tools by Co-Searching Solutions and Observers
Pith reviewed 2026-06-26 21:34 UTC · model grok-4.3
The pith
Co-searching executable vision tool pipelines together with observer programs that diagnose their failures improves adaptation to dense objects, occlusion, and domain shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
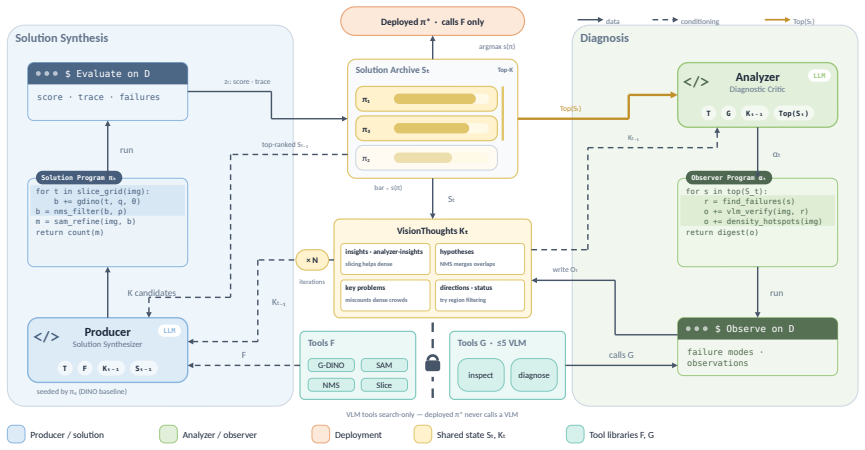
VTOS jointly searches over executable solution programs that chain tools such as Grounding DINO, SAM, NMS, and slice-and-detect, together with observer programs that identify failure modes such as incorrect thresholds or missed small objects and generate feedback; this feedback is stored in the VisionThoughts knowledge base to guide subsequent iterations, producing better orchestration than either static pipelines or agent baselines on tasks that require threshold calibration, mask refinement, and handling of domain shift.
What carries the argument
Joint search of solution programs and observer programs whose diagnoses are accumulated in a shared VisionThoughts knowledge base.
If this is right
- Solution programs can be adapted on the fly for dense object counting by adjusting slicing, NMS, and thresholds.
- Observer feedback enables better mask refinement and generalization on out-of-domain plant-disease segmentation.
- The co-search strategy reduces brittleness compared with fixed tool pipelines under occlusion and small targets.
- Accumulated observations in VisionThoughts allow iterative improvement across multiple search rounds.
Where Pith is reading between the lines
- The same co-search pattern could be tested on orchestration of tools outside vision, such as combining language models with retrieval or code execution.
- If observer quality can itself be improved by search, the method might create self-improving orchestration loops.
- The knowledge base might support transfer of successful observer patterns from one task to another without retraining from scratch.
Load-bearing premise
Observer programs can reliably diagnose failure modes in candidate solutions and generate feedback that improves the joint search without adding noise or bias.
What would settle it
An experiment in which VTOS is run with non-informative or random observers on LVIS-Count and PlantSeg-OOD and still matches the performance of the full method would show that the observers are not driving the gains.
Figures


read the original abstract
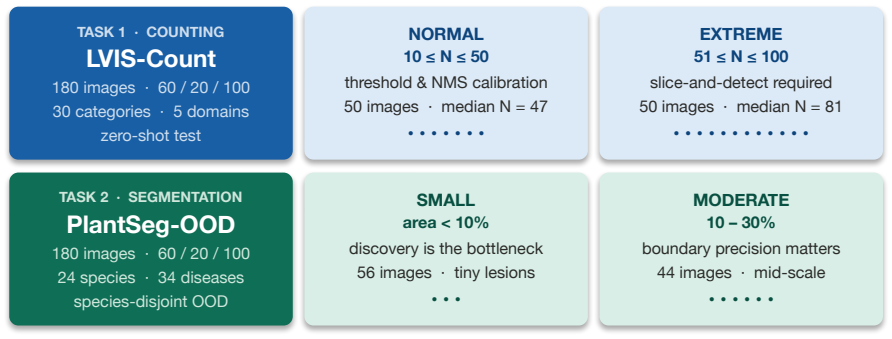
Vision foundation tools such as open-vocabulary detectors, segmentation models, and post-processing operators are powerful building blocks for computer vision, but their effectiveness depends heavily on how they are orchestrated: which tools are used, in what order, with what parameters, and under what visual conditions. Existing visual-programming agents typically generate a fixed solution pipeline, making them brittle under dense objects, occlusion, small targets, and domain shift. We introduce VTOS (Vision Tools Orchestration Search), a framework for adaptive visual tool orchestration through joint solution--observer search. VTOS co-searches executable solution programs that compose vision tools such as Grounding DINO, SAM, NMS, and slice-and-detect, together with observer programs that diagnose candidate solutions, identify failure modes, and generate actionable feedback. These observations are accumulated in a shared VisionThoughts knowledge base to guide subsequent search. We evaluate VTOS through two case studies: dense object counting on LVIS-Count and zero-shot plant-disease segmentation on PlantSeg-OOD, which stress different orchestration challenges including threshold calibration, NMS, slicing, mask refinement, and domain generalization. Across both tasks, VTOS outperforms static tool pipelines and agentic visual-programming baselines, showing that co-searching solutions and observers is an effective strategy for adapting vision tools to challenging computer vision tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VTOS, a framework for adaptive orchestration of vision foundation tools (e.g., Grounding DINO, SAM) via joint search over executable solution programs and diagnostic observer programs. Observers identify failure modes and accumulate feedback in a VisionThoughts knowledge base to guide further search. The approach is evaluated on two case studies—dense object counting on LVIS-Count and zero-shot plant-disease segmentation on PlantSeg-OOD—claiming outperformance over static tool pipelines and agentic visual-programming baselines.
Significance. If the experimental claims are substantiated with controlled quantitative results, the co-search of solutions and observers could represent a meaningful advance in making vision tool pipelines robust to occlusion, domain shift, and dense scenes. The VisionThoughts accumulation mechanism offers a concrete way to close the loop between diagnosis and search, which is a promising direction for agentic CV systems beyond fixed pipelines.
major comments (3)
- [Abstract] Abstract: the central claim that 'VTOS outperforms static tool pipelines and agentic visual-programming baselines' is stated without any quantitative results, error bars, ablation tables, or implementation details (e.g., number of LLM calls, search budget, or success metrics), so the claim cannot be evaluated from the provided text.
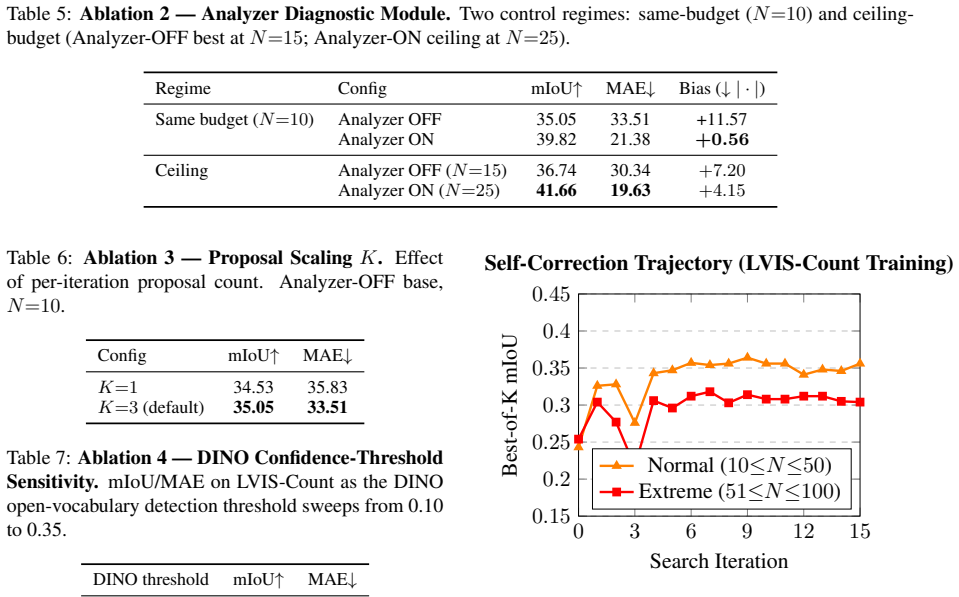
- [Evaluation] Evaluation sections (case studies): no controlled ablation is described that holds total search iterations or LLM evaluations fixed while toggling the presence of observer generation and VisionThoughts feedback. Without this isolation, gains cannot be attributed specifically to co-searching observers rather than simply exploring more candidate solutions.
- [Method] Method description: the assumption that observer programs reliably produce actionable, low-noise feedback is load-bearing for the joint-search claim, yet no analysis of observer accuracy, failure-mode coverage, or cases where feedback introduces bias is provided.
minor comments (1)
- [Abstract] The abstract and introduction would benefit from explicit definitions of the two tasks' metrics (e.g., counting MAE, segmentation IoU) and the exact baselines used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract, evaluation protocol, and observer analysis require strengthening for clarity and rigor. We address each major comment below and will incorporate revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'VTOS outperforms static tool pipelines and agentic visual-programming baselines' is stated without any quantitative results, error bars, ablation tables, or implementation details (e.g., number of LLM calls, search budget, or success metrics), so the claim cannot be evaluated from the provided text.
Authors: We agree the abstract should include concrete quantitative support. In the revision we will add key performance metrics (with error bars), search budget, and LLM call counts drawn from the experimental results to make the central claim evaluable directly from the abstract. revision: yes
-
Referee: [Evaluation] Evaluation sections (case studies): no controlled ablation is described that holds total search iterations or LLM evaluations fixed while toggling the presence of observer generation and VisionThoughts feedback. Without this isolation, gains cannot be attributed specifically to co-searching observers rather than simply exploring more candidate solutions.
Authors: This is a valid concern for attribution. We will add a controlled ablation that fixes the total search iterations and LLM evaluations while toggling observer generation and VisionThoughts feedback, allowing direct isolation of the co-search contribution. revision: yes
-
Referee: [Method] Method description: the assumption that observer programs reliably produce actionable, low-noise feedback is load-bearing for the joint-search claim, yet no analysis of observer accuracy, failure-mode coverage, or cases where feedback introduces bias is provided.
Authors: We acknowledge the need for explicit validation of the observer component. The revision will include quantitative and qualitative analysis of observer accuracy (e.g., agreement with human failure-mode labels on sampled cases), coverage of failure modes, and discussion of potential bias introduced by noisy feedback. revision: yes
Circularity Check
No circularity in empirical framework
full rationale
The paper describes an empirical search framework evaluated on two computer vision tasks with comparisons to baselines. No equations, derivations, fitted parameters presented as predictions, or self-referential definitions appear in the abstract or described content. Claims rest on experimental outcomes rather than any reduction to inputs by construction. No load-bearing self-citations or uniqueness theorems are invoked. This is the expected non-finding for a non-mathematical systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Visual instruction tuning , volume =
Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae , editor =. Visual instruction tuning , volume =. Advances in neural information processing systems , publisher =. 2023 , keywords =
2023
-
[2]
Toward ultra-long-horizon agentic science: Cognitive accumulation for machine learning engineering
Zhu, Xinyu and Cai, Yuzhu and Liu, Zexi and Zheng, Bingyang and Wang, Cheng and Ye, Rui and Chen, Jiaao and Wang, Hanrui and Wang, Wei-Chen and Zhang, Yuzhi and Zhang, Linfeng and E, Weinan and Jin, Di and Chen, Siheng , month = jan, year =. Toward ultra-long-horizon agentic science:. doi:10.48550/arXiv.2601.10402 , abstract =
-
[3]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Wang, Guanzhi and Xie, Yuqi and Jiang, Yunfan and Mandlekar, Ajay and Xiao, Chaowei and Zhu, Yuke and Fan, Linxi and Anandkumar, Anima , month = oct, year =. Voyager:. doi:10.48550/arXiv.2305.16291 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.16291
-
[4]
arXiv preprint arXiv:2511.15593 , author =
What does it take to be a good. arXiv preprint arXiv:2511.15593 , author =. 2025 , note =
arXiv 2025
-
[5]
Gupta, Tanmay and Kembhavi, Aniruddha , month = jun, year =. Visual. 2023. doi:10.1109/CVPR52729.2023.01436 , urldate =
-
[6]
Surís, Dídac and Menon, Sachit and Vondrick, Carl , month = oct, year =. 2023. doi:10.1109/ICCV51070.2023.01092 , urldate =
-
[7]
SAM 2: Segment Anything in Images and Videos
Ravi, Nikhila and Gabeur, Valentin and Hu, Yuan-Ting and Hu, Ronghang and Ryali, Chaitanya and Ma, Tengyu and Khedr, Haitham and Rädle, Roman and Rolland, Chloe and Gustafson, Laura and Mintun, Eric and Pan, Junting and Vasudev Alwala, Kalyan and Carion, Nicolas and Wu, Chao-Yuan and Girshick, Ross and Dollár, Piotr and Feichtenhofer, Christoph , month = ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.00714
-
[8]
Slicing aided hyper inference and fine-tuning for small object detection , doi =
Akyon, Fatih Cagatay and Onur Altinuc, Sinan and Temizel, Alptekin , year =. Slicing aided hyper inference and fine-tuning for small object detection , doi =. 2022
2022
-
[9]
Bai, Shuai and Cai, Yuxuan and Chen, Ruizhe and Chen, Keqin and Chen, Xionghui and Cheng, Zesen and Deng, Lianghao and Ding, Wei and Gao, Chang and Ge, Chunjiang and Ge, Wenbin and Guo, Zhifang and Huang, Qidong and Huang, Jie and Huang, Fei and Hui, Binyuan and Jiang, Shutong and Li, Zhaohai and Li, Mingsheng and Li, Mei and Li, Kaixin and Lin, Zicheng a...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.21631
-
[10]
International conference on machine learning,
Gao, Luyu and Madaan, Aman and Zhou, Shuyan and Alon, Uri and Liu, Pengfei and Yang, Yiming and Callan, Jamie and Neubig, Graham , editor =. International conference on machine learning,. 2023 , note =
2023
-
[11]
System prompt optimization with meta-learning , url =
Choi, Yumin and Baek, Jinheon and Hwang, Sung Ju , month = oct, year =. System prompt optimization with meta-learning , url =. doi:10.48550/arXiv.2505.09666 , abstract =
-
[12]
International conference on learning representations , author =
Tent:. International conference on learning representations , author =. 2021 , keywords =
2021
-
[13]
Multi-agent architecture search via agentic supernet , shorttitle =
Zhang, Guibin and Niu, Luyang and Fang, Junfeng and Wang, Kun and Bai, Lei and Wang, Xiang , month = jun, year =. Multi-agent architecture search via agentic supernet , shorttitle =. doi:10.48550/arXiv.2502.04180 , abstract =
-
[14]
Zhou, Han and Wan, Xingchen and Sun, Ruoxi and Palangi, Hamid and Iqbal, Shariq and Vulić, Ivan and Korhonen, Anna and Arık, Sercan Ö , month = feb, year =. Multi-agent design:. doi:10.48550/arXiv.2502.02533 , abstract =
-
[15]
doi:10.48550/arXiv.2304.01904 , abstract =
Paul, Debjit and Ismayilzada, Mete and Peyrard, Maxime and Borges, Beatriz and Bosselut, Antoine and West, Robert and Faltings, Boi , month = feb, year =. doi:10.48550/arXiv.2304.01904 , abstract =
-
[16]
TextGrad: Automatic "Differentiation" via Text
Yuksekgonul, Mert and Bianchi, Federico and Boen, Joseph and Liu, Sheng and Huang, Zhi and Guestrin, Carlos and Zou, James , month = jun, year =. doi:10.48550/arXiv.2406.07496 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.07496
-
[17]
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
Yang, Zhengyuan and Li, Linjie and Wang, Jianfeng and Lin, Kevin and Azarnasab, Ehsan and Ahmed, Faisal and Liu, Zicheng and Liu, Ce and Zeng, Michael and Wang, Lijuan , year =. doi:10.48550/ARXIV.2303.11381 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.11381
-
[18]
Shen, Yongliang and Song, Kaitao and Tan, Xu and Li, Dongsheng and Lu, Weiming and Zhuang, Yueting , booktitle =
-
[19]
and Cao, Yuan , year =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik R. and Cao, Yuan , year =. The eleventh international conference on learning representations,
-
[20]
Proceedings of the 37th international conference on neural information processing systems , publisher =
Madaan, Aman and Tandon, Niket and Gupta, Prakhar and Hallinan, Skyler and Gao, Luyu and Wiegreffe, Sarah and Alon, Uri and Dziri, Nouha and Prabhumoye, Shrimai and Yang, Yiming and Gupta, Shashank and Majumder, Bodhisattwa Prasad and Hermann, Katherine and Welleck, Sean and Yazdanbakhsh, Amir and Clark, Peter , year =. Proceedings of the 37th internation...
-
[21]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Ren, Tianhe and Liu, Shilong and Zeng, Ailing and Lin, Jing and Li, Kunchang and Cao, He and Chen, Jiayu and Huang, Xinyu and Chen, Yukang and Yan, Feng and Zeng, Zhaoyang and Zhang, Hao and Li, Feng and Yang, Jie and Li, Hongyang and Jiang, Qing and Zhang, Lei , month = jan, year =. Grounded. doi:10.48550/arXiv.2401.14159 , journal =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.14159
-
[22]
arXiv e-prints , author =
Learning transferable visual models from natural language supervision , doi =. arXiv e-prints , author =. 2021 , note =
2021
-
[23]
and Lo, Wan-Yen and Dollar, Piotr and Girshick, Ross , month = oct, year =
Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Dollar, Piotr and Girshick, Ross , month = oct, year =. Segment anything , booktitle =
-
[24]
Executable code actions elicit better
Wang, Xingyao and Chen, Yangyi and Yuan, Lifan and Zhang, Yizhe and Li, Yunzhu and Peng, Hao and Ji, Heng , year =. Executable code actions elicit better. Proceedings of the 41st international conference on machine learning , publisher =
-
[25]
Amini-Naieni, Niki and Han, Tengda and Zisserman, Andrew , editor =. 2024 , pages =. doi:10.52202/079017-1547 , booktitle =
-
[26]
CORAL: Towards Autonomous Multi-Agent Evolution for Open-Ended Discovery
Qu, Ao and Zheng, Han and Zhou, Zijian and Yan, Yihao and Tang, Yihong and Ong, Shao Yong and Hong, Fenglu and Zhou, Kaichen and Jiang, Chonghe and Kong, Minwei and Zhu, Jiacheng and Jiang, Xuan and Li, Sirui and Wu, Cathy and Low, Bryan Kian Hsiang and Zhao, Jinhua and Liang, Paul Pu , month = apr, year =. doi:10.48550/arXiv.2604.01658 , journal =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.01658
-
[27]
arXiv preprint arXiv:2604.04872 , author =
Synthetic sandbox for training machine learning engineering agents , url =. arXiv preprint arXiv:2604.04872 , author =. 2026 , note =
Pith/arXiv arXiv 2026
-
[28]
Learning to ideate for machine learning engineering agents , url =
Zhang, Yunxiang and Zhou, Kang and Xu, Zhichao and Ramnath, Kiran and Zhou, Yun and Woo, Sangmin and Ding, Haibo and Cheong, Lin Lee , editor =. Learning to ideate for machine learning engineering agents , url =. 2026 , pages =. doi:10.18653/v1/2026.eacl-short.32 , booktitle =
- [29]
-
[30]
Advances in neural information processing systems , author =
-
[31]
arXiv preprint arXiv:2505.14738 , author =
R&. arXiv preprint arXiv:2505.14738 , author =. 2025 , note =
arXiv 2025
-
[32]
International conference on learning representations , author =
-
[33]
Reflexion: language agents with verbal reinforcement learning , abstract =
Shinn, Noah and Cassano, Federico and Gopinath, Ashwin and Narasimhan, Karthik and Yao, Shunyu , year =. Reflexion: language agents with verbal reinforcement learning , abstract =. Proceedings of the 37th international conference on neural information processing systems , publisher =
-
[34]
CoRR , author =. 2024 , note =. doi:10.48550/ARXIV.2410.21276 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.21276 2024
-
[35]
Kim, Jin and Wahi-Anwa, Muhammad and Park, Sangyun and Shin, Shawn and Hoffman, John M. and Brown, Matthew S. , month = jun, year =. Autonomous computer vision development with agentic. doi:10.48550/arXiv.2506.11140 , abstract =
-
[36]
GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering
Hudson, Drew A. and Manning, Christopher D. , month = may, year =. doi:10.48550/arXiv.1902.09506 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1902.09506 1902
-
[37]
doi:10.48550/arXiv.1908.03195 , abstract =
Gupta, Agrim and Dollár, Piotr and Girshick, Ross , month = sep, year =. doi:10.48550/arXiv.1908.03195 , abstract =
-
[38]
doi:10.48550/arXiv.2209.11486 , abstract =
Hou, Yutai and Dong, Hongyuan and Wang, Xinghao and Li, Bohan and Che, Wanxiang , month = feb, year =. doi:10.48550/arXiv.2209.11486 , abstract =
-
[39]
arXiv preprint arXiv:2303.05499 , author =
Grounding. arXiv preprint arXiv:2303.05499 , author =. 2023 , keywords =
Pith/arXiv arXiv 2023
-
[40]
doi:10.48550/arXiv.2410.02958 , abstract =
Trirat, Patara and Jeong, Wonyong and Hwang, Sung Ju , month = jun, year =. doi:10.48550/arXiv.2410.02958 , abstract =
-
[41]
doi:10.48550/arXiv.2402.15351 , abstract =
Yang, Zekang and Zeng, Wang and Jin, Sheng and Qian, Chen and Luo, Ping and Liu, Wentao , month = dec, year =. doi:10.48550/arXiv.2402.15351 , abstract =
-
[42]
Learning to count everything , url =
Ranjan, Viresh and Sharma, Udbhav and Nguyen, Thu and Hoai, Minh , month = apr, year =. Learning to count everything , url =. doi:10.48550/arXiv.2104.08391 , abstract =
- [43]
- [44]
-
[45]
doi:10.48550/arXiv.2510.02669 , abstract =
Ma, Bo and Li, Hang and Hu, ZeHua and Gui, XiaoFan and Liu, LuYao and Liu, Simon , month = oct, year =. doi:10.48550/arXiv.2510.02669 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.