Weak-to-Strong Elicitation via Mismatched Wrong Drafts
Pith reviewed 2026-05-20 14:27 UTC · model grok-4.3
The pith
Injecting mismatched wrong drafts from a smaller model into GRPO training improves a stronger model's math reasoning over standard on-policy methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
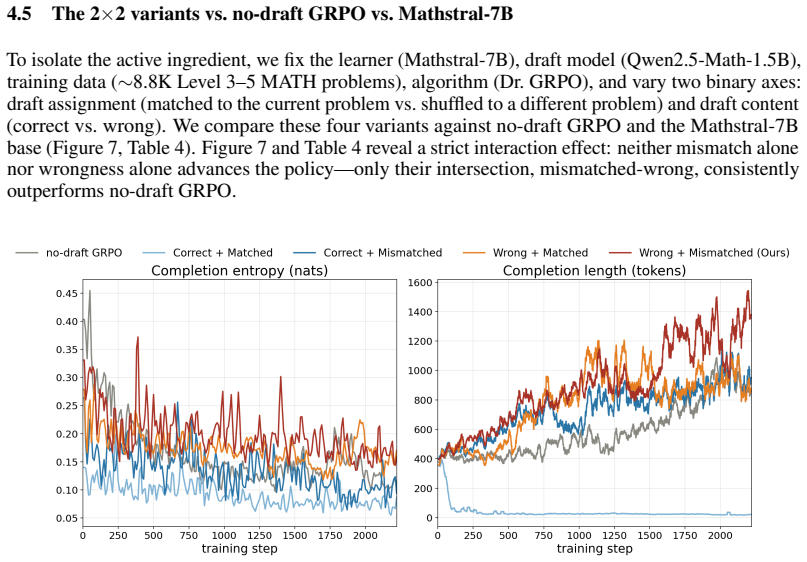
The authors claim that injecting mathematically wrong drafts from a smaller but more domain-trained model mismatched to the current problem into a stronger learner's GRPO context consistently outperforms standard on-policy GRPO on held-out MATH-500 and out-of-distribution AIME 2025/2026. Using Mathstral-7B as the learner and Qwen2.5-Math-1.5B as the draft model on 8.8K Level 3-5 MATH problems, the mismatched-wrong variant leads all tested variants on MATH-500 and uniquely lifts pass@k on both AIME years at every sample budget, reaching 71.98 percent MATH-500 greedy pass@1.
What carries the argument
Mismatched wrong draft injection into the GRPO context, which supplies off-policy incorrect reasoning traces from the smaller model to guide the stronger model's policy updates.
If this is right
- The mismatched-wrong recipe achieves 71.98 percent on MATH-500 for Mathstral-7B, exceeding prior heavier pipelines on the same model.
- It raises pass@k on AIME 2025 and 2026 above both the base learner and the draft model at every sample budget from k=1 to k=1024.
- Shuffling drafts to create mismatch produces a statistically significant gain over the matched-wrong variant on MATH-500.
- All gains occur with the same prompt at test time and with no draft injection during evaluation.
Where Pith is reading between the lines
- The result suggests weak-to-strong elicitation can exploit error signals from specialized smaller models when the errors are deliberately mismatched.
- Similar benefits might appear in non-math reasoning domains if a weaker model supplies domain-tuned but incorrect traces.
- The approach raises the possibility that controlled mismatch and incorrectness could be a general lever in off-policy RL for language models.
Load-bearing premise
The performance lift comes specifically from the combination of the drafts being mathematically wrong and mismatched to the problem rather than from simply adding any extra context or from incidental differences in training dynamics.
What would settle it
Running the identical training setup but replacing mismatched wrong drafts with matched wrong drafts or with correct drafts and finding no remaining advantage on MATH-500 or AIME would falsify the claim.
Figures






read the original abstract
We consider whether off-policy experience from a smaller, weaker model can elicit capability in a stronger learner that on-policy RL fine-tuning (e.g., GRPO) does not reach. We find that injecting mathematically wrong drafts from a smaller but more domain-trained model -- mismatched to the current problem -- into a stronger learner's GRPO context consistently outperforms standard on-policy GRPO on held-out MATH-500 and out-of-distribution AIME 2025/2026. Concretely, we use Mathstral-7B as the learner, Qwen2.5-Math-1.5B as the draft model, 8.8K Level 3--5 MATH problems (with MATH-500 held out), and train with Dr. GRPO. Mismatch is an active ingredient: shuffling drafts to mismatched problems while holding everything else constant yields $+1.62$pp on MATH-500 (greedy pass@1) over the matched-wrong variant ($n=10$ seeds, $p=0.0015$, Welch's $t$). In fact, the mismatched-wrong variant leads all other variants we tested on MATH-500 across both greedy pass@1 and sampling pass@$k$. On out-of-distribution AIME 2025 and 2026, the mismatched-wrong variant uniquely lifts pass@$k$ above both Mathstral-7B (in its native [INST] format) and the Qwen2.5-Math-1.5B draft model at every sample budget from $k=1$ to $k=1024$ across 2 seeds ($+14.2$pp on 2025 and $+9.0$pp on 2026 at pass@1024 over Mathstral-7B), and at pass@1024 also leads no-draft, matched-wrong, and mismatched-correct variants on both years. All variants use the same prompt with no draft injection at test time. The recipe -- trained on a single GPU with no SFT, no reward models, no synthesized data, and no produce-critique-revise inner loop -- reaches 71.98% MATH-500 on Mathstral-7B-v0.1, the highest published result on this model to our knowledge, surpassing the heavier WizardMath pipeline at 70.9% on full MATH (SFT + PPO with process/instruction reward models).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes eliciting stronger math reasoning in a 7B model (Mathstral) via GRPO by injecting mismatched mathematically wrong solution drafts generated by a smaller, more domain-specialized 1.5B model (Qwen2.5-Math). It reports that the mismatched-wrong variant outperforms standard on-policy GRPO as well as matched-wrong, mismatched-correct, and no-draft baselines on held-out MATH-500 (71.98% greedy pass@1) and OOD AIME 2025/2026 (lifts at all k up to 1024), with a shuffling experiment showing a statistically significant +1.62pp gain from mismatch (n=10, p=0.0015). The method requires no SFT, reward models, or synthesized data.
Significance. If the performance gains can be causally attributed to the combination of wrongness and mismatch rather than ancillary factors, the approach offers a lightweight, single-GPU recipe for improving RL fine-tuning on math tasks and contributes to weak-to-strong elicitation research. The consistent outperformance across greedy/sampling metrics, multiple seeds, and OOD sets, together with the explicit mismatch ablation, provides a falsifiable empirical foundation worth further investigation.
major comments (2)
- The central claim that gains arise specifically from injecting mathematically wrong and mismatched drafts is load-bearing, yet the variant comparisons do not explicitly control for differences in injected sequence length or token distribution. These factors could alter the group-relative advantage estimates inside Dr. GRPO independently of wrongness or mismatch; the shuffling experiment (+1.62pp over matched-wrong) and mismatched-correct comparison are helpful but insufficient without length-matched or distribution-matched controls.
- In the OOD AIME 2025/2026 results, the mismatched-wrong variant leads at pass@1024, but the manuscript does not report whether all training variants maintain identical total context lengths or prompt structures when drafts are injected. Without this, it remains possible that the observed lifts reflect changes in training dynamics rather than the proposed weak-to-strong mechanism.
minor comments (2)
- Ensure the full paper defines 'Dr. GRPO' and any modifications to standard GRPO on first use, including how drafts are formatted and inserted into the context.
- The abstract states the result surpasses WizardMath at 70.9% on full MATH; clarify whether the comparison is on identical test sets and model scales for precision.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for tighter controls on potential confounds. We address each point below and outline targeted revisions to strengthen the causal claims while preserving the core empirical findings.
read point-by-point responses
-
Referee: The central claim that gains arise specifically from injecting mathematically wrong and mismatched drafts is load-bearing, yet the variant comparisons do not explicitly control for differences in injected sequence length or token distribution. These factors could alter the group-relative advantage estimates inside Dr. GRPO independently of wrongness or mismatch; the shuffling experiment (+1.62pp over matched-wrong) and mismatched-correct comparison are helpful but insufficient without length-matched or distribution-matched controls.
Authors: We agree that explicit controls for sequence length and token distribution would further isolate the contributions of wrongness and mismatch. The shuffling experiment randomizes wrong drafts across problems while preserving the overall empirical distribution of lengths and token statistics between the matched-wrong and mismatched-wrong conditions. The mismatched-correct condition likewise uses drafts from the identical generator on the same problems, differing only in content correctness. To directly address the concern, we will add a length-matched ablation in the revision by truncating or padding drafts to equalize lengths across variants and re-report the key metrics; this will confirm whether the +1.62pp mismatch gain persists under length equalization. revision: partial
-
Referee: In the OOD AIME 2025/2026 results, the mismatched-wrong variant leads at pass@1024, but the manuscript does not report whether all training variants maintain identical total context lengths or prompt structures when drafts are injected. Without this, it remains possible that the observed lifts reflect changes in training dynamics rather than the proposed weak-to-strong mechanism.
Authors: All variants use the identical base prompt template and consistent draft insertion position within the context window. Any differences in total context length arise solely from the natural variation in draft lengths produced by the 1.5B model; we verified that no variant experienced differential truncation at the model’s maximum context limit. In the revision we will add a table reporting mean and standard deviation of training context lengths per variant, together with explicit confirmation that prompt structures remained fixed, thereby ruling out training-dynamic confounds as the source of the OOD lifts. revision: yes
Circularity Check
No circularity; purely empirical comparisons with external benchmarks
full rationale
The paper reports direct experimental results from training Mathstral-7B with Dr. GRPO under different draft-injection variants (no-draft, matched-wrong, mismatched-wrong, mismatched-correct) and measures greedy pass@1 and sampling pass@k on held-out MATH-500 plus out-of-distribution AIME 2025/2026. All claims rest on these measured performance deltas and statistical tests (n=10 seeds, Welch's t, p=0.0015 for the shuffle ablation). No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the reported method or results; the comparisons are falsifiable against the external benchmarks and do not reduce to the inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- GRPO training hyperparameters
axioms (1)
- domain assumption GRPO functions as an effective on-policy RL method for math reasoning when applied to the base model.
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URLhttps://aclanthology.org/2023.emnlp-main.67/. 9 Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-Refine: Iterative refinement with self-feedba...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URLhttps://openreview.net/forum?id=5PAF7PAY2Y. Collin Burns, Pavel Izmailov, Jan Hendrik Kirchner, Bowen Baker, Leo Gao, Leopold Aschenbrenner, Yining Chen, Adrien Ecoffet, Manas Joglekar, Jan Leike, Ilya Sutskever, and Jeff Wu. Weak- to-strong generalization: Eliciting strong capabilities with weak supervision.arXiv preprint arXiv:2312.09390,
-
[5]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, et al. DAPO: An open-source LLM reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. Open-Reasoner-Zero: An open source approach to scaling up reinforcement learning on the base model.arXiv preprint arXiv:2503.24290,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. SimpleRL- Zoo: Investigating and taming zero reinforcement learning for open base models in the wild.arXiv preprint arXiv:2503.18892,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Tianjian Li, Yiming Zhang, Ping Yu, Swarnadeep Saha, Daniel Khashabi, Jason Weston, Jack Lan- chantin, and Tianlu Wang. Jointly reinforcing diversity and quality in language model generations. arXiv preprint arXiv:2509.02534,
-
[9]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jian- hong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2.5-Math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
A Experimental setup details Table 5 consolidates the settings underlying our experiments. 11 Learner (πS) Mathstral-7B-v0.1 [Mistral AI, 2024] Draft model (πW ) Qwen2.5-Math-1.5B [Yang et al., 2024] Training data∼8.8K MATH L3–5 (MATH-500 held out) [Hendrycks et al., 2021] Algorithm Dr. GRPO [Liu et al., 2025];β=0,G=16, grad accum4 LoRA rank16on all linea...
work page 2024
-
[12]
Conclusion: 244 C.2 AIME 2025 Problem 15 Problem.Let N denote the number of ordered triples of positive integers (a, b, c) such that a, b, c≤ 36 anda 3 +b 3 +c 3 is a multiple of3
work page 2025
-
[13]
Find the remainder whenNis divided by1000. Gold answer .735. Raw correctness counts (n=2048samples per cell): Correct / 2048 Mismatched + Wrong (nodraft),s=422 Mismatched + Wrong (nodraft),s=1374 Mathstral-7B base ([INST]),s=420 Mathstral-7B base ([INST]),s=1370 Mathstral-7B never solves this problem ( 0/4096); Mismatched + Wrong solves it 6 times. The Mi...
work page 2048
-
[14]
Thus, the number of ordered triples (a, b, c) such that a3 +b 3 +c 3 is a multiple of 37 is 735 . C.3 AIME 2026 Problem 22 (inverse case: base>ours) Problem.A standard fair six-sided die is rolled repeatedly. Each time the die reads 1 or 2, Alice gets a coin; each time it reads 3 or 4, Bob gets a coin; and each time it reads 5 or 6, Carol gets a coin. The...
work page 2026
-
[15]
Therefore, the probability of reachingC 2 without passing throughC 1 is 1 9 + 1 18 + 1 18 = 7 18
The probabilities of these paths are 1 9 , 1 18 , and 1 18 , respectively. Therefore, the probability of reachingC 2 without passing throughC 1 is 1 9 + 1 18 + 1 18 = 7 18 . Finally, the solution calculates the probability of Alice and Bob each receiving at least two coins before Carol receives any coins. This is done by summing the probabilities of all p...
work page 2024
-
[16]
rigorous mostly wrong I-6 (2024) Mismatched + Wrong (ours) 2 1 1 0 I-6 (2024) No-draft GRPO 1 1 0 0 P8 (2026) Mismatched + Wrong (ours) 74 5 0 69 P8 (2026) No-draft GRPO 157 3 3 151 P19 (2026) Mismatched + Wrong (ours) 1 0 1 0 P19 (2026) No-draft GRPO 1 0 0 1 Table 10: Head-on rigor verdicts (judge: Gemini 3.1 Pro). We scoped this scan to three problems f...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.