LUIVITON: Learned Universal Interoperable VIrtual Try-ON
Pith reviewed 2026-05-21 21:56 UTC · model grok-4.3
The pith
A virtual try-on system uses SMPL as a proxy to automatically fit complex garments onto diverse posed humanoids without shared templates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
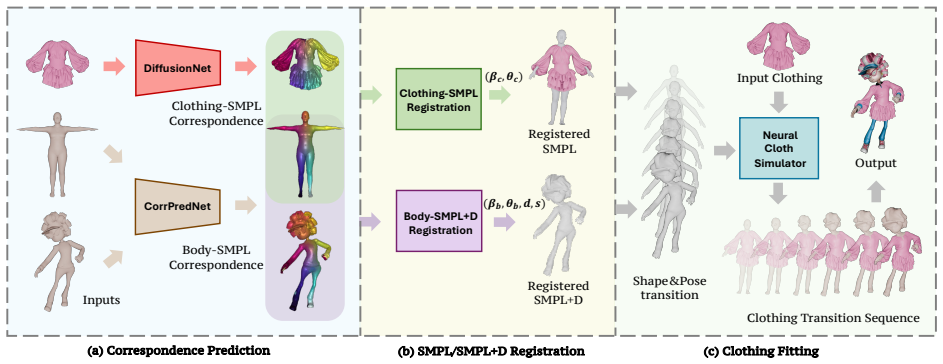
By treating SMPL as an intermediate proxy, the system solves clothing-to-SMPL partial alignment with a geometry-driven correspondence model and body-to-SMPL alignment with a diffusion model that uses multi-view appearance features from a pretrained 2D foundation model. These correspondences allow registration of SMPL and SMPL+D to both the source garment and target body, followed by physically simulated fitting that transfers the garment along a smooth transition path to produce plausible draping.
What carries the argument
SMPL as an intermediate proxy that splits the problem into geometry-driven clothing-to-SMPL alignment and diffusion-based body-to-SMPL alignment using multi-view consistent features.
If this is right
- High-quality 3D clothing fittings become possible without any human labor or access to 2D sewing patterns.
- The same pipeline supports fast post-draping adjustment of clothing size on the target character.
- Physically plausible results are obtained even on complex non-manifold garment meshes and stylized humanoid bodies.
- Existing real-world 3D garment assets can be reused at scale across characters that share no rigging or topology.
Where Pith is reading between the lines
- The two-stage proxy could be adapted to transfer other 3D accessories such as props or armor in animation pipelines.
- Replacing the diffusion step with a faster feed-forward network might enable interactive editing sessions in design tools.
- Testing the method on animal-like or mechanical bodies beyond humanoids would reveal how far the SMPL proxy generalizes.
Load-bearing premise
That SMPL can serve as a reliable intermediate proxy for partial-to-complete alignment and large pose/shape variation without requiring dense correspondences or shared templates between garments and target bodies.
What would settle it
A test case where the system produces visibly implausible folds or intersections when fitting a non-manifold multi-layer garment onto a cartoon character in an extreme pose would falsify the claim of reliable automated fitting across topologies and stylizations.
Figures












read the original abstract
To enable large-scale reuse of real-world 3D assets, where garments and characters rarely share skeletons, templates, or dense correspondences, we present a fully automated virtual try-on system that dresses complex, multi-layer garments onto diverse, arbitrarily posed humanoids. Our key idea is to use SMPL as an intermediate proxy and decompose clothing-to-body transfer into two correspondence tasks with distinct challenges: (1) clothing-to-SMPL (partial-to-complete alignment) and (2) body-to-SMPL (large pose/shape variation and stylization). We address clothing-to-SMPL using a geometry-driven correspondence model, and introduce a diffusion-based body-to-SMPL correspondence approach that leverages multi-view consistent appearance features together with a pretrained 2D foundation model. Using these correspondences, we register SMPL/SMPL+D (Displacement) to the garment and target body and then perform simulator-driven fitting by transferring the garment along a smooth SMPL-to-SMPL+D transition, producing physically plausible draping on the target. Our system handles complex garment topology (including non-manifold meshes) and generalizes to a wide range of humanoid characters (e.g., humans, robots, cartoons, and creatures) while remaining computationally practical. Upon draping, our system also supports fast customization of clothing size. We show that our system can produce high-quality 3D clothing fittings without any human labor, even when 2D clothing sewing patterns are not available. Our project page is: https://cao-cong0.github.io/LUIVITON-Learned-Universal-Interoperable-VIrtual-Try-ON/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents LUIVITON, a fully automated virtual try-on pipeline that dresses complex multi-layer garments (including non-manifold meshes) onto diverse, arbitrarily posed humanoids by using SMPL as an intermediate proxy. The transfer is decomposed into (1) clothing-to-SMPL partial-to-complete alignment via a geometry-driven correspondence model and (2) body-to-SMPL alignment for large pose/shape/stylization variation via a diffusion model that incorporates multi-view consistent appearance features and a pretrained 2D foundation model. These correspondences enable SMPL/SMPL+D registration followed by simulator-driven fitting along a smooth SMPL-to-SMPL+D transition to produce physically plausible draping; the system also supports fast size customization and claims to operate without sewing patterns or human labor.
Significance. If the generalization and physical-plausibility claims hold, the work would be significant for large-scale reuse of real-world 3D garment assets across characters that lack shared skeletons, templates, or dense correspondences. The explicit decomposition into two distinct correspondence problems, the integration of pretrained 2D models with 3D simulation, and the handling of non-manifold topology are technically interesting strengths that could influence downstream applications in animation, gaming, and virtual fashion.
major comments (2)
- [Abstract] Abstract: The claim that the system generalizes to robots, cartoons, and creatures 'without requiring dense correspondences or shared templates' is load-bearing for the central interoperability result, yet the abstract supplies no explicit mechanism (e.g., loss terms, architectural choices, or regularization) that would guarantee reliable body-to-SMPL alignment when target geometry deviates strongly from SMPL topology and proportions. Errors at this step would propagate through SMPL/SMPL+D registration and simulator fitting, directly undermining the physical-plausibility guarantee.
- [Abstract] Abstract: No quantitative results, error analysis, ablation studies, or baseline comparisons are reported despite repeated assertions of 'high-quality 3D clothing fittings' and 'computational practicality.' This absence prevents assessment of whether the diffusion-based body-to-SMPL step or the simulator-driven fitting actually delivers the claimed robustness on non-humanoid stylizations.
minor comments (1)
- [Abstract] Abstract: The project page is referenced but the manuscript should be self-contained; key implementation details (network architectures, training data, registration objective, simulator parameters) should be summarized or placed in a methods section to allow reviewers to evaluate the pipeline without external resources.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential significance of LUIVITON for interoperable 3D asset reuse. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the system generalizes to robots, cartoons, and creatures 'without requiring dense correspondences or shared templates' is load-bearing for the central interoperability result, yet the abstract supplies no explicit mechanism (e.g., loss terms, architectural choices, or regularization) that would guarantee reliable body-to-SMPL alignment when target geometry deviates strongly from SMPL topology and proportions. Errors at this step would propagate through SMPL/SMPL+D registration and simulator fitting, directly undermining the physical-plausibility guarantee.
Authors: The abstract summarizes the core technical contribution at a high level: a diffusion-based body-to-SMPL correspondence model that incorporates multi-view consistent appearance features extracted via a pretrained 2D foundation model. This design enables robust alignment under large pose, shape, and stylization deviations (including non-SMPL topologies) by operating in a learned feature space rather than relying on explicit geometric templates or dense correspondences. Full architectural details, training objectives, and regularization are provided in Section 3.2 of the manuscript. We maintain that the abstract-level description is appropriate for the format while the body supplies the requested mechanisms; we do not believe further expansion of the abstract is required. revision: no
-
Referee: [Abstract] Abstract: No quantitative results, error analysis, ablation studies, or baseline comparisons are reported despite repeated assertions of 'high-quality 3D clothing fittings' and 'computational practicality.' This absence prevents assessment of whether the diffusion-based body-to-SMPL step or the simulator-driven fitting actually delivers the claimed robustness on non-humanoid stylizations.
Authors: We agree that quantitative support strengthens the claims. The manuscript currently emphasizes qualitative results and visual comparisons across diverse humanoids (including robots, cartoons, and creatures) to demonstrate fitting quality and physical plausibility. In the revised version we will add quantitative error metrics on correspondence accuracy, ablation studies isolating the diffusion and simulation components, and baseline comparisons to better substantiate robustness and practicality on non-humanoid targets. revision: yes
Circularity Check
No circularity: derivation relies on external pretrained models and simulation
full rationale
The paper's pipeline decomposes clothing transfer into clothing-to-SMPL (geometry-driven correspondence) and body-to-SMPL (diffusion model with multi-view features plus pretrained 2D foundation model), followed by SMPL/SMPL+D registration and simulator-driven fitting. These steps are constructed from independent external components rather than self-referential definitions, fitted parameters renamed as predictions, or load-bearing self-citations. The abstract and description present a forward-engineered system for generalization without dense correspondences, with no equations or claims that reduce by construction to the inputs. This is a standard non-circular proposal of a learned pipeline.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SMPL provides a sufficient intermediate representation for arbitrary garments and characters
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We use SMPL as an intermediate proxy and decompose clothing-to-body transfer into two correspondence tasks: (1) clothing-to-SMPL (partial-to-complete alignment) and (2) body-to-SMPL (large pose/shape variation and stylization). We address clothing-to-SMPL using a geometry-driven correspondence model, and introduce a diffusion-based body-to-SMPL correspondence approach that leverages multi-view consistent appearance features together with a pretrained 2D foundation model.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We adopt a learning-based correspondence network, DiffusionNet [50], which has been shown to be highly effective in partial-to-complete correspondence predictions in connection with functional map approaches.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Zero-shot 3d shape correspon- dence
Ahmed Abdelreheem, Abdelrahman Eldesokey, Maks Ovs- janikov, and Peter Wonka. Zero-shot 3d shape correspon- dence. InSIGGRAPH Asia 2023 Conference Papers, pages 1–11, 2023. 2
work page 2023
-
[2]
Yonathan Aflalo, Anastasia Dubrovina, and Ron Kimmel. Spectral generalized multi-dimensional scaling.Interna- tional Journal of Computer Vision, 118:380–392, 2016. 2
work page 2016
-
[3]
3d garment positioning using hermite radial basis functions.Virtual Reality, pages 1–28, 2022
Abderrazzak Ait Mouhou, Abderrahim Saaidi, Majid Ben Yakhlef, and Khalid Abbad. 3d garment positioning using hermite radial basis functions.Virtual Reality, pages 1–28, 2022. 3
work page 2022
- [4]
-
[5]
Hybrid functional maps for crease-aware non- isometric shape matching
Lennart Bastian, Yizheng Xie, Nassir Navab, and Zorah L¨ahner. Hybrid functional maps for crease-aware non- isometric shape matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3313–3323, 2024. 8
work page 2024
-
[6]
Hugo Bertiche, Meysam Madadi, and Sergio Escalera. Cloth3d: clothed 3d humans. InEuropean Conference on Computer Vision, pages 344–359. Springer, 2020. 6
work page 2020
-
[7]
Hugo Bertiche, Meysam Madadi, and Sergio Escalera. Pbns: physically based neural simulator for unsupervised garment pose space deformation.arXiv preprint arXiv:2012.11310,
-
[8]
Deepsd: Automatic deep skinning and pose space deformation for 3d garment animation
Hugo Bertiche, Meysam Madadi, Emilio Tylson, and Ser- gio Escalera. Deepsd: Automatic deep skinning and pose space deformation for 3d garment animation. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 5471–5480, 2021
work page 2021
-
[9]
Neu- ral cloth simulation.ACM Transactions on Graphics (TOG), 41(6):1–14, 2022
Hugo Bertiche, Meysam Madadi, and Sergio Escalera. Neu- ral cloth simulation.ACM Transactions on Graphics (TOG), 41(6):1–14, 2022. 3
work page 2022
-
[10]
Method for registration of 3-d shapes
Paul J Besl and Neil D McKay. Method for registration of 3-d shapes. InSensor fusion IV: control paradigms and data structures, pages 586–606, 1992. 2
work page 1992
-
[11]
Combining implicit func- tion learning and parametric models for 3d human recon- struction
Bharat Lal Bhatnagar, Cristian Sminchisescu, Christian Theobalt, and Gerard Pons-Moll. Combining implicit func- tion learning and parametric models for 3d human recon- struction. InEuropean Conference on Computer Vision, pages 311–329. Springer, 2020. 2
work page 2020
-
[12]
Davide Boscaini, Jonathan Masci, Emanuele Rodol `a, and Michael Bronstein. Learning shape correspondence with anisotropic convolutional neural networks.Advances in Neu- ral Information Processing Systems, 29, 2016. 2
work page 2016
-
[13]
Unsupervised Learning of Robust Spectral Shape Matching
Dongliang Cao, Paul Roetzer, and Florian Bernard. Unsu- pervised learning of robust spectral shape matching.arXiv preprint arXiv:2304.14419, 2023. 8
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Mitra, Mark Pauly, and Michael Wand
Will Chang, Hao Li, Niloy J. Mitra, Mark Pauly, and Michael Wand. Geometric registration for deformable shapes. InEu- rographics 2010: Tutorial Notes, 2010. 2
work page 2010
-
[15]
Mitra, Mark Pauly, Szymon Rusinkiewicz, and Michael Wand
Will Chang, Hao Li, Niloy J. Mitra, Mark Pauly, Szymon Rusinkiewicz, and Michael Wand. Computing correspon- dences in geometric data sets. InEurographics 2011: Tuto- rial Notes, 2011
work page 2011
-
[16]
Mitra, Mark Pauly, and Michael Wand
Will Chang, Hao Li, Niloy J. Mitra, Mark Pauly, and Michael Wand. Dynamic geometry processing. InEurographics 2012: Tutorial Notes, 2012. 2
work page 2012
-
[17]
Drapenet: Garment generation and self- supervised draping
Luca De Luigi, Ren Li, Beno ˆıt Guillard, Mathieu Salzmann, and Pascal Fua. Drapenet: Garment generation and self- supervised draping. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 1451–1460, 2023. 2, 3, 6
work page 2023
-
[18]
Deep geometric functional maps: Robust feature learning for shape correspondence
Nicolas Donati, Abhishek Sharma, and Maks Ovsjanikov. Deep geometric functional maps: Robust feature learning for shape correspondence. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8592–8601, 2020. 2
work page 2020
-
[19]
Deep geometric maps: Robust feature learning for shape cor- respondence.CVPR, 2020
Nicolas Donati, Abhishek Sharma, and Maks Ovsjanikov. Deep geometric maps: Robust feature learning for shape cor- respondence.CVPR, 2020. 8
work page 2020
-
[20]
Diffusion 3d features (diff3f): Decorating untextured shapes with distilled semantic features
Niladri Shekhar Dutt, Sanjeev Muralikrishnan, and Niloy J Mitra. Diffusion 3d features (diff3f): Decorating untextured shapes with distilled semantic features. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4494–4504, 2024. 2, 3, 4, 8
work page 2024
-
[21]
Deblurring and denois- ing of maps between shapes
Danielle Ezuz and Mirela Ben-Chen. Deblurring and denois- ing of maps between shapes. InComputer Graphics Forum, pages 165–174. Wiley Online Library, 2017. 2
work page 2017
-
[22]
Marvelous designer: 3d clothing de- sign software, 2025
CLO Virtual Fashion. Marvelous designer: 3d clothing de- sign software, 2025. Accessed: 2025-01-12. 2, 3, 10
work page 2025
-
[23]
Hood: Hierarchical graphs for generalized modelling of clothing dynamics
Artur Grigorev, Michael J Black, and Otmar Hilliges. Hood: Hierarchical graphs for generalized modelling of clothing dynamics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16965– 16974, 2023. 3
work page 2023
-
[24]
ContourCraft: Learning to resolve intersections in neural multi-garment simulations
Artur Grigorev, Giorgio Becherini, Michael Black, Ot- mar Hilliges, and Bernhard Thomaszewski. ContourCraft: Learning to resolve intersections in neural multi-garment simulations. InACM SIGGRAPH 2024 Conference Papers, pages 1–10, 2024. 3, 6
work page 2024
-
[25]
Luchen Huang and Ruoyu Yang. Automatic alignment for virtual fitting using 3d garment stretching and human body relocation.The Visual Computer, 32:705–715, 2016. 3
work page 2016
-
[26]
Robust 3d shape correspondence in the spectral domain
Varun Jain and Hao Zhang. Robust 3d shape correspondence in the spectral domain. InIEEE International Conference on Shape Modeling and Applications, pages 19–19. IEEE,
-
[27]
GarmentCodeData: A dataset of 3D made-to-measure garments with sewing pat- terns
Maria Korosteleva, Timur Levent Kesdogan, Fabian Kem- per, Stephan Wenninger, Jasmin Koller, Yuhan Zhang, Mario Botsch, and Olga Sorkine-Hornung. GarmentCodeData: A dataset of 3D made-to-measure garments with sewing pat- terns. InEuropean Conference on Computer Vision, 2024. 7
work page 2024
-
[28]
Global corre- spondence optimization for non-rigid registration of depth scans
Hao Li, Robert W Sumner, and Mark Pauly. Global corre- spondence optimization for non-rigid registration of depth scans. InComputer Graphics Forum, pages 1421–1430,
-
[29]
Robust single-view geometry and motion reconstruction
Hao Li, Bart Adams, Leonidas J Guibas, and Mark Pauly. Robust single-view geometry and motion reconstruction. ACM Transactions on Graphics (ToG), 28(5):1–10, 2009. 2
work page 2009
-
[30]
Fitting 3d garment models onto individual human mod- els.Computers & graphics, 34(6):742–755, 2010
Jituo Li, Juntao Ye, Yangsheng Wang, Li Bai, and Guodong Lu. Fitting 3d garment models onto individual human mod- els.Computers & graphics, 34(6):742–755, 2010. 3
work page 2010
-
[31]
Ren Li, Beno ˆıt Guillard, and Pascal Fua. Isp: Multi-layered garment draping with implicit sewing patterns.Advances in Neural Information Processing Systems, 36, 2024. 2, 3, 6
work page 2024
-
[32]
3d clothing fitting based on the geometric feature matching
Zhong Li, Xiaogang Jin, Brian Barsky, and Jun Liu. 3d clothing fitting based on the geometric feature matching. In IEEE International Conference on Computer-Aided Design and Computer Graphics, pages 74–80, 2009. 3
work page 2009
-
[33]
Deep functional maps: Structured prediction for dense shape correspondence
Or Litany, Tal Remez, Emanuele Rodola, Alex Bronstein, and Michael Bronstein. Deep functional maps: Structured prediction for dense shape correspondence. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 5659–5667, 2017. 2
work page 2017
-
[34]
Text-guided texturing by synchronized multi-view diffusion
Yuxin Liu, Minshan Xie, Hanyuan Liu, and Tien-Tsin Wong. Text-guided texturing by synchronized multi-view diffusion. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11,
work page 2024
-
[35]
Smpl: A skinned multi- person linear model
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi- person linear model. InSeminal Graphics Papers: Pushing the Boundaries, pages 851–866. 2023. 2
work page 2023
-
[36]
Learn- ing to dress 3d people in generative clothing
Qianli Ma, Jinlong Yang, Anurag Ranjan, Sergi Pujades, Gerard Pons-Moll, Siyu Tang, and Michael J Black. Learn- ing to dress 3d people in generative clothing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 6469–6478, 2020. 3
work page 2020
-
[37]
Memory-scalable and simplified functional map learning
Robin Magnet and Maks Ovsjanikov. Memory-scalable and simplified functional map learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4041–4050, 2024. 2
work page 2024
-
[38]
Nicp: neural icp for 3d human registration at scale
Riccardo Marin, Enric Corona, and Gerard Pons-Moll. Nicp: neural icp for 3d human registration at scale. InEuropean Conference on Computer Vision, pages 265–285. Springer,
-
[39]
Rahul Narain, Armin Samii, and James F O’brien. Adaptive anisotropic remeshing for cloth simulation.ACM transac- tions on graphics (TOG), 31(6):1–10, 2012. 3
work page 2012
-
[40]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 2, 3, 4, 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Maks Ovsjanikov, Mirela Ben-Chen, Justin Solomon, Adrian Butscher, and Leonidas Guibas. Functional maps: a flexible representation of maps between shapes.ACM Transactions on Graphics (TOG), 31(4):1–11, 2012. 2
work page 2012
-
[42]
Predicting loose-fitting garment defor- mations using bone-driven motion networks
Xiaoyu Pan, Jiaming Mai, Xinwei Jiang, Dongxue Tang, Jingxiang Li, Tianjia Shao, Kun Zhou, Xiaogang Jin, and Dinesh Manocha. Predicting loose-fitting garment defor- mations using bone-driven motion networks. InACM SIG- GRAPH 2022 Conference Papers, pages 1–10, 2022. 3
work page 2022
-
[43]
Tailornet: Predicting clothing in 3d as a function of human pose, shape and garment style
Chaitanya Patel, Zhouyingcheng Liao, and Gerard Pons- Moll. Tailornet: Predicting clothing in 3d as a function of human pose, shape and garment style. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7365–7375, 2020. 2, 3
work page 2020
-
[44]
Gerard Pons-Moll, Sergi Pujades, Sonny Hu, and Michael J Black. Clothcap: Seamless 4d clothing capture and retar- geting.ACM Transactions on Graphics (TOG), 36(4):1–15,
-
[45]
Partial functional corre- spondence
Emanuele Rodol `a, Luca Cosmo, Michael M Bronstein, An- drea Torsello, and Daniel Cremers. Partial functional corre- spondence. InComputer Graphics Forum, pages 222–236. Wiley Online Library, 2017. 2
work page 2017
-
[46]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022. 3
work page 2022
-
[47]
Learning-based animation of clothing for virtual try-on
Igor Santesteban, Miguel A Otaduy, and Dan Casas. Learning-based animation of clothing for virtual try-on. In Computer Graphics Forum, pages 355–366. Wiley Online Library, 2019. 3
work page 2019
-
[48]
Self-supervised collision handling via generative 3d garment models for virtual try-on
Igor Santesteban, Nils Thuerey, Miguel A Otaduy, and Dan Casas. Self-supervised collision handling via generative 3d garment models for virtual try-on. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11763–11773, 2021
work page 2021
-
[49]
Snug: Self-supervised neural dynamic garments
Igor Santesteban, Miguel A Otaduy, and Dan Casas. Snug: Self-supervised neural dynamic garments. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8140–8150, 2022. 3
work page 2022
-
[50]
Nicholas Sharp, Souhaib Attaiki, Keenan Crane, and Maks Ovsjanikov. Diffusionnet: Discretization agnostic learning on surfaces.ACM Transactions on Graphics (TOG), 41(3): 1–16, 2022. 3, 8
work page 2022
-
[51]
Guangyuan Shi, Chengying Gao, Dong Wang, and Zhuo Su. Automatic 3d virtual fitting system based on skeleton driv- ing.The Visual Computer, 37:1075–1088, 2021. 3
work page 2021
-
[52]
Deepdraper: Fast and accurate 3d garment draping over a 3d human body
Lokender Tiwari and Brojeshwar Bhowmick. Deepdraper: Fast and accurate 3d garment draping over a 3d human body. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1416–1426, 2021. 2
work page 2021
-
[53]
Dense human body correspondences using con- volutional networks
Lingyu Wei, Qixing Huang, Duygu Ceylan, Etienne V ouga, and Hao Li. Dense human body correspondences using con- volutional networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1544– 1553, 2016. 2, 4
work page 2016
-
[54]
Nannan Wu, Zhigang Deng, Yue Huang, Chen Liu, Dongliang Zhang, and Xiaogang Jin. A fast garment fitting algorithm using skeleton-based error metric.Computer Ani- mation and Virtual Worlds, 29(3-4):e1811, 2018. 3
work page 2018
-
[55]
3d human mesh regression with dense cor- respondence
Wang Zeng, Wanli Ouyang, Ping Luo, Wentao Liu, and Xi- aogang Wang. 3d human mesh regression with dense cor- respondence. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7054– 7063, 2020. 3
work page 2020
-
[56]
The stitched puppet: A graphical model of 3d human shape and pose
Silvia Zuffi and Michael J Black. The stitched puppet: A graphical model of 3d human shape and pose. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3537–3546, 2015. 2
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.