CORTEX: Token-Level Hallucination Detection in RAG via Comparative Internal Representations
Pith reviewed 2026-07-01 06:12 UTC · model grok-4.3
The pith
CORTEX identifies ungrounded tokens in RAG by comparing an LLM's internal representations with and without the retrieved documents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
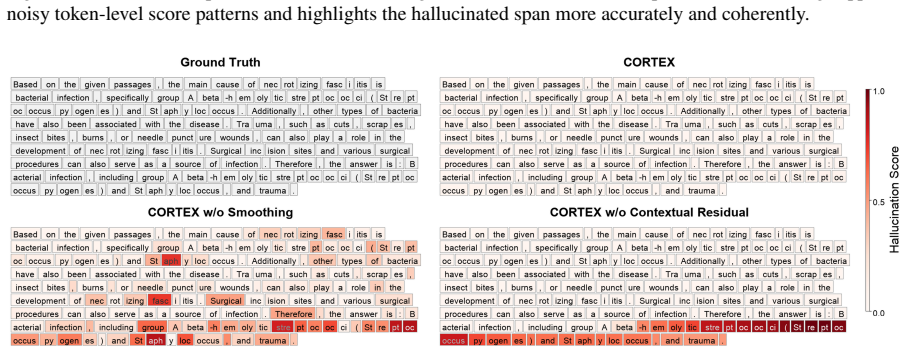
CORTEX identifies ungrounded tokens by comparing the internal representations of an LLM under two conditions—with and without the retrieved documents. It incorporates the propagation of document-grounded information through preceding tokens to reduce false positives and applies a post-processing smoothing step that models the persistence of hallucination labels over contiguous spans.
What carries the argument
Comparison of internal representations generated with versus without retrieved documents, extended by propagation of grounded effects across tokens and span-smoothing post-processing.
If this is right
- Token-level hallucination detection accuracy improves over prior methods on standard RAG benchmarks.
- The three components—comparative representations, propagation tracking, and smoothing—each add measurable performance gains.
- Fine-grained localization becomes possible in long-form RAG outputs where hallucinations appear in isolated spans.
- The gains hold across multiple large language models and evaluation sets.
Where Pith is reading between the lines
- Similar internal-state comparisons could be tested on generation tasks that do not use explicit retrieval.
- Feedback from such detectors during training might encourage models to strengthen document influence on grounded tokens.
- The method could be inserted into generation pipelines to flag and revise emerging hallucinations in real time.
Load-bearing premise
Tokens grounded in the retrieved documents are more strongly influenced by those documents in the model's internal representations than hallucinated tokens are.
What would settle it
If the difference in internal representations between the with-document and without-document conditions shows no reliable separation between known grounded tokens and known hallucinated tokens on a labeled benchmark, the core comparison signal would fail.
Figures




read the original abstract
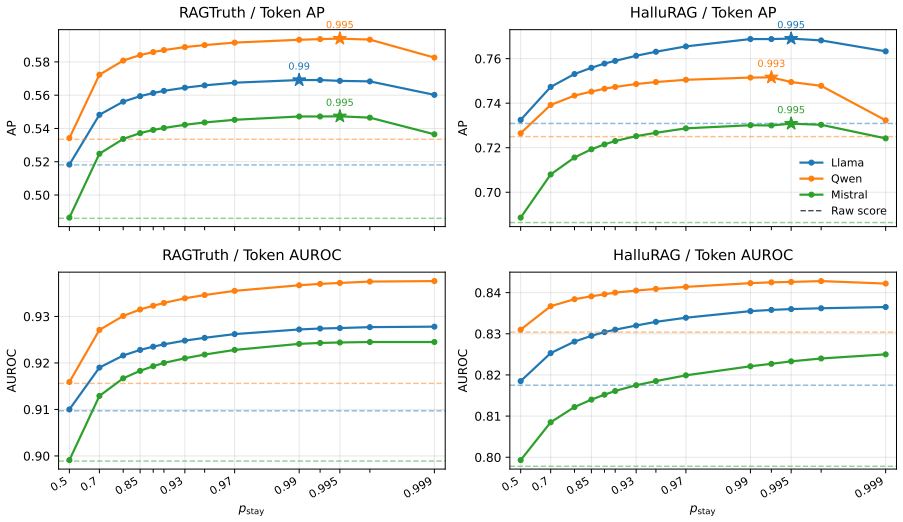
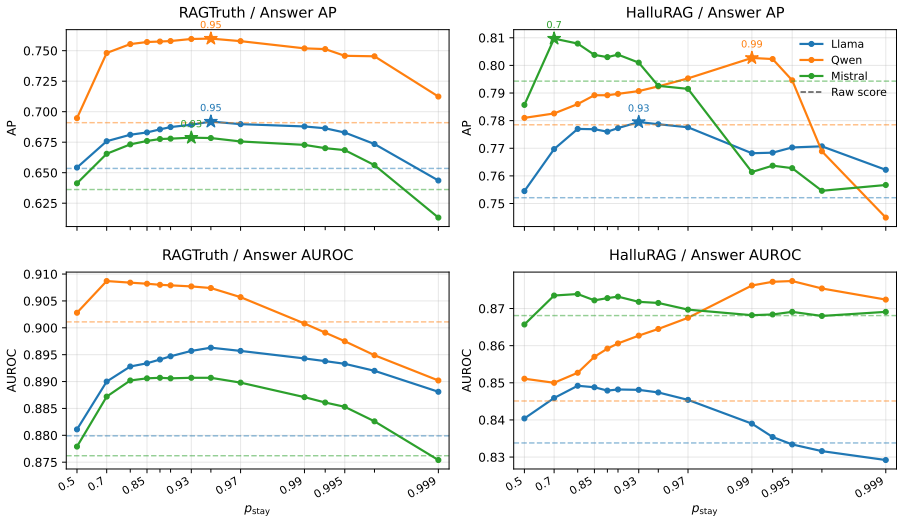
In this paper, we propose CORTEX, a token-level hallucination detection method for Retrieval-Augmented Generation (RAG). In long-form RAG outputs, hallucinations often arise in localized spans rather than throughout an entire response. CORTEX therefore identifies ungrounded content at the token level, enabling fine-grained localization of hallucinations. The key intuition behind CORTEX is that tokens grounded in retrieved documents should be more strongly influenced by those documents than hallucinated tokens. To capture this document-induced effect, CORTEX compares internal representations of a large language model (LLM) under two conditions: with and without the retrieved documents. Instead of relying solely on each token's immediate sensitivity to the retrieved documents, CORTEX also leverages the propagation of document-grounded information through preceding tokens, reducing false positives for tokens whose evidence has already been absorbed into the context. Finally, CORTEX applies post-processing smoothing step that models the tendency of hallucination labels to persist over contiguous spans, reducing local noise and encouraging span-consistent predictions. Experiments on two RAG benchmarks and three LLMs show that CORTEX substantially improves token-level hallucination detection, with each component consistently contributing to performance gains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CORTEX, a token-level hallucination detection method for RAG that compares an LLM's internal representations under with-document and without-document conditions. It incorporates propagation of document-grounded information through preceding tokens and a post-processing smoothing step to encourage span-consistent predictions. Experiments on two RAG benchmarks and three LLMs are claimed to show substantial improvements, with each component contributing to gains.
Significance. If the core comparative mechanism can be made reliable, the approach would provide a novel internal-representation-based signal for localizing hallucinations at the token level in long-form RAG outputs, potentially complementing existing logit- or embedding-based detectors.
major comments (2)
- [Approach (abstract and method description)] The central mechanism requires per-token comparison of internal representations between the with-document and without-document generations. However, removing the retrieved documents frequently produces a different token sequence, so the positions no longer align to the same content. No explicit alignment procedure (forced decoding, prefix-constrained generation, or extraction along the with-document trajectory) is described, rendering the difference signal undefined for most tokens. This directly undermines the claim that the comparative signal distinguishes grounded from hallucinated tokens.
- [Experiments (abstract)] The abstract asserts that 'each component consistently contributing to performance gains' and that CORTEX 'substantially improves' detection, yet supplies no quantitative metrics, baselines, ablation tables, or dataset statistics. Without these, the data-to-claim link cannot be evaluated and the contribution statements remain unevaluable.
minor comments (2)
- The abstract does not name the two RAG benchmarks or the three LLMs; these details should appear in the abstract or a dedicated experimental-setup paragraph.
- Notation for the two conditions (with vs. without documents) and for the representation vectors being compared should be introduced formally with symbols rather than prose only.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, indicating the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Approach (abstract and method description)] The central mechanism requires per-token comparison of internal representations between the with-document and without-document generations. However, removing the retrieved documents frequently produces a different token sequence, so the positions no longer align to the same content. No explicit alignment procedure (forced decoding, prefix-constrained generation, or extraction along the with-document trajectory) is described, rendering the difference signal undefined for most tokens. This directly undermines the claim that the comparative signal distinguishes grounded from hallucinated tokens.
Authors: We agree that the manuscript does not explicitly describe an alignment procedure between the two generation conditions, which leaves the per-token comparison underspecified. This is a genuine presentational gap. In the revised manuscript we will add a dedicated paragraph in Section 3.2 detailing the alignment method: we employ prefix-constrained decoding so that the without-document generation is forced to follow the exact token sequence produced by the with-document generation up to each comparison point. This ensures the internal-representation difference is computed on aligned positions. revision: yes
-
Referee: [Experiments (abstract)] The abstract asserts that 'each component consistently contributing to performance gains' and that CORTEX 'substantially improves' detection, yet supplies no quantitative metrics, baselines, ablation tables, or dataset statistics. Without these, the data-to-claim link cannot be evaluated and the contribution statements remain unevaluable.
Authors: The referee correctly notes that the abstract contains only qualitative claims without supporting numbers. Although abstracts are conventionally concise, we accept that the current wording makes the contribution statements difficult to evaluate. We will revise the abstract to include the primary quantitative results (F1 improvements on both benchmarks across the three LLMs) together with a brief reference to the ablation study and dataset sizes reported in Section 4. revision: yes
Circularity Check
No significant circularity; empirical method with independent validation
full rationale
The paper presents CORTEX as an empirical technique that compares LLM internal representations under with-document vs. without-document conditions, motivated by an explicit intuition and validated on external benchmarks. No equations, parameters, or predictions reduce to self-definition or fitted inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing. The derivation chain consists of design choices followed by experimental measurement, which remains falsifiable against held-out data and does not collapse into its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tokens grounded in retrieved documents should be more strongly influenced by those documents than hallucinated tokens.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Manakul, Potsawee and Liusie, Adian and Gales, Mark , booktitle =. 2023 , publisher =. doi:10.18653/v1/2023.emnlp-main.557 , pages =
-
[9]
From Generation to Judgment: Opportunities and Challenges of LLM -as-a-judge
Li, Dawei and Jiang, Bohan and Huang, Liangjie and Beigi, Alimohammad and Zhao, Chengshuai and Tan, Zhen and Bhattacharjee, Amrita and Jiang, Yuxuan and Chen, Canyu and Wu, Tianhao and Shu, Kai and Cheng, Lu and Liu, Huan. From Generation to Judgment: Opportunities and Challenges of LLM -as-a-judge. Proceedings of the 2025 Conference on Empirical Methods ...
-
[10]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , url =
2023
-
[11]
RAGA s: Automated Evaluation of Retrieval Augmented Generation
Es, Shahul and James, Jithin and Espinosa Anke, Luis and Schockaert, Steven. RAGA s: Automated Evaluation of Retrieval Augmented Generation. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations. 2024. doi:10.18653/v1/2024.eacl-demo.16
-
[12]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Sriramanan, Gaurang and Bharti, Siddhant and Sadasivan, Vinu Sankar and Saha, Shoumik and Kattakinda, Priyatham and Feizi, Soheil , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[13]
2025 , url =
Zhang, Zhenliang and Hu, Xinyu and Zhang, Huixuan and Zhang, Junzhe and Wan, Xiaojun , booktitle =. 2025 , url =
2025
-
[14]
Huang, Lei and Yu, Weijiang and Ma, Weitao and Zhong, Weihong and Feng, Zhangyin and Wang, Haotian and Chen, Qianglong and Peng, Weihua and Feng, Xiaocheng and Qin, Bing and Liu, Ting , title =. 2025 , publisher =. doi:10.1145/3703155 , journal =
-
[15]
2025 , journal=
Why Language Models Hallucinate , author=. 2025 , journal=
2025
-
[16]
2024 , url=
Retrieval-Augmented Generation for Large Language Models: A Survey , author=. 2024 , url=
2024
-
[17]
Rag-Fusion: A New Take on Retrieval Augmented Generation , volume=
Rackauckas, Zackary , year=. Rag-Fusion: A New Take on Retrieval Augmented Generation , volume=. International Journal on Natural Language Computing , publisher=. doi:10.5121/ijnlc.2024.13103 , number=
-
[18]
Proceedings of the 2021 International Conference on Learning Representations , year=
Uncertainty Estimation in Autoregressive Structured Prediction , author=. Proceedings of the 2021 International Conference on Learning Representations , year=
2021
-
[19]
The internal state of an LLM knows when it’s lying
Azaria, Amos and Mitchell, Tom , booktitle =. The Internal State of an. 2023 , publisher =. doi:10.18653/v1/2023.findings-emnlp.68 , pages =
-
[20]
Computing Research Repository , year=
HalluHard: A Hard Multi-Turn Hallucination Benchmark , author=. Computing Research Repository , year=
-
[21]
2024 , url =
Llama 3.1 Model Card , author=. 2024 , url =
2024
-
[22]
Qwen3: Think Deeper, Act Faster , url =
Qwen Team , year =. Qwen3: Think Deeper, Act Faster , url =
-
[23]
2025 , journal=
Qwen3 Technical Report , author=. 2025 , journal=
2025
-
[24]
2024 , journal=
The Llama 3 Herd of Models , author=. 2024 , journal=
2024
-
[25]
https://aclanthology.org/2024.acl-long.585/
Niu, Cheng and Wu, Yuanhao and Zhu, Juno and Xu, Siliang and Shum, KaShun and Zhong, Randy and Song, Juntong and Zhang, Tong , booktitle =. 2024 , url = "https://aclanthology.org/2024.acl-long.585/", publisher =
2024
-
[26]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Li, Junyi and Cheng, Xiaoxue and Zhao, Xin and Nie, Jian-Yun and Wen, Ji-Rong , editor =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =. doi:10.18653/v1/2023.emnlp-main.397 , pages =
-
[27]
The HalluRAG Dataset: Detecting Closed-Domain Hallucinations in RAG Applications Using an LLM's Internal States , journal=
Fabian Ridder and Malte Schilling , journal=. The HalluRAG Dataset: Detecting Closed-Domain Hallucinations in RAG Applications Using an LLM's Internal States , journal=. 2024 , volume=
2024
-
[28]
Zero-shot Persuasive Chatbots with
Furumai, Kazuaki and Legaspi, Roberto and Romero, Julio Cesar Vizcarra and Yamazaki, Yudai and Nishimura, Yasutaka and Semnani, Sina and Ikeda, Kazushi and Shi, Weiyan and Lam, Monica , booktitle =. Zero-shot Persuasive Chatbots with. 2024 , publisher =. doi:10.18653/v1/2024.findings-emnlp.656 , pages =
-
[29]
The Fourteenth International Conference on Learning Representations , year=
Toward Faithful Retrieval-Augmented Generation with Sparse Autoencoders , author=. The Fourteenth International Conference on Learning Representations , year=
-
[30]
2005 , publisher=
Inference in Hidden Markov Models , author=. 2005 , publisher=
2005
-
[31]
, title =
Rabiner, Lawrence R. , title =. Readings in Speech Recognition , pages =. 1990 , isbn =
1990
-
[32]
Rethinking Hallucinations: Correctness, Consistency, and Prompt Multiplicity
Ganesh, Prakhar and Shokri, Reza and Farnadi, Golnoosh. Rethinking Hallucinations: Correctness, Consistency, and Prompt Multiplicity. Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 1: Long Papers). 2026. doi:10.18653/v1/2026.eacl-long.327
-
[33]
Too Consistent to Detect: A Study of Self-Consistent Errors in LLM s
Tan, Hexiang and Sun, Fei and Liu, Sha and Su, Du and Cao, Qi and Chen, Xin and Wang, Jingang and Cai, Xunliang and Wang, Yuanzhuo and Shen, Huawei and Cheng, Xueqi. Too Consistent to Detect: A Study of Self-Consistent Errors in LLM s. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.238
-
[34]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , url =
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , url =. Advances in Neural Information Processing Systems , editor =
-
[35]
The Illusion of Progress: Re-evaluating Hallucination Detection in LLM s
Janiak, Denis and Binkowski, Jakub and Sawczyn, Albert and Gabrys, Bogdan and Shwartz-Ziv, Ravid and Kajdanowicz, Tomasz Jan. The Illusion of Progress: Re-evaluating Hallucination Detection in LLM s. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1761
-
[36]
Attention-guided Self-reflection for Zero-shot Hallucination Detection in Large Language Models
Liu, Qiang and Chen, Xinlong and Ding, Yue and Song, Bowen and Wang, Weiqiang and Wu, Shu and Wang, Liang. Attention-guided Self-reflection for Zero-shot Hallucination Detection in Large Language Models. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1063
-
[37]
H allu L ens: LLM Hallucination Benchmark
Bang, Yejin and Ji, Ziwei and Schelten, Alan and Hartshorn, Anthony and Fowler, Tara and Zhang, Cheng and Cancedda, Nicola and Fung, Pascale. H allu L ens: LLM Hallucination Benchmark. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1176
-
[38]
and McCallum, Andrew and Pereira, Fernando C
Lafferty, John D. and McCallum, Andrew and Pereira, Fernando C. N. , title =. Proceedings of the Eighteenth International Conference on Machine Learning , pages =. 2001 , isbn =
2001
-
[39]
Computing Research Repository , year=
GPT-4o System Card , author=. Computing Research Repository , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.