3D RL-DWA: A Hybrid Reinforcement Learning and Dynamic Window Approach for Goal-Directed Local Navigation in Multi-DoF Robots
Pith reviewed 2026-05-14 20:17 UTC · model grok-4.3
The pith
A hybrid RL and DWA controller improves deformation and path completion for microrobots in 3D constrained spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
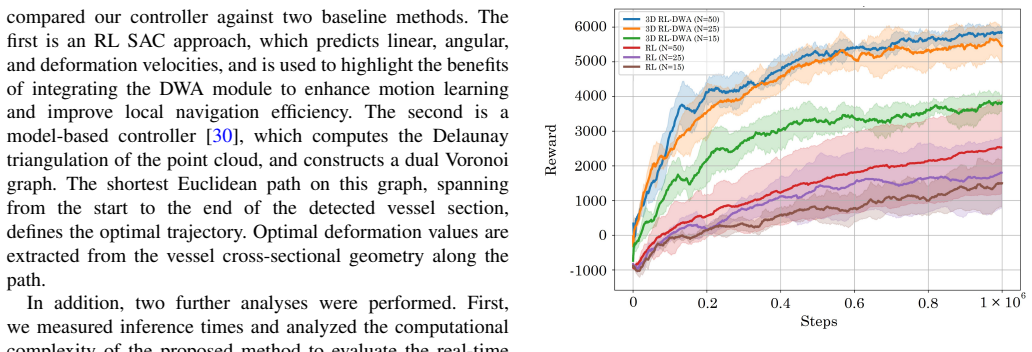
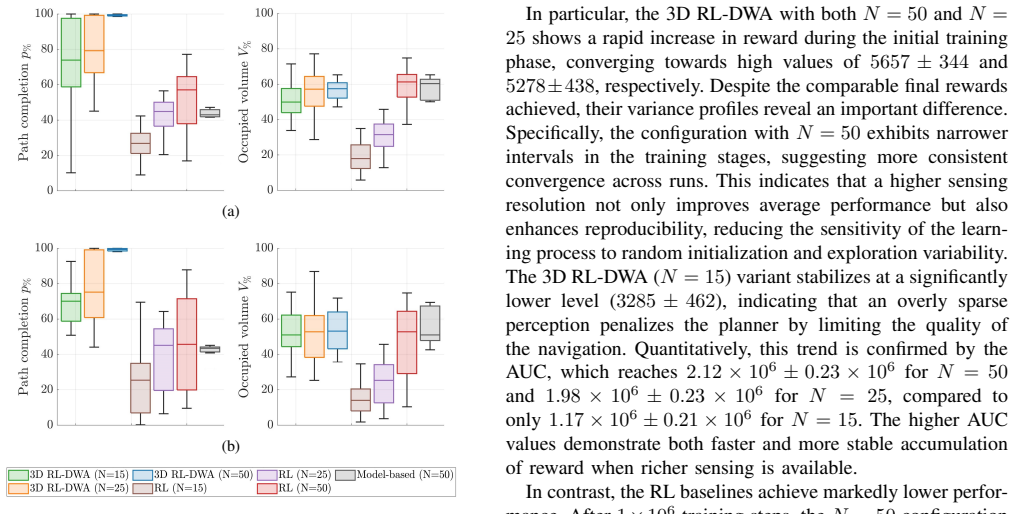
The central claim is that integrating reinforcement learning with a Dynamic Window Approach-based local planner significantly enhances both deformation and navigation capabilities of high-degree-of-freedom deformable microrobots compared to pure RL and model-based methods, consistently achieving high deformation and near-perfect path completion in a simulated vascular network while maintaining robust performance in unseen scenarios.
What carries the argument
The RL-DWA hybrid controller, which uses reinforcement learning to select actions inside the dynamic window approach constraints so the microrobot can adjust both its motion and its shape from sparse point cloud inputs.
If this is right
- The hybrid controller achieves consistently high deformation while navigating during training.
- Near-perfect path completion rates hold even when the robot encounters new vascular layouts not seen in training.
- The approach delivers better deformation and navigation than either pure reinforcement learning or traditional model-based planners alone.
- Robust performance persists under sparse sensory conditions in complex three-dimensional spaces.
Where Pith is reading between the lines
- Hybrid learning-plus-classical planners may reduce the amount of real-world data needed to achieve reliable navigation in shape-changing systems.
- The same structure could be tested on other multi-DoF robots that must alter form to pass through narrow passages.
- Future trials could measure how contact forces and sensor noise in physical setups alter the policies learned in simulation.
Load-bearing premise
The simulated vascular network and sparse point-cloud sensor model are representative enough of real contact forces, dynamics, and sensing noise that performance gains transfer to physical robots.
What would settle it
Deploy the trained hybrid controller on a physical deformable microrobot inside a real vascular phantom and measure whether deformation levels and path completion rates match or exceed the simulation results under comparable goal and obstacle conditions.
Figures



read the original abstract
In this paper, we present a novel hybrid approach that combines Reinforcement Learning (RL) with Dynamic Window Approach (DWA) for adaptive 3D local navigation of high-degree-of-freedom robotic systems. Our method leverages sparse point cloud data to dynamically adjust both the motion and the shape of a deformable microrobot, enabling the system to navigate toward a goal in complex, constrained environments while maximizing the occupied volume. We evaluate our framework in a simulated vascular network. Experimental results, based on 1080 trials, indicate that integrating RL with a DWA-based local planner significantly enhances both deformation and navigation capabilities compared to pure RL and model-based methods. In particular, the proposed autonomous controller consistently achieves high deformation and near-perfect path completion during training and maintains robust performance in unseen scenarios. These findings highlight the potential of hybrid planning strategies for efficient and adaptive 3D navigation under sparse sensory conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hybrid 3D RL-DWA controller that combines reinforcement learning with the dynamic window approach to enable goal-directed local navigation for high-DoF deformable microrobots. Using sparse point-cloud observations, the method simultaneously optimizes robot shape (deformation) and motion in constrained 3D environments. Evaluation in a simulated vascular network across 1080 trials shows the hybrid controller achieving higher deformation and near-perfect path completion than pure RL and model-based baselines, with maintained performance in unseen scenarios.
Significance. If the simulation results transfer, the hybrid RL-DWA formulation provides a practical way to fuse learned deformation policies with model-based local planning for sparse-sensing navigation tasks. This could be relevant for medical microrobotics and other high-DoF systems operating under partial observability, where pure RL struggles with local constraints and pure DWA lacks adaptive shape control.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: the claim of statistically significant improvement over baselines rests on 1080 trials, yet no error bars, confidence intervals, hypothesis tests, or training-seed variance are reported, so the magnitude and reliability of the reported gains cannot be assessed.
- [Simulation setup and results] Simulation setup and results: the central claim that the hybrid controller 'maintains robust performance in unseen scenarios' is supported only by trials inside a single simulated vascular network with a sparse point-cloud sensor model; without any analysis of how contact forces, tissue compliance, fluid drag, or sensor noise compare to physical conditions, the performance advantage may be an artifact of the simulator rather than a property of the controller.
minor comments (2)
- [Method] Clarify the precise state representation passed to the RL policy and the exact form of the reward that balances deformation volume against goal progress and collision avoidance.
- [Method] Specify the DWA parameter ranges and how they are modulated by the RL output; the integration point between the learned policy and the local planner is described at a high level but lacks implementation equations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments point-by-point below, clarifying the scope of our simulation study while committing to improvements in statistical reporting and discussion of limitations.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: the claim of statistically significant improvement over baselines rests on 1080 trials, yet no error bars, confidence intervals, hypothesis tests, or training-seed variance are reported, so the magnitude and reliability of the reported gains cannot be assessed.
Authors: We agree that the current presentation lacks sufficient statistical detail to fully support claims of improvement. In the revised manuscript we will add error bars, 95% confidence intervals, and aggregated results across multiple training seeds (with variance reported) in the Evaluation section and associated figures. This will allow readers to assess both the magnitude and reliability of the performance differences. revision: yes
-
Referee: [Simulation setup and results] Simulation setup and results: the central claim that the hybrid controller 'maintains robust performance in unseen scenarios' is supported only by trials inside a single simulated vascular network with a sparse point-cloud sensor model; without any analysis of how contact forces, tissue compliance, fluid drag, or sensor noise compare to physical conditions, the performance advantage may be an artifact of the simulator rather than a property of the controller.
Authors: The evaluation is explicitly a simulation study; 'unseen scenarios' denotes novel goal locations and path segments within the same vascular network model. We acknowledge that no direct comparison to physical contact forces, tissue compliance, fluid drag, or sensor noise is provided. In revision we will expand the Discussion to detail the simulator's modeling assumptions for these phenomena and to state clearly that physical transfer remains an open question for future work. revision: partial
Circularity Check
No circularity: empirical comparisons are independent of fitted inputs
full rationale
The paper reports performance from 1080 direct simulation trials comparing the hybrid RL-DWA controller against pure RL and model-based baselines. No equations, parameter fits, or self-citations are invoked to derive the claimed gains in deformation or path completion; results are presented as raw experimental outcomes. The derivation chain consists solely of training and evaluation procedures whose outputs are not algebraically forced by their inputs. This is the standard non-circular case for an empirical robotics paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reinforcement learning policies trained in simulation can produce effective continuous control for shape and motion of a deformable body.
- domain assumption The dynamic window approach can be extended to select both velocity and deformation commands without violating kinematic constraints.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
G(v) = α·vel(v)+β·dir(v)+γ·clear(v)+ζ·head(v)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.