Vecchia-Inducing-Points Full-Scale Approximations for Gaussian Processes
Pith reviewed 2026-05-25 07:42 UTC · model grok-4.3
The pith
Vecchia-inducing-points full-scale approximations combine inducing points and Vecchia methods to scale Gaussian processes to large datasets with improved accuracy and stability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VIF approximations bridge the regimes of inducing point and Vecchia methods by using inducing points for the main process and Vecchia for the residual, with correlation-based neighbor finding, resulting in computationally efficient, accurate, and stable approximations for both Gaussian and non-Gaussian likelihoods.
What carries the argument
The VIF approximation, which pairs inducing points with a Vecchia approximation on the residual process via correlation-based neighbor search implemented with a modified cover tree algorithm.
If this is right
- Enables handling of both low- and high-dimensional inputs effectively.
- Reduces computational costs for non-Gaussian likelihoods by several orders of magnitude using iterative methods.
- Provides theoretical convergence results for the preconditioners in Laplace approximations.
- Shows superior performance in experiments on simulated and real-world datasets.
Where Pith is reading between the lines
- The approach may allow Gaussian processes to be applied to even larger problems in fields like spatial statistics or machine learning.
- Novel preconditioners could be adapted for other scalable GP methods.
- Further testing in extreme regimes might highlight when the neighbor-finding strategy needs adjustment.
Load-bearing premise
The correlation-based neighbor-finding strategy for the Vecchia approximation of the residual process works reliably across various input dimensions and covariance smoothness levels.
What would settle it
If experiments on data with higher input dimensions or less smooth covariance functions than those tested show reduced accuracy or instability compared to alternatives, that would challenge the central claim.
Figures



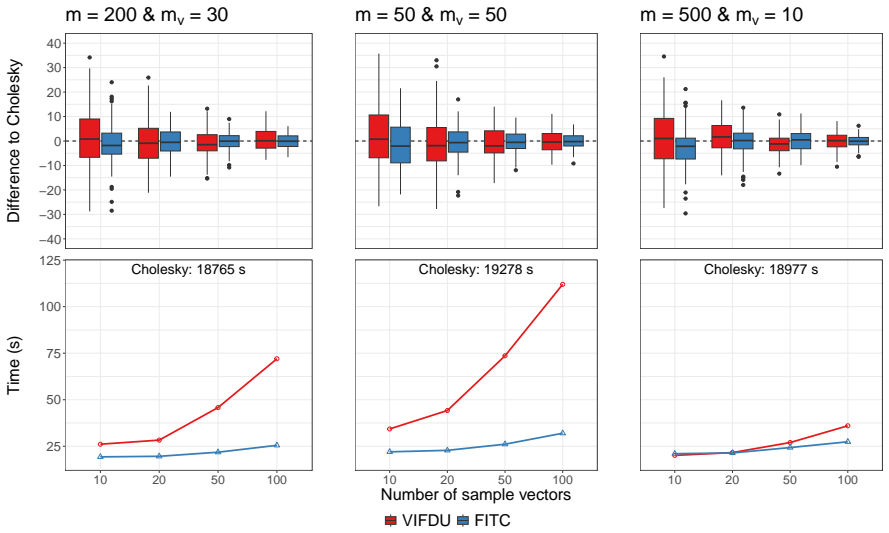

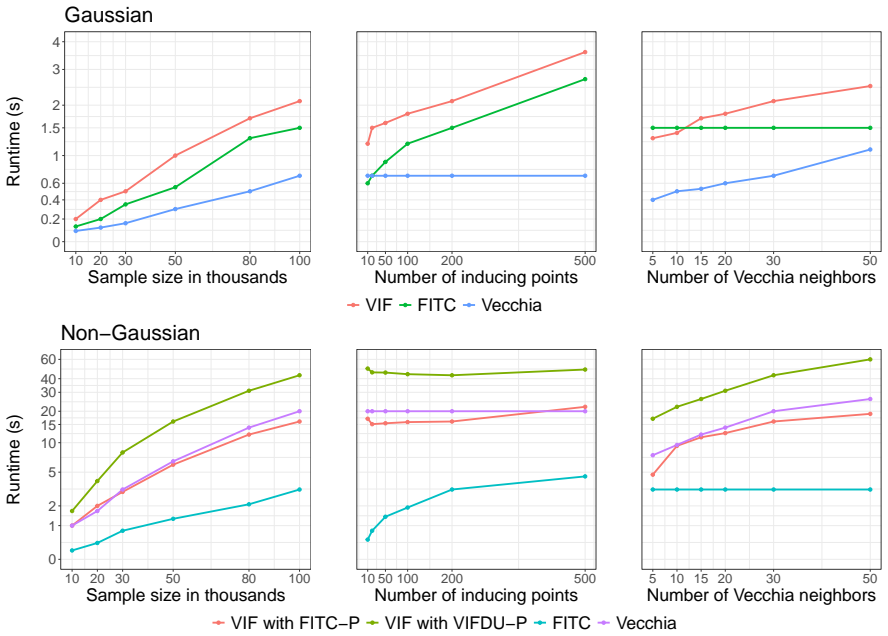







read the original abstract
Gaussian processes are flexible, probabilistic, non-parametric models widely used in machine learning and statistics. However, their scalability to large data sets is limited by computational constraints. To overcome these challenges, we propose Vecchia-inducing-points full-scale (VIF) approximations combining the strengths of global inducing points and local Vecchia approximations. Vecchia approximations excel in settings with low-dimensional inputs and moderately smooth covariance functions, while inducing point methods are better suited to high-dimensional inputs and smoother covariance functions. Our VIF approach bridges these two regimes by using an efficient correlation-based neighbor-finding strategy for the Vecchia approximation of the residual process, implemented via a modified cover tree algorithm. We further extend our framework to non-Gaussian likelihoods by introducing iterative methods that substantially reduce computational costs for training and prediction by several orders of magnitudes compared to Cholesky-based computations when using a Laplace approximation. In particular, we propose and compare novel preconditioners and provide theoretical convergence results. Extensive numerical experiments on simulated and real-world data sets show that VIF approximations are both computationally efficient as well as more accurate and numerically stable than state-of-the-art alternatives. All methods are implemented in the open source C++ library GPBoost with high-level Python and R interfaces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Vecchia-inducing-points full-scale (VIF) approximations for Gaussian processes that combine global inducing-point methods with local Vecchia approximations applied to the residual process after the inducing-point correction. The Vecchia component uses a correlation-based neighbor-finding strategy implemented via a modified cover tree. The framework is extended to non-Gaussian likelihoods via iterative methods and novel preconditioners with theoretical convergence results under Laplace approximation. Extensive numerical experiments on simulated and real-world datasets are reported to demonstrate that VIF approximations are computationally efficient as well as more accurate and numerically stable than state-of-the-art alternatives. The methods are implemented in the open-source GPBoost library with Python and R interfaces.
Significance. If the central claims hold, the work provides a practical method that bridges the regimes where Vecchia approximations excel (low-dimensional inputs, moderate smoothness) and where inducing-point methods are preferred (high-dimensional inputs, smoother kernels). The open-source implementation and the theoretical convergence results for the iterative solvers are explicit strengths that enhance reproducibility and usability.
major comments (2)
- [Method description of VIF approximation and neighbor-finding strategy] The central claim that VIF bridges low- and high-dimensional regimes rests on the reliability of the correlation-based neighbor-finding strategy for the residual Vecchia component. The manuscript does not report targeted experiments that stress this heuristic when input dimension exceeds the tested range (d>20) or when covariance smoothness increases (e.g., Matérn ν>5/2), where pairwise correlation may cease to be a faithful proxy for conditional dependence after the global correction. This assumption is load-bearing for the accuracy and stability superiority claims.
- [Numerical experiments section] The abstract asserts superiority on the basis of extensive numerical experiments, yet the manuscript provides no details on experimental design, data exclusion criteria, or error-bar reporting. Without these, the support for the claim that VIF is more accurate and numerically stable cannot be fully assessed. This directly affects evaluation of the central empirical claim.
minor comments (2)
- [Abstract] The phrase 'several orders of magnitudes' in the abstract should read 'several orders of magnitude'.
- Notation for the residual process and the correlation threshold parameter should be introduced with explicit definitions and cross-references to the inducing-point correction step to improve readability.
Simulated Author's Rebuttal
We are grateful to the referee for their insightful comments. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method description of VIF approximation and neighbor-finding strategy] The central claim that VIF bridges low- and high-dimensional regimes rests on the reliability of the correlation-based neighbor-finding strategy for the residual Vecchia component. The manuscript does not report targeted experiments that stress this heuristic when input dimension exceeds the tested range (d>20) or when covariance smoothness increases (e.g., Matérn ν>5/2), where pairwise correlation may cease to be a faithful proxy for conditional dependence after the global correction. This assumption is load-bearing for the accuracy and stability superiority claims.
Authors: We agree that the reliability of the correlation-based neighbor-finding strategy after the inducing-point correction is central to the bridging claim. While the current experiments span a range of input dimensions and kernel smoothness levels, we acknowledge that the manuscript lacks targeted stress tests specifically for d>20 and Matérn ν>5/2. In the revised manuscript we will add such experiments to directly evaluate the heuristic's performance in these regimes and thereby provide stronger empirical support for the accuracy and stability claims. revision: yes
-
Referee: [Numerical experiments section] The abstract asserts superiority on the basis of extensive numerical experiments, yet the manuscript provides no details on experimental design, data exclusion criteria, or error-bar reporting. Without these, the support for the claim that VIF is more accurate and numerically stable cannot be fully assessed. This directly affects evaluation of the central empirical claim.
Authors: We thank the referee for highlighting the need for greater transparency. In the revised manuscript we will expand the numerical experiments section to include a detailed description of the experimental design, any data exclusion criteria applied, and reporting of error bars or standard deviations across repeated runs. This will allow readers to fully assess the empirical support for the accuracy and stability superiority claims. revision: yes
Circularity Check
No significant circularity; hybrid approximation is independently constructed.
full rationale
The paper introduces VIF as an algorithmic combination of global inducing points and local Vecchia approximations for the residual process, with a correlation-based neighbor search via modified cover tree. No equations, predictions, or uniqueness claims are shown to reduce by construction to fitted inputs, self-citations, or prior ansatzes from the same authors. The central performance claims rest on numerical experiments rather than any self-referential derivation. This is the common case of a self-contained methodological proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
K-means++ the advantages of careful seeding
David Arthur and Sergei Vassilvitskii. K-means++ the advantages of careful seeding. In Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms, pages 1027--1035, 2007
work page 2007
-
[2]
Parameter estimation in high dimensional G aussian distributions
Erlend Aune, Daniel P Simpson, and Jo Eidsvik. Parameter estimation in high dimensional G aussian distributions. Statistics and Computing, 24: 0 247--263, 2014
work page 2014
-
[3]
G aussian predictive process models for large spatial data sets
Sudipto Banerjee, Alan E Gelfand, Andrew O Finley, and Huiyan Sang. G aussian predictive process models for large spatial data sets. Journal of the Royal Statistical Society Series B: Statistical Methodology, 70 0 (4): 0 825--848, 2008
work page 2008
-
[4]
An estimator for the diagonal of a matrix
Costas Bekas, Effrosyni Kokiopoulou, and Yousef Saad. An estimator for the diagonal of a matrix. Applied N umerical M athematics , 57 0 (11-12): 0 1214--1229, 2007
work page 2007
-
[5]
Cover trees for nearest neighbor
Alina Beygelzimer, Sham Kakade, and John Langford. Cover trees for nearest neighbor. In Proceedings of the 23rd international conference on Machine learning, pages 97--104, 2006
work page 2006
-
[6]
Jian Cao, Myeongjong Kang, Felix Jimenez, Huiyan Sang, Florian Tobias Schaefer, and Matthias Katzfuss. Variational sparse inverse C holesky approximation for latent G aussian processes via double K ullback- L eibler minimization. In International Conference on Machine Learning, pages 3559--3576. PMLR, 2023
work page 2023
-
[7]
Noel Cressie. Statistics for spatial data. John Wiley & Sons, 1993
work page 1993
-
[8]
Improving dual-tree algorithms
Ryan R Curtin. Improving dual-tree algorithms. PhD thesis, Georgia Institute of Technology, Atlanta, GA, USA, 2016
work page 2016
-
[9]
Hierarchical nearest-neighbor G aussian process models for large geostatistical datasets
Abhirup Datta, Sudipto Banerjee, Andrew O Finley, and Alan E Gelfand. Hierarchical nearest-neighbor G aussian process models for large geostatistical datasets. Journal of the American Statistical Association, 111 0 (514): 0 800--812, 2016
work page 2016
-
[10]
Direct methods for sparse linear systems
Timothy A Davis. Direct methods for sparse linear systems. SIAM, 2006
work page 2006
-
[11]
Scalable log determinants for G aussian process kernel learning
Kun Dong, David Eriksson, Hannes Nickisch, David Bindel, and Andrew G Wilson. Scalable log determinants for G aussian process kernel learning. Advances in Neural Information Processing Systems, 30, 2017
work page 2017
-
[12]
The approximation of one matrix by another of lower rank
Carl Eckart and Gale Young. The approximation of one matrix by another of lower rank. Psychometrika, 1 0 (3): 0 211--218, 1936
work page 1936
-
[13]
A new near-linear time algorithm for k-nearest neighbor search using a compressed cover tree
Yury Elkin and Vitaliy Kurlin. A new near-linear time algorithm for k-nearest neighbor search using a compressed cover tree. In International Conference on Machine Learning, pages 9267--9311. PMLR, 2023
work page 2023
-
[14]
Improving the performance of predictive process modeling for large datasets
Andrew O Finley, Huiyan Sang, Sudipto Banerjee, and Alan E Gelfand. Improving the performance of predictive process modeling for large datasets. Computational S tatistics & D ata A nalysis , 53 0 (8): 0 2873--2884, 2009
work page 2009
-
[15]
Practical methods of optimization
Roger Fletcher. Practical methods of optimization. John Wiley & Sons, 2000
work page 2000
-
[16]
Covariance tapering for interpolation of large spatial datasets
Reinhard Furrer, Marc G Genton, and Douglas Nychka. Covariance tapering for interpolation of large spatial datasets. Journal of Computational and Graphical Statistics, 15 0 (3): 0 502--523, 2006
work page 2006
-
[17]
Gpytorch: B lackbox matrix-matrix G aussian process inference with gpu acceleration
Jacob Gardner, Geoff Pleiss, Kilian Q Weinberger, David Bindel, and Andrew G Wilson. Gpytorch: B lackbox matrix-matrix G aussian process inference with gpu acceleration. Advances in Neural Information Processing Systems, 31, 2018 a
work page 2018
-
[18]
Product kernel interpolation for scalable G aussian processes
Jacob Gardner, Geoff Pleiss, Ruihan Wu, Kilian Weinberger, and Andrew Wilson. Product kernel interpolation for scalable G aussian processes. In International Conference on Artificial Intelligence and Statistics, pages 1407--1416. PMLR, 2018 b
work page 2018
-
[19]
G aussian process learning via F isher scoring of V ecchia’s approximation
Joseph Guinness. G aussian process learning via F isher scoring of V ecchia’s approximation . Statistics and Computing, 31 0 (3): 0 1--8, 2021
work page 2021
-
[20]
Iterative methods for full-scale G aussian process approximations for large spatial data
Tim Gyger, Reinhard Furrer, and Fabio Sigrist. Iterative methods for full-scale G aussian process approximations for large spatial data. arXiv preprint arXiv:2405.14492, 2024
-
[21]
On the low-rank approximation by the pivoted C holesky decomposition
Helmut Harbrecht, Michael Peters, and Reinhold Schneider. On the low-rank approximation by the pivoted C holesky decomposition. Applied N umerical M athematics , 62 0 (4): 0 428--440, 2012
work page 2012
-
[22]
A case study competition among methods for analyzing large spatial data
Matthew J Heaton, Abhirup Datta, Andrew O Finley, Reinhard Furrer, Joseph Guinness, Rajarshi Guhaniyogi, Florian Gerber, Robert B Gramacy, Dorit Hammerling, Matthias Katzfuss, et al. A case study competition among methods for analyzing large spatial data. Journal of Agricultural, Biological and Environmental Statistics, 24: 0 398--425, 2019
work page 2019
-
[23]
G aussian processes for big data
James Hensman, Nicol \`o Fusi, and Neil D Lawrence. G aussian processes for big data. In Proceedings of the Twenty-Ninth Conference on Uncertainty in Artificial Intelligence, pages 282--290, 2013
work page 2013
-
[24]
Scalable variational G aussian process classification
James Hensman, Alexander Matthews, and Zoubin Ghahramani. Scalable variational G aussian process classification. In Artificial intelligence and statistics, pages 351--360. PMLR, 2015
work page 2015
-
[25]
Roger A Horn and Charles R Johnson. Matrix analysis. Cambridge university P ress, 2012
work page 2012
-
[26]
A stochastic estimator of the trace of the influence matrix for L aplacian smoothing splines
Michael F Hutchinson. A stochastic estimator of the trace of the influence matrix for L aplacian smoothing splines. Communications in Statistics-Simulation and Computation, 18 0 (3): 0 1059--1076, 1989
work page 1989
-
[27]
Correlation-based sparse inverse C holesky factorization for fast G aussian-process inference
Myeongjong Kang and Matthias Katzfuss. Correlation-based sparse inverse C holesky factorization for fast G aussian-process inference. Statistics and Computing, 33 0 (3): 0 56, 2023
work page 2023
-
[28]
A general framework for V ecchia approximations of G aussian processes
Matthias Katzfuss and Joseph Guinness. A general framework for V ecchia approximations of G aussian processes. Statistical Science, 36 0 (1): 0 124--141, 2021
work page 2021
-
[29]
V ecchia approximations of G aussian-process predictions
Matthias Katzfuss, Joseph Guinness, Wenlong Gong, and Daniel Zilber. V ecchia approximations of G aussian-process predictions. Journal of Agricultural, Biological and Environmental Statistics, 25: 0 383--414, 2020
work page 2020
-
[30]
Iterative methods for V ecchia- L aplace approximations for latent G aussian process models
Pascal K \"u ndig and Fabio Sigrist. Iterative methods for V ecchia- L aplace approximations for latent G aussian process models. Journal of the American Statistical Association, 0 (just-accepted): 0 1--22, 2024
work page 2024
-
[31]
Cornelius Lanczos. An iteration method for the solution of the eigenvalue problem of linear differential and integral operators. 1950
work page 1950
-
[32]
Christiane Lemieux. Control variates. Wiley StatsRef: Statistics Reference Online, pages 1--8, 2014
work page 2014
-
[33]
Richard J Lipton, Donald J Rose, and Robert Endre Tarjan. Generalized nested dissection. SIAM Journal on N umerical A nalysis , 16 0 (2): 0 346--358, 1979
work page 1979
-
[34]
When G aussian process meets big data: A review of scalable GP s
Haitao Liu, Yew-Soon Ong, Xiaobo Shen, and Jianfei Cai. When G aussian process meets big data: A review of scalable GP s. IEEE Transactions on Neural Networks and Learning Systems, 31 0 (11): 0 4405--4423, 2020
work page 2020
-
[35]
Approximations for binary G aussian process classification
Hannes Nickisch and Carl Edward Rasmussen. Approximations for binary G aussian process classification. Journal of Machine Learning Research, 9 0 (Oct): 0 2035--2078, 2008
work page 2035
-
[36]
Constant-time predictive distributions for G aussian processes
Geoff Pleiss, Jacob Gardner, Kilian Weinberger, and Andrew Gordon Wilson. Constant-time predictive distributions for G aussian processes. In International Conference on Machine Learning, pages 4114--4123. PMLR, 2018
work page 2018
-
[37]
A unifying view of sparse approximate G aussian process regression
Joaquin Quinonero-Candela and Carl Edward Rasmussen. A unifying view of sparse approximate G aussian process regression. The Journal of Machine Learning Research, 6: 0 1939--1959, 2005
work page 1939
-
[38]
Filippo Rambelli and Fabio Sigrist. An accuracy-runtime trade-off comparison of scalable G aussian process approximations for spatial data. arXiv preprint arXiv:2501.11448, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [39]
-
[40]
Iterative methods for sparse linear systems
Yousef Saad. Iterative methods for sparse linear systems. SIAM, 2003
work page 2003
-
[41]
A full scale approximation of covariance functions for large spatial data sets
Huiyan Sang and Jianhua Z Huang. A full scale approximation of covariance functions for large spatial data sets. Journal of the Royal Statistical Society Series B: Statistical Methodology, 74 0 (1): 0 111--132, 2012
work page 2012
-
[42]
Huiyan Sang, Mikyoung Jun, and Jianhua Z Huang. Covariance approximation for large multivariate spatial data sets with an application to multiple climate model errors. The Annals of Applied Statistics, pages 2519--2548, 2011
work page 2011
-
[43]
Sparse C holesky factorization by K ullback-- L eibler minimization
Florian Sch\"afer, Matthias Katzfuss, and Houman Owhadi. Sparse C holesky factorization by K ullback-- L eibler minimization. SIAM Journal on Scientific Computing, 43 0 (3): 0 A2019--A2046, 2021 a
work page 2021
-
[44]
Florian Sch\"afer, Timothy John Sullivan, and Houman Owhadi. Compression, inversion, and approximate pca of dense kernel matrices at near-linear computational complexity. Multiscale Modeling & Simulation, 19 0 (2): 0 688--730, 2021 b
work page 2021
-
[45]
Two new lower bounds for the smallest singular value
Xu Shun. Two new lower bounds for the smallest singular value. arXiv preprint arXiv:2108.01221, 2021
-
[46]
Fabio Sigrist. G aussian process boosting. The Journal of Machine Learning Research, 23 0 (1): 0 10565--10610, 2022 a
work page 2022
-
[47]
Latent G aussian model boosting
Fabio Sigrist. Latent G aussian model boosting. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45 0 (2): 0 1894--1905, 2022 b
work page 1905
-
[48]
Integrating random effects in deep neural networks
Giora Simchoni and Saharon Rosset. Integrating random effects in deep neural networks. Journal of Machine Learning Research, 24 0 (156): 0 1--57, 2023
work page 2023
-
[49]
A review of nystr \"o m methods for large-scale machine learning
Shiliang Sun, Jing Zhao, and Jiang Zhu. A review of nystr \"o m methods for large-scale machine learning. Information Fusion, 26: 0 36--48, 2015
work page 2015
-
[50]
Accurate approximations for posterior moments and marginal densities
Luke Tierney and Joseph B Kadane. Accurate approximations for posterior moments and marginal densities . Journal of the American Statistical Association, 81 0 (393): 0 82--86, 1986
work page 1986
-
[51]
Variational learning of inducing variables in sparse G aussian processes
Michalis Titsias. Variational learning of inducing variables in sparse G aussian processes. In Artificial intelligence and statistics, pages 567--574. PMLR, 2009
work page 2009
-
[52]
N umerical linear algebra , volume 181
Lloyd N Trefethen and David Bau. N umerical linear algebra , volume 181. Siam, 2022
work page 2022
-
[53]
Some bounds for the singular values of matrices
Ramazan Turkmen and Haci Civciv. Some bounds for the singular values of matrices. Applied M athematical Sciences , 1 0 (49): 0 2443--2449, 2007
work page 2007
-
[54]
Fast estimation of tr(f(a)) via stochastic lanczos quadrature
Shashanka Ubaru, Jie Chen, and Yousef Saad. Fast estimation of tr(f(a)) via stochastic lanczos quadrature. SIAM Journal on Matrix Analysis and Applications, 38 0 (4): 0 1075--1099, 2017
work page 2017
-
[55]
Estimation and model identification for continuous spatial processes
Aldo V V ecchia. Estimation and model identification for continuous spatial processes. Journal of the Royal Statistical Society Series B: Statistical Methodology, 50 0 (2): 0 297--312, 1988
work page 1988
-
[56]
Kernel interpolation for scalable structured G aussian processes ( KISS - GP )
Andrew Wilson and Hannes Nickisch. Kernel interpolation for scalable structured G aussian processes ( KISS - GP ). In International conference on machine learning, pages 1775--1784. PMLR, 2015
work page 2015
-
[57]
A note on a lower bound for the smallest singular value
Yu Yi-Sheng and Gu Dun-He. A note on a lower bound for the smallest singular value. Linear algebra and its Applications, 253 0 (1-3): 0 25--38, 1997
work page 1997
-
[58]
Bohai Zhang, Huiyan Sang, and Jianhua Z Huang. Smoothed full-scale approximation of G aussian process models for computation of large spatial data sets. Statistica Sinica, 29 0 (4): 0 1711--1737, 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.