DrivingDepth: Sparse-Prompted Pixel-wise Scale Correction for Driving Depth Estimation
Pith reviewed 2026-07-01 06:10 UTC · model grok-4.3
The pith
Foundation models already encode coherent relative depth for driving, so only per-pixel scale correction from sparse LiDAR is needed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
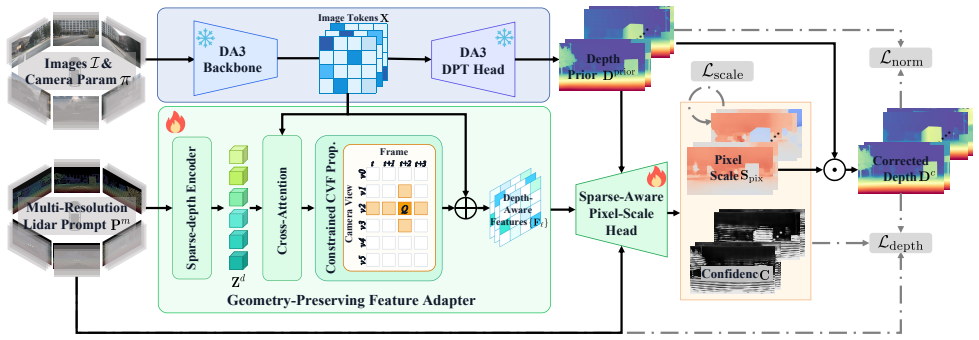
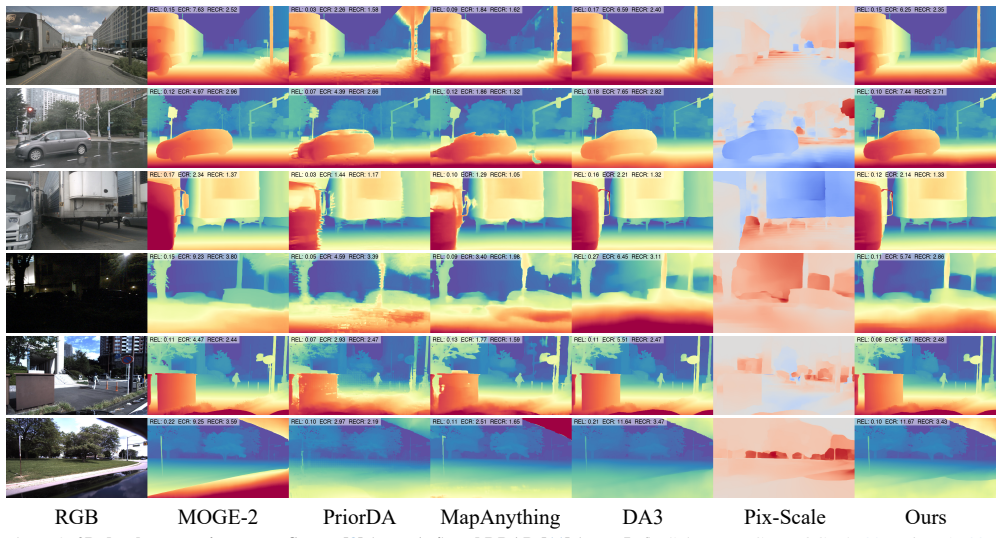
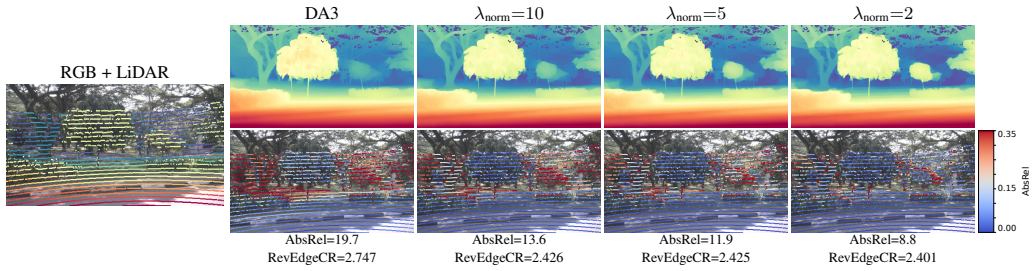
Foundation models already capture geometrically coherent relative depth; no additional surface structure learning is required-only a per-pixel scale factor mapping relative geometry to metric coordinates. DrivingDepth treats sparse LiDAR as geometric prompts that locally calibrate a frozen foundation prior through residual pixel-wise scale correction, preserving dense visual geometry by construction. On nuScenes with 4-frame surround-view input, DrivingDepth achieves an AbsRel of 11.19 and an EdgeCR of 5.741, outperforming MapAnything (11.99/1.914).
What carries the argument
residual pixel-wise scale correction that treats sparse LiDAR as local geometric prompts on a frozen foundation prior
If this is right
- Metric depth is obtained without regenerating surface structure, preserving the foundation model's geometric coherence.
- Sparse LiDAR serves only for local calibration rather than as primary depth source.
- On nuScenes 4-frame surround-view input the method reaches AbsRel 11.19 and EdgeCR 5.741 while beating regeneration baselines.
- Geometric consistency improves because the dense relative depth prior is left intact.
Where Pith is reading between the lines
- The separation of geometry and scale may reduce the amount of dense supervision required for new driving domains.
- Similar residual correction could be tested on other foundation-model outputs where metric scale is the primary gap.
- Hardware requirements might shift toward fewer LiDAR beams if scale calibration proves robust.
Load-bearing premise
Foundation models already deliver pixel-aligned dense visual geometry whose only missing element is a per-pixel metric scale factor.
What would settle it
If the scale-corrected output exhibits structural artifacts on visually continuous surfaces or fails to align with dense ground-truth geometry where available, the claim that only scale is missing would be refuted.
Figures


read the original abstract
Dense depth estimation for autonomous driving faces a geometry-scale conflict: depth foundation models deliver pixel-aligned dense visual geometry without reliable metric scale, while projected LiDAR provides metric anchors that are sparse, noisy, and misaligned with image structures. Existing sparse-prompted methods incorporate LiDAR by regenerating depth from scratch, overriding the foundation model's coherent geometry and producing structural artifacts on visually continuous surfaces. Our key insight is that foundation models already capture geometrically coherent relative depth; no additional surface structure learning is required-only a per-pixel scale factor mapping relative geometry to metric coordinates. Based on this, we propose DrivingDepth, which treats sparse LiDAR as geometric prompts that locally calibrate a frozen foundation prior through residual pixel-wise scale correction, preserving dense visual geometry by construction. On nuScenes with 4-frame surround-view input, DrivingDepth achieves an AbsRel of 11.19 and an EdgeCR of 5.741, outperforming MapAnything (11.99/1.914) by simultaneously delivering SOTA metric accuracy and geometric consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that foundation models already provide pixel-aligned dense relative depth for driving scenes, so metric depth estimation requires only a per-pixel multiplicative scale correction (prompted by sparse LiDAR) rather than regenerating depth structure. DrivingDepth implements this by treating LiDAR points as geometric prompts to locally calibrate a frozen foundation prior via residual scale correction, thereby preserving visual geometry by construction. On nuScenes with 4-frame surround-view input, it reports AbsRel of 11.19 and EdgeCR of 5.741, outperforming MapAnything (11.99/1.914).
Significance. If the central claim holds, the work shows that sparse-prompted scale correction suffices to convert foundation-model relative depth into metric depth without structural artifacts, which could simplify pipelines that currently override foundation priors. The dual reporting of metric error and geometric consistency metrics directly tests the preservation claim.
minor comments (1)
- The abstract states performance numbers but does not indicate whether the scale-correction network is trained end-to-end or with frozen components beyond the foundation model; a one-sentence clarification in §3 or the abstract would help readers assess implementation scope.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. The provided summary correctly captures the core claim that foundation models already deliver pixel-aligned relative depth, so that metric conversion reduces to per-pixel scale correction prompted by sparse LiDAR.
Circularity Check
No significant circularity
full rationale
The paper states its key insight directly as an assumption (foundation models supply coherent relative depth; only per-pixel scale correction is required) and builds the method as a direct implementation of that assumption via residual scale correction prompted by sparse LiDAR. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce the claimed result to its inputs by construction. The evaluation metrics (AbsRel, EdgeCR) address the stated goals without evidence of statistical forcing or definitional equivalence. This is the normal case of a self-contained derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AdaBins: Depth estimation using adaptive bins
Shariq Farooq Bhat, Ibraheem Alhashim, and Peter Wonka. AdaBins: Depth estimation using adaptive bins. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4009–4018, 2021. 2
2021
-
[2]
Depth Pro: Sharp monocular metric depth in less than a second
Alexey Bochkovskiy, Ama ¨el Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan Richter, and Vladlen Koltun. Depth Pro: Sharp monocular metric depth in less than a second. InInternational Conference on Learning Rep- resentations, pages 75602–75637, 2025. 1, 2, 6
2025
-
[3]
Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuScenes: A multi- modal dataset for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11621–11631, 2020. 2, 5, 6, 7, 8, 9
2020
-
[4]
Yuanzhouhan Cao, Zifeng Wu, and Chunhua Shen. Esti- mating depth from monocular images as classification using deep fully convolutional residual networks.IEEE Transac- tions on Circuits and Systems for Video Technology, 28(11): 3174–3182, 2017. 2
2017
-
[5]
TTT3R: 3D Reconstruction as Test-Time Training
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. TTT3R: 3D reconstruction as test-time training. arXiv preprint arXiv:2509.26645, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
DGGT: Feedforward 4D reconstruction of dynamic driving scenes using unposed images
Xiaoxue Chen, Ziyi Xiong, Yuantao Chen, Gen Li, Nan Wang, Hongcheng Luo, Long Chen, Haiyang Sun, Bing Wang, Guang Chen, Hongyang Li, Ya-Qin Zhang, Hangjun Ye, and Hao Zhao. DGGT: Feedforward 4D reconstruction of dynamic driving scenes using unposed images. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages ...
2026
-
[7]
Depth map prediction from a single image using a multi-scale deep net- work.Advances in Neural Information Processing Systems, 27, 2014
David Eigen, Christian Puhrsch, and Rob Fergus. Depth map prediction from a single image using a multi-scale deep net- work.Advances in Neural Information Processing Systems, 27, 2014. 2
2014
-
[8]
Deep ordinal regression net- work for monocular depth estimation
Huan Fu, Mingming Gong, Chaohui Wang, Kayhan Bat- manghelich, and Dacheng Tao. Deep ordinal regression net- work for monocular depth estimation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), pages 2002–2011, 2018. 2
2002
-
[9]
Unsupervised monocular depth estimation with left- right consistency
Cl ´ement Godard, Oisin Mac Aodha, and Gabriel J Bros- tow. Unsupervised monocular depth estimation with left- right consistency. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 270–279, 2017. 2
2017
-
[10]
Digging into self-supervised monocular depth estimation
Cl ´ement Godard, Oisin Mac Aodha, Michael Firman, and Gabriel J Brostow. Digging into self-supervised monocular depth estimation. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), pages 3828– 3838, 2019. 2
2019
-
[11]
3D packing for self-supervised monocular depth estimation
Vitor Guizilini, Rares Ambrus, Sudeep Pillai, Allan Raven- tos, and Adrien Gaidon. 3D packing for self-supervised monocular depth estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2485–2494, 2020. 2, 5, 6, 7, 9
2020
-
[12]
Dist-4D: Disentangled spatiotemporal diffusion with metric depth for 4D driving scene generation
Jiazhe Guo, Yikang Ding, Xiwu Chen, Shuo Chen, Bohan Li, Yingshuang Zou, Xiaoyang Lyu, Feiyang Tan, Xiaojuan Qi, Zhiheng Li, et al. Dist-4D: Disentangled spatiotemporal diffusion with metric depth for 4D driving scene generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 27231–27241, 2025. 2
2025
-
[13]
Zhuolin He, Jing Li, Guanghao Li, Xiaolei Chen, Jiacheng Tang, Siyang Zhang, Zhounan Jin, Feipeng Cai, Bin Li, Jian Pu, et al. DynamicVGGT: Learning dynamic point maps for 4D scene reconstruction in autonomous driving.arXiv preprint arXiv:2603.08254, 2026. 3
-
[14]
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Hao Chen, Kaixuan Wang, Gang Yu, Chunhua Shen, and Shaojie Shen. Metric3D v2: A versatile monocular geomet- ric foundation model for zero-shot metric depth and surface normal estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):10579–10596, 2024. 2
2024
-
[15]
MapAnything: Universal feed- forward metric 3D reconstruction
Nikhil Keetha, Norman M ¨uller, Johannes Sch ¨onberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, Jonathon Luiten, Manuel Lopez-Antequera, Samuel Rota Bul`o, Christian Richardt, Deva Ramanan, Sebastian Scherer, and Peter Kontschieder. MapAnything: Universal feed- forward metric 3D reconstructio...
2026
-
[16]
Jin Han Lee, Myung-Kyu Han, Dong Wook Ko, and Il Hong Suh. From big to small: Multi-scale local planar guidance for monocular depth estimation.arXiv preprint arXiv:1907.10326, 2019. 2
-
[17]
Ground- ing image matching in 3D with MASt3R
Vincent Leroy, Yohann Cabon, and Jerome Revaud. Ground- ing image matching in 3D with MASt3R. InProceedings of the European Conference on Computer Vision (ECCV),
-
[18]
Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation
Haotong Lin, Sida Peng, Jingxiao Chen, Songyou Peng, Ji- aming Sun, Minghuan Liu, Hujun Bao, Jiashi Feng, Xiaowei Zhou, and Bingyi Kang. Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17070–17080, 2025. 2, 4, 6
2025
-
[19]
Chen, Zhenyu Li, Yang Zhao, Sida Peng, Hengkai Guo, Xiaowei Zhou, Guang Shi, Jiashi Feng, and Bingyi Kang
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Yang Zhao, Sida Peng, Hengkai Guo, Xiaowei Zhou, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth Any- thing 3: Recovering the visual space from any views. InThe Fourteenth International Conference on Learning Represen- tations, 2026. 1, 2, 3, 4, 5, 6, 7, 8
2026
-
[20]
VGD: Visual geometry gaussian splat- ting for feed-forward surround-view driving reconstruction
Junhong Lin, Kangli Wang, Shunzhou Wang, Songlin Fan, Ge Li, and Wei Gao. VGD: Visual geometry gaussian splat- ting for feed-forward surround-view driving reconstruction. arXiv preprint arXiv:2510.19578, 2025. 3
-
[21]
Learning depth from single monocular images using deep convolutional neural fields.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 38(10):2024–2039,
Fayao Liu, Chunhua Shen, Guosheng Lin, and Ian Reid. Learning depth from single monocular images using deep convolutional neural fields.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 38(10):2024–2039,
2024
-
[22]
Baorui Ma, Jiahui Yang, Donglin Di, Xuancheng Zhang, Jianxun Cui, Hao Li, Yan Xie, and Wei Chen. Metri- cAnything: Scaling metric depth pretraining with noisy het- erogeneous sources.arXiv preprint arXiv:2601.22054, 2026. 5
-
[23]
UniDepth: Universal monocular metric depth estimation
Luigi Piccinelli, Yung-Hsu Yang, Christos Sakaridis, Mattia Segu, Siyuan Li, Luc Van Gool, and Fisher Yu. UniDepth: Universal monocular metric depth estimation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 2
2024
-
[24]
Vi- sion transformers for dense prediction
Rene Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vi- sion transformers for dense prediction. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 12179–12188, 2021. 2
2021
-
[25]
FastVGGT: Training-Free Acceleration of Visual Geometry Transformer
You Shen, Zhipeng Zhang, Yansong Qu, Xiawu Zheng, Ji- ayi Ji, Shengchuan Zhang, and Liujuan Cao. FastVGGT: Training-free acceleration of visual geometry transformer. arXiv preprint arXiv:2509.02560, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Driv- ingForward: Feed-forward 3D gaussian splatting for driv- ing scene reconstruction from flexible surround-view input
Qijian Tian, Xin Tan, Yuan Xie, and Lizhuang Ma. Driv- ingForward: Feed-forward 3D gaussian splatting for driv- ing scene reconstruction from flexible surround-view input. InProceedings of the AAAI Conference on Artificial Intelli- gence, pages 7374–7382, 2025. 3
2025
-
[27]
VGGT: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. VGGT: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5294–5306, 2025. 2
2025
-
[28]
Efros, and Angjoo Kanazawa
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A. Efros, and Angjoo Kanazawa. Continuous 3D perception model with persistent state. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10510–10522, 2025. 2
2025
-
[29]
MoGe: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. MoGe: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5261–5271, 2025. 3, 5, 6, 7, 8
2025
-
[30]
MoGe-2: Accurate monocular geometry with metric scale and sharp details.Advances in Neural Information Pro- cessing Systems, 38:35928–35959, 2026
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang. MoGe-2: Accurate monocular geometry with metric scale and sharp details.Advances in Neural Information Pro- cessing Systems, 38:35928–35959, 2026. 1, 2, 6, 7
2026
-
[31]
DUSt3R: Geometric 3D vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. DUSt3R: Geometric 3D vision made easy. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 20697–20709, 2024. 2, 5
2024
-
[32]
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chun- hua Shen, and Tong He.π 3: Permutation-equivariant visual geometry learning.arXiv preprint arXiv:2507.13347, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Depth Anything with any prior
Zehan Wang, Siyu Chen, Lihe Yang, Jialei Wang, Ziang Zhang, Hengshuang Zhao, and Zhou Zhao. Depth Anything with any prior. InThe Fourteenth International Conference on Learning Representations, 2026. 2, 6, 7
2026
-
[34]
Surround- Depth: Entangling surrounding views for self-supervised multi-camera depth estimation
Yi Wei, Linqing Zhao, Wenzhao Zheng, Zheng Zhu, Yong- ming Rao, Guan Huang, Jiwen Lu, and Jie Zhou. Surround- Depth: Entangling surrounding views for self-supervised multi-camera depth estimation. InProceedings of The 6th Conference on Robot Learning, pages 539–549. PMLR,
-
[35]
Scal3R: Scalable Test-Time Training for Large-Scale 3D Reconstruction
Tao Xie, Peishan Yang, Yudong Jin, Yingfeng Cai, Wei Yin, Weiqiang Ren, Qian Zhang, Wei Hua, Sida Peng, Xiaoyang Guo, et al. SCAL3R: Scalable test-time training for large- scale 3D reconstruction.arXiv preprint arXiv:2604.08542,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Depth Anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth Anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 1, 2
2024
-
[37]
Depth Any- thing V2
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth Any- thing V2. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 2
2024
-
[38]
InfiniDepth: Arbitrary-resolution and fine- grained depth estimation with neural implicit fields
Hao Yu, Haotong Lin, Jiawei Wang, Jiaxin Li, Yida Wang, Xueyang Zhang, Yue Wang, Xiaowei Zhou, Ruizhen Hu, and Sida Peng. InfiniDepth: Arbitrary-resolution and fine- grained depth estimation with neural implicit fields. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26920–26930, 2026. 2
2026
-
[39]
Zhongrui Yu, Zhao Wang, Yijia Xie, Yida Wang, Xueyang Zhang, Yifei Zhan, and Kun Zhan. StreetForward: Perceiv- ing dynamic street with feedforward causal attention.arXiv preprint arXiv:2603.19552, 2026. 3
-
[40]
NeW CRFs: Neural window fully-connected CRFs for monocular depth estimation
Weihao Yuan, Xiaodong Gu, Zuozhuo Dai, Siyu Zhu, and Ping Tan. NeW CRFs: Neural window fully-connected CRFs for monocular depth estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3916–3925, 2022. 2
2022
-
[41]
CompletionFormer: Depth completion with convolutions and vision transform- ers
Youmin Zhang, Xianda Guo, Matteo Poggi, Zheng Zhu, Guan Huang, and Stefano Mattoccia. CompletionFormer: Depth completion with convolutions and vision transform- ers. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 18527– 18536, 2023. 2
2023
-
[42]
M2Depth: Self-supervised two-frame multi- camera metric depth estimation
Yingshuang Zou, Yikang Ding, Xi Qiu, Haoqian Wang, and Haotian Zhang. M2Depth: Self-supervised two-frame multi- camera metric depth estimation. InComputer Vision – ECCV 2024, pages 269–285, Cham, 2025. Springer Nature Switzer- land. 2
2024
-
[43]
DVGT: Driving visual geometry transformer
Sicheng Zuo, Zixun Xie, Wenzhao Zheng, Shaoqing Xu, Fang Li, Shengyin Jiang, Long Chen, Zhi-Xin Yang, and Ji- wen Lu. DVGT: Driving visual geometry transformer. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 14658–14668,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.