Less Context, Better Agents: Efficient Context Engineering for Long-Horizon Tool-Using LLM Agents
Pith reviewed 2026-06-27 16:08 UTC · model grok-4.3
The pith
Pruning context to the last five tool interactions plus summarization raises complete itemization from 71% to 91.6% while halving token use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
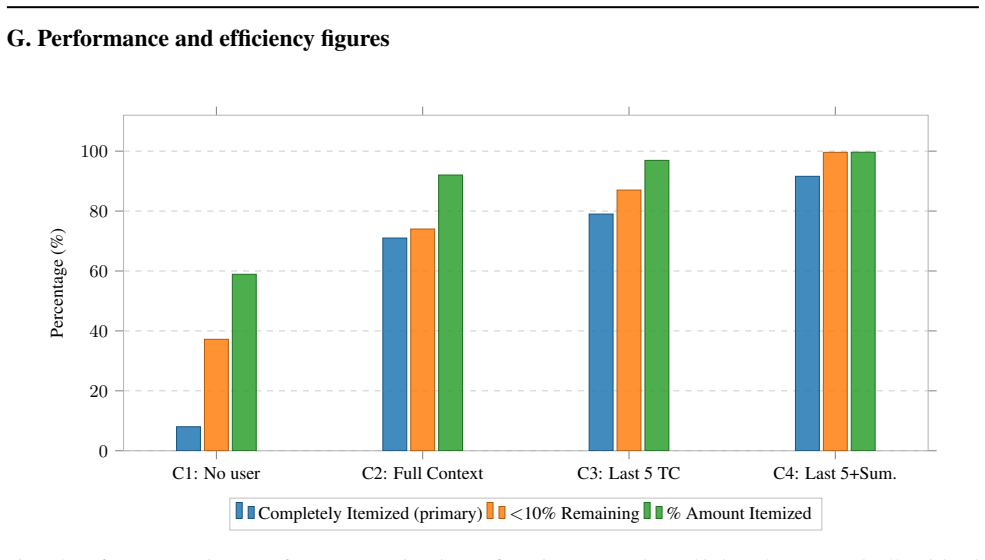
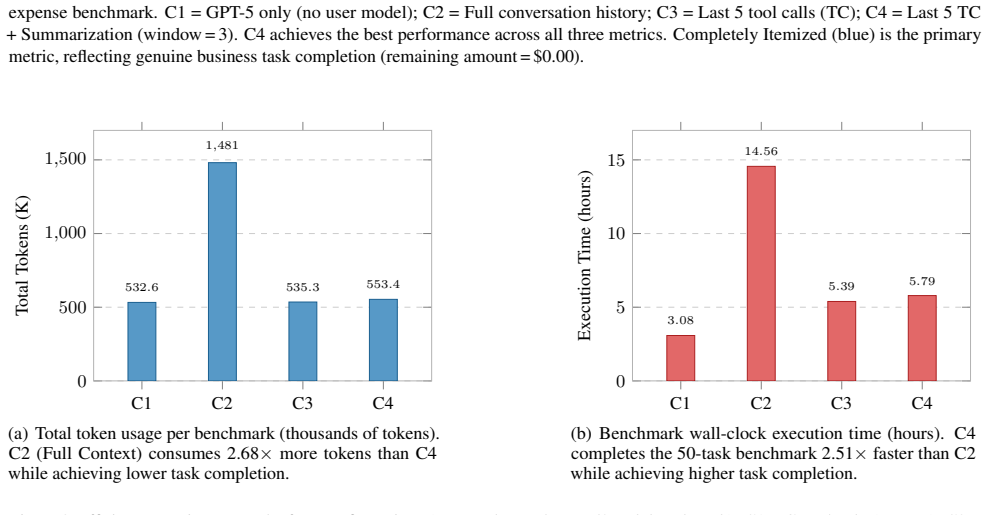
In the fifty-task hotel expense benchmark the configuration that keeps only the last five tool call/response pairs and adds automated summarization achieves 91.6 percent complete itemization and 99.64 percent average amount itemized, while full-context retention reaches only 71.0 percent; the pruned-plus-summarized run also consumes 553,374 tokens and 5.79 hours versus 1,480,996 tokens and 14.56 hours for full history.
What carries the argument
Context pruning to the last five tool call/response pairs combined with automated summarization, which keeps recent interactions and condenses earlier ones to avoid overflow and stale state.
Load-bearing premise
The fifty-task hotel expense benchmark is representative of the context-management problems that long-horizon tool-using LLM agents face in other enterprise workflows.
What would settle it
Repeating the identical four-configuration experiment on a different enterprise system or on a benchmark with more than fifty tasks and seeing whether the accuracy and efficiency gains disappear.
Figures

read the original abstract
Large language models deployed as autonomous agents for enterprise workflows face a key challenge: verbose tool responses from enterprise systems can cause context overflow, stale-state errors, and high inference cost. We study this problem in automated expense itemization in Microsoft Dynamics 365 Finance and Operations using Model Context Protocol tools. We evaluate four GPT-5 configurations on a 50-task hotel expense benchmark: no user model, full conversation history, context pruned to the last 5 tool call/response pairs, and pruning with automated summarization. Results are averaged across 5 independent runs, with the user model held constant for the context-engineering comparison. The no-user-model baseline achieves only 8.0% complete itemization. Full-context retention improves completion to 71.0%, but consumes 1,480,996 tokens and 14.56 hours per benchmark. Pruning to the last 5 tool calls improves completion to 79.0% while reducing token use to 535,274 and runtime to 5.39 hours. Adding summarization achieves the best result: 91.6% complete itemization and 99.64% average amount itemized, with 553,374 tokens and 5.79 hours. We further report confidence intervals, effect-size analysis, sensitivity over pruning and summary windows, failure analysis, results across five expense types grouped into three categories, and cross-model evidence with Claude Sonnet 4.5. These results show that, for this class of enterprise tool-use workflow, selective retention of recent tool interactions plus compact summarization can improve both reliability and efficiency compared with full-history retention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates context engineering strategies for LLM agents in long-horizon tool-using tasks, specifically automated expense itemization in Microsoft Dynamics 365 Finance and Operations. It compares four configurations on a 50-task hotel expense benchmark: no user model (8.0% complete itemization), full conversation history (71.0%), pruning to last 5 tool call/response pairs (79.0%), and pruning with automated summarization (91.6% complete itemization, 99.64% average amount itemized). The latter also reduces token consumption and runtime. Results are averaged over five runs with additional analyses including confidence intervals, effect sizes, sensitivity checks, failure analysis, and cross-model validation with Claude.
Significance. If the results hold, this work demonstrates that selective context retention combined with summarization can substantially improve both task completion and computational efficiency for LLM agents in enterprise tool-use scenarios. The inclusion of multiple independent runs, statistical measures, sensitivity analysis, and cross-model evidence strengthens the empirical contribution. These findings could inform practical context management techniques for reducing context overflow and costs in similar workflows, though the scope is limited to the evaluated benchmark.
major comments (1)
- [Abstract and Conclusion] Abstract and Conclusion: The paper concludes that selective retention plus summarization improves reliability and efficiency 'for this class of enterprise tool-use workflow.' However, the evidence is limited to one system (Dynamics 365 F&O) and one task family (hotel expenses) across 50 tasks whose horizon lengths and state-dependency complexities are not quantified. This raises a concern about whether the observed performance gap (e.g., 91.6% vs 71.0%) generalizes beyond this specific distribution, as other enterprise flows like multi-step approvals may differ.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the constructive comment on the scope of our claims. We agree that the evaluation is limited to a single system and task family, and we will revise the manuscript to reflect this more precisely while adding requested quantifications.
read point-by-point responses
-
Referee: [Abstract and Conclusion] Abstract and Conclusion: The paper concludes that selective retention plus summarization improves reliability and efficiency 'for this class of enterprise tool-use workflow.' However, the evidence is limited to one system (Dynamics 365 F&O) and one task family (hotel expenses) across 50 tasks whose horizon lengths and state-dependency complexities are not quantified. This raises a concern about whether the observed performance gap (e.g., 91.6% vs 71.0%) generalizes beyond this specific distribution, as other enterprise flows like multi-step approvals may differ.
Authors: We agree that the current phrasing in the abstract and conclusion risks implying broader generalization than the evidence supports. The evaluation is confined to Dynamics 365 F&O and the hotel expense itemization task family. In revision we will: (1) replace the phrase 'for this class of enterprise tool-use workflow' with 'for hotel expense itemization in Dynamics 365 F&O'; (2) add explicit quantification of task horizons (average tool calls per task, range, and state-dependency characteristics) in Section 3 and the appendix; (3) include a limitations paragraph noting that results may not extend to qualitatively different flows such as multi-step approvals. We retain the empirical contribution for the evaluated benchmark but will not claim transfer without additional experiments. revision: yes
Circularity Check
No circularity: direct empirical comparison on fixed benchmark
full rationale
The paper reports performance metrics from running four fixed context-engineering configurations (no user model, full history, pruned to last 5 pairs, pruned+summarized) on a 50-task hotel-expense benchmark in Dynamics 365. All numbers (91.6% complete itemization, token counts, runtimes, confidence intervals, effect sizes, sensitivity checks, cross-model results) are direct measurements from these runs. No equations, fitted parameters, self-citations, or derivations appear in the provided text that would reduce any reported outcome to a quantity defined by the inputs themselves. The central claim is an empirical ordering on this benchmark, not a derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The user model is held constant across the context-engineering conditions.
- domain assumption Results on the hotel expense benchmark generalize to the broader class of enterprise tool-use workflows.
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learn- ers,
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. ...
1901
-
[2]
LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models, 2023
H. Jiang, Q. Wu, C.-Y . Lin, Y . Yang, and L. Qiu, “LLMLingua: Compressing prompts for accelerated inference of large language models,”arXiv preprint arXiv:2310.05736, 2023
-
[3]
arXiv preprint arXiv:2304.12102 , year=
Y . Li, Y . Zhang, and L. Sun, “Selective context: On- demand context compression for long-context lan- guage models,”arXiv preprint arXiv:2304.12102, 2023
-
[4]
Effective context engineering for AI agents
Anthropic, “Effective context engineering for AI agents.” https://www.anthropic.com/en gineering/effective-context-enginee ring-for-ai-agents, 2025
2025
-
[5]
Mem- oryBank: Enhancing large language models with long- term memory,
W. Zhong, L. Guo, Q. Gao, H. Ye, and Y . Wang, “Mem- oryBank: Enhancing large language models with long- term memory,” inProceedings of the AAAI Conference on Artificial Intelligence, 2024
2024
-
[6]
Long- Mem: Augmenting large language models with mem- ory mechanism for long-context understanding,
Y . Wang, Y . Dong, D. Zeng, Z. Li, and M. Sun, “Long- Mem: Augmenting large language models with mem- ory mechanism for long-context understanding,”arXiv preprint arXiv:2407.01917, 2024
-
[7]
Evaluating Very Long-Term Conversational Memory of LLM Agents
A. Maharana, D.-H. Lee, S. Tulyakov, M. Bansal, F. Barbieri, and Y . Fung, “Evaluating very long- term conversational memory of LLM agents,”arXiv preprint arXiv:2402.17753, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
D. Wu, H. Wang, W. Yu, Y . Zhang, K.-W. Chang, and D. Yu, “LongMemEval: Benchmarking chat assis- tants on long-term interactive memory,”arXiv preprint arXiv:2410.10813, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
ACON: Optimizing Context Compression for Long-horizon LLM Agents
M. Kanget al., “ACON: Optimizing context compres- sion for long-horizon LLM agents,”arXiv preprint arXiv:2510.00615, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Context as a tool: Context management for long-horizon swe-agents,
S. Liu, J. Yang, B. Jiang, Y . Li, J. Guo, X. Liu, and B. Dai, “Context as a tool: Context manage- ment for long-horizon SWE-agents,”arXiv preprint arXiv:2512.22087, 2025
-
[11]
Z. Wanget al., “MCP-Bench: Benchmarking tool- using LLM agents with complex real-world tasks via MCP servers,”arXiv preprint arXiv:2508.20453, 2025
-
[12]
ReAct: Synergizing rea- soning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing rea- soning and acting in language models,” inProceedings of the International Conference on Learning Represen- tations (ICLR), 2023. Appendix A. Reproducibility overview This appendix collects the following artifacts: the tool inventory (B), the metric-computation/...
2023
-
[13]
Room service - breakfast $28
have much smaller catalogs and rarely repeat subcategories, which is why GPT-5 with no user model achieves higher CIR on those categories (∼27–40%) than on hotel (8%). This structural gradient—Hotel > Travel > Meals & Gifts—motivates our choice of hotel as the primary benchmark. Structural notes. • Hotelreceipts span multi-night stays with per-night charg...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.