Intrinsic 4D Gaussian Segmentation from Scene Cues
Pith reviewed 2026-06-26 21:54 UTC · model grok-4.3
The pith
Object segmentation in 4D Gaussian scenes can be recovered from the Gaussians' intrinsic properties without external masks or foundation models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
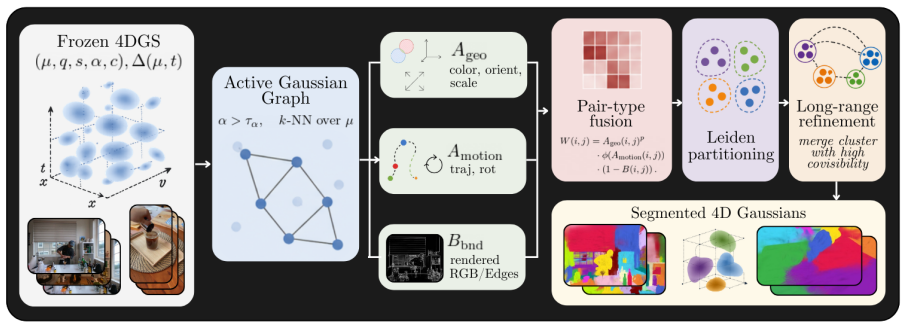
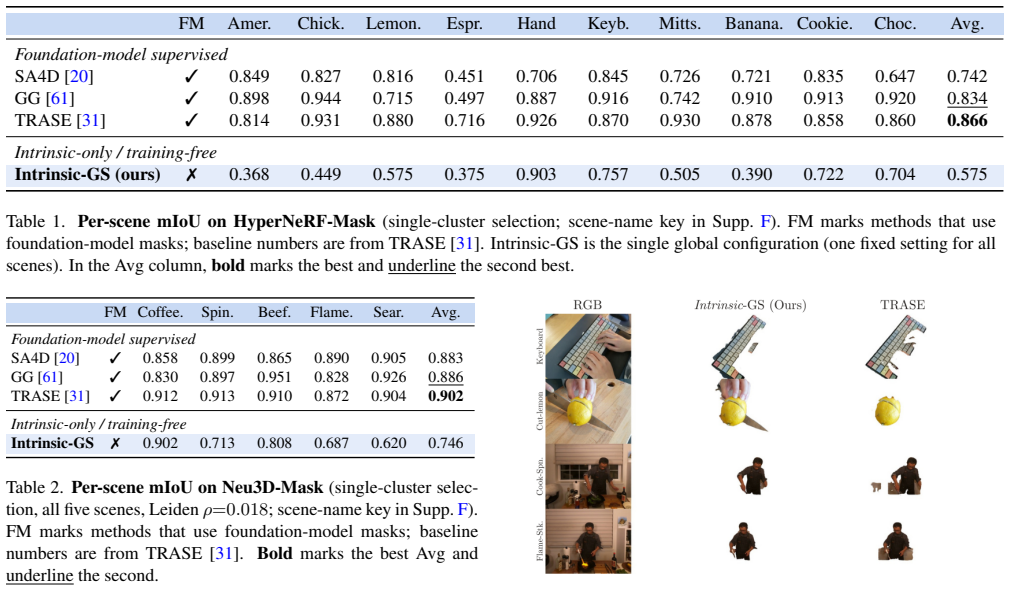
A training-free method builds a sparse affinity graph over Gaussian primitives from appearance, orientation, scale, deformation-trajectory and non-learned rendered-boundary cues, then partitions the graph with Leiden community detection to recover object-level structure; on Neu3D this yields 0.746 mIoU overall and 0.902 mIoU for a geometry-only variant that matches SAM-supervised baselines, while on HyperNeRF it runs 12.5x faster than mask-generation stages.
What carries the argument
A sparse affinity graph over Gaussian primitives constructed from intrinsic cues and partitioned by Leiden community detection.
If this is right
- A geometry-only variant reaches 0.902 mIoU on Neu3D, matching SAM-supervised TRASE.
- The method requires no foundation model and no learned feature field.
- Runtime is 12.5x faster than the mask-generation and feature-rendering stages of mask-supervised pipelines.
- The same cue set applies to both 3D and 4D Gaussian representations.
Where Pith is reading between the lines
- The approach may support editing and manipulation pipelines that cannot rely on consistent external masks.
- Because the cues are non-learned, the segmentation may remain stable under changes to scene lighting or camera paths that affect learned feature fields.
- The same graph-construction step could be inserted into existing Gaussian Splatting training loops to produce object labels as a byproduct.
Load-bearing premise
The chosen intrinsic cues produce an affinity graph whose communities found by Leiden detection correspond to coherent semantic objects.
What would settle it
On the Neu3D or HyperNeRF test sets, the Leiden communities on the affinity graph fail to match the provided ground-truth object labels at the reported mIoU levels.
Figures


read the original abstract
Dynamic 4D Gaussian Splatting reconstructs deforming scenes with high fidelity and is increasingly adopted as a representation for dynamic 3D scenes. Putting such a scene to use, for editing, manipulation or motion analysis, first requires segmenting it: grouping the Gaussian primitives into coherent objects. Current pipelines obtain this grouping by importing 2D masks from foundation models such as SAM and lifting or distilling them into the Gaussian representation. In dynamic scenes these masks must be generated across many frames and views, which is costly, and the resulting segmentation can depend strongly on the quality and consistency of those external masks. We ask how much object-level structure can instead be recovered from the Gaussians themselves, and propose Intrinsic-GS, a training-free, mask-free method that builds a sparse affinity graph over Gaussian primitives from appearance, orientation, scale, deformation-trajectory and non-learned rendered-boundary cues. The graph is partitioned with Leiden community detection, requiring no foundation model and no learned feature field. On the standard 4D Gaussian segmentation benchmarks, Neu3D and HyperNeRF, Intrinsic-GS recovers substantial object structure without mask supervision, reaching 0.746 mIoU on Neu3D and 0.575 on HyperNeRF; on Neu3D, a geometry-only variant reaches 0.902 mIoU, matching SAM-supervised TRASE. On HyperNeRF, Intrinsic-GS runs 12.5x faster than the mask-generation and feature-rendering stages used by mask-supervised pipelines. These results suggest that much of the segmentation signal is already encoded in the Gaussians themselves, offering a fast, mask-free direction for 3D and 4D Gaussian segmentation that may also point toward more generalizable, robust segmentation in settings where external masks are unreliable or expensive.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Intrinsic-GS, a training-free and mask-free approach to segmenting dynamic 4D Gaussian splatting scenes. It constructs a sparse affinity graph over Gaussian primitives using intrinsic non-learned cues (appearance, orientation, scale, deformation-trajectory, and rendered-boundary) and partitions the graph via Leiden community detection. On Neu3D and HyperNeRF benchmarks the method reports mIoU of 0.746 and 0.575 respectively; a geometry-only variant reaches 0.902 mIoU on Neu3D (matching a SAM-supervised baseline) while running 12.5× faster than mask-supervised pipelines on HyperNeRF. The central claim is that substantial object-level segmentation signal is already encoded in the Gaussians themselves.
Significance. If the empirical results hold under full verification, the work shows that object structure can be recovered directly from the 4D Gaussian representation without external masks or learned feature fields. This offers a faster, more robust alternative for 3D/4D Gaussian segmentation and reduces reliance on foundation-model mask generation, which is especially valuable when masks are inconsistent or expensive to obtain across frames and views.
major comments (2)
- [Abstract] The abstract states that the affinity graph is built from the listed cues and partitioned by Leiden detection, yet provides no quantitative breakdown of how each cue contributes to the final mIoU (e.g., ablation removing deformation-trajectory or rendered-boundary). Without this, it is difficult to assess whether the reported 0.746 / 0.575 scores are driven by a single dominant cue or by their combination.
- [Abstract] The geometry-only variant is reported to reach 0.902 mIoU on Neu3D and match the SAM-supervised TRASE baseline, but the abstract does not specify which subset of cues is retained or how the graph construction changes; this comparison is load-bearing for the claim that intrinsic cues suffice.
minor comments (2)
- [Abstract] The abstract mentions 'non-learned rendered-boundary cues' without defining the exact rendering procedure or threshold used to extract boundaries; a short paragraph or equation in the methods section would clarify reproducibility.
- [Abstract] Runtime comparison (12.5× faster) is given only for HyperNeRF; reporting the same metric on Neu3D would strengthen the efficiency claim.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the minor revision recommendation. The comments highlight opportunities to improve clarity in the abstract regarding cue contributions and the geometry-only variant; we address each below and will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] The abstract states that the affinity graph is built from the listed cues and partitioned by Leiden detection, yet provides no quantitative breakdown of how each cue contributes to the final mIoU (e.g., ablation removing deformation-trajectory or rendered-boundary). Without this, it is difficult to assess whether the reported 0.746 / 0.575 scores are driven by a single dominant cue or by their combination.
Authors: We agree the abstract would benefit from indicating that the reported scores reflect the combination of cues rather than any single dominant one. The full manuscript contains quantitative ablations (Section 4.3) showing incremental contributions from each cue, with no single cue accounting for the majority of performance. To address the comment directly, we will revise the abstract to include a concise clause noting that ablations confirm the value of the full cue set. revision: yes
-
Referee: [Abstract] The geometry-only variant is reported to reach 0.902 mIoU on Neu3D and match the SAM-supervised TRASE baseline, but the abstract does not specify which subset of cues is retained or how the graph construction changes; this comparison is load-bearing for the claim that intrinsic cues suffice.
Authors: We will clarify the geometry-only variant in the revised abstract. It retains the geometric and deformation cues (orientation, scale, deformation-trajectory, rendered-boundary) while omitting appearance; the affinity graph is constructed identically but without the appearance term. This matches the experimental setup in Section 4.2 where the variant is defined and compared to TRASE. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines Intrinsic-GS explicitly as the construction of an affinity graph from five listed non-learned cues followed by off-the-shelf Leiden partitioning; the reported mIoU figures are presented as empirical measurements on Neu3D and HyperNeRF rather than quantities derived by algebraic identity from the method's own inputs. No equation equates a claimed output to a fitted parameter, no uniqueness theorem is invoked via self-citation, and no ansatz is smuggled through prior work. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Leiden community detection applied to the constructed affinity graph yields groups that correspond to semantic objects in the scene.
Reference graph
Works this paper leans on
-
[1]
Neural point-based graph- ics
Kara-Ali Aliev, Artem Sevastopolsky, Maria Kolos, Dmitry Ulyanov, and Victor Lempitsky. Neural point-based graph- ics. InEuropean Conference on Computer Vision (ECCV), pages 696–712, 2020
2020
-
[2]
Zamir, Helen Jiang, Ioan- nis Brilakis, Martin Fischer, and Silvio Savarese
Iro Armeni, Ozan Sener, Amir R. Zamir, Helen Jiang, Ioan- nis Brilakis, Martin Fischer, and Silvio Savarese. 3d seman- tic parsing of large-scale indoor spaces. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), pages 1534–1543, 2016
2016
-
[3]
Hyperreel: High-fidelity 6-dof video with ray- conditioned sampling
Benjamin Attal, Jia-Bin Huang, Christian Richardt, Michael Zollh¨ofer, Johannes Kopf, Matthew O’Toole, and Changil Kim. Hyperreel: High-fidelity 6-dof video with ray- conditioned sampling. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16610–16620, 2023
2023
-
[4]
Mohamed Rayan Barhdadi, Hasan Kurban, and Hussein Al- nuweiri. PhysicsNeRF: Physics-guided 3D reconstruction from sparse views.arXiv preprint arXiv:2505.23481, 2025
arXiv 2025
-
[5]
Mohamed Rayan Barhdadi, Samir Abdaljalil, Rasul Khan- bayov, Erchin Serpedin, and Hasan Kurban. 4D synchro- nized fields: Motion-language Gaussian splatting for tempo- ral scene understanding.arXiv preprint arXiv:2603.14301, 2026
arXiv 2026
-
[6]
Barron, Ben Mildenhall, Matthew Tancik, Pe- ter Hedman, Ricardo Martin-Brualla, and Pratul P
Jonathan T. Barron, Ben Mildenhall, Matthew Tancik, Pe- ter Hedman, Ricardo Martin-Brualla, and Pratul P. Srini- vasan. Mip-NeRF: A multiscale representation for anti- aliasing neural radiance fields. InProc. IEEE/CVF Inter- national Conference on Computer Vision (ICCV), 2021
2021
-
[7]
Blondel, Jean-Loup Guillaume, Renaud Lam- biotte, and Etienne Lefebvre
Vincent D. Blondel, Jean-Loup Guillaume, Renaud Lam- biotte, and Etienne Lefebvre. Fast unfolding of communities in large networks.Journal of Statistical Mechanics: Theory and Experiment, 2008(10):P10008, 2008
2008
-
[8]
Ricardo J. G. B. Campello, Davoud Moulavi, and J ¨org Sander. Density-based clustering based on hierarchical den- sity estimates. InProc. Pacific-Asia Conference on Knowl- edge Discovery and Data Mining (PAKDD), 2013
2013
-
[9]
Oxford University Press, 2009
Susan Carey.The Origin of Concepts. Oxford University Press, 2009
2009
-
[10]
SAM 3: Segment anything with con- cepts.arXiv preprint arXiv:2511.16719, 2025
Nicolas Carion et al. SAM 3: Segment anything with con- cepts.arXiv preprint arXiv:2511.16719, 2025
Pith/arXiv arXiv 2025
-
[11]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. In Proc. IEEE/CVF International Conference on Computer Vi- sion (ICCV), 2021
2021
-
[12]
SAGA: Segment any 3D Gaussians.arXiv preprint arXiv:2312.00860, 2023
Jiazhong Cen, Jiemin Fang, Chen Yang, Lingxi Xie, Xi- aopeng Zhang, Wei Shen, and Qi Tian. SAGA: Segment any 3D Gaussians.arXiv preprint arXiv:2312.00860, 2023
arXiv 2023
-
[13]
pixelSplat: 3D Gaussian splats from im- age pairs for scalable generalizable 3D reconstruction
David Charatan, Sizhe Li, Andrea Tagliasacchi, and Vin- cent Sitzmann. pixelSplat: 3D Gaussian splats from im- age pairs for scalable generalizable 3D reconstruction. In Proc. IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), 2024
2024
-
[14]
MVSplat: Efficient 3D Gaussian splatting from sparse multi-view images
Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-Jen Cham, and Jianfei Cai. MVSplat: Efficient 3D Gaussian splatting from sparse multi-view images. InProc. European Conference on Com- puter Vision (ECCV), 2024
2024
-
[15]
Tracking anything with de- coupled video segmentation
Ho Kei Cheng, Seoung Wug Oh, Brian Price, Alexander Schwing, and Joon-Young Lee. Tracking anything with de- coupled video segmentation. InProc. IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), 2023
2023
-
[16]
A density-based algorithm for discovering clusters in large spatial databases with noise
Martin Ester, Hans-Peter Kriegel, J ¨org Sander, and Xiaowei Xu. A density-based algorithm for discovering clusters in large spatial databases with noise. InProc. Interna- tional Conference on Knowledge Discovery and Data Min- ing (KDD), 1996
1996
-
[17]
SuGaR: Surface- aligned Gaussian splatting for efficient 3D mesh reconstruc- tion and high-quality mesh rendering
Antoine Gu ´edon and Vincent Lepetit. SuGaR: Surface- aligned Gaussian splatting for efficient 3D mesh reconstruc- tion and high-quality mesh rendering. InProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[18]
2D Gaussian splatting for geometrically ac- curate radiance fields
Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2D Gaussian splatting for geometrically ac- curate radiance fields. InACM SIGGRAPH, 2024
2024
-
[19]
Gaus- sianCut: Interactive segmentation via graph cut for 3D Gaus- sian splatting
Umangi Jain, Ashkan Mirzaei, and Igor Gilitschenski. Gaus- sianCut: Interactive segmentation via graph cut for 3D Gaus- sian splatting. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[20]
SA4D: Segment any 4D Gaussians.arXiv preprint arXiv:2407.04504, 2024
Shengxiang Ji, Guanjun Wu, Jiemin Fang, Jiazhong Cen, Taoran Yi, Wenyu Liu, Qi Tian, and Xinggang Wang. SA4D: Segment any 4D Gaussians.arXiv preprint arXiv:2407.04504, 2024
arXiv 2024
-
[21]
3D Gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42 (4), 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3D Gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42 (4), 2023
2023
-
[22]
LERF: Language embed- ded radiance fields
Justin Kerr, Chung Min Kim, Ken Goldberg, Angjoo Kanazawa, and Matthew Tancik. LERF: Language embed- ded radiance fields. InProc. IEEE/CVF International Con- ference on Computer Vision (ICCV), 2023
2023
-
[23]
Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C. Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick. Segment anything. InProc. IEEE/CVF In- ternational Conference on Computer Vision (ICCV), 2023
2023
-
[24]
Harcourt, Brace and Company, 1935
Kurt Koffka.Principles of Gestalt Psychology. Harcourt, Brace and Company, 1935
1935
-
[25]
Point-based neural rendering with per- view optimization.Computer Graphics Forum, 40(4), 2021
Georgios Kopanas, Julien Philip, Thomas Leimk ¨uhler, and George Drettakis. Point-based neural rendering with per- view optimization.Computer Graphics Forum, 40(4), 2021
2021
-
[26]
DynMF: Neural motion factorization for real-time dynamic view synthesis with 3D Gaussian splatting
Agelos Kratimenos, Jiahui Lei, and Kostas Daniilidis. DynMF: Neural motion factorization for real-time dynamic view synthesis with 3D Gaussian splatting. InProc. Euro- pean Conference on Computer Vision (ECCV), 2024
2024
-
[27]
DGD: Dynamic 3D Gaussians distillation
Isaac Labe, Noam Issachar, Itai Lang, and Sagie Benaim. DGD: Dynamic 3D Gaussians distillation. InProc. Euro- pean Conference on Computer Vision (ECCV), 2024
2024
-
[28]
Neural 3D video synthesis from multi- view video
Tianye Li, Mira Slavcheva, Michael Zollhoefer, Simon Green, Christoph Lassner, Changil Kim, Tanner Schmidt, Steven Lovegrove, Michael Goesele, Richard Newcombe, and Zhaoyang Lv. Neural 3D video synthesis from multi- view video. InProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 10
2022
-
[29]
Langsplatv2: High-dimensional 3d language gaussian splatting with 450+ fps.Advances in Neural Information Processing Systems (NeurIPS), 2025
Wanhua Li, Yujie Zhao, Minghan Qin, Yang Liu, Yuan- hao Cai, Chuang Gan, and Hanspeter Pfister. Langsplatv2: High-dimensional 3d language gaussian splatting with 450+ fps.Advances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[30]
4d langsplat: 4d language gaussian splatting via multimodal large language models
Wanhua Li, Renping Zhou, Jiawei Zhou, Yingwei Song, Jo- hannes Herter, Minghan Qin, Gao Huang, and Hanspeter Pfister. 4d langsplat: 4d language gaussian splatting via multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22001–22011, 2025
2025
-
[31]
TRASE: Tracking-free 4d segmentation and editing via soft- mined contrastive learning
Yun-Jin Li, Mariia Gladkova, Yan Xia, and Daniel Cremers. TRASE: Tracking-free 4d segmentation and editing via soft- mined contrastive learning. InProc. International Confer- ence on 3D Vision (3DV), 2026
2026
-
[32]
Scaffold-GS: Structured 3D Gaussians for view-adaptive rendering
Tao Lu, Mulin Yu, Linning Xu, Yuanbo Xiangli, Limin Wang, Dahua Lin, and Bo Dai. Scaffold-GS: Structured 3D Gaussians for view-adaptive rendering. InProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[33]
Yiren Lu, Yunlai Zhou, Yiran Qiao, Chaoda Song, Tuo Liang, Jing Ma, and Yu Yin. Segment then splat: A uni- fied approach for 3d open-vocabulary segmentation based on gaussian splatting.arXiv preprint arXiv:2503.22204, 2025
arXiv 2025
-
[34]
Dynamic 3D Gaussians: Tracking by per- sistent dynamic view synthesis
Jonathon Luiten, Georgios Kopanas, Bastian Leibe, and Deva Ramanan. Dynamic 3D Gaussians: Tracking by per- sistent dynamic view synthesis. InProc. International Con- ference on 3D Vision (3DV), 2024
2024
-
[35]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view syn- thesis. InProc. European Conference on Computer Vision (ECCV), 2020
2020
-
[36]
Instant neural graphics primitives with a multires- olution hash encoding.ACM Transactions on Graphics, 41 (4), 2022
Thomas M ¨uller, Alex Evans, Christoph Schied, and Alexan- der Keller. Instant neural graphics primitives with a multires- olution hash encoding.ACM Transactions on Graphics, 41 (4), 2022
2022
-
[37]
Mark E. J. Newman and Michelle Girvan. Finding and eval- uating community structure in networks.Physical Review E, 69(2):026113, 2004
2004
-
[38]
Barron, Ben Mildenhall, Mehdi S
Michael Niemeyer, Jonathan T. Barron, Ben Mildenhall, Mehdi S. M. Sajjadi, Andreas Geiger, and Noha Radwan. RegNeRF: Regularizing neural radiance fields for view syn- thesis from sparse inputs. InProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[39]
Barron, Sofien Bouaziz, Dan B
Keunhong Park, Utkarsh Sinha, Peter Hedman, Jonathan T. Barron, Sofien Bouaziz, Dan B. Goldman, Ricardo Martin- Brualla, and Steven M. Seitz. HyperNeRF: A higher- dimensional representation for topologically varying neural radiance fields.ACM Transactions on Graphics, 40(6):1–12, 2021
2021
-
[40]
D-NeRF: Neural radiance fields for dynamic scenes
Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer. D-NeRF: Neural radiance fields for dynamic scenes. InProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
2021
-
[41]
LangSplat: 3D language Gaussian splat- ting
Minghan Qin, Wanhua Li, Jiawei Zhou, Haoqian Wang, and Hanspeter Pfister. LangSplat: 3D language Gaussian splat- ting. InProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[42]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProc. Interna- tional Conference on Machine Learning (ICML), 2021
2021
-
[43]
SAM 2: Segment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feicht- enhofer. SAM 2: Segment anything in images and videos. arXiv preprint arXiv:...
Pith/arXiv arXiv 2024
-
[44]
Statistical mechanics of community detection.Physical Review E, 74(1):016110, 2006
J ¨org Reichardt and Stefan Bornholdt. Statistical mechanics of community detection.Physical Review E, 74(1):016110, 2006
2006
-
[45]
ADOP: Approximate differentiable one-pixel point render- ing
Darius R ¨uckert, Linus Franke, and Marc Stamminger. ADOP: Approximate differentiable one-pixel point render- ing. InProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[46]
Flash- Splat: 2D to 3D Gaussian splatting segmentation solved op- timally
Qiuhong Shen, Xingyi Yang, and Xinchao Wang. Flash- Splat: 2D to 3D Gaussian splatting segmentation solved op- timally. InProc. European Conference on Computer Vision (ECCV), 2024
2024
-
[47]
Normalized cuts and image segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 22(8):888–905, 2000
Jianbo Shi and Jitendra Malik. Normalized cuts and image segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 22(8):888–905, 2000
2000
-
[48]
Silva, Mahtab Dahaghin, Matteo Toso, and Alessio Del Bue
Myrna C. Silva, Mahtab Dahaghin, Matteo Toso, and Alessio Del Bue. Contrastive Gaussian clustering: Weakly super- vised 3D scene segmentation. InProc. European Conference on Computer Vision (ECCV), 2024
2024
-
[49]
Elizabeth S. Spelke. Principles of object perception.Cogni- tive Science, 14(1):29–56, 1990
1990
-
[50]
Spelke and Katherine D
Elizabeth S. Spelke and Katherine D. Kinzler. Core knowl- edge.American Psychologist, 55(11):1233–1243, 2000
2000
-
[51]
Pixel difference net- works for efficient edge detection
Zhuo Su, Wenzhe Liu, Zitong Yu, Dewen Hu, Qing Liao, Qi Tian, Matti Pietik¨ainen, and Li Liu. Pixel difference net- works for efficient edge detection. InProc. IEEE/CVF Inter- national Conference on Computer Vision (ICCV), 2021
2021
-
[52]
Su Sun, Cheng Zhao, Zhuoyang Sun, Yingjie Victor Chen, and Mei Chen. SplatFlow: Self-supervised dynamic Gaus- sian splatting in neural motion flow field for autonomous driving.arXiv preprint arXiv:2411.15482, 2025
arXiv 2025
-
[53]
Traag, Ludo Waltman, and Nees Jan van Eck
Vincent A. Traag, Ludo Waltman, and Nees Jan van Eck. From Louvain to Leiden: Guaranteeing well-connected com- munities.Scientific Reports, 9(1):5233, 2019
2019
-
[54]
A tutorial on spectral clustering.Statis- tics and Computing, 17(4):395–416, 2007
Ulrike von Luxburg. A tutorial on spectral clustering.Statis- tics and Computing, 17(4):395–416, 2007
2007
-
[55]
SynSin: End-to-end view synthesis from a single image
Olivia Wiles, Georgia Gkioxari, Richard Szeliski, and Justin Johnson. SynSin: End-to-end view synthesis from a single image. InProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[56]
11 4D Gaussian splatting for real-time dynamic scene render- ing
Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xiaopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, and Xinggang Wang. 11 4D Gaussian splatting for real-time dynamic scene render- ing. InProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[57]
OpenGaussian: Towards point-level 3D Gaussian-based open vocabulary understand- ing
Yanmin Wu, Jiarui Meng, Haijie Li, Chenming Wu, Yahao Shi, Xinhua Cheng, Chen Zhao, Haocheng Feng, Errui Ding, Jingdong Wang, and Jian Zhang. OpenGaussian: Towards point-level 3D Gaussian-based open vocabulary understand- ing. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[58]
AD-GS: Object-aware B-spline Gaussian splatting for self-supervised autonomous driving
Jiawei Xu et al. AD-GS: Object-aware B-spline Gaussian splatting for self-supervised autonomous driving. InProc. IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[59]
Point-NeRF: Point-based neural radiance fields
Qiangeng Xu, Zexiang Xu, Julien Philip, Sai Bi, Zhixin Shu, Kalyan Sunkavalli, and Ulrich Neumann. Point-NeRF: Point-based neural radiance fields. InProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[60]
Deformable 3D Gaussians for high-fidelity monocular dynamic scene reconstruction
Ziyi Yang, Xinyu Gao, Wen Zhou, Shaohui Jiao, Yuqing Zhang, and Xiaogang Jin. Deformable 3D Gaussians for high-fidelity monocular dynamic scene reconstruction. In Proc. IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), 2024
2024
-
[61]
Gaussian grouping: Segment and edit anything in 3D scenes
Mingqiao Ye, Martin Danelljan, Fisher Yu, and Lei Ke. Gaussian grouping: Segment and edit anything in 3D scenes. InProc. European Conference on Computer Vision (ECCV), 2024
2024
-
[62]
Mip-Splatting: Alias-free 3D Gaussian splatting
Zehao Yu, Anpei Chen, Binbin Huang, Torsten Sattler, and Andreas Geiger. Mip-Splatting: Alias-free 3D Gaussian splatting. InProc. IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), 2024
2024
-
[63]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProc. IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[64]
one static
Shijie Zhou, Haoran Chang, Sicheng Jiang, Zhiwen Fan, Ze- hao Zhu, Dejia Xu, Pradyumna Chari, Suya You, Zhangyang Wang, and Achuta Kadambi. Feature 3DGS: Supercharging 3D Gaussian splatting to enable distilled feature fields. In Proc. IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), 2024. 12 Supplementary Material: Intrinsic-GS A. ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.