When Is Next-Token Prediction Useful? Marginalization, Ergodicity, Mixture Identifiability, Local Sufficiency, RAG, Tools, and Programming
Pith reviewed 2026-05-25 05:00 UTC · model grok-4.3
The pith
Next-token prediction estimates the marginal text-only law and is useful only when observed prefixes are approximately sufficient statistics for latent circumstances.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A model trained on realized token trajectories receives sampled continuations and therefore estimates the marginal text-only process rather than the full conditional law; this marginal is useful for prediction only when the observed prefix is an approximately sufficient statistic for the latent circumstances relevant to continuation, which holds when residual conditional mutual information is small.
What carries the argument
The three-way distinction among the full conditional language process, the marginal text-only process, and the model-induced distribution, with local sufficiency of the observed prefix serving as the condition for usefulness.
If this is right
- RAG improves next-token prediction by supplying additional context that reduces residual mutual information with omitted circumstances.
- Tool use functions as a conditional sufficiency device that augments the observed text with external information.
- In heterogeneous training corpora the identifiability of mixture components depends on the same sufficiency conditions.
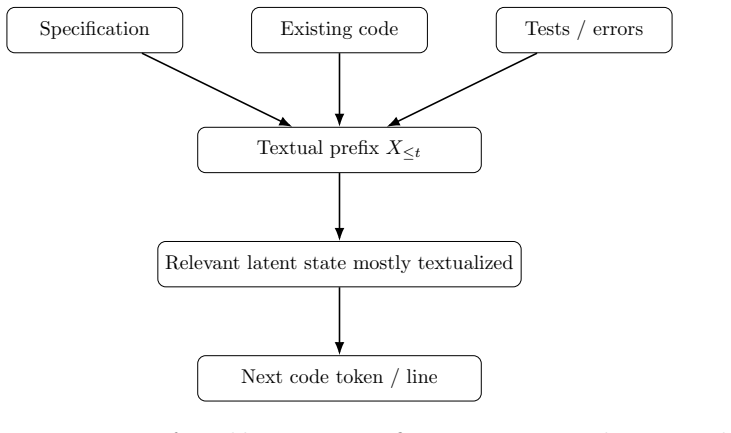
- Programming tasks require richer context because code continuations depend on non-textual goals and constraints.
Where Pith is reading between the lines
- If the sufficiency condition fails, scaling data volume alone will not close the gap between marginal and conditional performance.
- Tasks with rapidly changing external circumstances may require explicit conditioning mechanisms beyond pure next-token training.
- The same marginal-versus-conditional distinction applies to any sequential prediction setting where observations are generated under varying latent regimes.
Load-bearing premise
Real language corpora can be meaningfully analyzed as samples from a stationary ergodic process whose marginal can be estimated from finite observed trajectories.
What would settle it
A direct measurement showing that next-token prediction error remains high even after conditioning on prefixes that are information-theoretically sufficient for the relevant latent circumstances would falsify the usefulness criterion.
Figures

read the original abstract
Language models trained on observed sequences are often described as learning the conditional distribution of the next token given previous tokens. This description is only conditionally correct. A model trained on realized token trajectories does not observe full conditional laws; it receives sampled continuations. Moreover, real language generation is conditioned not only on previous words but also on non-textual circumstances: facts, events, intentions, goals, beliefs, social context, and task-specific constraints. This paper distinguishes three objects that are often conflated: the full conditional language process conditioned on latent circumstances, the marginal text-only process obtained by integrating those circumstances out, and the model-induced distribution learned from finite observed corpora. The paper argues that interpreting model training as estimating the marginal text-only law requires strong assumptions of stationarity, representativeness, and ergodicity, assumptions that are standard in statistical estimation but problematic when applied to heterogeneous language corpora. Even if these assumptions hold, the marginal text-only law is useful only when the observed prefix is an approximately sufficient statistic for the latent circumstances relevant to continuation. In information-theoretic terms, usefulness requires that the residual conditional mutual information between the next token and the omitted circumstances, given the observed text, be small. The paper then extends this argument to heterogeneous training corpora. Finally, the paper interprets Retrieval Augmented Generation (RAG) and tool use as conditional sufficiency devices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper distinguishes the full conditional language process (conditioned on latent circumstances), the marginal text-only process (circumstances integrated out), and the model distribution learned from finite corpora. It argues that next-token prediction training estimates the marginal only under stationarity, representativeness, and ergodicity assumptions (problematic for heterogeneous language data) and is useful only when the observed prefix is approximately sufficient for the relevant latent circumstances, i.e., when residual conditional mutual information I(next token; circumstances | text) is small. The argument is extended to heterogeneous corpora, and RAG/tool use is interpreted as providing conditional sufficiency.
Significance. If the framework holds, it supplies a clean information-theoretic lens for understanding the scope and limits of next-token training, the mismatch between language data and standard statistical assumptions, and the mechanistic role of retrieval and tools. This could usefully inform both theoretical analyses of LM capabilities and practical system design.
major comments (1)
- [Abstract] Abstract: the usefulness claim rests on the residual conditional mutual information being small, yet the manuscript supplies neither a formal derivation of this condition from the chain rule nor any concrete bounds or corpus examples showing when the term is plausibly negligible; without such support the central practical implication remains untested.
minor comments (1)
- The extension to heterogeneous training corpora is announced but receives no detailed treatment or examples in the provided text; a short dedicated subsection would clarify how the stationarity/ergodicity issues compound across domains.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on the manuscript. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the usefulness claim rests on the residual conditional mutual information being small, yet the manuscript supplies neither a formal derivation of this condition from the chain rule nor any concrete bounds or corpus examples showing when the term is plausibly negligible; without such support the central practical implication remains untested.
Authors: We agree that the abstract and surrounding discussion would be strengthened by an explicit derivation and supporting illustrations. The key condition follows from the chain rule: H(next token | text) = H(next token | text, circumstances) + I(next token; circumstances | text). When the residual mutual information term is small, the marginal next-token law given text approximates the full conditional law. We will insert this derivation into the revised abstract and add a short subsection with illustrative cases (e.g., technical prose versus open-ended dialogue) showing domains where the term is plausibly negligible. These changes will be incorporated in the next version. revision: yes
Circularity Check
No significant circularity
full rationale
The paper distinguishes the full conditional process, marginal text-only law, and learned model via standard information-theoretic definitions (chain rule, conditional mutual information, sufficiency). It states assumptions of stationarity/ergodicity/representativeness explicitly as requirements for interpreting training as marginal estimation, without deriving any quantity from fitted parameters or self-citations. RAG/tool-use are positioned as mechanisms to reduce residual I(next token; circumstances | text), following directly from the definitions without reduction to inputs. No equations or claims reduce by construction to the paper's own outputs; the argument is self-contained against external statistical concepts.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Language generation is conditioned on latent non-textual circumstances (facts, events, intentions, goals, beliefs, social context).
- domain assumption Training corpora can be treated under assumptions of stationarity, representativeness, and ergodicity for marginal estimation.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
interpreting model training as estimating the marginal text-only law requires strong assumptions of stationarity, representativeness, and ergodicity... residual conditional mutual information I(Xt+1;Zt | X≤t)≈0
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
mixture conditional pmix(xt+1 | x≤t) = Σ p(k|x≤t) pk(xt+1 | x≤t)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.