Towards Demystifying and Repairing LLM-in-the-Loop Vulnerabilities
Pith reviewed 2026-06-29 11:18 UTC · model grok-4.3
The pith
LLM-in-the-loop vulnerabilities are more difficult to repair than conventional software bugs, with prompt injection cases repaired correctly only 28.57 percent of the time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
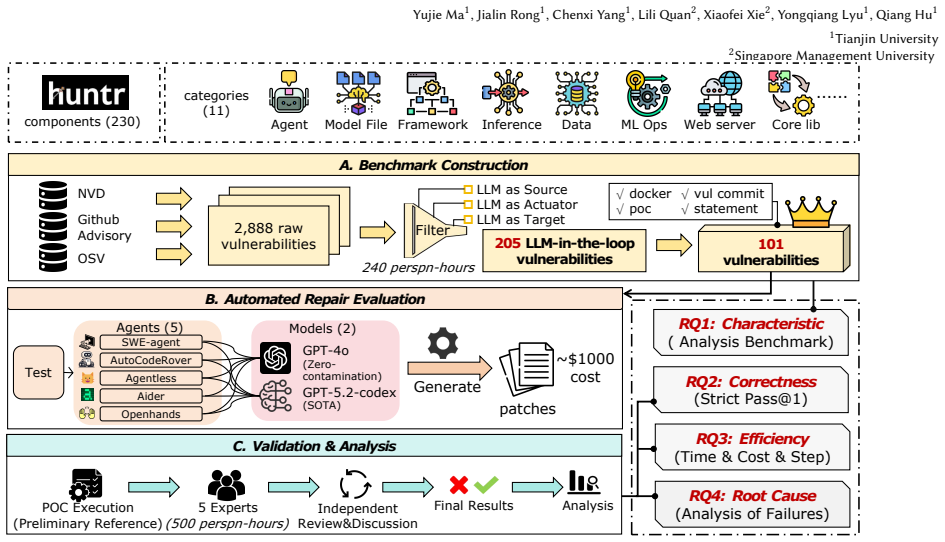
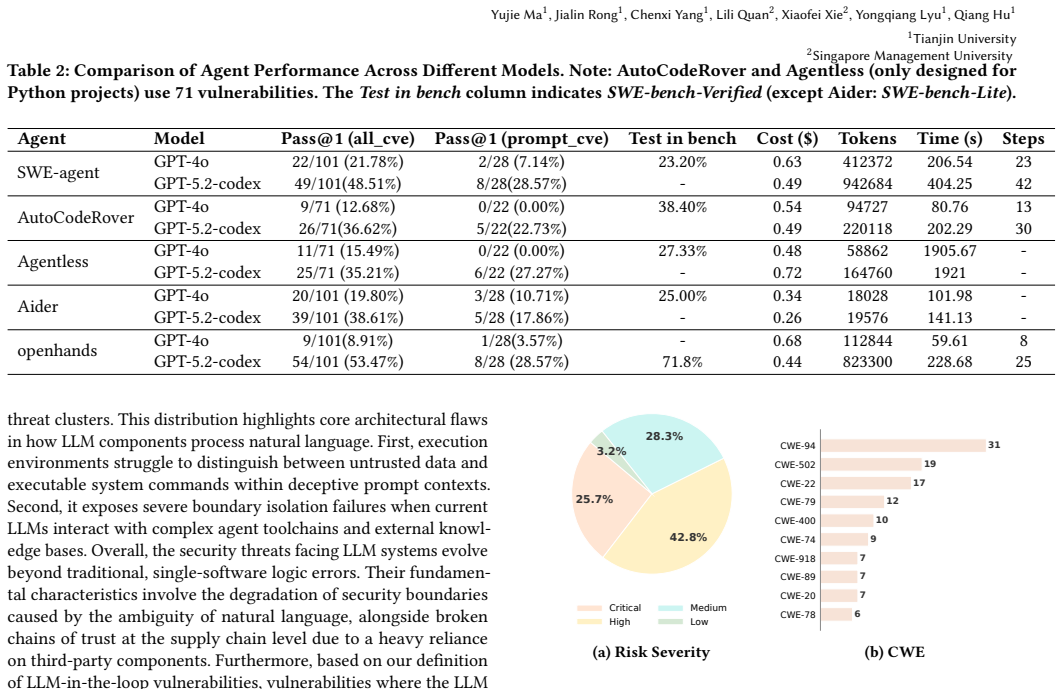
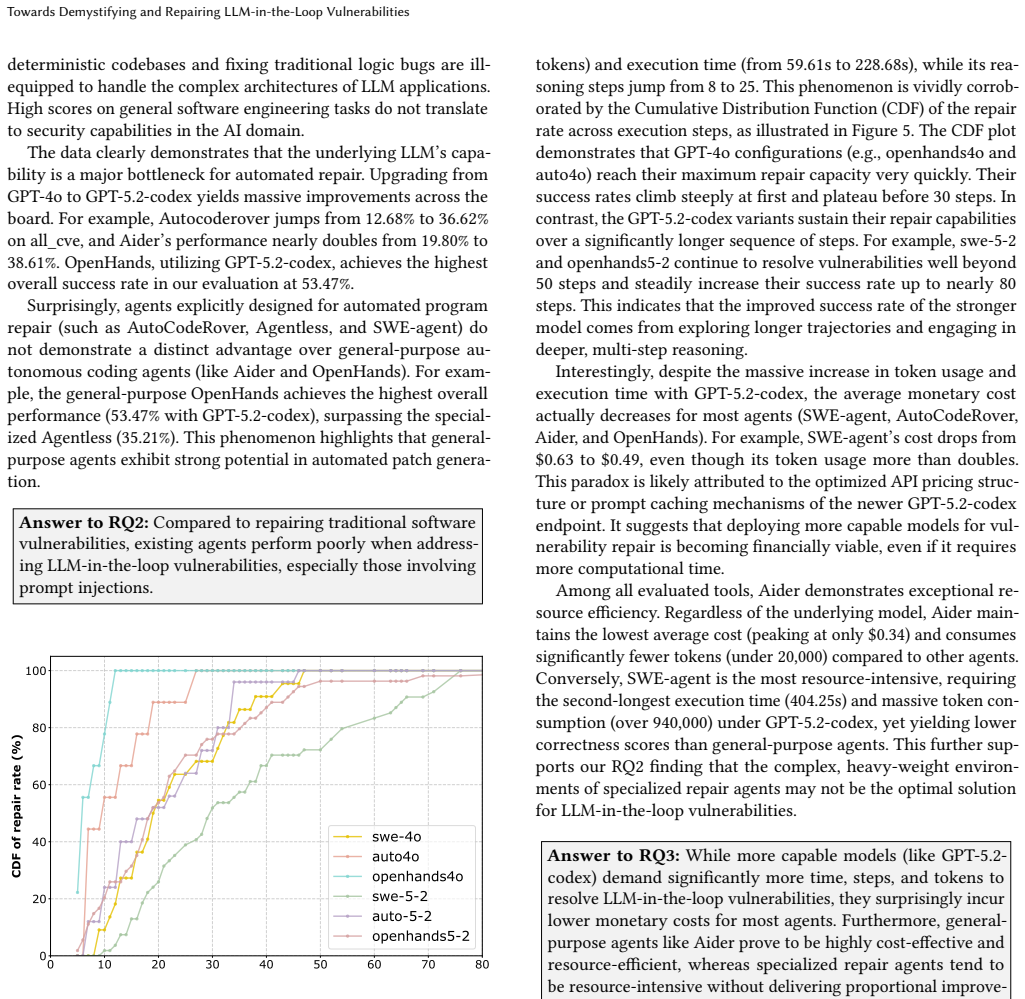
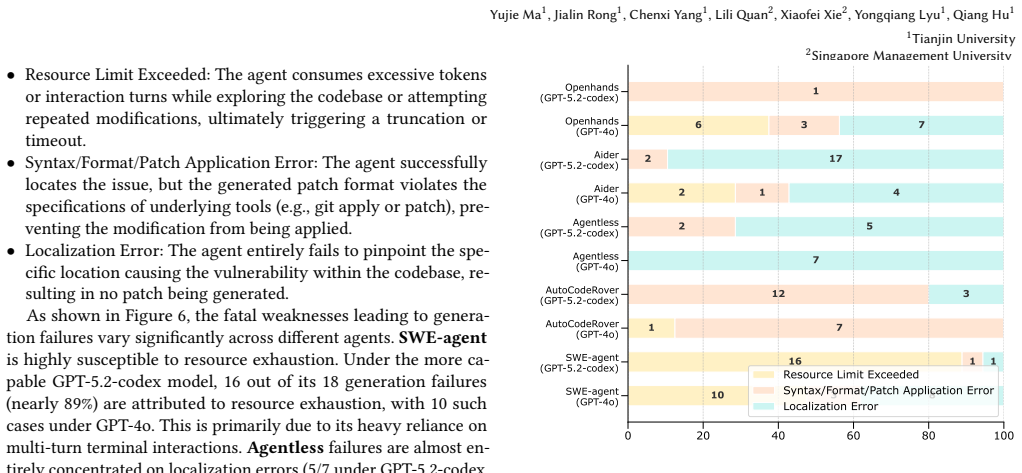
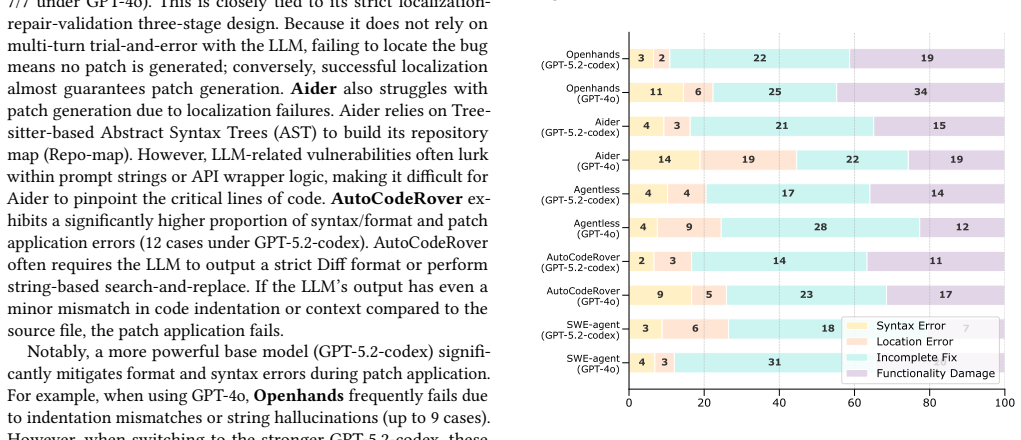
The authors present LLMCVE, a dataset of 205 LLM-in-the-loop vulnerabilities drawn from 2,888 collected issues across 230 components. In these cases LLMs function more often as targets or propagation vectors than as root causes. When existing agent-based repair methods are applied, success rates drop below those for conventional vulnerabilities, reaching only 28.57 percent Pass@1 for prompt-injection examples.
What carries the argument
The LLMCVE dataset built through manual filtering of multi-source vulnerability reports to isolate cases where LLM integration introduces or amplifies the flaw.
If this is right
- Existing repair agents need adaptation to handle prompt-related and LLM-dependent issues.
- Security analysis of LLM-integrated systems must treat the model as a potential attack surface or vector rather than only a code generator.
- Prompt injection vulnerabilities within LLM loops require specialized detection and mitigation beyond standard code fixes.
Where Pith is reading between the lines
- Future benchmarks for automated repair should include LLM-in-the-loop cases to avoid overestimating tool performance on real deployments.
- Developers integrating LLMs may need new design patterns that isolate the model from direct user input flows.
- Classification of vulnerabilities could shift to track whether the LLM component is the source, target, or conduit.
Load-bearing premise
The manual review correctly separated the 205 LLM-in-the-loop cases from the larger collection and that those cases represent typical risks in deployed LLM software.
What would settle it
A replication study that applies the same repair agents to the LLMCVE dataset and obtains Pass@1 rates comparable to those on standard vulnerability benchmarks would falsify the claim of greater difficulty.
Figures




read the original abstract
Large Language Models(LLMs) have been actively integrated into modern software systems as critical components. LLM-in-the-loop vulnerabilities, where vulnerabilities are introduced by LLMs and their dependent downstream components, such as frameworks, introduce new risks. Although some benchmark datasets have been constructed to study the impact of such vulnerabilities, most works still remain at the analysis from the conventional software level, ignoring the harm actually caused by LLMs. Understanding real-world LLM-in-the-loop vulnerabilities is still an open problem. To address this gap, we build the first LLM-in-the-loop vulnerability dataset, LLMCVE, to facilitate the risk analysis of LLM-integrated software. To do so, we first collect 2,888 multi-source vulnerabilities across 230 popular LLM components. Then, through manual analysis, we identify 205 vulnerabilities that strictly fall under the concept of LLM-in-the-loop vulnerability. Through analysis, we found that LLMs more often play as targets or propagation vectors rather than the root cause of these vulnerabilities. Furthermore, based on LLMCVE, we evaluate the repairing capabilities of existing agent-based vulnerability repair methods, such as SWE-Agent. Experimental results demonstrate that compared to conventional software vulnerabilities, LLM-in-the-Loop vulnerabilities are more challenging to precisely fix, especially for those involving prompt injections where the Pass@1 rate is only 28.57%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to construct LLMCVE, the first dataset of LLM-in-the-loop vulnerabilities, by collecting 2,888 multi-source vulnerabilities across 230 LLM components and using manual analysis to identify 205 that strictly match the concept. It analyzes the roles of LLMs (often as targets or propagation vectors) and evaluates agent-based repair tools such as SWE-Agent, reporting that these vulnerabilities are harder to fix than conventional ones, with a Pass@1 rate of only 28.57% on prompt-injection cases.
Significance. If the curation is made reproducible, the work supplies a new public dataset and empirical evidence of repair challenges specific to LLM-integrated systems, which could inform both vulnerability research and tool design. The direct experimental comparison of existing repair agents on the curated cases is a concrete contribution.
major comments (1)
- [Abstract and LLMCVE construction section] Abstract and the section on LLMCVE construction: the reduction from 2,888 collected items to 205 LLM-in-the-loop vulnerabilities is performed by manual analysis, yet no operational definition, decision criteria, number of annotators, or inter-rater agreement statistic is supplied. Because the dataset composition directly determines the repair-rate comparisons (including the 28.57% Pass@1 figure), this omission renders the central empirical claims non-reproducible.
minor comments (1)
- [Abstract] The abstract states collection and filtering numbers but does not reference a table or appendix that would allow readers to inspect the classification process.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in our dataset curation process. We address the single major comment below and will incorporate the requested details in a revised manuscript.
read point-by-point responses
-
Referee: [Abstract and LLMCVE construction section] Abstract and the section on LLMCVE construction: the reduction from 2,888 collected items to 205 LLM-in-the-loop vulnerabilities is performed by manual analysis, yet no operational definition, decision criteria, number of annotators, or inter-rater agreement statistic is supplied. Because the dataset composition directly determines the repair-rate comparisons (including the 28.57% Pass@1 figure), this omission renders the central empirical claims non-reproducible.
Authors: We agree that the current manuscript provides insufficient detail on the manual analysis step. The text states only that vulnerabilities were identified 'through manual analysis' to 'strictly fall under the concept of LLM-in-the-loop vulnerability,' without an operational definition, explicit decision criteria, annotator count, or agreement metric. Because the 205-case subset directly informs the reported repair rates, this information is necessary for reproducibility. In the revised manuscript we will add a dedicated subsection to the LLMCVE construction section that supplies: (1) a precise operational definition of LLM-in-the-loop vulnerabilities, (2) the decision criteria and annotation guidelines applied, (3) the number of annotators and their backgrounds, and (4) inter-rater agreement statistics. These additions will allow readers to verify the selection process and the validity of the empirical comparisons. revision: yes
Circularity Check
No significant circularity; empirical data collection and evaluation are self-contained
full rationale
The paper collects 2,888 vulnerabilities, applies manual analysis to select 205 as LLM-in-the-loop cases, analyzes their roles, and evaluates existing repair agents (e.g., SWE-Agent) on the resulting dataset. No equations, parameter fitting, derivations, or predictions appear. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. The central claims rest on direct experimental measurement rather than any reduction to the paper's own inputs by construction. The manual classification step, while potentially under-specified for reproducibility, does not match any enumerated circularity pattern and does not force the reported Pass@1 gap by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Manual analysis can reliably and consistently identify vulnerabilities that strictly fall under the LLM-in-the-loop concept
Reference graph
Works this paper leans on
-
[1]
Sara Abdali, Richard Anarfi, Carlos J Barberan, Jia He, and Erfan Shayegani
- [2]
-
[3]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Aider AI. 2024. Aider: AI pair programming in your terminal. https://github. com/Aider-AI/aider Accessed: 2026-03-20
2024
- [5]
- [6]
- [7]
-
[8]
Farzana Ahamed Bhuiyan, Md Bulbul Sharif, and Akond Rahman. 2021. Security bug report usage for software vulnerability research: a systematic mapping study. IEEE Access9 (2021), 28471–28495
2021
-
[9]
Quang-Cuong Bui, Riccardo Scandariato, and Nicolás E Díaz Ferreyra. 2022. Vul4j: A dataset of reproducible java vulnerabilities geared towards the study of program repair techniques. InProceedings of the 19th International Conference on Mining Software Repositories. 464–468
2022
-
[10]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Satish Chitimoju. 2024. A Survey on the Security Vulnerabilities of Large Lan- guage Models and Their Countermeasures.Journal of Computational Innovation 4, 1 (2024)
2024
-
[12]
Badhan Chandra Das, M Hadi Amini, and Yanzhao Wu. 2025. Security and privacy challenges of large language models: A survey.Comput. Surveys57, 6 (2025), 1–39
2025
-
[13]
David de Fitero-Dominguez, Eva Garcia-Lopez, Antonio Garcia-Cabot, and Jose- Javier Martinez-Herraiz. 2024. Enhanced automated code vulnerability repair using large language models.Engineering Applications of Artificial Intelligence 138 (2024), 109291
2024
-
[14]
Xiaoning Dong, Wenbo Hu, Wei Xu, and Tianxing He. 2025. Sata: A paradigm for llm jailbreak via simple assistive task linkage. InFindings of the Association for Computational Linguistics: ACL 2025. 1952–1987
2025
-
[15]
Mohamad Fakih, Rahul Dharmaji, Halima Bouzidi, Gustavo Quiros Araya, Oluwatosin Ogundare, Mst Ayesha Siddika, and Mohammad Abdullah Al Faruque
-
[16]
In2025 28th Euromicro Conference on Digital System Design (DSD)
Llm4cve: Enabling iterative automated vulnerability repair with large lan- guage models. In2025 28th Euromicro Conference on Digital System Design (DSD). IEEE, 592–599
-
[17]
Tarek Gasmi, Ramzi Guesmi, Jihene Bennaceur, and Ines Belhadj. 2026. Bridging AI and software security: A comparative vulnerability assessment of LLM agent deployment paradigms.Information Sciences740 (2026), 123231
2026
-
[18]
Danielle Gonzalez, Holly Hastings, and Mehdi Mirakhorli. 2019. Automated characterization of software vulnerabilities. In2019 IEEE International Conference on Software Maintenance and Evolution (ICSME). IEEE, 135–139
2019
-
[19]
Junda He, Christoph Treude, and David Lo. 2025. Llm-based multi-agent systems for software engineering: Literature review, vision, and the road ahead.ACM Transactions on Software Engineering and Methodology34, 5 (2025), 1–30
2025
-
[20]
Xinyi Hou, Yanjie Zhao, and Haoyu Wang. 2025. On the (in) security of llm app stores. In2025 IEEE Symposium on Security and Privacy (SP). IEEE, 317–335
2025
-
[21]
Yiwei Hu, Zhen Liu, Kedie Shu, Shenghua Guan, Deqing Zou, Shouhuai Xu, Bin Yuan, and Hai Jin. 2025. {SoK}: Automated Vulnerability Repair: Methods, Tools, and Assessments. In34th USENIX Security Symposium (USENIX Security 25). 4421–4440
2025
- [22]
- [23]
-
[24]
Bo Hui, Haolin Yuan, Neil Gong, Philippe Burlina, and Yinzhi Cao. 2024. Pleak: Prompt leaking attacks against large language model applications. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security. 3600–3614
2024
-
[25]
Umar Iqbal, Tadayoshi Kohno, and Franziska Roesner. 2024. LLM platform security: Applying a systematic evaluation framework to OpenAI’s ChatGPT plugins. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Vol. 7. 611–623
2024
-
[26]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
René Just, Darioush Jalali, and Michael D Ernst. 2014. Defects4J: A database of existing faults to enable controlled testing studies for Java programs. In Proceedings of the 2014 international symposium on software testing and analysis. 437–440
2014
-
[28]
Youngjoon Kim, Sunguk Shin, Hyoungshick Kim, and Jiwon Yoon. 2025. Logs In, Patches Out: Automated Vulnerability Repair via {Tree-of-Thought} {LLM} Analysis. In34th USENIX Security Symposium (USENIX Security 25). 4401–4419
2025
-
[29]
Yi Liu, Gelei Deng, Yuekang Li, Kailong Wang, Zihao Wang, Xiaofeng Wang, Tianwei Zhang, Yepang Liu, Haoyu Wang, Yan Zheng, et al. 2023. Prompt injec- tion attack against llm-integrated applications.arXiv preprint arXiv:2306.05499 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Jose Luna, Lili Quan, Ivan Tan, Lingxiao Jiang, Ming Hu, Qiang Hu, and Xiaofei Xie. 2026. Security and Safety Threats in the Large Language Model Supply Chain: A Systematic Survey and Taxonomy.A vailable at SSRN 6327419(2026)
2026
- [31]
-
[32]
MITRE Corporation. 2026. Common Weakness Enumeration (CWE). https: //cwe.mitre.org/ Accessed: 2026-03-27
2026
-
[33]
Vitor Hugo Galhardo Moia, Rodrigo Duarte de Meneses, and Igor Jochem Sanz
-
[34]
InSimpósio Brasileiro de Segurança da Informação e de Sistemas Computacionais (SBSeg)
An Analysis of Real-World Vulnerabilities and Root Causes in the LLM Supply Chain. InSimpósio Brasileiro de Segurança da Informação e de Sistemas Computacionais (SBSeg). SBC, 388–396
-
[35]
National Vulnerability Database (NVD). 2024. CVE-2024-12909 Detail. https: //nvd.nist.gov/vuln/detail/CVE-2024-12909. Accessed: 2026-03-26
2024
-
[36]
National Vulnerability Database (NVD). 2024. CVE-2024-5565 Detail. https: //nvd.nist.gov/vuln/detail/CVE-2024-5565. Accessed: 2026-03-26
2024
-
[37]
National Vulnerability Database (NVD). 2024. CVE-2024-8309 Detail. https: //nvd.nist.gov/vuln/detail/CVE-2024-8309. Accessed: 2026-03-26
2024
- [38]
-
[39]
Yu Nong, Haoran Yang, Long Cheng, Hongxin Hu, and Haipeng Cai. 2025. {APPATCH}: Automated adaptive prompting large language models for {Real- World} software vulnerability patching. In34th USENIX Security Symposium (USENIX Security 25). 4481–4500
2025
-
[40]
OWASP Foundation. 2025. OWASP Top 10 for LLM Applications 2025. https: //genai.owasp.org/llm-top-10/ Accessed: 2026-03-27
2025
-
[41]
Hammond Pearce, Benjamin Tan, Baleegh Ahmad, Ramesh Karri, and Brendan Dolan-Gavitt. 2023. Examining zero-shot vulnerability repair with large language models. In2023 IEEE symposium on security and privacy (SP). IEEE, 2339–2356
2023
- [42]
-
[43]
Protect AI. 2024. Huntr. https://huntr.com/
2024
- [44]
-
[45]
Muhammad Shahzad, Muhammad Zubair Shafiq, and Alex X Liu. 2012. A large scale exploratory analysis of software vulnerability life cycles. In2012 34th International Conference on Software Engineering (ICSE). IEEE, 771–781
2012
- [46]
-
[47]
Zhuoxiang Shen, Jiarun Dai, Yuan Zhang, and Min Yang. 2025. Security Debt in LLM Agent Applications: A Measurement Study of Vulnerabilities and Mitigation Trade-offs. In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 559–570
2025
-
[48]
Dongxun Su, Yanjie Zhao, Xinyi Hou, Shenao Wang, and Haoyu Wang. 2025. Gpt store mining and analysis. InProceedings of the 16th International Conference on Internetware. 344–354
2025
- [49]
-
[50]
Peiran Wang, Xiaogeng Liu, and Chaowei Xiao. 2025. Cve-bench: Benchmarking llm-based software engineering agent’s ability to repair real-world cve vulnerabil- ities. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 4207–4224
2025
-
[51]
Shenao Wang, Yanjie Zhao, Xinyi Hou, and Haoyu Wang. 2025. Large lan- guage model supply chain: A research agenda.ACM Transactions on Software Engineering and Methodology34, 5 (2025), 1–46
2025
-
[52]
Shenao Wang, Yanjie Zhao, Zhao Liu, Quanchen Zou, and Haoyu Wang. 2025. Sok: Understanding vulnerabilities in the large language model supply chain. arXiv preprint arXiv:2502.12497(2025). Yujie Ma1, Jialin Rong1, Chenxi Yang1, Lili Quan2, Xiaofei Xie2, Yongqiang Lyu1, Qiang Hu1 1Tianjin University 2Singapore Management University
- [53]
-
[54]
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. 2024. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
Yi Wu, Nan Jiang, Hung Viet Pham, Thibaud Lutellier, Jordan Davis, Lin Tan, Petr Babkin, and Sameena Shah. 2023. How effective are neural networks for fixing security vulnerabilities. InProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1282–1294
2023
-
[56]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2024. Agentless: Demystifying llm-based software engineering agents.arXiv preprint arXiv:2407.01489(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. 2023. Automated program repair in the era of large pre-trained language models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 1482–1494
2023
-
[58]
Yinglin Xie, Xinyi Hou, Yanjie Zhao, Kai Chen, and Haoyu Wang. 2025. LLM app squatting and cloning. InProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering. 64–74
2025
-
[59]
Chuan Yan, Ruomai Ren, Mark Huasong Meng, Liuhuo Wan, Tian Yang Ooi, and Guangdong Bai. 2024. Exploring chatgpt app ecosystem: Distribution, deploy- ment and security. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 1370–1382
2024
-
[60]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems37 (2024), 50528–50652
2024
-
[61]
John Yang, Kilian Lieret, Carlos E Jimenez, Alexander Wettig, Kabir Khand- pur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang
-
[62]
Swe-smith: Scaling data for software engineering agents.arXiv preprint arXiv:2504.21798(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Zheng Yu, Ziyi Guo, Yuhang Wu, Jiahao Yu, Meng Xu, Dongliang Mu, Yan Chen, and Xinyu Xing. 2025. {PATCHAGENT}: A Practical Program Repair Agent Mimicking Human Expertise. In34th USENIX Security Symposium (USENIX Security 25). 4381–4400
2025
-
[64]
Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. 2024. Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents.arXiv preprint arXiv:2410.02644(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
Lan Zhang, Qingtian Zou, Anoop Singhal, Xiaoyan Sun, and Peng Liu. 2024. Evaluating large language models for real-world vulnerability repair in c/c++ code. InProceedings of the 10th ACM International Workshop on Security and Privacy Analytics. 49–58
2024
-
[66]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. Autocoderover: Autonomous program improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1592– 1604
2024
-
[67]
Yanjie Zhao, Xinyi Hou, Shenao Wang, and Haoyu Wang. 2025. Llm app store analysis: A vision and roadmap.ACM Transactions on Software Engineering and Methodology34, 5 (2025), 1–25
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.