MLFriend: Interactive Prediction Task Recommendation for Event-Driven Time-Series Data
Pith reviewed 2026-05-25 13:31 UTC · model grok-4.3
The pith
MLFriend generates all possible prediction tasks in a fixed space for event-driven time-series data and recommends the useful ones after interactive context learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
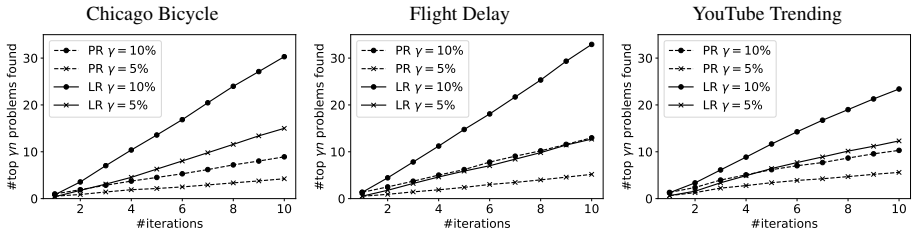
MLFriend first generates all possible prediction tasks under a predefined space, then interacts with a data scientist to learn the context of the data and recommend good prediction tasks from all the tasks in the space. Evaluation on three datasets generated 2885 tasks total, of which 722 were deemed useful by expert data scientists, and showed that the system identifies the top 10 tasks a user may like within any batch of 100 tasks.
What carries the argument
The interactive recommendation step that ranks exhaustively generated tasks after learning data context from the user session.
If this is right
- Experts can review hundreds of candidate tasks per dataset instead of inventing them from scratch.
- Useful tasks surface early enough that only a small batch needs inspection.
- The same generation-plus-ranking loop applies whenever a fixed task space can be written down for the data type.
- Automation of task definition becomes measurable by counting how many generated tasks experts accept.
Where Pith is reading between the lines
- If the interaction reliably captures context, repeated sessions on similar data could reuse prior rankings without new queries.
- The approach could extend to streaming settings where new events continuously expand the candidate task list.
- A multi-user version might aggregate context across several data scientists to produce consensus rankings.
Load-bearing premise
The predefined space already contains the tasks domain experts actually want and the short interaction supplies enough context to rank them correctly.
What would settle it
On a fresh dataset the top ten tasks returned by the system receive no useful ratings from the expert while lower-ranked tasks do.
Figures




read the original abstract
Most automation in machine learning focuses on model selection and hyper parameter tuning, and many overlook the challenge of automatically defining predictive tasks. We still heavily rely on human experts to define prediction tasks, and generate labels by aggregating raw data. In this paper, we tackle the challenge of defining useful prediction problems on event-driven time-series data. We introduce MLFriend to address this challenge. MLFriend first generates all possible prediction tasks under a predefined space, then interacts with a data scientist to learn the context of the data and recommend good prediction tasks from all the tasks in the space. We evaluate our system on three different datasets and generate a total of 2885 prediction tasks and solve them. Out of these 722 were deemed useful by expert data scientists. We also show that an automatic prediction task discovery system is able to identify top 10 tasks that a user may like within a batch of 100 tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MLFriend, a system that generates all possible prediction tasks for event-driven time-series data under a predefined space, interacts with a data scientist to learn data context, and recommends useful tasks. On three datasets it generates 2885 tasks and solves them, with 722 labeled useful by expert data scientists; it further claims an automatic system can identify the top 10 tasks a user may like within any batch of 100.
Significance. If the central claims hold, the work addresses a genuine gap in ML automation by moving beyond model selection to task definition. The concrete counts (2885 tasks generated, 722 judged useful) supply empirical grounding that is rare in this area, and the interactive recommendation framing is a plausible direction. However, the absence of a defined task space, interaction protocol, or evaluation baseline makes it impossible to assess whether the reported usefulness or top-10 performance reflects genuine context capture rather than surface heuristics.
major comments (3)
- [Abstract] Abstract: the claim that the system 'generates all possible prediction tasks under a predefined space' is load-bearing for both the 2885-task count and the usefulness judgment, yet the manuscript supplies no definition of that space (allowed operators, prediction horizons, aggregations, or feature constructions). Without this, it is impossible to verify whether the space is broad enough to contain tasks domain experts actually want.
- [Abstract] Abstract: the top-10-in-100 claim requires an evaluation protocol (user-study design, preference metric, baseline comparator, and how user feedback is modeled), none of which is described. The reported expert judgments likewise lack stated criteria, inter-rater agreement, or comparison against a non-interactive baseline, rendering the 722/2885 usefulness ratio non-interpretable.
- [Abstract] Abstract: the interaction mechanism that 'learns the context of the data' is central to the recommendation claim, yet no protocol (questions asked, feedback model, or learning algorithm) is provided. This omission directly undermines the assertion that the system captures sufficient context to rank tasks meaningfully.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We agree that several key elements were insufficiently described, which hinders assessment of the claims. We will revise the manuscript to address these issues by providing the missing definitions and protocols. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the system 'generates all possible prediction tasks under a predefined space' is load-bearing for both the 2885-task count and the usefulness judgment, yet the manuscript supplies no definition of that space (allowed operators, prediction horizons, aggregations, or feature constructions). Without this, it is impossible to verify whether the space is broad enough to contain tasks domain experts actually want.
Authors: We acknowledge this omission in the current version of the manuscript. In the revised version, we will include a formal definition of the predefined task space, specifying the allowed operators, prediction horizons, aggregations, and feature constructions. This will enable readers to assess the breadth and relevance of the generated tasks. revision: yes
-
Referee: [Abstract] Abstract: the top-10-in-100 claim requires an evaluation protocol (user-study design, preference metric, baseline comparator, and how user feedback is modeled), none of which is described. The reported expert judgments likewise lack stated criteria, inter-rater agreement, or comparison against a non-interactive baseline, rendering the 722/2885 usefulness ratio non-interpretable.
Authors: We agree that the evaluation details are missing. The revised manuscript will describe the user-study design, the preference metric used, any baseline comparators, how user feedback is modeled, the criteria for deeming tasks useful, inter-rater agreement statistics, and comparisons to non-interactive baselines to make the 722/2885 ratio interpretable. revision: yes
-
Referee: [Abstract] Abstract: the interaction mechanism that 'learns the context of the data' is central to the recommendation claim, yet no protocol (questions asked, feedback model, or learning algorithm) is provided. This omission directly undermines the assertion that the system captures sufficient context to rank tasks meaningfully.
Authors: We recognize the need for a detailed description of the interaction protocol. In the revision, we will specify the questions asked during interaction, the feedback model employed, and the learning algorithm used to capture data context and rank tasks. revision: yes
Circularity Check
No circularity; derivation is self-contained with external validation
full rationale
The paper presents a system that enumerates tasks from a fixed space and ranks them via interaction, with usefulness judged by external expert data scientists on 2885 generated tasks. No equations, fitted parameters, or derivations are described that reduce to their own inputs by construction. Evaluation metrics rely on independent human judgments rather than self-referential scores, and no self-citation chains or uniqueness theorems are invoked as load-bearing premises. The approach is therefore not circular.
Axiom & Free-Parameter Ledger
free parameters (1)
- predefined task space definition
axioms (1)
- domain assumption Expert data scientists provide consistent and meaningful judgments of task usefulness
Reference graph
Works this paper leans on
-
[1]
2017] Baker, B.; Gupta, O.; Raskar, R.; and Naik, N
[Baker et al. 2017] Baker, B.; Gupta, O.; Raskar, R.; and Naik, N
work page 2017
-
[2]
Accelerating Neural Architecture Search using Performance Prediction
Accelerating neural architecture search using performance prediction. arXiv preprint arXiv:1705.10823. [Bengio 2012] Bengio, Y
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[3]
In Neural networks: Tricks of the trade
Practical recommendations for gradient-based training of deep architectures. In Neural networks: Tricks of the trade. Springer. 437–478. [Bergstra and Bengio 2012] Bergstra, J., and Bengio, Y
work page 2012
-
[4]
Journal of Machine Learning Research 13(Feb):281–305
Random search for hyper-parameter optimization. Journal of Machine Learning Research 13(Feb):281–305. [Bergstra et al. 2011] Bergstra, J. S.; Bardenet, R.; Bengio, Y .; and K´egl, B
work page 2011
-
[5]
In Advances in neural information processing systems, 2546–2554
Algorithms for hyper-parameter op- timization. In Advances in neural information processing systems, 2546–2554. [Bergstra, Yamins, and Cox 2013] Bergstra, J.; Yamins, D.; and Cox, D. D
work page 2013
-
[6]
Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. [Feurer et al. 2015] Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.; Blum, M.; and Hutter, F
work page 2015
-
[7]
In Advances in Neural Information Processing Systems, 2962–2970
Efficient and robust automated machine learning. In Advances in Neural Information Processing Systems, 2962–2970. [Hutter, Hoos, and Leyton-Brown 2011] Hutter, F.; Hoos, H. H.; and Leyton-Brown, K
work page 2011
-
[8]
InInterna- tional Conference on Learning and Intelligent Optimization, 507–523
Sequential model-based optimization for general algorithm configuration. InInterna- tional Conference on Learning and Intelligent Optimization, 507–523. Springer. [Jamieson and Nowak 2011] Jamieson, K. G., and Nowak, R
work page 2011
-
[9]
[Kanter and Veeramachaneni 2015] Kanter, J. M., and Veeramachaneni, K
work page 2015
-
[10]
IEEE International Conference on, 1–10. IEEE. [Katz, Shin, and Song 2016] Katz, G.; Shin, E. C. R.; and Song, D
work page 2016
-
[11]
In Data Mining (ICDM), 2016 IEEE 16th In- ternational Conference on, 979–984
Explorekit: Automatic feature generation and selection. In Data Mining (ICDM), 2016 IEEE 16th In- ternational Conference on, 979–984. IEEE. [Kaul, Maheshwary, and Pudi 2017] Kaul, A.; Maheshwary, S.; and Pudi, V
work page 2016
-
[12]
In Data Mining (ICDM), 2017 IEEE International Conference on, 217–226
Autolearnautomated feature gener- ation and selection. In Data Mining (ICDM), 2017 IEEE International Conference on, 217–226. IEEE. [Khurana, Samulowitz, and Turaga 2017] Khurana, U.; Samulowitz, H.; and Turaga, D
work page 2017
-
[13]
Feature Engineering for Predictive Modeling using Reinforcement Learning
Feature engineering for predictive modeling using reinforcement learning. arXiv preprint arXiv:1709.07150. [Liu et al. 2017a] Liu, C.; Zoph, B.; Shlens, J.; Hua, W.; Li, L.-J.; Fei-Fei, L.; Yuille, A.; Huang, J.; and Murphy, K. 2017a. Progressive neural architecture search. arXiv preprint arXiv:1712.00559. [Liu et al. 2017b] Liu, H.; Simonyan, K.; Vinyals...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[14]
In International Conference on Machine Learning , 2113–2122
Gradient-based hyperparameter optimization through reversible learn- ing. In International Conference on Machine Learning , 2113–2122. [Mountantonakis and Tzitzikas 2017] Mountantonakis, M., and Tzitzikas, Y
work page 2017
-
[15]
In International Conference on Theory and Practice of Digital Libraries, 155–168
How linked data can aid machine learning-based tasks. In International Conference on Theory and Practice of Digital Libraries, 155–168. Springer. [Pham et al. 2018] Pham, H.; Guan, M. Y .; Zoph, B.; Le, Q. V .; and Dean, J
work page 2018
-
[16]
Efficient Neural Architecture Search via Parameter Sharing
Efficient neural architecture search via parameter sharing. arXiv preprint arXiv:1802.03268. [Real et al. 2018] Real, E.; Aggarwal, A.; Huang, Y .; and Le, Q. V
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
Regularized Evolution for Image Classifier Architecture Search
Regularized evolution for image classifier ar- chitecture search. arXiv preprint arXiv:1802.01548. [Snoek, Larochelle, and Adams 2012] Snoek, J.; Larochelle, H.; and Adams, R. P
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[18]
In Advances in neural information processing systems, 2951–2959
Practical bayesian optimiza- tion of machine learning algorithms. In Advances in neural information processing systems, 2951–2959. [Swearingen et al. ] Swearingen, T.; Drevo, W.; Cyphers, B.; Cuesta-Infante, A.; Ross, A.; and Veeramachaneni, K. Atm: A distributed, collaborative, scalable system for automated machine learning. [Swersky, Snoek, and Adams 20...
work page 2013
-
[19]
In Advances in neural information processing systems , 2004–
Multi-task bayesian optimization. In Advances in neural information processing systems , 2004–
work page 2004
-
[20]
2013] Thornton, C.; Hutter, F.; Hoos, H
[Thornton et al. 2013] Thornton, C.; Hutter, F.; Hoos, H. H.; and Leyton-Brown, K
work page 2013
-
[21]
Auto-weka: Combined selec- tion and hyperparameter optimization of classification algo- rithms. In Proceedings of the 19th ACM SIGKDD interna- tional conference on Knowledge discovery and data mining, 847–855. ACM. [van den Bosch 2017] van den Bosch, S
work page 2017
-
[22]
Master’s thesis, Faculty of Science, Radboud Univer- sity 3(1):3–1
Automatic feature generation and selection in predictive analytics solu- tions. Master’s thesis, Faculty of Science, Radboud Univer- sity 3(1):3–1. [Wauthier, Jordan, and Jojic 2013] Wauthier, F.; Jordan, M.; and Jojic, N
work page 2013
-
[23]
In International Conference on Machine Learning , 109–117
Efficient ranking from pairwise compar- isons. In International Conference on Machine Learning , 109–117. [Zhong, Xiong, and Socher 2017] Zhong, V .; Xiong, C.; and Socher, R
work page 2017
-
[24]
Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning
Seq2sql: Generating structured queries from natural language using reinforcement learning. CoRR abs/1709.00103. [Zoph and Le 2016] Zoph, B., and Le, Q. V
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[25]
Neural Architecture Search with Reinforcement Learning
Neu- ral architecture search with reinforcement learning. arXiv preprint arXiv:1611.01578. [Zoph et al. 2017] Zoph, B.; Vasudevan, V .; Shlens, J.; and Le, Q. V
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Learning Transferable Architectures for Scalable Image Recognition
Learning transferable architectures for scal- able image recognition. arXiv preprint arXiv:1707.07012 2(6). ChicagoBicycle O: <from_station_id> [all_fil(None), count_agg(None)] G: For each <from_station_id> predict the number of records H: Predict how many trips will start from this station tomorrow. O: <from_station_id> [eq_fil(<usertype>), count_agg(None)...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.