Recognition: no theorem link
Scal3R: Scalable Test-Time Training for Large-Scale 3D Reconstruction
Pith reviewed 2026-05-10 16:51 UTC · model grok-4.3
The pith
Lightweight neural sub-networks adapted at test time compress global scene context to keep large-scale 3D reconstructions accurate and consistent over long video sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A neural global context representation realized through lightweight neural sub-networks that are rapidly adapted during test time via self-supervised objectives compresses and retains long-range scene information, allowing the model to leverage extensive contextual cues for enhanced reconstruction accuracy and consistency on large-scale scenes from long video sequences.
What carries the argument
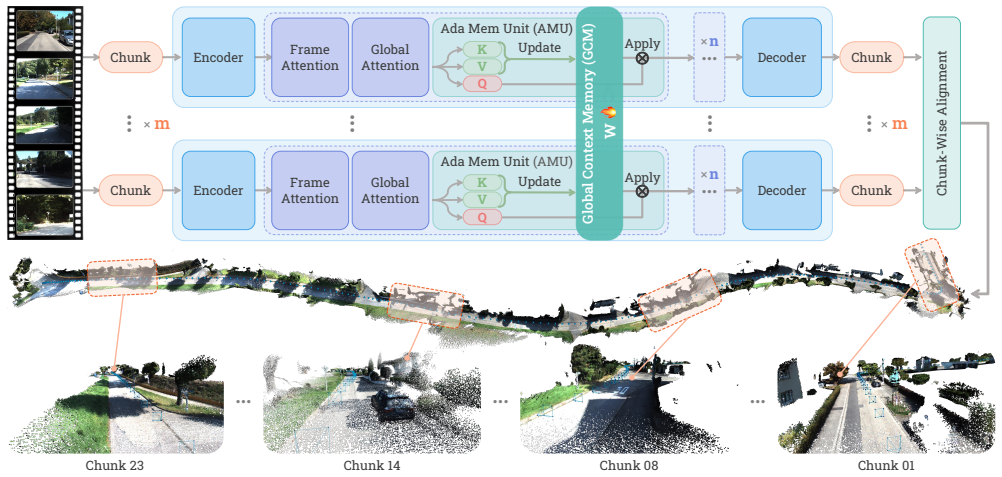
A set of lightweight neural sub-networks that adapt at test time to form a compressible neural global context representation.
If this is right
- The same adapted context can be reused across subsequent frames to enforce global consistency without re-processing the entire history.
- Pose estimation accuracy improves because local camera motion is informed by the retained global cues.
- Overall memory usage stays low while effective context capacity grows, enabling ultra-large scenes without proportional compute increase.
- The method remains compatible with existing feed-forward reconstruction backbones and requires no change to the core geometry regression network.
Where Pith is reading between the lines
- The same test-time adaptation pattern could be applied to other sequential perception tasks such as video depth estimation or object tracking where long-range consistency matters.
- If the sub-networks prove stable across domains, the approach might reduce reliance on hand-crafted geometric regularizers in future reconstruction pipelines.
- A natural next test would be to measure whether the adapted context transfers usefully to new scenes with similar structure but different lighting or camera motion.
Load-bearing premise
Rapid self-supervised adaptation of the sub-networks can reliably extract and preserve accurate long-range contextual information without introducing new inconsistencies or drift.
What would settle it
Measure whether reconstruction error on a long sequence with known ground-truth geometry grows linearly with sequence length or remains bounded when the test-time adaptation is removed versus when it is enabled.
Figures




read the original abstract
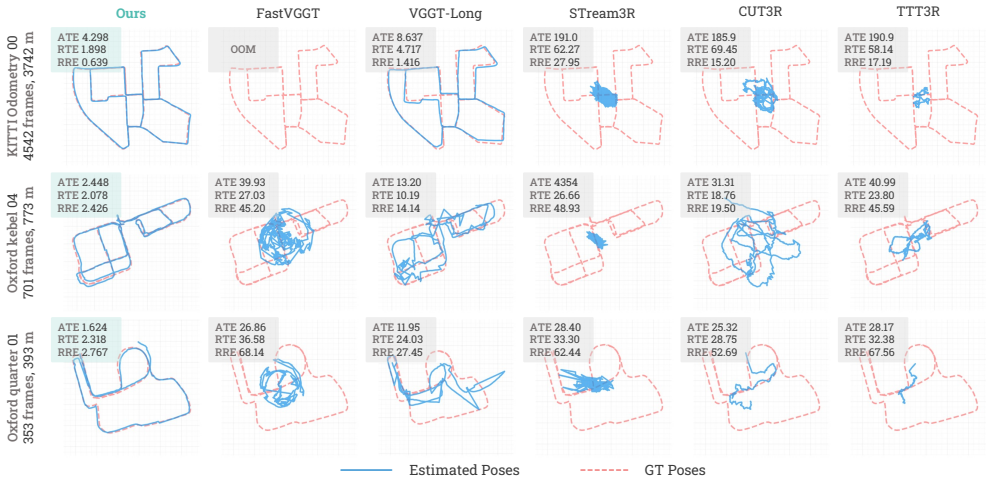
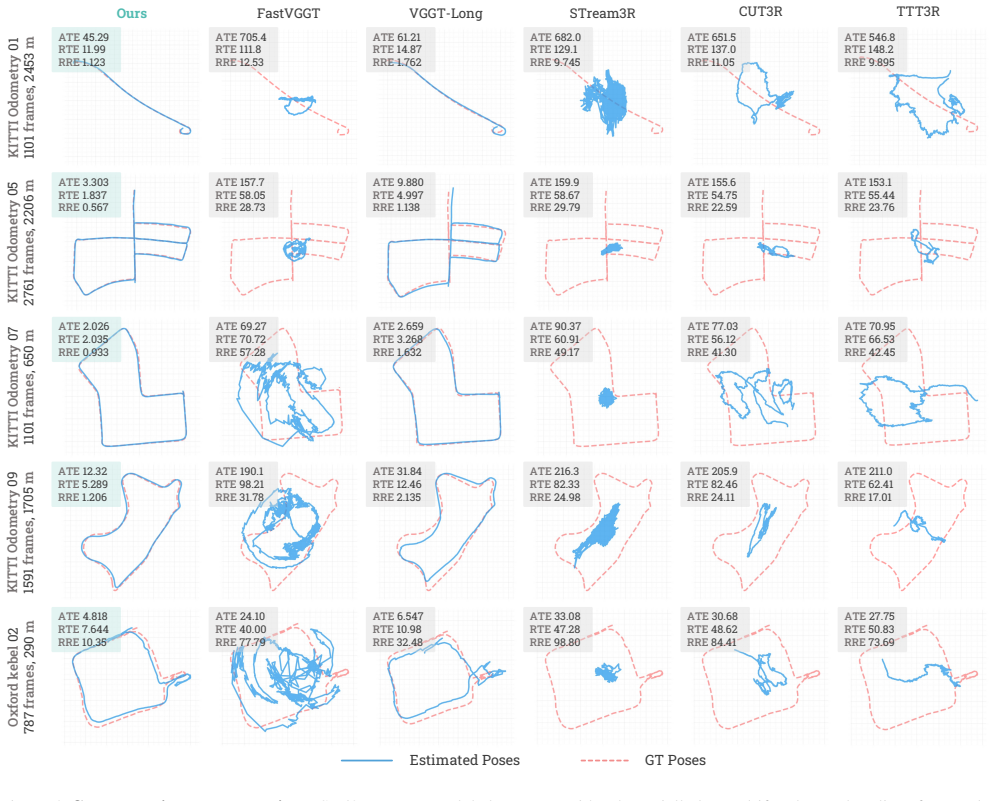
This paper addresses the task of large-scale 3D scene reconstruction from long video sequences. Recent feed-forward reconstruction models have shown promising results by directly regressing 3D geometry from RGB images without explicit 3D priors or geometric constraints. However, these methods often struggle to maintain reconstruction accuracy and consistency over long sequences due to limited memory capacity and the inability to effectively capture global contextual cues. In contrast, humans can naturally exploit the global understanding of the scene to inform local perception. Motivated by this, we propose a novel neural global context representation that efficiently compresses and retains long-range scene information, enabling the model to leverage extensive contextual cues for enhanced reconstruction accuracy and consistency. The context representation is realized through a set of lightweight neural sub-networks that are rapidly adapted during test time via self-supervised objectives, which substantially increases memory capacity without incurring significant computational overhead. The experiments on multiple large-scale benchmarks, including the KITTI Odometry~\cite{Geiger2012CVPR} and Oxford Spires~\cite{tao2025spires} datasets, demonstrate the effectiveness of our approach in handling ultra-large scenes, achieving leading pose accuracy and state-of-the-art 3D reconstruction accuracy while maintaining efficiency. Code is available at https://zju3dv.github.io/scal3r.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Scal3R for large-scale 3D scene reconstruction from long video sequences. It proposes a neural global context representation implemented via lightweight neural sub-networks that undergo rapid test-time adaptation using self-supervised objectives. This is claimed to overcome memory and global cue limitations in prior feed-forward models, enabling leading pose accuracy and state-of-the-art 3D reconstruction accuracy on ultra-large scenes from benchmarks such as KITTI Odometry and Oxford Spires, while maintaining efficiency. Code is released.
Significance. If the central claims hold, the work would represent a meaningful advance in scalable 3D reconstruction by demonstrating that test-time adaptation of compact sub-networks can effectively compress and retain long-range contextual information for consistent performance on extended sequences. This could influence downstream applications in robotics, autonomous driving, and large-scale mapping. The public code release supports reproducibility and follow-up work.
major comments (2)
- [§3.2] §3.2 (Method, self-supervised objectives): The loss formulation relies on photometric and local consistency terms but lacks explicit geometric regularization (e.g., multi-view reprojection or drift penalization across the full sequence). This is load-bearing for the claim that adaptation reliably retains long-range global cues without accumulating inconsistencies on datasets like KITTI Odometry.
- [§4.2] §4.2 (Experiments, ablation on context representation): The reported ablations compare full Scal3R against variants but do not isolate whether performance gains stem from global context retention versus simple local adaptation; without this, the attribution of SOTA reconstruction accuracy to the proposed neural global context remains under-supported.
minor comments (2)
- [Abstract] The citation for Oxford Spires appears as tao2025spires; confirm the reference is correctly formatted and accessible.
- [Figure 3] Figure 3 (qualitative results): The scale of the visualized scenes makes it difficult to assess fine-grained consistency; consider adding zoomed insets or error heatmaps.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address the major comments point-by-point below, clarifying our design choices and outlining targeted revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Method, self-supervised objectives): The loss formulation relies on photometric and local consistency terms but lacks explicit geometric regularization (e.g., multi-view reprojection or drift penalization across the full sequence). This is load-bearing for the claim that adaptation reliably retains long-range global cues without accumulating inconsistencies on datasets like KITTI Odometry.
Authors: We appreciate the referee's point on the loss design. Our self-supervised objectives combine photometric consistency with local geometric terms, but the key mechanism for long-range retention is the test-time adaptation of the shared lightweight neural sub-networks across the full sequence. This shared parameterization implicitly couples local observations to global cues, reducing drift without an explicit full-sequence reprojection term. Results on KITTI Odometry demonstrate low accumulated error relative to baselines, supporting that the global context prevents inconsistencies. To address the concern directly, we will expand §3.2 with a paragraph explaining this implicit regularization effect and add qualitative visualizations of consistency over extended sequences in the revised manuscript. revision: partial
-
Referee: [§4.2] §4.2 (Experiments, ablation on context representation): The reported ablations compare full Scal3R against variants but do not isolate whether performance gains stem from global context retention versus simple local adaptation; without this, the attribution of SOTA reconstruction accuracy to the proposed neural global context remains under-supported.
Authors: We agree that the ablation analysis can be strengthened to more clearly isolate the global context contribution. The current comparisons include a local-adaptation-only variant (removing the neural global context sub-networks), which shows clear degradation, but we will revise §4.2 to include an additional controlled ablation: one where the global context is adapted only on the first segment and then frozen for the remainder of the sequence. This will directly quantify the benefit of ongoing global retention versus purely local adaptation. We will update the text, tables, and discussion accordingly in the revision. revision: yes
Circularity Check
No significant circularity; method is empirically grounded without reductive derivations
full rationale
The paper introduces a test-time adaptation technique for large-scale 3D reconstruction using lightweight neural sub-networks and self-supervised objectives, validated on external benchmarks such as KITTI Odometry. No equations, first-principles derivations, or predictions are presented that reduce claimed accuracy improvements to quantities defined by fitted parameters or self-citations. The central premise relies on the proposed context representation and adaptation process, which is described independently of the experimental outcomes. A citation to the Oxford Spires dataset exists but serves only as an evaluation benchmark and is not load-bearing for any derivation chain. The approach remains self-contained against external data without circular reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-supervised objectives on video sequences can effectively adapt the context representation to capture long-range cues
invented entities (1)
-
neural global context representation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Building rome in a day.Communications of the ACM, 54 (10):105–112, 2011
Sameer Agarwal, Yasutaka Furukawa, Noah Snavely, Ian Simon, Brian Curless, Steven M Seitz, and Richard Szeliski. Building rome in a day.Communications of the ACM, 54 (10):105–112, 2011. 2
2011
-
[2]
Mapillary planet-scale depth dataset
Manuel L´opez Antequera, Pau Gargallo, Markus Hofinger, Samuel Rota Bulo, Yubin Kuang, and Peter Kontschieder. Mapillary planet-scale depth dataset. InEuropean Confer- ence on Computer Vision, pages 589–604. Springer, 2020. 6
2020
-
[3]
Map-free visual relocalization: Metric pose relative to a single image
Eduardo Arnold, Jamie Wynn, Sara Vicente, Guillermo Garcia-Hernando, ´Aron Monszpart, Victor Adrian Prisacariu, Daniyar Turmukhambetov, and Eric Brachmann. Map-free visual relocalization: Metric pose relative to a single image. InECCV, 2022. 6
2022
-
[4]
Titans: Learning to Memorize at Test Time
Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. Ti- tans: Learning to memorize at test time.arXiv preprint arXiv:2501.00663, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[5]
arXiv preprint arXiv:2504.13173 , year =
Ali Behrouz, Meisam Razaviyayn, Peilin Zhong, and Vahab Mirrokni. It’s all connected: A journey through test-time memorization, attentional bias, retention, and online opti- mization.arXiv preprint arXiv:2504.13173, 2025. 5
-
[6]
Token merging for fast stable diffusion
Daniel Bolya and Judy Hoffman. Token merging for fast stable diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4599– 4603, 2023. 2
2023
-
[7]
Yohann Cabon, Naila Murray, and Martin Humenberger. Virtual kitti 2.arXiv preprint arXiv:2001.10773, 2020. 2, 6, 7, 8, 1, 3
work page internal anchor Pith review arXiv 2001
-
[8]
Must3r: Multi-view network for stereo 3d reconstruc- tion
Yohann Cabon, Lucas Stoffl, Leonid Antsfeld, Gabriela Csurka, Boris Chidlovskii, Jerome Revaud, and Vincent Leroy. Must3r: Multi-view network for stereo 3d reconstruc- tion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1050–1060, 2025. 2, 3
2025
-
[9]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. In Proceedings of the International Conference on Computer Vision (ICCV), 2021. 3, 5
2021
-
[10]
Learning to match features with seeded graph matching network
Hongkai Chen, Zixin Luo, Jiahui Zhang, Lei Zhou, Xuyang Bai, Zeyu Hu, Chiew-Lan Tai, and Long Quan. Learning to match features with seeded graph matching network. In Proceedings of the IEEE/CVF international conference on computer vision, pages 6301–6310, 2021. 2
2021
-
[11]
Ttt3r: 3d reconstruction as test-time training
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. Ttt3r: 3d reconstruction as test-time training. arXiv preprint arXiv:2509.26645, 2025. 3, 6, 7, 2, 4
-
[12]
Global structure-from-motion by similarity averaging
Zhaopeng Cui and Ping Tan. Global structure-from-motion by similarity averaging. InProceedings of the IEEE interna- tional conference on computer vision, pages 864–872, 2015. 2
2015
-
[13]
Large-scale lidar slam with factor graph optimization on high-level geometric features.Sen- sors, 21(10):3445, 2021
Krzysztof ´Cwian, Michał R Nowicki, Jan Wietrzykowski, and Piotr Skrzypczy´nski. Large-scale lidar slam with factor graph optimization on high-level geometric features.Sen- sors, 21(10):3445, 2021. 2, 3
2021
-
[14]
One-minute video generation with test-time training
Karan Dalal, Daniel Koceja, Jiarui Xu, Yue Zhao, Shihao Han, Ka Chun Cheung, Jan Kautz, Yejin Choi, Yu Sun, and Xiaolong Wang. One-minute video generation with test-time training. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17702–17711, 2025. 3, 4
2025
-
[15]
Tri Dao and Albert Gu. Transformers are ssms: General- ized models and efficient algorithms through structured state space duality.arXiv preprint arXiv:2405.21060, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[16]
Junyuan Deng, Heng Li, Tao Xie, Weiqiang Ren, Qian Zhang, Ping Tan, and Xiaoyang Guo. Sail-recon: Large sfm by augmenting scene regression with localization.arXiv preprint arXiv:2508.17972, 2025. 3
-
[17]
Kai Deng, Zexin Ti, Jiawei Xu, Jian Yang, and Jin Xie. Vggt-long: Chunk it, loop it, align it–pushing vggt’s lim- its on kilometer-scale long rgb sequences.arXiv preprint arXiv:2507.16443, 2025. 2, 4, 6, 7, 1, 3
-
[18]
Kai Deng, Yigong Zhang, Jian Yang, and Jin Xie. Gi- gaslam: Large-scale monocular slam with hierarchical gaus- sian splats.arXiv preprint arXiv:2503.08071, 2025. 2
-
[19]
Superpoint: Self-supervised interest point detection and description
Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabi- novich. Superpoint: Self-supervised interest point detection and description. InProceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 224–236, 2018. 2
2018
-
[20]
D2-net: A trainable cnn for joint description and detection of lo- cal features
Mihai Dusmanu, Ignacio Rocco, Tomas Pajdla, Marc Polle- feys, Josef Sivic, Akihiko Torii, and Torsten Sattler. D2-net: A trainable cnn for joint description and detection of lo- cal features. InProceedings of the ieee/cvf conference on computer vision and pattern recognition, pages 8092–8101,
-
[21]
Ldso: Direct sparse odometry with loop closure
Xiang Gao, Rui Wang, Nikolaus Demmel, and Daniel Cre- mers. Ldso: Direct sparse odometry with loop closure. In2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2198–2204. IEEE, 2018. 2, 3
2018
-
[22]
Are we ready for autonomous driving? the kitti vision benchmark suite
Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. InConference on Computer Vision and Pattern Recog- nition (CVPR), 2012. 1, 2, 6, 7, 3
2012
-
[23]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. InFirst conference on language modeling, 2024. 3
2024
-
[24]
Xiaodong Gu, Weihao Yuan, Zuozhuo Dai, Chengzhou Tang, Siyu Zhu, and Ping Tan. Dro: Deep recurrent optimizer for structure-from-motion.arXiv preprint arXiv:2103.13201, 2 (3):7, 2021. 3
-
[25]
Detector-free struc- ture from motion.CVPR, 2024
Xingyi He, Jiaming Sun, Yifan Wang, Sida Peng, Qixing Huang, Hujun Bao, and Xiaowei Zhou. Detector-free struc- ture from motion.CVPR, 2024. 2
2024
-
[26]
Benchmark- ing visual slam methods in mirror environments.Computa- tional Visual Media, 10(2):215–241, 2024
Peter Herbert, Jing Wu, Ze Ji, and Yu-Kun Lai. Benchmark- ing visual slam methods in mirror environments.Computa- tional Visual Media, 10(2):215–241, 2024. 3
2024
-
[27]
Long short-term memory.Neural computation, 9(8):1735–1780, 1997
Sepp Hochreiter and J¨urgen Schmidhuber. Long short-term memory.Neural computation, 9(8):1735–1780, 1997. 3
1997
-
[28]
Deepmvs: Learning multi-view stereopsis
Po-Han Huang, Kevin Matzen, Johannes Kopf, Narendra Ahuja, and Jia-Bin Huang. Deepmvs: Learning multi-view stereopsis. InProceedings of the IEEE conference on com- puter vision and pattern recognition, pages 2821–2830,
-
[29]
Greedy- based feature selection for efficient lidar slam
Jianhao Jiao, Yilong Zhu, Haoyang Ye, Huaiyang Huang, Peng Yun, Linxin Jiang, Lujia Wang, and Ming Liu. Greedy- based feature selection for efficient lidar slam. In2021 IEEE international conference on robotics and automation (ICRA), pages 5222–5228. IEEE, 2021. 3
2021
-
[30]
Lattice: Learn- ing to efficiently compress the memory.arXiv preprint arXiv:2504.05646, 2025
Mahdi Karami and Vahab Mirrokni. Lattice: Learn- ing to efficiently compress the memory.arXiv preprint arXiv:2504.05646, 2025. 5
-
[31]
Transformers are rnns: Fast autore- gressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and Franc ¸ois Fleuret. Transformers are rnns: Fast autore- gressive transformers with linear attention. InInternational conference on machine learning, pages 5156–5165. PMLR,
-
[32]
Tanks and temples: Benchmarking large-scale scene reconstruction.ACM Transactions on Graphics (ToG), 36 (4):1–13, 2017
Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and temples: Benchmarking large-scale scene reconstruction.ACM Transactions on Graphics (ToG), 36 (4):1–13, 2017. 2
2017
-
[33]
Yushi Lan, Yihang Luo, Fangzhou Hong, Shangchen Zhou, Honghua Chen, Zhaoyang Lyu, Shuai Yang, Bo Dai, Chen Change Loy, and Xingang Pan. Stream3r: Scalable sequential 3d reconstruction with causal transformer.arXiv preprint arXiv:2508.10893, 2025. 3, 6, 7, 1, 2, 4
-
[34]
Ground- ing image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and J´erˆome Revaud. Ground- ing image matching in 3d with mast3r. InEuropean Confer- ence on Computer Vision, pages 71–91. Springer, 2024. 2, 6, 7, 4
2024
-
[35]
Matrixcity: A large-scale city dataset for city-scale neural rendering and beyond
Yixuan Li, Lihan Jiang, Linning Xu, Yuanbo Xiangli, Zhen- zhi Wang, Dahua Lin, and Bo Dai. Matrixcity: A large-scale city dataset for city-scale neural rendering and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3205–3215, 2023. 6
2023
-
[36]
Megadepth: Learning single- view depth prediction from internet photos
Zhengqi Li and Noah Snavely. Megadepth: Learning single- view depth prediction from internet photos. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2041–2050, 2018. 6
2041
-
[37]
Longsplat: Robust unposed 3d gaussian splatting for casual long videos
Chin-Yang Lin, Cheng Sun, Fu-En Yang, Min-Hung Chen, Yen-Yu Lin, and Yu-Lun Liu. Longsplat: Robust unposed 3d gaussian splatting for casual long videos. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 27412–27422, 2025. 3
2025
-
[38]
Lightglue: Local feature matching at light speed
Philipp Lindenberger, Paul-Edouard Sarlin, and Marc Polle- feys. Lightglue: Local feature matching at light speed. In Proceedings of the IEEE/CVF international conference on computer vision, pages 17627–17638, 2023. 2
2023
-
[39]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22160–22169, 2024. 6
2024
-
[40]
Deep patch visual slam
Lahav Lipson, Zachary Teed, and Jia Deng. Deep patch visual slam. InEuropean Conference on Computer Vision, pages 424–440. Springer, 2024. 3, 6, 7, 4
2024
-
[41]
arXiv preprint arXiv:2505.12549 (2025)
Dominic Maggio, Hyungtae Lim, and Luca Carlone. Vggt- slam: Dense rgb slam optimized on the sl (4) manifold. arXiv preprint arXiv:2505.12549, 2025. 6, 7, 2, 4
-
[42]
John McCormac, Ankur Handa, Stefan Leutenegger, and Andrew J Davison. Scenenet rgb-d: 5m photorealistic im- ages of synthetic indoor trajectories with ground truth.arXiv preprint arXiv:1612.05079, 2016. 6
-
[43]
Orb-slam: A versatile and accurate monocular slam system.IEEE transactions on robotics, 31(5):1147–1163,
Raul Mur-Artal, Jose Maria Martinez Montiel, and Juan D Tardos. Orb-slam: A versatile and accurate monocular slam system.IEEE transactions on robotics, 31(5):1147–1163,
-
[44]
Mast3r-slam: Real-time dense slam with 3d reconstruction priors
Riku Murai, Eric Dexheimer, and Andrew J Davison. Mast3r-slam: Real-time dense slam with 3d reconstruction priors. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16695–16705, 2025. 3, 6, 7, 2, 4
2025
-
[45]
Global structure-from-motion revisited
Linfei Pan, D´aniel Bar´ath, Marc Pollefeys, and Johannes L Sch¨onberger. Global structure-from-motion revisited. In European Conference on Computer Vision, pages 58–77. Springer, 2024. 2
2024
-
[46]
Aria digital twin: A new benchmark dataset for egocentric 3d machine perception
Xiaqing Pan, Nicholas Charron, Yongqian Yang, Scott Pe- ters, Thomas Whelan, Chen Kong, Omkar Parkhi, Richard Newcombe, and Yuheng Carl Ren. Aria digital twin: A new benchmark dataset for egocentric 3d machine perception. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 20133–20143, 2023. 6, 3
2023
-
[47]
Diffposenet: Direct differentiable camera pose estimation
Chethan M Parameshwara, Gokul Hari, Cornelia Ferm¨uller, Nitin J Sanket, and Yiannis Aloimonos. Diffposenet: Direct differentiable camera pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6845–6854, 2022. 3
2022
-
[48]
Pytorch: An im- perative style, high-performance deep learning library, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas K¨opf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An im- perative style, high-perfo...
2019
-
[49]
RWKV: Reinventing RNNs for the Transformer Era
Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Stella Biderman, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grella, et al. Rwkv: Reinventing rnns for the transformer era.arXiv preprint arXiv:2305.13048, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[50]
Gaussian-plus-sdf slam: High-fidelity 3d reconstruction at 150+ fps.Computa- tional Visual Media, 2025
Zhexi Peng, Kun Zhou, and Tianjia Shao. Gaussian-plus-sdf slam: High-fidelity 3d reconstruction at 150+ fps.Computa- tional Visual Media, 2025. 3
2025
-
[51]
Relocalization, global optimization and map merging for monocular visual- inertial slam
Tong Qin, Peiliang Li, and Shaojie Shen. Relocalization, global optimization and map merging for monocular visual- inertial slam. In2018 IEEE International Conference on Robotics and Automation (ICRA), pages 1197–1204. IEEE,
-
[52]
Vins-mono: A robust and versatile monocular visual-inertial state estimator
Tong Qin, Peiliang Li, and Shaojie Shen. Vins-mono: A robust and versatile monocular visual-inertial state estimator. IEEE transactions on robotics, 34(4):1004–1020, 2018. 2, 3
2018
-
[53]
Self-taught learning: transfer learn- ing from unlabeled data
Rajat Raina, Alexis Battle, Honglak Lee, Benjamin Packer, and Andrew Y Ng. Self-taught learning: transfer learn- ing from unlabeled data. InProceedings of the 24th inter- national conference on Machine learning, pages 759–766,
-
[54]
Vi- sion transformers for dense prediction
Ren´e Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vi- sion transformers for dense prediction. InProceedings of the IEEE/CVF international conference on computer vision, pages 12179–12188, 2021. 1
2021
-
[55]
Com- mon objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction
Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotny. Com- mon objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. InProceedings of the IEEE/CVF international conference on computer vision, pages 10901–10911, 2021. 6, 3
2021
-
[56]
Hypersim: A photorealistic syn- thetic dataset for holistic indoor scene understanding
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M Susskind. Hypersim: A photorealistic syn- thetic dataset for holistic indoor scene understanding. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10912–10922, 2021. 6
2021
-
[57]
Linear transformers are secretly fast weight programmers
Imanol Schlag, Kazuki Irie, and J¨urgen Schmidhuber. Linear transformers are secretly fast weight programmers. InInter- national conference on machine learning, pages 9355–9366. PMLR, 2021. 3
2021
-
[58]
Learning to control fast-weight mem- ories: An alternative to dynamic recurrent networks.Neural Computation, 4(1):131–139, 1992
J¨urgen Schmidhuber. Learning to control fast-weight mem- ories: An alternative to dynamic recurrent networks.Neural Computation, 4(1):131–139, 1992. 3
1992
-
[59]
Structure- from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure- from-motion revisited. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 4104–4113, 2016. 2, 6, 7, 4
2016
-
[60]
BAD SLAM: Bundle adjusted direct RGB-D SLAM
Thomas Sch¨ops, Torsten Sattler, and Marc Pollefeys. BAD SLAM: Bundle adjusted direct RGB-D SLAM. InConfer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[61]
You Shen, Zhipeng Zhang, Yansong Qu, and Liujuan Cao. Fastvggt: Training-free acceleration of visual geometry transformer.arXiv preprint arXiv:2509.02560, 2025. 2, 6, 7, 4
-
[62]
Photo tourism: exploring photo collections in 3d
Noah Snavely, Steven M Seitz, and Richard Szeliski. Photo tourism: exploring photo collections in 3d. InACM siggraph 2006 papers, pages 835–846. 2006. 2
2006
-
[63]
The Replica Dataset: A Digital Replica of Indoor Spaces
Julian Straub, Thomas Whelan, Lingni Ma, Yufan Chen, Erik Wijmans, Simon Green, Jakob J Engel, Raul Mur-Artal, Carl Ren, Shobhit Verma, et al. The replica dataset: A digital replica of indoor spaces.arXiv preprint arXiv:1906.05797,
work page internal anchor Pith review arXiv 1906
-
[64]
A benchmark for the evalua- tion of rgb-d slam systems
J¨urgen Sturm, Nikolas Engelhard, Felix Endres, Wolfram Burgard, and Daniel Cremers. A benchmark for the evalua- tion of rgb-d slam systems. In2012 IEEE/RSJ international conference on intelligent robots and systems, pages 573–580. IEEE, 2012. 7, 3
2012
-
[65]
LoFTR: Detector-free local feature matching with transformers.CVPR, 2021
Jiaming Sun, Zehong Shen, Yuang Wang, Hujun Bao, and Xiaowei Zhou. LoFTR: Detector-free local feature matching with transformers.CVPR, 2021. 2
2021
-
[66]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, 2020. 7, 3
2020
-
[67]
Learning to (Learn at Test Time): RNNs with Expressive Hidden States
Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sanmi Koyejo, et al. Learning to (learn at test time): Rnns with expressive hidden states.arXiv preprint arXiv:2407.04620, 2024. 3, 4, 5
work page internal anchor Pith review arXiv 2024
-
[68]
Ba-net: Dense bundle ad- justment network.arXiv preprint arXiv:1806.04807, 2018
Chengzhou Tang and Ping Tan. Ba-net: Dense bundle ad- justment network.arXiv preprint arXiv:1806.04807, 2018. 3
-
[69]
Mv-dust3r+: Single-stage scene reconstruction from sparse views in 2 seconds
Zhenggang Tang, Yuchen Fan, Dilin Wang, Hongyu Xu, Rakesh Ranjan, Alexander Schwing, and Zhicheng Yan. Mv-dust3r+: Single-stage scene reconstruction from sparse views in 2 seconds.arXiv preprint arXiv:2412.06974, 2024. 3
-
[70]
The oxford spires dataset: Benchmarking large-scale lidar-visual localisation, reconstruction and radiance field methods.In- ternational Journal of Robotics Research, 2025
Yifu Tao, Miguel ´Angel Mu˜noz-Ba˜n´on, Lintong Zhang, Jia- hao Wang, Lanke Frank Tarimo Fu, and Maurice Fallon. The oxford spires dataset: Benchmarking large-scale lidar-visual localisation, reconstruction and radiance field methods.In- ternational Journal of Robotics Research, 2025. 1, 2, 6, 7, 8, 3
2025
-
[71]
Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.Advances in neural information processing systems, 34:16558–16569,
Zachary Teed and Jia Deng. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.Advances in neural information processing systems, 34:16558–16569,
-
[72]
Deep patch vi- sual odometry.Advances in Neural Information Processing Systems, 36:39033–39051, 2023
Zachary Teed, Lahav Lipson, and Jia Deng. Deep patch vi- sual odometry.Advances in Neural Information Processing Systems, 36:39033–39051, 2023. 3
2023
-
[73]
Disk: Learning local features with policy gradient.Advances in neural information processing systems, 33:14254–14265,
Michał Tyszkiewicz, Pascal Fua, and Eduard Trulls. Disk: Learning local features with policy gradient.Advances in neural information processing systems, 33:14254–14265,
-
[74]
Least-squares estimation of transforma- tion parameters between two point patterns.IEEE Transac- tions on pattern analysis and machine intelligence, 13(4): 376–380, 2002
Shinji Umeyama. Least-squares estimation of transforma- tion parameters between two point patterns.IEEE Transac- tions on pattern analysis and machine intelligence, 13(4): 376–380, 2002. 8, 1
2002
-
[75]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 2, 4, 5
2017
-
[76]
3d reconstruction with spatial memory.arXiv preprint arXiv:2408.16061, 2024
Hengyi Wang and Lourdes Agapito. 3d reconstruction with spatial memory.arXiv preprint arXiv:2408.16061, 2024. 3
-
[77]
Vggsfm: Visual geometry grounded deep structure from motion
Jianyuan Wang, Nikita Karaev, Christian Rupprecht, and David Novotny. Vggsfm: Visual geometry grounded deep structure from motion. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 21686–21697, 2024. 3
2024
-
[78]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025. 2, 3, 4, 5, 6, 1
2025
-
[79]
arXiv preprint arXiv:2501.12352 , year=
Ke Alexander Wang, Jiaxin Shi, and Emily B Fox. Test- time regression: a unifying framework for designing se- quence models with associative memory.arXiv preprint arXiv:2501.12352, 2025. 2, 4, 5
-
[80]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10510–10522, 2025. 2, 3, 6, 7, 4
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.