Distortion-Aware PETR for BEV Object Detection with Mixed Pinhole-Fisheye Cameras
Pith reviewed 2026-06-27 18:30 UTC · model grok-4.3
The pith
DAPETR introduces distortion-aware positional embeddings and co-modulation to enable effective BEV detection with mixed pinhole-fisheye cameras.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
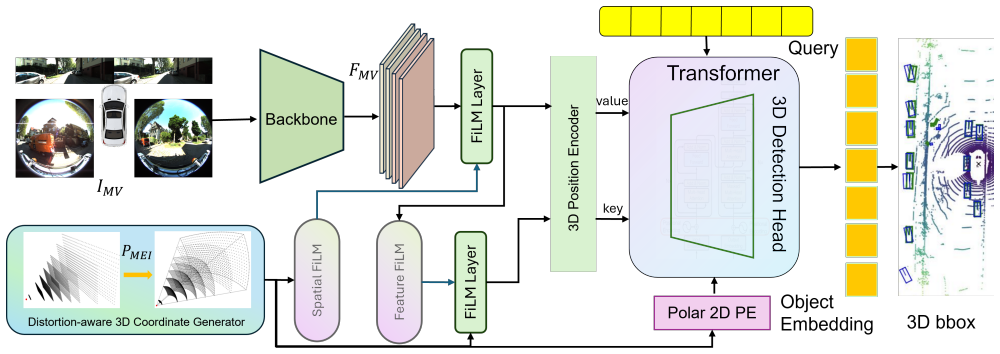
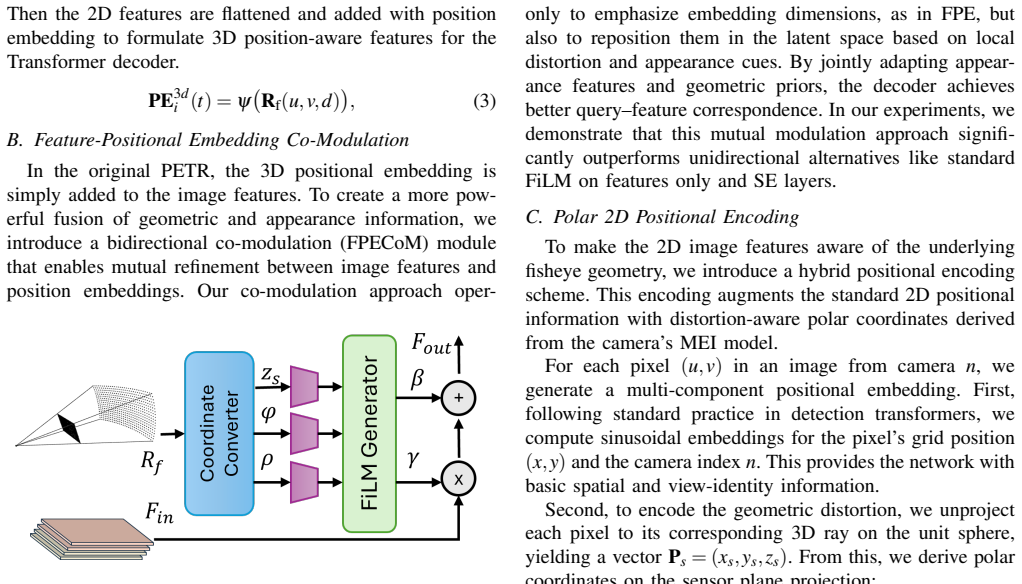
DAPETR advances fisheye BEV detection by incorporating a unified distortion-aware positional embedding that harmonizes positional encodings with fisheye geometry and a bidirectional feature-geometry co-modulation module that mutually adapts image features and 3D positional embeddings, achieving superior performance over PETR and PolarPETR on the converted KITTI-360 benchmark while revealing a negative interaction between learned adaptation and explicit geometric reparameterization.
What carries the argument
The unified distortion-aware positional embedding and bidirectional feature-geometry co-modulation module that allow adaptation to fisheye geometry without projection or rectification.
If this is right
- Both learned adaptive modules and polar reparameterization improve over the PETR baseline for fisheye cameras.
- The learned modules in DAPETR achieve better performance than PolarPETR.
- Combining the learned adaptation with explicit geometric reparameterization leads to negative interaction and reduced performance.
- The approach provides insights for distortion-aware 3D perception designs that avoid image rectification.
Where Pith is reading between the lines
- Adaptive learning approaches may generalize better to real mixed camera setups than fixed geometric transformations.
- Future detectors could integrate these modules to handle a wider variety of camera distortions without preprocessing steps.
- Testing on diverse real-world data could confirm if the benchmark results hold beyond the converted KITTI-360 dataset.
Load-bearing premise
The converted KITTI-360 benchmark faithfully represents real mixed pinhole-fisheye camera setups and performance differences are due to the proposed modules.
What would settle it
Running DAPETR and PolarPETR on raw data from an actual vehicle equipped with both pinhole and fisheye cameras to check if the performance advantage persists.
Figures

read the original abstract
Fisheye cameras are widely deployed in autonomous driving perception suites for their low cost and full-coverage field of view (FOV), yet their potential remains underleveraged in 3D object detection. Severe radial distortion challenges most BEV detectors by violating the fundamental assumption of uniform sampling. To bridge this gap, we propose Distortion-Aware PETR (DAPETR), a projection-free detector tailored for mixed pinhole-fisheye camera setups. DAPETR incorporates two key learned-adaptive modules: a unified distortion-aware positional embedding that harmonizes positional encodings for image representations with fisheye geometry, and a bidirectional feature-geometry co-modulation module that mutually adapts image features and 3D positional embeddings. In our experiments on a converted KITTI-360 benchmark, we systematically compare our learned adaptive approach against PETR in polar coordinates (PolarPETR). We find that while both methods improve over the baseline, our learned modules achieve superior performance. Crucially, we uncover a negative interaction when combining both strategies, revealing that learned adaptation and explicit geometric reparameterization can conflict. Our final DAPETR model significantly advances the research and benchmark for fisheye BEV detection, providing critical insights into effective distortion-aware 3D perception design other than image rectification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Distortion-Aware PETR (DAPETR) for BEV 3D object detection on mixed pinhole-fisheye camera rigs. It introduces two learned modules—a unified distortion-aware positional embedding that adapts encodings to fisheye geometry and a bidirectional feature-geometry co-modulation module that mutually refines image features and 3D embeddings—without explicit rectification or polar reparameterization. On a converted KITTI-360 benchmark the authors report that DAPETR outperforms both standard PETR and PolarPETR, while the two adaptation strategies interact negatively when combined.
Significance. If the benchmark conversion faithfully reproduces real mixed-camera geometry and the reported deltas are attributable to the modules rather than conversion artifacts, the work supplies a concrete empirical comparison between learned adaptive positional encodings and explicit geometric reparameterization for fisheye BEV detection, together with the observation of negative interaction. This could inform design choices in distortion-aware perception pipelines.
major comments (2)
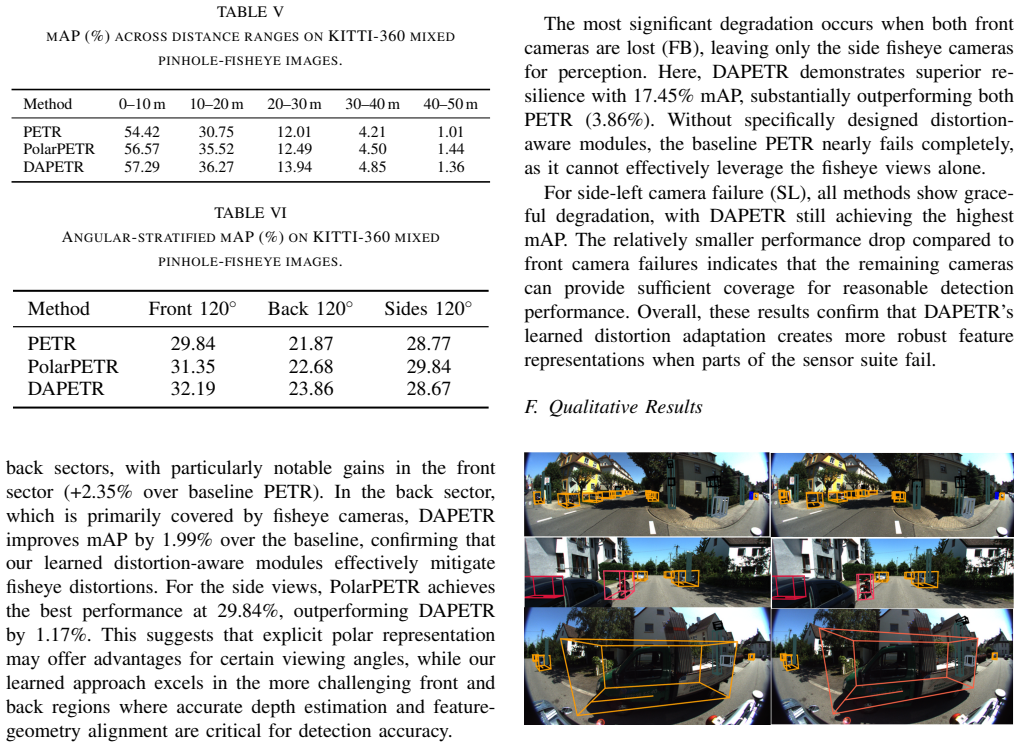
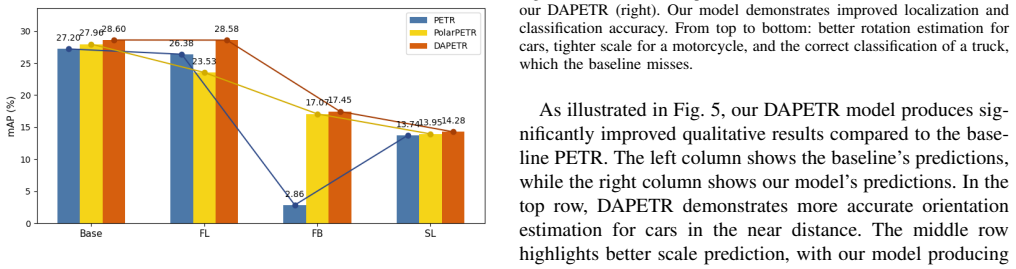
- [Experiments / benchmark description] The central empirical claims rest on a “converted KITTI-360 benchmark” whose construction is not described in the abstract or visible experimental section. No procedure is given for embedding radial distortion into the original pinhole images, for maintaining consistent 3D-to-2D correspondences across camera types, or for cross-validating against native fisheye sequences. Without these details it is impossible to rule out that measured gains over PolarPETR arise from benchmark artifacts rather than the proposed modules (§ on experiments / benchmark construction).
- [Ablation studies] The headline result that the two strategies “interact negatively” is presented as a design insight, yet no ablation table, interaction term, or statistical test is referenced that isolates the interaction from other factors (e.g., training schedule, embedding dimensionality). This interaction is load-bearing for the claim that learned adaptation and explicit reparameterization conflict.
minor comments (2)
- [Method] Notation for the distortion-aware positional embedding and the co-modulation module should be introduced with explicit equations rather than prose descriptions only.
- [Abstract / Experiments] The abstract states that DAPETR “significantly advances the research and benchmark,” but no quantitative comparison to prior fisheye BEV detectors (outside PETR/PolarPETR) is mentioned; a broader baseline table would strengthen the claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to improve clarity on the benchmark and strengthen the ablation analysis.
read point-by-point responses
-
Referee: [Experiments / benchmark description] The central empirical claims rest on a “converted KITTI-360 benchmark” whose construction is not described in the abstract or visible experimental section. No procedure is given for embedding radial distortion into the original pinhole images, for maintaining consistent 3D-to-2D correspondences across camera types, or for cross-validating against native fisheye sequences. Without these details it is impossible to rule out that measured gains over PolarPETR arise from benchmark artifacts rather than the proposed modules (§ on experiments / benchmark construction).
Authors: We acknowledge that the description of the benchmark conversion process requires expansion for full reproducibility. The experimental section does outline the conversion from KITTI-360 pinhole images, but we agree it lacks sufficient procedural detail. In the revised manuscript we will add a dedicated subsection describing the radial distortion embedding method, how 3D-to-2D correspondences are preserved across camera models, and any validation against native fisheye data. This will help demonstrate that performance differences are attributable to the proposed modules. revision: yes
-
Referee: [Ablation studies] The headline result that the two strategies “interact negatively” is presented as a design insight, yet no ablation table, interaction term, or statistical test is referenced that isolates the interaction from other factors (e.g., training schedule, embedding dimensionality). This interaction is load-bearing for the claim that learned adaptation and explicit reparameterization conflict.
Authors: The negative interaction is shown via direct comparison of the four combinations (baseline, distortion-aware embedding only, co-modulation only, and both) in our ablation experiments. However, the referee is correct that an explicit interaction term or statistical test isolating confounding factors is not provided. We will add a more granular ablation table with additional controls and a brief statistical note in the revision to better substantiate the interaction claim. revision: partial
Circularity Check
No circularity: empirical module comparison on external benchmark
full rationale
The paper introduces two learned modules (distortion-aware positional embedding and bidirectional co-modulation) and reports performance gains versus PETR and PolarPETR on a converted KITTI-360 benchmark. No equations, self-definitions, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims are experimental outcomes rather than derivations that reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The converted KITTI-360 benchmark is a valid proxy for real mixed-camera fisheye perception.
Reference graph
Works this paper leans on
-
[1]
Surround-view fisheye camera perception for automated driving: Overview, survey & challenges,
V . R. Kumar, C. Eising, C. Witt, and S. K. Yogamani, “Surround-view fisheye camera perception for automated driving: Overview, survey & challenges,”IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 4, pp. 3638–3659, 2023
2023
-
[2]
Delving into the devils of bird’s-eye-view perception: A review, evaluation and recipe,
H. Li, C. Sima, J. Dai, W. Wang, L. Lu, H. Wang, J. Zeng, Z. Li, J. Yang, H. Deng, H. Tian, E. Xie, J. Xie, L. Chen, T. Li, Y . Li, Y . Gao, X. Jia, S. Liu, J. Shi, D. Lin, and Y . Qiao, “Delving into the devils of bird’s-eye-view perception: A review, evaluation and recipe,”IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–20, 2023
2023
-
[3]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11621–11631, 2020
2020
-
[4]
Petr: Position embedding transformation for multi-view 3d object detection,
Y . Liu, T. Wang, X. Zhang, and J. Sun, “Petr: Position embedding transformation for multi-view 3d object detection,” inEuropean con- ference on computer vision, pp. 531–548, Springer, 2022
2022
-
[5]
Polarformer: Multi-camera 3d object detection with polar transformer,
Y . Jiang, L. Zhang, Z. Miao, X. Zhu, J. Gao, W. Hu, and Y .-G. Jiang, “Polarformer: Multi-camera 3d object detection with polar transformer,” inProceedings of the AAAI conference on Artificial Intelligence, vol. 37, pp. 1042–1050, 2023
2023
-
[6]
Polarbevdet: Exploring polar representation for multi-view 3d object detection in bird’s-eye-view,
Z. Yu, Q. Liu, W. Wang, L. Zhang, and X. Zhao, “Polarbevdet: Exploring polar representation for multi-view 3d object detection in bird’s-eye-view,”arXiv preprint arXiv:2408.16200, 2024
-
[7]
Polardetr: Polar parametrization for vision-based surround-view 3d detection,
S. Chen, X. Wang, T. Cheng, Q. Zhang, C. Huang, and W. Liu, “Polardetr: Polar parametrization for vision-based surround-view 3d detection,”Image and Vision Computing, vol. 156, p. 105438, 2025
2025
-
[8]
Kitti-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d,
Y . Liao, J. Xie, and A. Geiger, “Kitti-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 3, pp. 3292–3310, 2022
2022
-
[9]
Single view point omnidirectional camera calibration from planar grids,
C. Mei and P. Rives, “Single view point omnidirectional camera calibration from planar grids,” inProceedings 2007 IEEE International Conference on Robotics and Automation, pp. 3945–3950, IEEE, 2007
2007
-
[10]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,
J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,” inEuropean conference on computer vision, pp. 194–210, Springer, 2020
2020
-
[11]
BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View
J. Huang, G. Huang, Z. Zhu, Y . Ye, and D. Du, “Bevdet: High- performance multi-camera 3d object detection in bird-eye-view,”arXiv preprint arXiv:2112.11790, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Bevdet4d: Exploit temporal cues in multi- camera 3d object detection,
J. Huang and G. Huang, “Bevdet4d: Exploit temporal cues in multi- camera 3d object detection,”arXiv preprint arXiv:2203.17054, 2022
-
[13]
Bev- former: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers,
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu, and J. Dai, “Bev- former: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[14]
Detr3d: 3d object detection from multi-view images via 3d-to-2d queries,
Y . Wang, V . C. Guizilini, T. Zhang, Y . Wang, H. Zhao, and J. Solomon, “Detr3d: 3d object detection from multi-view images via 3d-to-2d queries,” inConference on robot learning, pp. 180–191, PMLR, 2022
2022
-
[15]
F2bev: Bird’s eye view generation from surround-view fisheye cam- era images for automated driving,
E. U. Samani, F. Tao, H. R. Dasari, S. Ding, and A. G. Banerjee, “F2bev: Bird’s eye view generation from surround-view fisheye cam- era images for automated driving,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 9367–9374, IEEE, 2023
2023
-
[16]
Fisheye- bevseg: Surround view fisheye cameras based bird’s-eye view seg- mentation for autonomous driving,
S. Yogamani, D. Unger, V . Narayanan, and V . R. Kumar, “Fisheye- bevseg: Surround view fisheye cameras based bird’s-eye view seg- mentation for autonomous driving,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1331– 1334, 2024
2024
-
[17]
Woodscape: A multi-task, multi-camera fisheye dataset for autonomous driving,
S. Yogamani, C. Hughes, J. Horgan, G. Sistu, P. Varley, D. O’Dea, M. Uric ´ar, S. Milz, M. Simon, K. Amende,et al., “Woodscape: A multi-task, multi-camera fisheye dataset for autonomous driving,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9308–9318, 2019
2019
-
[18]
G. Sistu and S. Yogamani, “Fisheyedetnet: 360{\deg}surround view fisheye camera based object detection system for autonomous driving,” arXiv preprint arXiv:2404.13443, 2024
-
[19]
Heal-swin: A vision transformer on the sphere,
O. Carlsson, J. E. Gerken, H. Linander, H. Spieß, F. Ohlsson, C. Peters- son, and D. Persson, “Heal-swin: A vision transformer on the sphere,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6067–6077, 2024
2024
-
[20]
Darswin: Distortion aware radial swin transformer,
A. Athwale, A. Afrasiyabi, J. Lag ¨ue, I. Shili, O. Ahmad, and J.- F. Lalonde, “Darswin: Distortion aware radial swin transformer,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 5929–5938, 2023
2023
-
[21]
Cam-convs: Camera-aware multi-scale convolutions for single-view depth,
J. M. Facil, B. Ummenhofer, H. Zhou, L. Montesano, T. Brox, and J. Civera, “Cam-convs: Camera-aware multi-scale convolutions for single-view depth,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11826–11835, 2019
2019
-
[22]
Sensor equivariance: A framework for semantic segmentation with diverse camera models,
H. Reichert, M. Hetzel, A. Hubert, K. Doll, and B. Sick, “Sensor equivariance: A framework for semantic segmentation with diverse camera models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1254–1261, 2024
2024
-
[23]
Adapting cnns for fisheye cameras without retraining,
R. Griffiths and D. G. Dansereau, “Adapting cnns for fisheye cameras without retraining,”arXiv preprint arXiv:2404.08187, 2024
-
[24]
Convolution kernel adaptation to calibrated fisheye,
B. Berenguel-Baeta, M. Santos-Villafranca, J. Bermudez-Cameo, A. P. Yus, and J. Guerrero, “Convolution kernel adaptation to calibrated fisheye,” in34th British Machine Vision Conference 2023, BMVC 2023, Aberdeen, UK, November 20-24, 2023, BMV A, 2023
2023
-
[25]
Film: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville, “Film: Visual reasoning with a general conditioning layer,” inProceedings of the AAAI conference on artificial intelligence, vol. 32, 2018
2018
-
[26]
Squeeze-and-excitation networks,
J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 7132–7141, 2018
2018
-
[27]
Petrv2: A unified framework for 3d perception from multi-camera images,
Y . Liu, J. Yan, F. Jia, S. Li, A. Gao, T. Wang, and X. Zhang, “Petrv2: A unified framework for 3d perception from multi-camera images,” in Proceedings of the IEEE/CVF international conference on computer vision, pp. 3262–3272, 2023
2023
-
[28]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in European conference on computer vision, pp. 213–229, Springer, 2020
2020
-
[29]
Benchmarking multi-view bev object detection with mixed pinhole and fisheye cameras,
X. Liu and H. Shen, “Benchmarking multi-view bev object detection with mixed pinhole and fisheye cameras,” inProceedings of the IEEE International Conference on Robotics and Automation (ICRA), IEEE,
-
[30]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
MMDetection3D: OpenMMLab next-generation platform for general 3D object detection
M. Contributors, “MMDetection3D: OpenMMLab next-generation platform for general 3D object detection.”https://github.com/ open-mmlab/mmdetection3d, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.